一種基于XML Schema的XML文檔到關系數據庫的映射方法
2013-12-06 06:49:34賈穎
大眾科技 2013年2期
賈 穎
(山東工商學院 計算機基礎教學部,山東 煙臺 264005)
XML是W3C組織推出的一種半結構化的、自描述的數據描述語言,目前已成為Web上數據表示的標準,并為各種跨平臺、用不同編程語言編寫的應用程序提供了數據交流與分享的工具,同時還成為各種異構數據(關系數據庫、Excel數據表、文本文件)進行數據交換的中間橋梁。可以說,XML技術已經得到了非常廣泛的應用和支持。
隨著XML技術的廣泛應用,XML文檔大量涌現出來。然而,XML文檔本身不是一個數據庫[1],缺乏成熟數據庫技術中關于并發訪問、完整性約束、安全控制等關鍵技術。并且以文檔方式存儲的XML數據支持的關鍵字查詢,查詢方式簡單,查詢能力低,不能滿足復雜條件查詢的需要[2]。所以,XML文檔在存儲和查詢機制上都缺乏系統支持。而關系數據庫仍是目前為止最成熟的數據管理技術。所以,已經有很多學者對XML文檔的關系數據庫存儲做出了研究,提出了結構映射和模式映射兩種主要的方法。由于結構映射保留了 XML文檔的結構和語義信息,成為了XML文檔在關系數據庫存儲的主流技術。結構映射要分析XML文檔的模式信息(DTD或XML Schema)。目前,基于XML Schema的結構映射方法中最具代表性的是Bohannon[3]的提出的P_Schema(Physical XML schema)。P_Schema是從XML Schema變化而來,將原始的XML Schema中的多值元素(元素屬性maxOccurs為unbounded的元素)提取出來,生成同名的新類型,同時,在該元素的父元素中保留對該元素的引用。P_Schema可以直接轉換為關系模式。然而,P_Schma僅進行了對多值元素的提取,沒有考慮其它形式復雜元素的提取,如遞歸嵌套結構、被不同父元素重復引用的元素、可選元素的映射問題,本文將進一步探討對這些類型元素的映射。
1 P-schema的改進
改進的P_Schema模式將XML文檔存儲到關系數據庫的步驟分為三步:第一步,將XML模式轉換為改進過的P_Schema++模式;第二步,將P-Schema++模式用DOM樹表示;第三步,將DOM樹映射為關系數據庫。
1.1 生成P_schema++模式
本文的實例文檔為The Purchase Order ,po.xml[4],對應的XML Schema為po.xsd。[4]數據來源于www.w3.org。表 1給出了 po.xsd的類型標識模式(即 XML Query Algebra ),這種模式因其準確指定了元素和屬性類型,非常有利于XML數據的存儲,將之稱為原始模式。P_schema++模式是基于此模式,進行改進和擴充得到。
從原始的XML Schema類型定義到P_Schema++類型定義的轉換遵循以下幾個原則:
(1)提取用<ComplexType>…</ ComplexType >標識定義的復雜類型為新類型(如PurchaseOrder);
(2)提取元素屬性maxoccurs=unbounded的多值元素為新類型(如items);
(3)提取被多個父元素重復引用的元素為新類型(如USAdress和 comment);
(4)提取用<choice>…</choice>標識的可選元素為新類型(本實例不涉及)。

表1
1.2 DOM樹表示
DOM(Document Object Model)全稱文檔對象模型,是一種與平臺和語言無關的編程接口。[5]一個 XML文檔使用XML分析器分析之后,其中的信息就會被轉化成一棵對象節點樹。在這棵樹中,有且只有一個根節點,其它所有節點都是根節點的后代節點。節點樹生成之后,就可以通過DOM接口訪問、修改、添加、刪除和創建樹中的節點和內容。將P_Schema++轉換為DOM樹表示。在DOM樹中,用符號○表示簡單類型元素的節點,用符號◎表示復雜類型元素的節點,用符號△表示屬性節點。Po.xsd的 P_Schema++轉換為 DOM樹如圖1所示:
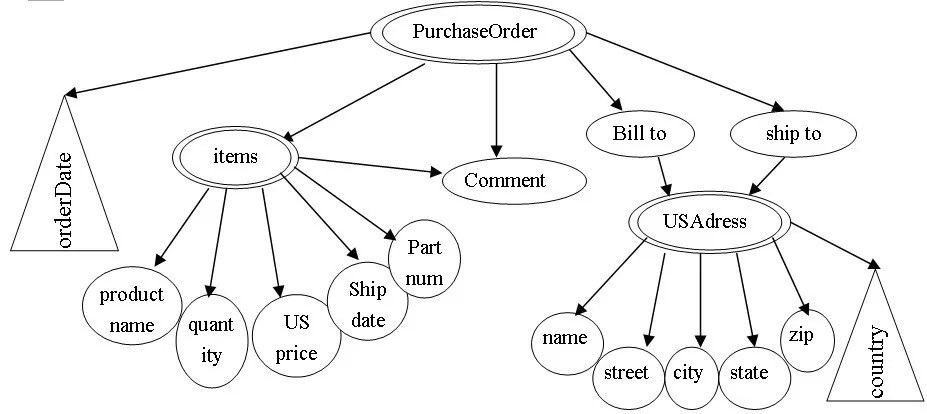
圖1 P_Schema++ DOM樹
得到DOM樹后,尋找DOM樹中子樹的根節點,又叫分級節點[3]。一個節點成為分級節點,必須滿足以下幾個條件之一:①不能由其他節點到達;②復雜類型的節點;③節點的入度>1。根據以上規則,PurchaseOder,items,comment,USAdress為分級節點,要單獨映射為關系。其中Comment節點是簡單類型元素節點,可以分成兩個節點,分別內聯到PurchaseOrder子樹和items子樹中。但考慮到在po.xsd中,PurchaseOrder和Items中對comment的定義都是minoccurs=0,如果將comment作為PurchaseOrder表和items表中的屬性列,應允許NULL值。而comment元素中的數據內容一般比較多,需要為comment列設置較大的字符串長度,而如果有大量的空值,就會造成很大的存儲浪費。所以,本文將comment元素單獨建表,并建立Pid字段作為外鍵,指向父節點。
1.3 映射為關系數據庫
將DOM樹中分級節點映射為關系數據庫中的表,映射的方法為:
(1)為每一棵子樹T創建關系R,把滿足以下條件的節點Y作為R的屬性:Y是T可達到,從T到Y的路徑中不包含任何生成獨立關系的分級節點。
(2)為每個關系R創建Id字段作為主鍵。若T與其他分級節點存在父子關系,則在關系R中添加Pid 字段作為外鍵,記錄其父節點的Id。
根據上面的方法,把DOM樹轉換為4張表:

表2 PurchaseOrde r

表3 comment

表4 items

表5 USAdress
另外,在PurchaseOrder表中,Bill to_id和ship to_id字段分別指向其孩子節點,與USAdress表中Id字段相對應。
2 實驗驗證
為了驗證P_Schema++的有效性和可行性,采用 Microsoft Visual Studio2003和C#語言在Windows內部組件之一的.NET Framework代碼庫中進行XML文檔到SQL Server 2003關系數據庫的轉化。對其存儲代價和查詢代價進行評估,結果發現,該算法生成的關系數據表數目相對較少,表的規模合理,查詢時連接運算少,查詢效率較高。
[1] Bourrent R. XML Data Binging[EB/OL].http://www.rpborrent.com/xml/XMLDataBingding.htm,2010-12-21.
[2] 曾慶玲.基于模式的復雜 XML文檔到關系數據庫存儲的研究[D].桂林:廣西師范大學,2011
[3] Bohannon P, Freire J, Roy P et al.,From XML schema to relations: a cost based approach to XML storage[C].Proc of the18th International Conference on Data Engineering.2002:64 75.
[4] The Purchase Order[EB/OL] .http://www.w3.org/TR/2004/REC-xmlschema-0-20041028/.
[5] 岳歡.XML文檔在數據庫中存儲方案的研究[D].重慶:重慶大學,2003.
