一種融合PLSA模型和樹模型的文本病歷語義分析新方法
2013-12-03 02:08:16黃文博
吉林大學學報(理學版) 2013年4期
黃文博,燕 楊,李 博
(1.長春師范大學 計算機科學與技術學院,長春 130032; 2.吉林大學 通信工程學院,長春 130012;3.深圳電信研究院,廣東 深圳 518048)
文本病歷是醫務人員通過文字處理軟件對患者醫療活動過程的記錄,合理并有效地利用文本病歷可為醫務人員提供較客觀的診斷依據及輔助診療信息,也可為探索疾病規律提供重要依據[1].面對“海量”的文本病歷,如何全面、 準確和快速地進行語義提取、 標注與檢索已成為學術界的研究熱點之一.文獻[2]提出利用“面向標引”的關鍵詞語義樹模型對文本進行語義分析,利用該模型可實現淺層語義文本的檢索;文獻[3]提出將PLSA(probability latent semantic analysis,概率潛語義分析)模型用于中文信息檢索,相對于傳統的LSA(latent semantic analysis,潛語義分析)模型提高了檢索的平均精度;文獻[4]提出了LSA-tree(latent semantic analysis-tree,潛語義分析樹)模型,將其應用于醫學文本的自動批注,提高了批注的準確率.
樹模型、 PLSA模型和LSA-tree模型是目前在文本語義分析領域內較主流的研究方向.通過樹模型進行語義分析可挖掘出語義元素的關聯性,如空間分布、 語義相關及相對位置等; 通過PLSA模型進行語義分析可從統計學的角度挖掘文本詞匯間存在的潛在關聯性; LSA-tree模型可較好地完成文本的自動批注.但在對醫學文本數據進行語義分析時,以上語義建模方法存在如下不足:樹模型缺乏從隱含語義的角度對文本數據進行分析; PLSA模型在建模過程中忽略了文本數據中語義元素的結構、 位置和層次等淺層語義特征; LSA-tree模型僅能滿足小規模的醫學文本處理.為了解決醫學文本語義分析技術存在的問題,本文設計一種融合PLSA模型與樹模型的PLSA-tree模型,利用該模型可實現對文本病歷從字面語義到隱含語義的綜合提取并檢索.PLSA-tree模型建模步驟如下:
1) 利用語義窗口對文本進行分割(分詞);
2) 利用樹模型將窗口中的詞劃分為若干子樹,確定核心詞與相關詞;
3) 計算子樹中核心詞與相關詞間的淺層語義參數;
4) 利用PLSA模型計算核心詞之間的關聯性.
本文通過對150份文本病歷語義分解和檢索實驗表明,所設計的PLSA-tree模型可更準確和全面地表達醫學文本數據的語義信息,降低了原LSA模型和LSA-tree模型的復雜度,解決了醫學文本語義消歧問題,提高了檢索匹配率和檢索精度.
1 文本病歷的語義樹建模和PLSA建模
1.1 文本病歷的語義樹建模
文本病歷是由醫務人員自主編寫的敘述性文字,屬半結構化文本,有一定的約束格式,但不完全符合自然語言的語法規則.為便于理解,本文將文本病例中命名實體和描述主體的醫學術語在語義上定義為“核心詞”,將與“核心詞”共同構成完整語義的詞語定義為“相關詞”[5].根據核心詞與相關詞的語義關系,一段包含完整語義的文本可視為核心詞wc與相關詞wRi(i=1,2,…,N)組成的可變階Markov鏈信源[6],語義函數可定義為核心詞與相關詞之間Corr(wc,wRi)的集合,即S(wc)=(Corr(wc,wRi))i=1,2,…,N.
文本病歷中的語法結構通常是由多個短分句構成復句的格式,復句中的分句在語義上存在邏輯關聯,但分句與復句均不能作為單獨的語義被處理,所以在建模前必須利用“語義窗口”對文本進行分割(分詞),分割前需進行如下假設:每個短分句中只包含一個核心詞,且各短分句間的核心詞沒有語義關聯.語義窗口確定的前提是核心詞的篩選,本文采用信息熵算法進行篩選.病歷文本中第i個詞的信息熵為
其中:kit表示詞wi在文本中出現的次數;T表示文本病歷的總數.ρ(i)越大詞wi的信息熵越大,根據信息熵原理[7]:一個醫學術語在一個文本病例中出現次數越多且該醫學術語在多個文本病例中出現次數越平均,則該醫學術語的信息熵越大,其能提供的信息量也就越少,所以利用病歷文本中詞信息熵ρ(i)閾值的方法進行核心詞篩選.
1.2 文本病歷的PLSA建模
文本病歷具有高維性和異質性的特點[8],主要表現為文本的復雜度(維數)高,且對某一固定概念表述的非標準化,即不同醫務人員對同一醫學數據可能會使用不同術語及不同的語法進行表述,不利于文本病歷的分析、 檢索和利用.
PLSA模型可在一定程度上解決文本病歷中的高維性和異質性問題,PLSA模型是LSA模型的改進,PLSA模型隱含的Multi-nomial分布假設更符合文本特性,通過降低文本維度獲取文本病歷和詞之間及文本病歷之間的相似度在低維潛在語義空間中的可靠估計[9],有良好的語義消歧作用.
利用PLSA建立“文本-潛在語義-詞”概率模型,“文本-詞”同現的聯合概率模型如下[10]:
其中:p(di)表示從文本集中選擇第i篇文本的概率;p(zk|di)表示在確定文本di的條件下屬于潛在語義zk的概率;p(wj|zk)表示潛在語義zk在詞wj上的分布概率.
實驗表明,隨著醫學文本集合的增加,PLSA模型語義分析效率明顯下降,所以需要引入并構建概率潛在專業詞典以提高語義分析效率[11].專業詞典用矩陣D表示:D=(D1,D2,…,DW),其中:
式中P(wx|wy)是詞wx對詞wy的概率,每個詞的概率都用PLSA模型概率計算:
其中Z為文檔中所有核心詞的集合.
2 融合PLSA的語義樹建模
針對樹模型和PLSA模型在醫學文本病歷語義分析中的缺點,本文提出融合兩種模型進行建模,利用概率隱含語義函數表達核心詞之間的語義關聯,表示為
其中: Dist表示模型中兩行或兩列的距離;n表示行或列的維數;η表示修正參數.
多層次的語義建模思想應充分結合文檔的結構信息、 構成文檔詞的信息和詞與詞之間的語義關聯信息,所以融合PLSA的語義樹建模思想應該為:句子由在語法層次得到的樹模型表示; 淺層的語義關聯由字面語義信息表示; 深層的語義關聯由PLSA模型表示.
該模型可將文本病例中的語法結構、 字面語義和隱含語義有機融合,通過語義計算文本病例之間、 文本病歷與醫學專業術語及醫學專業術語之間的語義關聯,從而可準確、 全面地的表述文本病歷的語義特征信息.在該模型中,子樹中任意詞之間的語義相關函數Corr(wx,wy)可表示為
其中: 式(1)為兩個詞都在同一子樹的情況; 式(2)為兩個詞都是核心詞的情況; 式(3)為核心詞與相關詞不屬于同一子樹的情況; 式(4)為兩個相關詞不屬于同一子樹的情況.
3 實驗方法與結果分析
實驗使用的操作系統環境為Windows XP,開發軟件為ActivePerl 5.14.2.1402和Matlab7.14; 輔助工具為Notepad++6.2.3.
3.1 語義分解實驗
實驗對象由80位不同的醫務人員編寫的150份文本病歷組成,病歷的文件格式為TXT文件,每次實驗隨機抽取15個文本病歷進行語義計算.
實驗分別根據語義樹模型和PLSA-tree模型(增加專業詞典)對文本病歷進行語義分解.詞典含詞量為通用詞詞典185 769詞,專業詞詞典625詞,停止詞詞典50詞,核心詞詞典65詞.對15個文本病歷進行的分詞對比實驗如圖1所示.實驗結果表明,采用PLSA-tree模型的語義分解精度明顯提高.
此外,語義分解所需的時間是衡量語義模型的一個重要指標,比較PLSA-tree模型和全文PLSA模型兩種方法在分解時間上的區別,結果列于表1.由表1可見,隨著文本病歷數的不斷增加,利用PLSA模型進行語義分解的時間迅速增加,這是因為在語義分解過程中需要分解的詞過多,直接導致矩陣運算的復雜度增加.而利用本文設計的PLSA-tree模型,由于將醫學專業術語的核心詞構成了專業詞典,降低了矩陣運算的復雜度,所以語義分解所用時間和增長幅度都低于PLSA模型.
3.2 語義檢索實驗
語義檢索實驗建立在語義分解實驗的基礎上,實驗分別利用PLSA模型和PLSA-tree模型對已經形成文本病歷的語義數據庫進行檢索.PLSA-tree模型的檢索流程如圖2所示.

圖1 分詞精度Fig.1 Accuracy of words segmentation
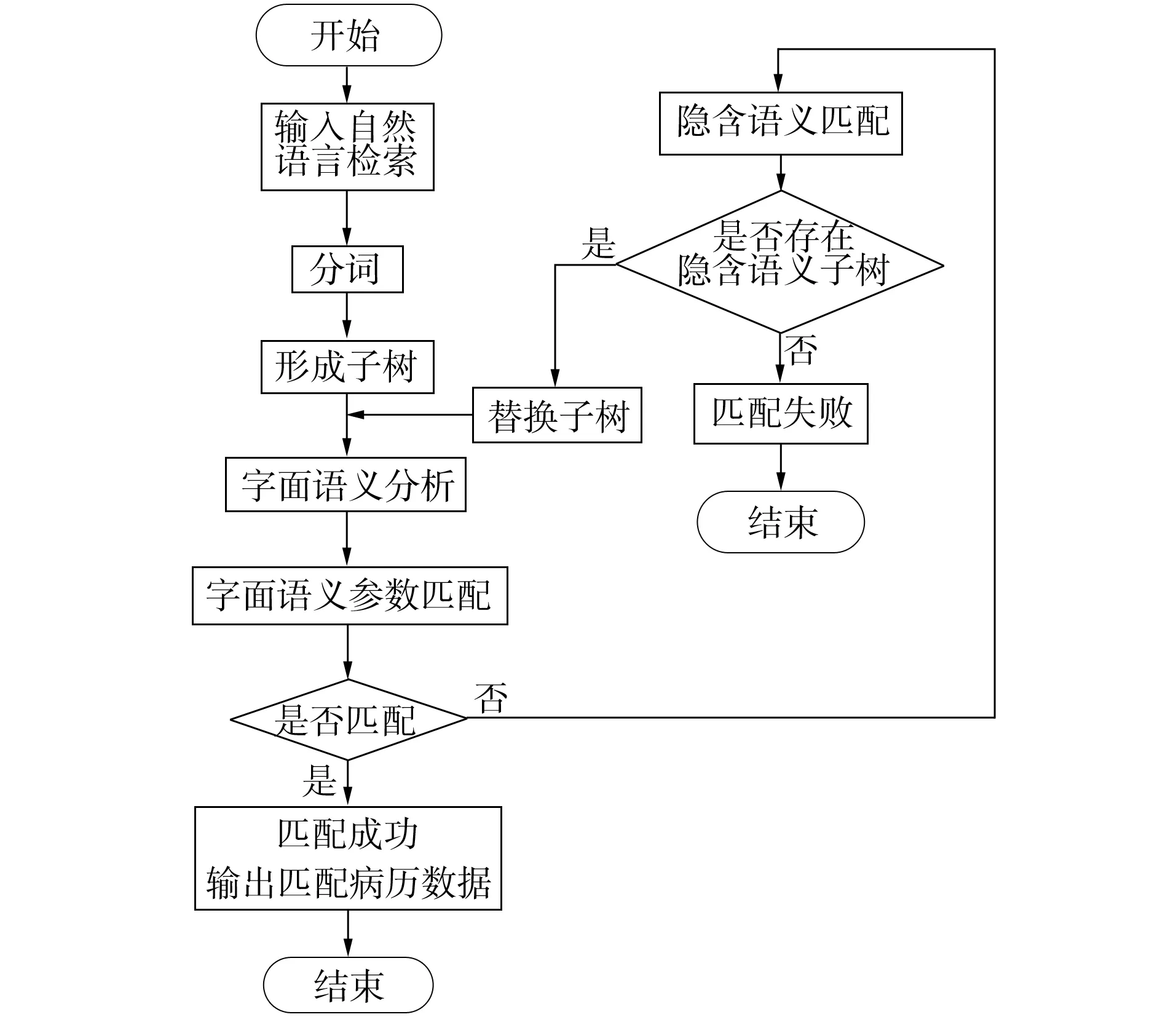
圖2 文本病歷語義檢索流程Fig.2 Semantic retrieval processes of text medical records
查準率和查全率是衡量語義檢索的重要指標:


其中“匹配正確的病例數”和“應該匹配到的病例數”由專業醫務人員參考檢索文字與匹配的結果給出.根據文獻[12]中衡量語義匹配度需要設定評估指標F1測試值:

利用PLSA模型和PLSA-tree模型檢索匹配度結果列于表2.

表1 語義分解時間對比(s)Table 1 Time comparison of semantics segmentation by PLSA and PLSA-tree models (s)

表2 檢索匹配率對比(%)Table 2 Comparison of retrieval matching rate by PLSA and PLSA-tree models (%)
基于PLSA-tree模型檢索的匹配度分散性較高,主要原因是PLSA-tree模型檢索匹配的復雜度和難度隨著輸入檢索文本的長度、 分解子樹數量和替換隱含語義子樹時間等因素的變化而變化,但PLSA-tree模型檢索的匹配度明顯高于當前較主流的PLSA模型的檢索匹配度.
綜上所述,基于文本病歷的語言特點,本文將語義樹模型和PLSA模型融合,解決了文本病歷語義分析過程中存在“多詞一義”的情況,降低了語義維度,簡化了窗口語義樹的結構.通過語義分解和語義檢索實驗進一步驗證了采用PLSA-tree模型的優越性.
[1] 劉全喜.醫療文書規范與管理 [M].鄭州:河南科學技術出版社,2003: 1-2.
[2] ZHAO Jun,JIN Qian-li,XU Bo.Semantic Computation for Text Retrieval [J].Chinese Journal of Computers,2005,28(12):2068-2078.(趙軍,金千里,徐波.面向文本檢索的語義計算 [J].計算機學報,2005,28(12):2068-2078.)
[3] LUO Jing,TU Xin-hui.Chinese Information Retrieval Based on Probabilistic Latent Semantic Analysis [J].Computer Engineering,2008,34(2):199-201.(羅景,涂新輝.基于概率潛在語義分析的中文信息檢索 [J].計算機工程,2008,34(2):199-201.)
[4] LI Bo,WEN Dun-wei,WANG Ke,et al.Automatic Annotation for Medical Texts Based on Hidden Topic and Semantic Tree [J].Journal of Jilin University: Engineering and Technology Edition,2012,42(1):234-239.(李博,文敦偉,王珂,等.基于隱含主題和語義樹的醫學文本自動批注 [J].吉林大學學報: 工學版,2012,42(1):234-239.)
[5] Nelson S,James T,Dan-Sung C,et al.Medical Subject Headings(MeSH) [EB/OL].2011-06-22.http://www.nlm.nih.gov/mesh/.
[6] Ginter F,Suominen H,Pyysalo S,et al.Combining Hidden Markov Models and Latent Semantic Analysis for Topic Segmentation and Labeling:Method and Clinical Application [J].International Journal of Medical Informatics,2009,78(12):e1-e6.
[7] WU Jun,WANG Zuo-ying.The Entropy of Chinese and the Perplexity of the Language Models [J].Acta Electronica Sinica,1996,24(10):69-71.(吳軍,王作英.漢語信息熵和語言模型的復雜度 [J].電子學報,1996,24(10):69-71.)
[8] ZHANG Hao,CUI Lei.Research Advances on Biomedical Knowledge Discovery in Text [J].Journal of Medical Informatics,2008,29(9):5-9.(張浩,崔雷.生物醫學文本知識發現的研究進展 [J].醫學信息學雜志,2008,29(9):5-9.)
[9] Dumais S.Latent Semantic Indexing [C]//The 2nd Text Retrieval Conference.[S.l.]: Department of Commerce,National Institute of Standards and Technology,1994:105-116.
[10] HU Wen-jing.Research of Text Sentiment Classification Based on Semantic Comprehension and PLSA [D].Tianjin:Tianjin Normal University,2012.(胡文靜.基于語義理解與PLSA的文本情感分類研究 [D].天津:天津師范大學,2012.)
[11] LI Sheng,HU He-ping.An Effective Retrieval Method Based on Probabilistic Latent Semantic Analysis [J].Journal of Huazhong University of Science and Technology: Natural Science Edition,2010,38(11):48-50.(李勝,胡和平.一種基于PLSA的高效檢索方法 [J].華中科技大學學報: 自然科學版,2010,38(11):48-50.)
[12] 崔雷.醫學數據挖掘 [M].北京:高等教育出版社,2006:168.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
電子制作(2018年18期)2018-11-14 01:48:06
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
