改進項編碼及粗糙集算法在病害蔬菜葉片圖像挖掘中的應用
2013-11-01 07:39:46羅曉麗
唐山師范學院學報 2013年5期
關鍵詞:數據庫
羅曉麗
(福州職業技術學院 計算機系,福建 福州 350108)
溫室蔬菜生產由于是在人為控制生產,周年生產、難以輪作等因素,使得病害極易發生,傳統的病蟲害檢測是通過專家觀察,憑經驗根據感病蔬菜葉片上病斑的顏色或形狀判斷病害的種類。筆者在大量的數據基礎上,在項編碼基礎上,利用粗糙集約簡的方法進一步挖掘出病害受損程度的圖像特征屬性及特征區間。
1 基于項編碼的的Apriori算法及改進算法
1.1 Apriori算法原理
Agrawal等首次提出將關聯規則[1]應用于解決挖掘顧客交易數據中項目集間問題,其核心是基于2階段頻繁集思想(即發現頻繁項目集和生成關聯規則)的遞推算法,其典型算法是Apriori算法,該算法的主要內容如下:(1)使用逐層搜索的迭代方法。首先過掃描數據庫,計算出各個頻繁1-項集的支持度,找出所有頻繁1-項集L1,得到頻繁1-項集的集合。(2)連接步。由2個只有一個項不同的頻繁1-項集進行JOIN運算得到的候選頻繁2-項目集C2。(3)剪枝步。對C2進行修剪得到頻繁項集L2。(4)通過掃描數據庫,計算各個項集的支持度,將不滿足支持度的項目集去掉,通過迭代循環,重復步驟2~4,直到找到最大頻繁項集,此時算法停止。
隨著掃描的數據量增大,Apriori算法也呈現出明顯不足:(1)候選集Ck中的每個元素都必須通過掃描數據庫一次計算支持度,來確定其是否能成為頻繁項集 Lk中的元素,而多次掃描事務數據庫,需要很大的I/O負載。(2)隨著掃描數據庫的事務量增大,可能有龐大的候選集產生。規模巨大的候選項集,不僅處理需要占用大量的主存空間,而且算法必須耗費大量的時間來處理。例如:對于1-頻繁項集個數如果是10 000個,那么可能產生的候選集就會有個。
1.2 基于項編碼的CA算法
基于項編碼的 CA算法[2],只需要掃描數據庫一次,并對每個項完成編碼轉換,根據它在數據庫中出現的事務記錄用0和1進行編碼,以后的過程都是針對編碼進行運算,統計1的個數計算支持數k項頻繁項集,通過編碼與運算生成K+1項頻繁項集,不需要再次掃描數據庫。其具體特點如下:(1)編碼運算。該算法只需要掃描一次數據庫,并對每個項在某個事務記錄中是否出現進行編碼,以“出現為1,不出現為0”的原則進行編碼,以后的過程都是針對編碼進行與運算。與Apriori算法相比,該算法僅掃描數據庫一次,因而減少了算法的I/O負載。(2)連接前剪枝。CA算法在對頻繁(k-1)-項集Lk-1通過與運算進行連接,得到候選頻繁k-項集Ck,并對Lk-1中1的個數進行計數處理,根據計數結果刪除Lk-1中包含出現次數小于(k-1)的項的項集,以減少參加連接的(k-1)項的數量,從而降低了組合的數據量,也減小了候選頻繁 k-項集 Ck的大小。但該算法在進行編碼轉換時需要消耗大量時間,而且編碼數位過長,I/O的負載過大;同時由于編碼過長,造成與運算的繁復,可見記錄的個數極大地影響了該算法運行的時間。
1.3 改進算法
通過上述分析可知,要提高算法的運行效率,可從如下方面進行處理:(1)降低掃描事務的記錄數;(2)計算支持度時減少掃描數據庫的次數。由此筆者提出通過減少數據庫的記錄數來減小編碼轉換時間的改進算法,其基本思路是先進行一次掃描,計算出候選頻繁1-項目集,將含有1-項目集的記錄重新組合生成新的數據庫(比原來的數據庫記錄大為減少,尤其是海量數據庫減少的記錄數量更多),并利用CA算法對新生成數據庫進行編碼轉換。這樣以后不再掃描的數據庫,而是通過編碼與運算生成候選頻繁項集,通過統計項編碼中1的個數計算支持度。由于只進行一次掃描,且縮小了掃描范圍,因而加快了運算速度,提高數據挖掘的效率。
改進算法的具體描述如下:
輸入:事務數據庫D;最小支持度閾值min_sup
輸出:D中的頻繁項集L
{C1=candidate1-Itemsets};//生成候選頻繁1-項目集,一般情況下,令T1={{I1},{I2},{I3}…{Im}},即T1為所有項目的集合。
L1={p∈T|Sup (p)≥min_sup};//掃描事務數據庫D一次,生成頻繁1-項集。
Copy * to D2for c ∈L1//生成縮小的新的數庫,并對該數庫進行編碼轉換。

2 粗糙集約簡算法[3]
2.1 決策表
設Q=(U, A, V, f)是一個信息系統,U為論域,即為數據庫所有對象集合,A為屬性集,C為條件屬性,D為決策屬性,V為屬性集的值域,f:U×A→V,A=C∪D。
2.2 等價類及相關概念
設數據庫U={x1, x2, x3, x4, x5, x6,…},屬性集A={a1,a2, a3, a4, a5, a6,…},條件屬性C={a0, a1, a2, a3, a4, a5,a6, …},決策屬性D={am},屬性集的值域V={V1, V2, V3,V4, V5, ……}。
定義1 對于屬性集A中任意一個屬性a,若xi和xj所對應屬性a的取值相等,則有xi,xj基于屬性a等價。
定義 2 屬于同等價類的記錄歸為一類,論域基于屬性A的劃分可表示為U={U1, U2, U3, U4, U5, U6, ……}。
2.3 屬性約簡與規則生成
(1)對于每一個 a∈C,按屬性值個數排列,排序后為{a0, a1, a2, a3, a4, a5, a6, ……ak};
(2)令a0=0, a1=1……ak-1=k-1, j=0, c=aj+1, aj+1=aj
If aji=a(j+1)i ‘判斷決策表是否相容
相容:a(j+2)i=a(j+2-1)i……, aki=a(k-1)i,則合并相同的行
不相容:a(j+1)i=c
令j=j+1, if j=k,則輸出a0, a1, a2, a3, a4, a5, a6, …ak-1
Else goto (2)
3 研究目標與方案確定
研究目的是找出病斑受病害程度嚴重與其他特征的關聯規則。運用改進的Apriori算法得到極大相關組,其屬性值的劃分過細,存在數據冗余現象,進一步通過屬性約簡,可以得到更為客觀科學的關聯規則。因此本文采用粗糙集約簡理論合理劃分屬性區間,以使挖掘出的規則更科學。
4 應用
4.1 圖像數據挖掘
傳統的數據挖掘[4]稱為數據庫中的知識發現(Knowledge Discovery in Database,KDD),是從存放在數據庫、數據倉庫或其他信息庫中的大量復雜的原始的數據中,提取出對人們的決策有價值的知識或規則的過程。而這種知識或規則是人們事先不知道的但又對決策者分析歷史或現在數據,挖掘出有價值的數據模型,對現在的決策或將來的預測有價值的規則或知識。隨著圖形圖像及多媒體信息的日益發展,圖像數據挖掘顯得越來越重要。從圖像數據庫中取得一些先驗知識對圖像信息的進一步提取的準確性及時效性顯得尤為重要。圖像數據庫的建立有微觀和宏觀角度兩種,微觀是把圖像看成由無數個象素點作為對象的數據庫,研究每個象素點的灰度、顏色、像距等;宏觀可以把圖像的局部作為對象創建數據庫,進而研究對象的灰度、顏色、大小、紋理等屬性。
4.2 實驗步驟及結果
(1)實驗環境:在同樣的實驗條件下(服務器:P4 2.0 GHz、4 G內存、SQL Server2000;客戶機: P4 3.9 GHz、2 G內存)。
(2)實驗數據預處理:選用563片黃瓜霜霉病葉片利用photoshop工具分離病斑圖像共計2 457塊病斑連通圖像區域數據,取得圖像特征屬性:面積A、顏色C、亮度B、位置P、周長G、灰度均值H、形狀R等。如表1。

表1 黃瓜葉片病斑圖像特征
(3)運用改進的Apriori算法得到支持度大于30%的極大相關組{ACHR},表明受害程度與亮度、位置無關,與面積、顏色、灰度均值、形狀極大相關。
(4)并根據每個特征最大與最小值,劃屬性區間,將屬性值離散化,將顏色屬性定為決策屬性按淺綠和淺黃、棕色和褐色C={1,2,3}(顏色的深淺表明受害程度的大小),D={A, P, H, R }為條件屬性,如面積按[0, 0.5],[0.5, 1],[1,1.5],[1.5, 2],[2, +∞]區間離散 A={1, 2, 3, 4, 5};灰度均值按[120,130],[130,140],[140,150],[140,150],[160,+∞]區間離散 H={1,2,3,4,5, 6, 7};形狀按圓形、三角形、長條形得到集合R={1, 2, 3}。原始數據初始化如表2。
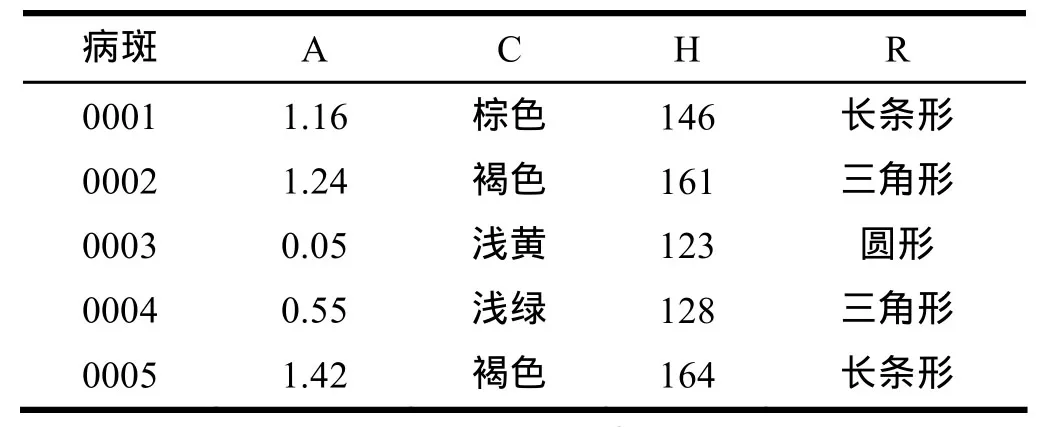
表2 黃瓜葉片病斑受害情況決策表
(5)利用粗糙集約簡算法,對上述表中屬性進行約簡,發現相對于顏色決策屬性,面積屬性值1、2合并,3、4、5合并約簡,灰度均值1、2合并,3、4合并,5、6合并,形狀屬性值2、3、4合并約簡。
挖掘結果:病斑面積較小低于1時,形狀接近圓形,且顏色較淺,顏色偏綠色黃色,灰度均值在區間[12,140],受害程度較輕。而當面積較大超過1時,形狀不規則,且顏色較深,顏色偏棕褐色,灰度均值在[140,+∞],受害程度較為嚴重。
5 結論
借鑒經典的Apriori算法及其優化解決方案,提出了一種保留含有頻繁1-項集的數據庫作為掃描的數據庫,不僅縮小了掃描數據庫的規模,而且減少了編碼轉換位長,逐步縮小了數據庫搜索的時間和進行運算的時間,從而極大提高了算法的運行效率。對于圖像數據量大、繁雜,這種算法尤為適合。對于圖像數據預處理,使用粗糙集約簡算法得出的挖掘規則,可以科學動態地劃分離散區間,從而挖掘出的結果更具科學性。
[1] 黃建明.關聯規則挖掘算法的研究與應用[D].西安:西安建筑科技大學,2009.
[2] 李磊,向正義.一種基于二項編碼的改進設計[J].微計算機信息,2009(21):214-215.
[3] 張亦軍.基于粗糙集和遺傳算法的大數據集數據挖掘應用研究[D].太原:太原理工大學,2012.
[4] 韓家瑋.數據挖掘·概念與技術[M].北京:機械工業出版社,2006:66-69.
猜你喜歡
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
華東師范大學學報(自然科學版)(2017年1期)2017-02-27 13:41:08
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
財經(2015年3期)2015-06-09 17:41:31
財經(2014年21期)2014-08-18 01:50:18
財經(2014年6期)2014-03-12 08:28:19
財經(2013年6期)2013-04-29 17:59:30
