中文分詞算法概述
2013-11-01 07:39:46甘秋云
唐山師范學院學報 2013年5期
甘秋云
(1.福州海峽職業技術學院,福建 福州 350014;2.福建工程學院 國脈信息院,福建 福州 350014)
對于以漢語為母語的我國來說,中文信息處理技術已經在我國信息化建設中占據了一個非常重要的地位。據統計,在信息領域中80%以上的信息是以語言文字為載體的,這些信息的自動輸入和輸出、文本的校勘和分類、信息的提取和檢索以及語言翻譯等語言工程,都是我國信息化建設的重要基礎。在眾多中文信息處理技術中,中文分詞技術是關鍵技術,同時也是中文信息處理的基礎。
1 中文分詞概述
1.1 中文分詞簡介
中文分詞既是中文信息處理的關鍵,也是中文信息處理的基礎。對于中文分詞可以通俗地指由機器在中文文本的詞與詞之間自動加上空格,以實現分詞的目的。
中文信息處理主要包括了字、詞、短語、句子、篇章等多層面的信息加工處理任務。當前漢語信息處理的主要任務已從“字處理”轉移到“詞處理”。由于中文文本是按詞連寫的,詞間無間隙,因而在中文文本處理中,首先遇到的問題是詞的切分問題,也就是中文自動分詞,例如將“學習信息科學”切分成“學習/信息/科學”。
在20世紀80年代初期,自動分詞技術的研究就受到重視并不斷發展,因此許多分詞模型和軟件也不斷問世。近年來,隨著國民經濟信息化的不斷發展以及 Internet的普及應用,在中文信息處理的廣泛應用中,實現漢語詞典和語料庫等中文資源的共享和復用顯得尤為重要,因此對自動分詞的要求也越來越高,自動分詞已經成為中文信息處理的一個前沿課題[1]。
1.2 中文分詞中存在的困難
1.2.1 分詞規范問題[2]
漢語詞的概念。對于分詞結果是否正確需要有一個通用、權威的分詞標準來衡量。分詞標準的問題實際上是漢語詞與語素、詞與詞組的界定問題,這是漢語語法的一個基本、長期的問題。主要包括核心詞表問題、詞的變形結構問題、詞綴的問題等。
不同應用對詞的切分規范要求不同。漢語自動分詞規范必須支持各種不同目標的應用,但不同目標的應用對詞的要求是不同的,甚至會有矛盾。如,以詞為單位的鍵盤輸入系統,為了提高輸入速度,一些互現頻率高的相互鄰接的幾個字也常作為輸入單位,如“這是”、“就是”等。
1.2.2 分詞算法的困難
1.2.2.1 分詞與理解的先后
由于計算機理解文本的前提是識別出詞、獲得詞的各項信息,即它只能在對輸入文本尚無理解的條件下進行分詞。因此它無法像人那樣在閱讀漢語文章時邊理解邊分詞,而只能是先分詞后理解,這就會造成邏輯上的兩難:分詞要以理解為前提,而理解又是以分詞為前提。所以任何分詞系統都不可能企求百分之百的切分正確率。
1.2.2.2 切分歧義的消除[3]
當語言存在歧義時,我們一般是通過上下文理解來選擇正確的詞語。但是機器很難正確判斷該如何切分。例如“中國人民”,到底是切分成“中國人/民”還是切分成“中國/人民”,就需要想辦法正確選擇。
對于歧義而言,我們按照它的結構可以分為兩種類型:交叉歧義(交集型歧義)和覆蓋歧義(組合型歧義)。
交叉歧義指的是,字串“ABC”,如果“AB”、“BC”分別屬于兩個不同的詞,既可以切分成“A/BC”,也可以切分成“AB/C”,則稱“ABC”存在交叉歧義。例如字串“組合成”,“組合”和“合成”都是一個詞,他們就存在交叉歧義。
覆蓋歧義,也稱為組合歧義,對于字串“AB”,如果“AB”是一個詞,“AB”其中的子串“A”和“B”也是一個詞,則稱“AB”存在覆蓋歧義。例如字串“才能”,“才能”是一個詞,“才”和“能”也可以單獨成詞。例如“他/來/了/,/問題/才/能/解決”,“他/的/才能/是/有目共睹/的”,這時候就存在覆蓋歧義。
歧義的消除一般需要提供更多的語法和語義信息,而且有時候要結合上下文語境理解。切分過程中,當出現人工也無法判斷時,就必須要結合更多的上下文才能理解。此時要求計算機自動識別,就更加困難了。
1.2.2.3 未登錄詞識別[4]
未登錄詞指的是詞典中沒有收錄的詞語。主要指各種命名實體和新詞。另外,一些縮略語和術語也屬于未登錄詞的范圍。
對于有些命名實體,比如數詞、時間等具有較強的規律性,相對容易識別。有些比如人名、地名,也有自己的常用詞,采用一些規則和統計信息,也能識別大部分。但是對于新詞來說,則很難找出什么規律。隨著社會的發展,各種新詞層出不窮,很多新詞的形成在語法語義上是完全沒有規律的,例如“非典”、“醬紫”等。而且很多未登錄詞和常用詞混在一起,容易形成歧義。
1.2.2.4 先識別已知詞還是先識別未登錄詞
在目前的分詞算法中,通常是將已知詞識別和未登錄詞識別分作兩個部分。這樣就產生了一個問題:先識別哪個部分更有利。
如果先識別未登錄詞,同樣也可能導致已知詞識別錯誤,例如“勝利/取決/于勇/氣”。反之,如果先識別已知詞,會導致未登錄詞識別錯誤,例如“內塔尼亞/胡說”。
目前來說,對于哪一步識別在先更好一些,研究者們并沒有一個確定的結論。
2 中文分詞切分算法
從1983年第一個實用分詞系統CDWS的誕生到現在,關于漢語分詞的算法大致可以分為四大類。
2.1 基于詞典和規則的方法[5]
這類算法在切分時用待切分的字符串去匹配詞典中的詞條,如果匹配成功,則切分成一個詞。目前最常用的是基于詞典的字符串匹配方法,主要包括最大匹配、全切分、最短路徑等。
2.1.1 最大匹配法
該方法又可分為正向最大匹配、反向最大匹配和雙向最大匹配三種,主要是根據取詞的方向來決定的。正向最大匹配從左到右每次取最長詞,反向最大匹配則每次是從右到左取最長詞,得到切分結果。雙向匹配則是進行正向、反向匹配,然后對于兩種匹配結果不同的地方再利用一定的規則進行消歧。這種方法實現簡單,而且切分速度較快。但是,當出現覆蓋歧義的時候,最大匹配法是無法發現的,對于某些復雜的交叉歧義也會遺漏。
2.1.2 全切分法
全切分算法是利用詞典匹配,獲得一個句子所有可能的切分結果。當句子長度增加時,全切分的結果數也隨之增加,且呈指數增長,對于比較長且包含較多歧義的句子,往往要經過很長的時間才能遍歷完所有的切分路徑。因此該方法的時間開銷非常大,無論是在統計語言模型訓練還是在全文檢索、機器翻譯等實際應用中都是難以接受的。
2.1.3 最短路徑法
最短路徑方法是一種動態規劃算法,它的基本思想是在詞圖上選擇一條詞數最少的路徑,節省了時間開銷,且它相對優于單向最大匹配方法,但是這種方法忽略了所有覆蓋歧義,也無法解決大部分交叉歧義問題。
2.2 基于大規模語料庫的統計方法
這一類方法是目前分詞算法中比較常用的方法,主要是從大規模語料庫中統計得到各種概率信息來指導字符串的切分。基于統計的方法可以借用許多比較成熟的概率模型來實現切分,不需要人工維護規則和復雜的語言學知識,擴展性較好。除了最常見的詞頻統計信息以外,目前常用的幾種其它概率模型主要包括有:
2.2.1 N元語法模型和隱馬爾可夫模型
在N元語法模型中,一個句子可以看成一個連續的字符串序列,即可以是單字序列,也可以是詞序列。N元語法假設一個單詞出現的概率分布只與單詞前面的 1-N 個單詞有關,與更早出現的單詞無關。若一個句子的出現概率用 P (W)表示[6]。則
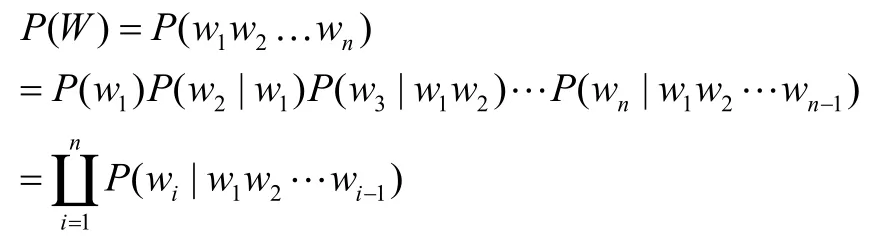
可以看出,N元語法模型認為產生語句W的概率是產生其第一個字的概率,乘以在給定第一個字的條件下產生第二個字的概率,乘以在給定前兩個字的條件下產生第三個字的概率,……乘以在給定前 1-n 個字的條件下產生第n個字的概率。產生第i個字的概率是由已產生的 1-i 個字決定的。
利用大規模的語料庫和成熟的N元語法模型,使用三元語法,在不考慮未定義詞的情況下,就可以將切分的正確率提高到98%以上[7]。
隱馬爾可夫模型是N元語法模型的一種,已廣泛地應用于自然語言處理領域中,比如語音識別、詞性標注等等。在隱馬爾可夫模型中,任一隨機事件都有一個狀態序列和一個觀察值序列隱馬爾可夫模型可以形式化為一個五元組),,,,(πBAOS,其中:

隱馬爾可夫模型很少單獨使用,通常是和詞性標注結合在一起用,它的作用類似于譯碼。在序列分析中,從序列中的每個觀察值去推測它可能屬于哪個狀態。
2.2.2 互信息
互信息用來表示兩個字之間結合的強度,其公式為:
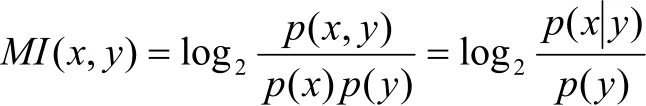
MI越大,表示兩個字之間的結合越緊密。反之,斷開的可能性越大。當x與y關系強時,0),(≥yxMI;當x與y關系弱時,0),(≈yxMI;而當0),(<yxMI時,x與y稱為“互補分布”[8]。
2.3 規則和統計相結合的方法
目前大多數的分詞算法都是采用規則和統計相結合的方法,主要是利用詞典進行初切分,然后用其它的概率統計方法和簡單規則進行消歧和未登錄詞識別。這樣不僅可以降低統計對語料庫的依賴性,充分利用已有的詞法信息,還能彌補規則方法的不足之處。
2.4 人工智能分詞方法
人工智能法,又稱理解分詞法,主要是對信息進行智能化處理的一種模式。主要有兩種處理方式:一種是基于生理學的模擬方法,例如神經網絡,即在模擬人腦的神經系統機構的運作機制來實現一定的功能;另一種是基于心理學的符號處理方法,例如專家系統,即通過模擬人腦的功能,構造推理網絡,經過符號轉換,從而可以進行解釋性處理。以上兩種思路是近年來人工智能領域研究的熱點問題,應用到分詞方法上,產生了專家系統分詞法和神經網絡分詞法。
3 結束語
每一種分詞算法都有各自的優缺點。由于漢語語言知識的籠統和復雜性,對于將各種語言信息組織成機器可直接讀取的形式具有一定的難度,目前基于人工智能的分詞系統還在試驗階段中。
[1] 文孝庭.漢語自動分詞研究進展[J].圖書情報,2005(5):54-62.
[2] 張春霞,郝天永.漢語自動分詞的研究現狀與困難[J].系統仿真學報,2005(17):138-147.
[3] 孫斌.切分歧義字段的綜合性分級處理方法.北京大學計算語言學研究所討論班[EB/OL].http://ccl.pku.edu.cn/doubtfire/nlp/Lexical_Analysis/Word_Segmentation_Tag ging/Chinese_Word_Seg_Tag/seg_tag_BSWEN.htm,199 9-4-13.
[4] 馮玉春,宋濤瀚.Web中文文本分詞技術研究[J].計算機應用,2004,24(4):134-136.
[5] 劉件,魏程.中文分詞算法研究[J].微計算機應用,2008,29(8):12-16.
[6] 龍樹全,趙正文,唐華.中文分詞算法概述[A].電腦知識與技術,2009,5(10):2605-2607.
[7] 高山,張艷,徐波等.基于三元統計模型的漢語分詞標注一體化研究[A].全國第六屆計算機語言學聯合學術會議(JSCL-2001)[C].太原:山西大學,2001.
[8] 張磊,張代遠.中文分詞算法解析[A].電腦知識與技術,2009,5(1):192-193.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
中外會展(2014年4期)2014-11-27 07:46:46
祝您健康(1987年3期)1987-12-30 09:52:32
