英語口語機考評分系統研究與實現*
2013-12-29 10:32:44汪文棣劉健剛
電子器件 2013年5期
汪文棣,劉健剛,曹 蕾,董 靜,姜 浩
(1.東南大學教務處,南京210096;2.東南大學研究生院,南京210096;3.東南大學外國語學院,南京210096;4.東南大學計算機科學與工程學院,南京210096)
楊晶佩宜在評述大學英語口語考試的文章中認為,大學英語口語考試中的試題設計、考生在考試中的真實表現以及考試評估所存在的差異等仍然值得進一步研究和討論[1]。基于計算機和網絡的大學英語四、六級考試項目于2008年12月20日在全國53所高校實施四、六級網考試點考試。基于計算機的英語口語考試則是英語四、六級網考中一個不可缺少的有機部分。然而,目前四、六級網考中的口語考試部分僅僅涉及“模仿”部分,不能含蓋英語口語考試的全部測試內容,在考試內容設計上存在漏洞[2]。
大學英語口語考試的目的在于測試中國全口制高等院校在校非英語專業大學生英語口語水平。根據全國大學英語考試委員會的規定,英語口語考試時間長度為20 min,考查內容分為三個部分:(1)自我介紹(熱身練習);(2)描述和評論一幅圖畫,并進行討論;(3)指定話題提問。金艷認為大學英語四、六級網考項目的總體目標是建立“以試卷庫為基礎的計算機網絡系統,盡可能在適當時間、適當地點為考生提供以聽力測試為主,包含說讀寫譯測試在內、重點考查英語學習可持續發展能力的計算機考試”[3]。顯然口語測試在大學英語網考中占有一席之地.但是,“跟讀句子”是不能全部替代英語口語測試的全部內容。英語口語測試的內容必須還原于全國大學英語考試委員會規定的英語口語測試內容。
口語考試可以以被定義為“一種能鼓勵人說話并且根據其話語內容進行評估的考核”[4]。對說話人內容的評估顯然在口語考試中占有十分重要的地位,如果在測試中刪除了對內容的評估,那么這樣的口語考試就沒有任何意義,從考試的效度上說是零效度,更談不上可信度。
本文重點研究的是在基于語音識別技術的最新成果,根據全國大學英語考試委員會規定的英語口語測試內容,從技術實現的途徑上提出了一條可行的英語大學英語網考中口語考試的系統模型,從而設法解決英語網考口語單一“模仿評估”的低效度缺陷。
1 基于語種識別的方法實現
基于語種識別方法的實現在英語大學英語網考中口語考試的系統模型設計中很重要。東南大學前幾年試用了高等教育出版社的《大學體驗英語?》,在原則與特點上注重實用口頭和書面表達能力的訓練與培養,以適應中國入世以后對外交往的需要,為英語教學網絡化及使用多媒體等現代化教學手段提供了立體、互動的英語教學環境。《大學體驗英語?》的《聽說教程》首先以簡短的引導語(Leadin),引出單元的主題。引導語后面一系列精美圖片展示了與主題有關的方方面面,為學生提供了聯系自我、“高談闊論”的素材(如圖1所示)。老師則進入管理系統,對學生的學習和在線測試進行管理(如圖2所示)。

圖1 口語測試素材示意圖
圖2 老師管理平臺示意圖
體驗英語《聽說教程》的教學內容和課程體系是東南大學在英語教學和測試改革方面所作的一次大膽嘗試,具有前瞻性和革命性,當然,也存在著技術上的疏漏,包括本節要解決的問題:非英語語種識別問題。我們現在在校的學生大多是80后,創新意識強,具有突出的個性色彩與表達欲望。學生在堂下進行網絡課程自學過程中會進行各種“奇思妙想”,在進行口語測試練習中,根據如圖1所上文提示的英文,不是進行英語回答,而是用中文或老家土語進行回答。于是,一傳十,十傳百,有些勇敢的學生就這個問題向老師提出質疑,懷疑計算機進行口語測試打分的可靠度和可信度。
對于這個問題,本文作者之一劉健剛和董靜老師在2011年8月在本刊上刊登了《英語口語機考系統中語種識別方法的研究》的文章,闡述了幾種語種識別的方法,這里就不累贅敘述。
2 基于語音識別的方法實現
語音識別技術在英語口語網考中占住著最重要的地位。語音識別技術過不去,英語口語網考中對說話人的內容進行評估就無從談起。因此基于語音識別的技術要根據口語評估的要求,在現有成熟技術的條件下,盡可能貼近實際測試內容來展開。
基于特征比較的語音評分機制是英語口語學習系統的核心技術,主要用計算機來自動評斷一個人的英語發音是否標準,并和標準音進行匹配。全國大學英語考試委員會在這方面已經做了大量工作,并得到了實證確認,人、機評分對比的相似率高達82.7%(如圖3所示)。
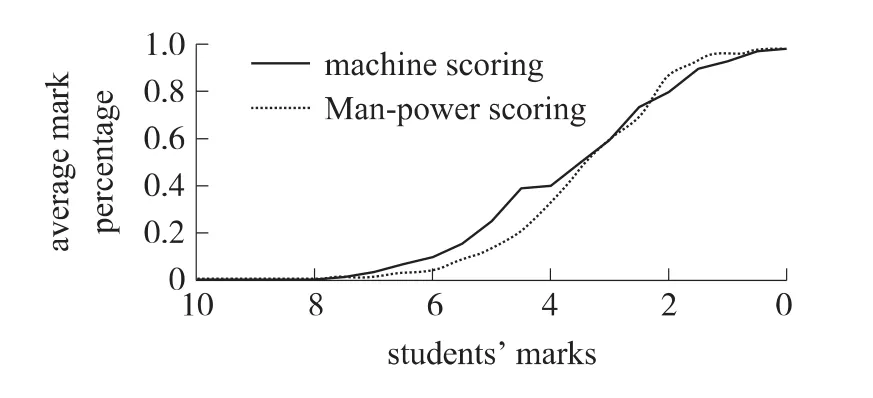
圖3 人、機評分對比相似率示意圖
此方法的實現,通過對受試者的發音進行評價,即對發音段中單個音素(如英語的音素)進行評價,還對超發音段(英語的重音調)、單詞的發音、句子中詞與詞之間的協同發音、句子的語速
和流利程度等進行評價(如圖4所示)[6]。
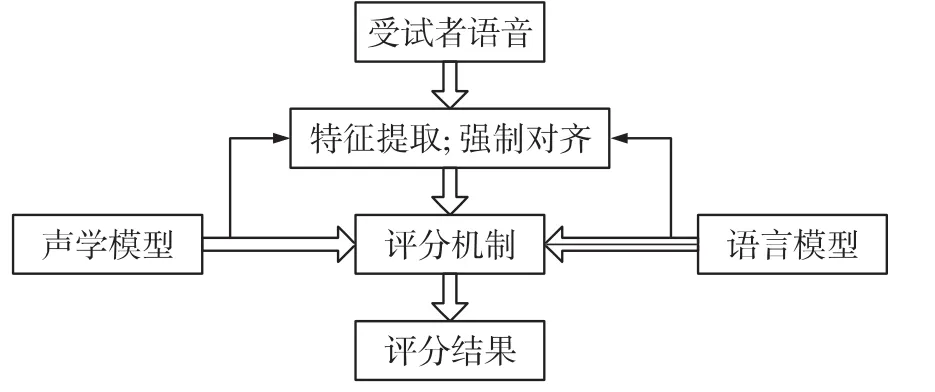
圖4 (語音)跟讀評分實現示意圖
3 語音文本轉換文字文本的方法實現
語音識別系統是建立在語音技術、信號處理、模式識別等學科的有關數學模型基礎上,運用不同的計算機算法來實現的。上世紀90年代初,IBM、Apple、AT&T Bell和NTT等很多大企業都投巨資支持語音識別系統的實用化研究。
客觀地說,隨著3G手機、GPS導航設備等移動通信終端和MP3、電子詞典等便攜式消費電子產品的日益普及,語音識別技術在嵌入式設備中的應用越來越廣泛,但是在教育系統的平臺卻始終落后于市場平臺,直到四、六級網考試點考試開始。即便如此,也僅僅停留在語音匹配的語音識別技術的層面,不敢越雷池一步,惟恐出現事故。
其實在2004年間,馮嘉禮、方紅峰提出的數學模型及軟件編程就已經實現了英語語音轉換成英文文字[7]。其從語音文本到文字文本實現的技術途徑通過對聲音文本的語音(單個詞匯、連續詞匯、寂聲段時長以及聲調)進行處理,將語音標點符號識別出來,從而為計算機轉化文字奠定了語法規范[8]。根據語言語法規范,將識別出來的文字進行準確斷句,然后生成文字(如圖5所示)。目前我國語音識別的技術實現率(未學習的樣本),可以達到72%[7]。

圖5 語音文本轉換文字文本實現途徑示意圖
4 文字文本自動評分的方法實現
在對72%實現率的語音轉換為文字文本后,我們通過數據挖掘的技術就可以對文字文本作自動評分。一般而言,對于文本內容的評估,考慮到受試者表達習慣、知識水平的不同,對同一個概念可能有不同的表達方式,我們采用LSA(Latent Sematic Analyser)的方法來檢測內容。
LSA假設文字文本中存在某種潛在的語義結構。這種潛在的語義結構隱含在文字文本中詞語的上下文使用模式中,可通過利用統計方法獲得。其核心思想是通過奇異值分解,將文檔向量和詞向量投影到一個低維空間,使得相互之間有關聯的文字文本,在沒有相同詞匹配的情況下,也能獲得相同的向量表示[9]。以LSA為模型的文字文本內容評估,基于東南大學外語教學中采集的大量作文集合。從這些大量的作文集合中,采用統計的方法可以計算出那些單詞對于評分較為關鍵。計算機自動提取出那些對評分高低影響較大的單詞項作為特征項,從而來衡量文字文本與英語口語主題內容的相關度。這樣的設計,有效防止了受試者回答問題偏題的棘手問題,也防止了一些與考題無關但語言方面優秀的答案獲取高分評估。
在計算機自動評分系統的平臺上,我們設計了嵌入式軟件,采用了語義詞典WordNet來作為語料庫,用來匹配與關鍵詞語義相關的詞。然后根據在受試者語音文本轉換為文字文本中文字命中率情況來對英語口語的內容方面進行評分。
5 英語口語機考評分系統的實現
系統依托我們開發的第一代智能語音交互技術,主要完成英語口語語音的智能評測和學習功能。測試功能大體上包括口語測試、聽力測試兩大部分;學習功能上主要包括英語朗讀,口語對話兩大部分。圖示如圖6。
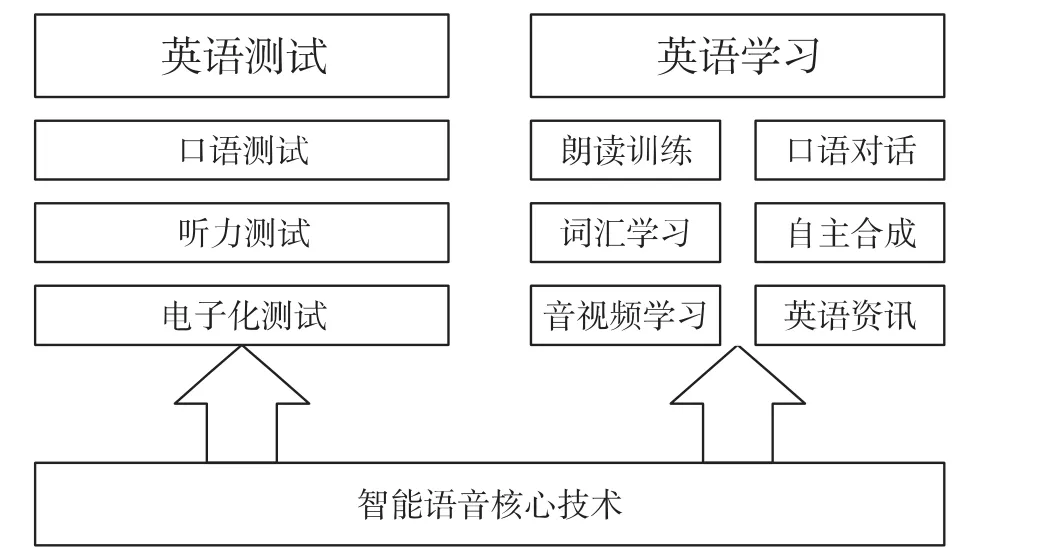
圖6 第一代智能語音交互技術示意圖
為了開發第一代智能語音交互平臺和便于攜帶的英語評分系統,我們把語音識別等功能在基于DSP的硬件系統上進行了實現。系統的DSP采用TMS320C54X系列芯片實現,它是TI公司于1996年推出的16 bit定點低功耗數字信號處理器。它采用先進的修正哈佛結構,片內有8條總線、CPU、片內存儲器和在片外圍電路等硬件,加上高專業化的指令系統和6級深度的指令流水線,使得C54X具有功耗小、高度并行等優點[10]。本系統采用了C54X系列的TMS320C5416定點DSP來實現說話人識別裝置,其結構如圖 7所示。因為TMS320C5416是定點的數字信號處理器,對定點數據處理很快,卻對浮點數據的處理卻很慢。為了能在實際應用中滿足用戶的需求,說話人自動識別系統應能以盡可能快的速度來完成識別過程,最好能達到實時。因此在開發過程中,我們對所有的浮點數據進行定點化,以提高程序執行的效率。C5416 DSP的片上資源有限,片上數據存儲器為64 kbyte,片上程序存儲器也是64 kbyte。為了防止數據空間不夠,在該系統中我們把所有的提示語音存放在程序存儲器里,而所有的碼本及采樣的語音數據都存放在數據存儲器里。
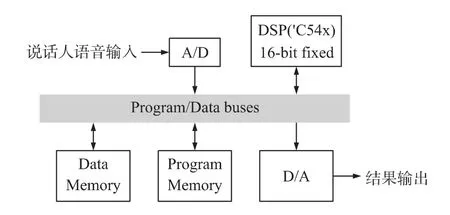
圖7 DSP說話人識別裝置示意圖
系統的實現主要包括語音信號的預處理,特征提取,訓練,測試和實時識別過程。在本設計中需要做的預處理及特征提取是預加重、加窗、分幀、求線性預測分析系數,最后求出LPC倒譜系數和倒譜系數的r階線性回歸系數以及估計基音和差值基音周期。
精度問題在定點DSP中是相當重要的,它將直接影響到識別的效果,為了能使系統有很高的正確識別率同時又不消耗過多的時間和內存資源,我們在開發系統時盡可能地合理分配計算位數,在保住精度的同時減少資源消耗。在定點化的過程中對各模塊進行了定點模擬并分析比較其誤差,確保計算的可靠性。
第1個實驗是非特定人英語連續語音識別實驗。利用日本電子協會標準噪聲數據庫中的行駛中的汽車(2 000 cc組,一般道路)內的噪聲(平穩噪聲)和展覽會中的展示隔間內的噪聲(非平穩噪聲),把這些噪聲按一定的信噪比(SNR)疊加進無噪連續數字語音中組成帶噪語音。識別結果如表1所示。
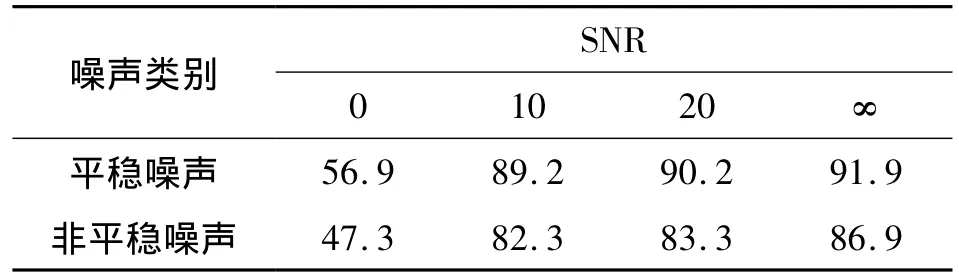
表1 連續英語語音識別結果 %
第2個識別實驗是戶外實際場所的英語語音識別實驗。實驗是利用在學校門口、交通道路和學校食堂3種不同的環境下采集的英語語音進行的。結果是這3種環境下的識別概率分別是86%、80.4%、82.4%,達到了較高的識別精度。
6 結論
文章論述了目前四、六級網考試點考試中口語測試中效度的不足。闡述了英語口語機考應該像傳統的口語測試一樣,檢測評估受試者的語音、語法和內容這幾個方面,而不應該僅僅拘泥于“跟讀”模仿能力的評估。文章提出了英語口語機考評分實現途徑,既通過語種識別、語音識別、語音文本轉換文字文本、文字文本評分四個環節來實現英語口語機考的自動評分。本文提出的方法能夠較好地實現四、六級網考中英語口語評估的難題,對大規模展開英語口語機考具有十分重要的指導作用和現實意義。
[1]楊晶佩宜.大學英語口語考試介評[J].昆明學院學報,2010,32(1):135-137.
[2]Liu Jiangang,Zheng Yuqi,Chen Meihua,et al.A Study on the Feasibility of CET Oral Test Based on Automatic Essay Marking[J].Journal of Southeast University(English Edition),2012,28(4):410-414.
[3]金艷,吳江.大學英語四、六級網考的設計原則[J].外語界,2009,133(4):61-68.
[4]Underhill N.Testing Spoken Language[M].Cambridge:Cambridge University Press,1987:21.
[5]宮力,梁維謙,丁玉國.大規模英語口語考試跟讀題型采用機器閱卷的可行性分析與實踐研究[J].外語電化教學,2009,126:10-21.
[6]黃曉勇,虞維.語音識別技術在外語口語學習中的應用[J].計算機系統應用,2006,6:18-21.
[7]方紅峰,馮嘉禮,韋夢蕓,等.英語語音轉換英文文字的軟件實現[J].哈爾濱工程大學學報,2006,27:584-586.
[8]劉健剛,儲琢佳,趙力.語音文本的標點符號特性初探[J].語言科學,2013,12(2):405-410.
[9]黃濤.四、六級考試英語作文自動評分研究[D].南京:東南大學計算機科學與工程學院,2011.
[10]彭啟.TMS320C54X實用教程[M].成都:電子科技大學出版社,1999:189-215
猜你喜歡
中學生天地(A版)(2022年6期)2022-07-14 12:39:26
大學(2021年2期)2021-06-11 01:13:12
海峽姐妹(2020年12期)2021-01-18 05:53:08
民主與法制(2020年16期)2020-08-24 06:54:50
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
瘋狂英語·新策略(2017年7期)2018-01-03 06:50:36
瘋狂英語·新策略(2017年8期)2017-05-31 08:13:19
小學教學參考(2015年20期)2016-01-15 08:44:38
當代教育實踐與教學研究(2015年2期)2015-02-27 08:03:04
