大數據技術中計算與數據的協作機制
2014-01-05 06:46:28安俊秀
成都信息工程大學學報 2014年1期
王 鵬, 黃 焱, 劉 峰, 安俊秀
(1.成都信息工程學院并行計算實驗室,四川成都610225;2.中國科學院成都計算機應用研究所,四川成都610041;3.中國科學院大學,北京 100049)
0 引言
信息技術的發展越來越清晰地呈現出兩大主題——計算和數據,伴隨這兩大主題,信息技術領域出現了大數據這個技術概念,大數據技術的出現與云計算技術的出現幾乎是同時的,早在1960年John McCarthy預言:“今后計算機將會作為公共設施提供給公眾”[1]這一云計算核心理念,1984年SUN公司董事會主席John Gage提出“網絡就是計算機”[2]這一具有云計算特征的論點,到網絡的繁盛期2006年Google公司CEO Eric Schmidt提出云計算概念,再到2008年云計算概念全面進入中國,網絡技術在云計算發展歷程背后發揮了重要的推動作用。網絡技術的發展促使服務向云端集中,并使數據量出現爆發式增長,因此面向數據成為云計算技術的重要特征之一,在一段時間里云計算和大數據兩個概念甚至被當成同一個概念使用,一些大數據系統如Hadoop也被稱為云計算系統,概念的模糊使不少人產生困惑。嚴格來講,大數據技術是指針對海量數據的存儲、分析和發布技術,而云計算是對資源和服務網絡化提供方式的一種描述,兩個概念之間的區別是很明顯的。大數據系統是一種計算和數據都密集的分布式系統,計算需要為數據分析服務,也可以稱之為面向數據的高性能計算,計算和數據的協作機制是研究這類系統的一個視角。
李國杰院士認為:“信息系統需要從數據圍繞著處理器轉改為處理能力圍繞著數據轉,將計算用于數據,而不是將數據用于計算”[3]。海量數據本身很難直接使用,只有通過處理的數據才能真正成為有用的數據,因此計算和數據兩大主題可以進一步明確為數據和針對數據的計算,計算可以使海量數據成為有用的信息,進而處理成為知識。在大數據系統中存儲不是一個獨立存在的系統,特別是在集群條件下,計算和存儲都是分布式的,如何讓計算“找”到自己需要處理的數據是大數據系統需要具有的核心功能。面向數據要求計算是面向數據的,那么數據的存儲方式將會深刻地影響計算實現的方式。這種在分布式系統中實現計算和數據有效融合從而提高數據處理能力,簡化分布式程序設計難度,降低系統網絡通訊壓力從而使系統能有效地面對大數據處理的機制稱為計算和數據的協作機制,在這種協作機制中計算如何找到數據并啟動分布式處理任務的問題是需要重點研究的課題,在文中這一問題被稱為計算和數據的位置一致性問題。
1 從面向計算到面向數據
1.1 計算機技術向大數據的演進歷程
大數據系統架構的基本設計思想就是面向數據,面向數據可以更準確地稱為“面向數據的計算”,要求系統的設計和架構是圍繞數據為核心展開的,而計算與數據的有效協作是面向數據的核心要求。
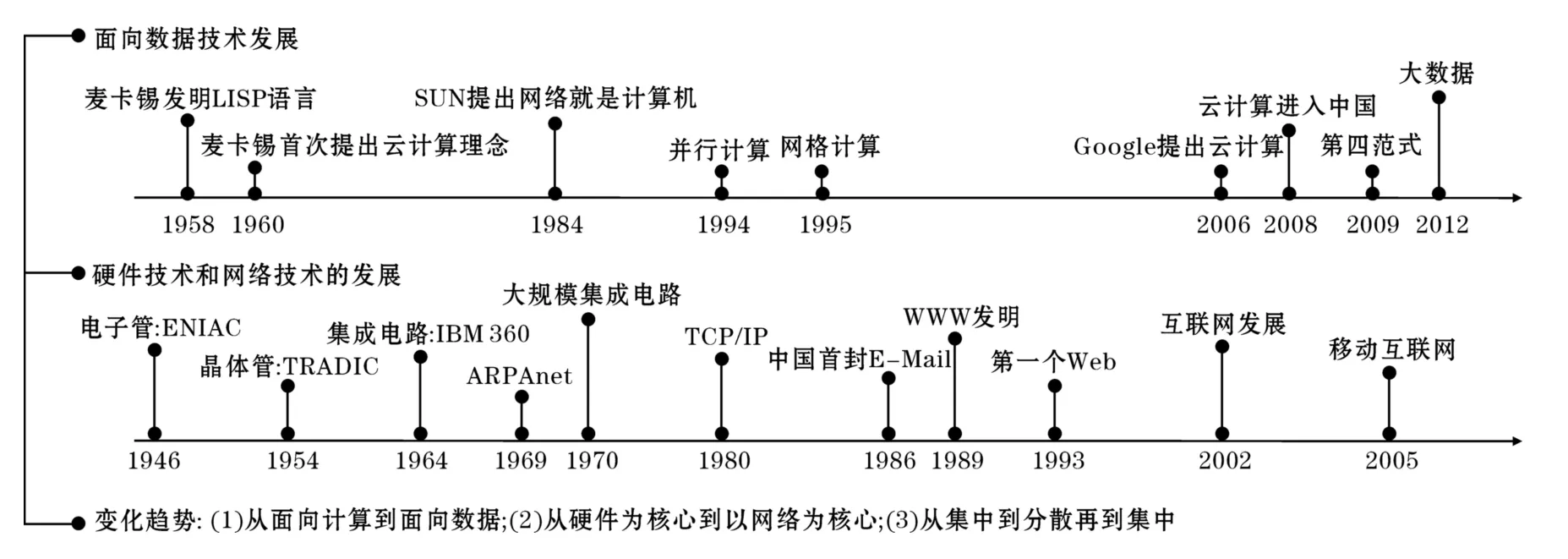
圖1 計算技術向大數據的演進
回顧計算機技術的發展歷程,可以清晰地看到計算機技術從面向計算逐步轉變到面向數據的過程。這一過程的描述如圖1所示,該圖從硬件、網絡和大數據的演進過程等方面以時間為順序進行了縱向和橫向的對比。
從圖1可以看到在計算機技術的早期由于硬件設備體積龐大,價格昂貴,這一階段數據的產生還是“個別”人的工作,這個時期的數據生產者主要是科學家或軍事部門,他們更關注計算機的計算能力,計算能力的高低決定了研究能力和一個國家軍事能力的高低,相對而言由于這時數據量很小,數據在整個計算系統中的重要性并不突出。這時網絡還沒有出現,推動計算技術發展的主要動力是硬件的發展,這個時期是硬件的高速變革時期,硬件從電子管迅速發展到大規模集成電路。1969年ARPANET網絡的出現改變了整個計算機技術的發展歷史,網絡逐步成為推動技術發展的一個重要力量,1989年Tim Berners-Lee發明的萬維網改變了信息的交流方式,特別是高速移動通信網絡技術的發展和成熟使現在數據的生產成為全球人的共同活動,人們生產數據不再是在固定時間和固定地點進行,人們隨時隨地都在產生數據,微博、博客、社交網、視頻共享網站、即時通訊等媒介隨時都在生產著數據并被融入全球網絡中。
從云計算之父John McCarthy提出云計算的概念到大數據之父Gray提出科學研究的第四范式,時間已經跨越半個世紀。以硬件為核心的時代也是面向計算的時代,那時數據的構成非常簡單,數據之間基本沒有關聯性,物理學家只處理物理實驗數據,生物學家只處理生物學數據,計算和數據之間的對應關系非常簡單和直接。到以網絡為核心的時代,數據的構成變得非常復雜,數據來源多樣化,不同數據之間存在大量的隱含關聯性,這時計算所面對的數據變得非常復雜,如社會感知、微關系等應用將數據和復雜的人類社會運行相關聯,由于人人都是數據的生產者,人們之間的社會關系和結構就被隱含到所產生的數據中。數據的產生目前呈現出大眾化、自動化、連續化、復雜化的趨勢,大數據概念正是在這樣的背景下出現,這一時期的典型特征就是計算必須面向數據,數據是架構整個系統的核心要素,這就使計算和存儲的協作機制研究成為需要重點關注的核心技術,計算能有效找到自己需要處理的數據可以使系統能更高效地完成海量數據的處理和分析。
1.2 第四范式——大數據時代的科學研究方法
信息技術領域提出面向數據的概念同時也開始深刻地改變科學研究的模式,2007年著名的數據庫專家Gray提出科學研究的第四范式。他認為利用海量的數據已可以為科學研究和知識發現提供除經驗,理論,計算外的第四種重要方法。科學研究的4個范式的發展歷程也同樣反映了從面向計算走向面向數據的過程。

圖2 科學研究4個范式的發展歷程
如圖2所示,人類早期知識的發現主要依賴于經驗、觀察和實驗,需要的計算和產生的數據都很少,人類在這一時期對于宇宙的認識都是這樣形成的,就像伽利略為了證明自由落體定理,是通過在比薩斜塔扔下兩個大小不一的小球一樣,人類在那個時代知識的獲取方式是原始而樸素的。當人類知識積累在一定程度后,知識逐漸形成了理論體系,如牛頓力學體系,Maxwell的電磁場理論,人類可以利用這些理論體系去預測自然并獲取新知識,這時對計算和數據的需求已經在萌生,人類已可以依賴這些理論發現新的行星,如海王星、冥王星的發現不是通過觀測而是通過計算得到。計算機的出現為人類發現新的知識提供了重要的工具,這個時代正好對應于面向計算的時代,這時可以在某些具有完善理論體系領域利用計算機仿真計算來進行研究,這時計算機的作用主要是計算,例如人類利用仿真計算可以實現模擬核爆這樣的復雜計算。現在人類在一年內所產生的數據可能已經超過人類過去幾千年產生的數據的總和,即使是復雜度為O(n)的數據處理方法在面對龐大的n時都顯得力不從心,人類逐步進入大數據的時代,第四范式說明可以利用海量數據加上高速計算發現新的知識,計算和數據的關系在大數據時代變得十分緊密,也使計算和數據的協作問題面臨巨大的技術挑戰。
2 機群系統中計算和數據的協作機制分析
回顧高性能計算的發展過程可以將高性能計算分為面向計算的高性能計算和面向數據的高性能計算。傳統的高性能計算通常指面向計算的高性能計算,這種系統以實現高速的計算能力為目標;而面向數據的高性能計算以實現對海量數據的存儲和處理為目標。由于他們都需要快速的計算能力所以這兩類系統常常以機群方式實現強大的計算。在機群系統中實施計算都存在計算如何獲得數據的問題,在面向計算系統中這一問題并不突出,在面向數據時代計算和數據的協作機制就成為必須考慮的問題,通常這種機制的實現與系統的架構有緊密的關系,系統的基礎架構決定了系統計算和數據的基本協作模式,下面以常見的分布式機群系統為例對計算和數據的協作機制進行分析對比。
2.1 面向計算的高性能計算
苗向計算的高性能計算系統出現在以硬件為核心的時代,從Cray C-90為代表的并行向量處理機[4]發展到IBM R50為代表的對稱多處理器機(SMP)[5]最終到工作站集群(COW)及Beowulf機群結構,這一過程對應的正是CPU等硬件技術的高速發展,可以采用便宜的工作站甚至通用的PC機來架構高性能系統,完成面向計算的高性能計算任務。
基于消息傳遞機制的并行計算技術MPI(Message-Passing Interface)幫助工作站機群和Beowulf機群實現強大的計算能力,提供了靈活的編程機制。MPI將大量的節點通過消息傳遞機制連接起來,從而使節點的計算能力聚集成為強大的高性能計算,主要面向計算密集的任務。MPI提供API接口,通過MPI-Send()和MPI-Recv()等消息通訊函數實現計算過程中數據的交換。高性能計算是一種較為典型的面向計算的系統,通常處理的是計算密集的工作,因此在基于MPI的分布式系統中并沒有與之匹配的文件系統支持,計算在發起前通過NFS等網絡文件系統從集中的存儲系統中讀出數據并用于計算。基于MPI的分布式系統的典型系統結構如圖3所示。
從圖3知,典型的利用MPI實現的分布式計算系統在發起計算時,首先將計算程序由主節點通過NFS等網絡共享文件系統分發到各子節點內存啟動計算,由于沒有分布式文件系統的支持,MPI一般不能直接從節點存儲設備上讀取數據,計算程序在子節點發起后只有通過網絡共享文件讀取需要處理的數據來進行計算,在這里數據和計算程序一般都是被集中存儲在陣列等專門的存儲系統中。這一過程并沒有計算尋找數據的過程,計算程序只是按設計要求先被分發給所有參與計算的節點。在進行MPI并行程序設計時,程序設計者需要事先將計算任務本身在程序中進行劃分,計算程序被分配到節點后根據判斷條件啟動相應的計算工作,計算中需要進行節點間的數據交換時通過MPI提供的消息傳遞機制進行數據交換。由于CPU的運行速度遠遠大于網絡數據傳輸的速度,通常希望不同節點間的任務關聯性越小越好,在MPI的編程實踐中就是“用計算換數據通訊”的原則,使系統盡可能少的進行數據交換。MPI的消息傳遞機制為計算的并行化提供了靈活的方法,但目前對于任意問題的自動并行化并沒有非常有效的方法,因此計算的切分工作往往需要編程人員自己根據經驗來完成,所以這種靈活性是以增加編程的難度為代價的。
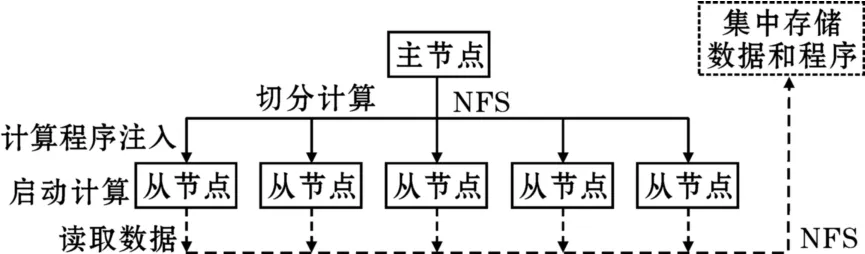
圖3 MPI的典型系統架構
基于MPI的高性能計算是一種典型的面向計算的分布式系統,這種典型的面向計算的系統往往要求節點的計算能力越強越好,從而降低系統的數據通訊代價。MPI的基本工作過程可以總結為:切分計算,注入程序,啟動計算,讀取數據。MPI雖然是典型的面向計算的分布式系統,但它也有類似于后來Google系統中的MapReduce能力,如MPI提供MPI-Reduce()函數實現Reduce功能[6],只是沒有像GFS這樣的分布式文件系統的支持,MPI的Reduce能力是相對有限而低效的,并不能實現計算在數據存儲位置發起的功能。
通常將MPI這樣以切分計算實現分布式計算的系統稱為面向計算的高性能計算系統。這種系統計算和存儲的協作是通過數據向計算的遷移實現,也就是說系統先定位計算節點再將數據從集中存儲設備通過網絡讀入計算程序所在的節點,在數據量不大時這種方法是可行的,但對于海量數據讀取這種方式會很低效。
2.2 面向數據的高性能計算
進入網絡高速發展的時期,數據的產生成為了全民無時無刻不在進行的日常行為,數據量呈現出爆炸式增長,大數據時代到來,數據的作用被提到很高的地位,人們對數據帶來的知識發現表現出強烈的信心。長期以來數據挖掘技術的應用一直都處于不溫不火的狀態,大數據時代的到來也使這一技術迅速地被再次重視起來,基于海量數據的挖掘被很快應用于網頁數據分析、客戶分析、行為分析、社會分析[7],現在可以經常看到被準確推送到自己電腦上的產品介紹和新聞報道就是基于這類面向數據的數據挖掘技術。基于數據切分實現分布式計算的方法被稱為數據并行(data parallel)方法,但在面向計算時代真正的問題在于計算和數據之間只是簡單的協作關系,數據和計算事實上并沒有很好的融合,計算只是簡單地讀取其需要處理的數據而已,系統并沒有太多地考慮數據的存儲方式,網絡帶寬的利用率等問題。
通過數據切分實現計算的分布化是面向數據技術的一個重要特征,2003年Google逐步公開了它的系統結構,Google的GFS文件系統實現了在文件系統上就對數據進行了切分,這一點對利用MapReduce實現對數據的自動分布式計算非常重要,文件系統自身就對文件施行了自動的切分完全改變了分布式計算的性質,MPI、網格計算都沒有相匹配的文件系統支持,從本質上看數據都是集中存儲的,網格計算雖然有數據切分的功能,但只是在集中存儲前提下的切分。具有數據切分功能的文件系統是面向數據的分布式系統的基本要求。
2004年Jeffrey Dean和Sanjay Ghemawat描述了Google系統的MapReduce框架[8],與MPI不同這種框架通常不是拆分計算來實現分布式處理,而是通過拆分數據來實現對大數據的分布式處理,MapReduce框架中分布式文件系統是整個框架的基礎,如圖4所示。這一框架下的文件系統一般將數據分為64MB的塊進行分布式存放,需要對數據進行處理時將計算在各個塊所在的節點直接發起,避免了從網絡上讀取數據所耗費的大量時間,實現計算主動“尋找”數據的功能,大大簡化了分布式處理程序設計的難度。在這里數據塊被文件系統預先切分是MapReduce能自動實現分布式計算的重要前提,系統通過主節點的元數據維護各數據塊在系統中存儲的節點位置,從而使計算能有效地找到所需要處理的數據。MapReduce這種大塊化的數據拆分策略非常適合對大數據的處理,過小的數據分塊會使這一框架在進行數據處理時的效率下降。這一框架在獲得良好的大數據并行處理能力的時候也有其應用的局限,MapReduce框架在對同類型大數據塊進行同類型的計算處理時具有非常好的自動分布式處理能力,但在數據較小、數據類型復雜、數據處理方式多變的應用場景卻效率相對低下。為了實現Google系統良好的計算和數據的協作機制GFS和MapReduce是密不可分的,沒有GFS支持單獨的采用MapReduce是沒有太大價值的。
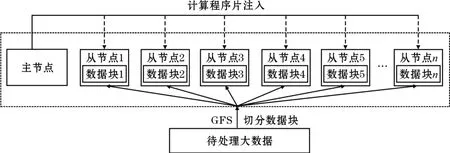
圖4 基于數據切分的分布式系統結構
MapReduce框架使計算在機群節點中能準確找到所處理的數據所在節點位置的前提是所處理的數據具有相同的數據類型和處理模式,從而可以通過數據的拆分實現計算向數據的遷移,事實上這類面向數據系統的負載均衡在其對數據進行分塊時就完成了,系統各節點的處理壓力與該節點上的數據塊的具體情況相對應,因此MapReduce框架下某一節點處理能力低下可能會造成系統的整體等待形成數據處理的瓶頸。在MapReduce框架下節點服務器主要是完成基本的計算和存儲功能,因此可以采用廉價的服務器作為節點,這一變化改變了人們對傳統服務器的看法。2005年Apache基金會以Google的系統為模板啟動了Hadoop項目,Hadoop完整地實現了上面描述的面向數據切分的分布式計算系統,對應的文件系統為HDFS[9],Hadoop成為了面向數據系統的一個被廣泛接納的標準系統。類似的如HPCC(High Performance Computing Cluster)系統則不是通過基于數據塊的數據分割而是通過基于記錄的數據分割來實現對數據的分布式計算,但進行數據分割的方法都是一樣的。
同時數據分析技術是面向數據的高性能計算的研究熱點。對類似于Web海量數據的分析需要對大量的新增數據進行分析,由于MapReduce框架無法對以往的局部,中間計算結果進行存儲,MapReduce框架只能對新增數據后的數據集全部進行重新計算,以獲得新的索引結果,這樣的計算方法所需要的計算資源和耗費的計算時間會隨著數據量的增加線性增加。Percolator是一種全新的架構,可以很好地用于增量數據的處理分析,已在Google索引中得到應用,大大提升Google索引更新速度[10],但與MapReduce等非增量系統不再兼容,并且編程人員需要根據特定應用開發動態增量的算法,使算法和代碼復雜度大大增加。Incoop[11]提出增量Hadoop文件系統(Inc-HDFS),HDFS按照固定的塊大小進文件劃分,而Inc-HDFS則根據內容進行文件劃分,當文件的內容發生變化時,只有少量的文件塊發生變化,大大減少了Map操作量。
迭代操作是PageRank、K-means等Web數據分析的核心操作,MapReduce作為一種通用的并行計算框架,其下一步迭代必須等待上一步迭代完成并把輸出寫入文件系統才能進行,如果有終止條件檢查也必須等待其完成。同時,上一步迭代輸出的數據寫入文件系統后馬上又由下一步迭代讀入,導致了明顯的網絡帶寬,I/O、CPU時間的浪費。iHadoop在分析了迭代過程存在的執行相關,數據相關,控制相關之后對潛在的可并行性進行挖掘,提出了異步迭代方式,比Hadoop實現的MapReduce執行時間平均減少了25%[12]。Twister對MapReduce的任務復用、數據緩存、迭代結束條件判斷等進行調整以適合迭代計算,但其容錯機制還很欠缺[13]。
Pregel是Google提出專用于解決分布式大規模圖計算的計算模型[14],適合計算FaceBook等社交關系圖分析,其將處理對象看成是連通圖,而MapReduce將處理對象看成是Key-Value對;Pregel將計算細化到頂點,而MapReduce將計算進行批量化,按任務進行循環迭代控制[15]。
在分布式文件系統條件下數據的切分使對文件的管理變復雜化,因此此類集群系統下文件系統的管理和數據分析是需要進行重點關注的研究領域之一,面向數據的高性能計算系統就是大數據系統。
2.3 兩種高性能計算系統的分析對比

表1 兩種高性能計算系統的對比
從面向計算發展到面向數據,分布式系統的主要特征發生了變化,表1對面向計算的高性能計算系統和面向數據的高性能計算系統進行了對比和分析。面向數據的高性能計算系統往往有對應的分布式文件系統的支持,從文件存儲開始就實現數據塊的劃分,為數據分析時實現自動的分布式計算提供了可能,計算和數據的協作機制在面向數據的系統中成為了核心問題,其重要性凸現出來。
由于面向計算的高性能計算系統具有靈活和功能強大的計算能力,能完成大多數問題的計算任務,而面向數據的高性能計算系統雖然能較好地解決海量數據的自動分布式處理問題,但目前其仍是一種功能受限的分布式計算系統,并不能靈活地適應大多數的計算任務,因此現在已有一些研究工作在探討將面向計算的高性能計算系統與面向數據高性能計算系統進行結合,希望能在計算的靈活性和對海量數據的處理上獲得良好的性能。文獻[16]初步探討了MPI和Hadoop結合問題,Amazon EC2也發布了面向高性能計算的解決方案CCI(Cluster Compute Instances),文獻[17]利用標準測試程序對比了在Amazon EC2 CCI上實現的云計算模式的高性能計算和在本機群上實現的高性能計算之間的性能。文獻[18]討論了將MPI應用于處理數據密集問題的可能性,將MPI的消息傳遞機制和Hadoop RPC進行對比,Hadoop RPC使Hadoop具有消息傳遞機制,這使其分布式編程能力變得更加靈活,但目前來說與MPI相比還有一定的差距。文獻[19]探討了采用MPI的機制實現MapReduce的可能性。可以看到目前技術的發展正在使面向計算和面向數據的系統之間的界限越來越不明確,很難準確地說某一個系統一定是面向計算的還是面向數據的系統,數據以及面向數據的計算在大數據時代到來時已緊密地結合在一起。
3 實現計算和數據協作機制的方法
面向數據的系統通常是分布式系統,往往是計算向數據遷移從而降低數據在系統中傳輸的通信代價,實現計算尋找數據,定位計算的前提是定位數據,而且數據存儲和切分的方式又會影響計算(數據分析)的處理效率和模式,因此實現計算和數據的有效協作首先需要研究數據在分布式文件系統中的存儲方法,同時由于在分布式系統中需要解決數據的備份、冗余、節點失效處理等問題,這給研究計算和數據的協作機制提出巨大的挑戰。由于計算和數據的位置一致性是協作機制的核心研究內容,下面主要從解決計算和數據位置一致性的角度進行討論。
3.1 計算和數據位置一致性的映射模型
在分布式系統中計算和數據的位置一致性問題可以等效地理解為將計算和數據映射到同一個節點位置上,也就是說使計算在數據存儲的位置發起。例如網格計算系統就是計算先于數據到達客戶節點,數據根據客戶端請求被映射到指定的客戶端進行處理;Hadoop系統是數據先于計算被存儲于分布式系統的某一個節點,計算發起時通過元數據查詢獲得數據的存儲位置,Map任務被映射到相應的節點進行處理。因此可以把計算和數據的位置一致性問題抽象為如圖5的映射模型。數據和計算的映射過程其實就是數據到節點的映射過程,計算程序片和數據片按照一定的映射規則定位到節點,將數據和計算注入節點,當集群節點發生失效時,數據片按規則進行數據遷移和備份,計算程序片則按照相應的規則重新映射到其對應的節點。
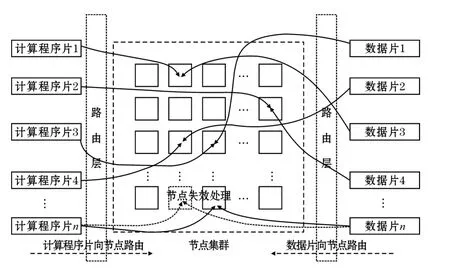
圖5 計算和數據位置一致性的映射模型
在這個模型中計算本身也被視為一種特殊數據,因為計算其實就是某種程序語言設計的可執行程序片,在被系統映射時可以與數據同等對待,而且計算程序中往往包含了其所要處理的數據的邏輯位置信息。分布式文件系統中定位數據塊的算法其實就是起到了將數據映射到相應的節點上的功能。所以在前面講到要實現計算和數據的位置一致性系統必須要有相應的分布式文件系統的支持。同時由于分布式系統存在數據冗余、計算遷移、存儲遷移等問題,在具體實現時會與節點負載均衡調度算法、存儲冗余技術(如副本策略、糾刪碼)[20]等技術相結合,實現一個計算和數據有效協作條件下的健壯穩定的高可用系統。相應典型的映射方法可以分為元數據映射方法,哈希映射方法。
3.2 元數據映射方法
元數據映射方法是最容易想到的實現計算和存儲位置一致性的方案,元數據方法通過在元數據庫中保存數據塊的存儲位置,使計算按照元數據庫中的位置被映射到指定的存儲節點上。元數據方法實現數據和計算的定位非常類似于網絡路由中的路由表,計算和數據通過查詢路由表來保證計算和數據能被分配到同一個節點。采用元數據方法的分布式系統通常是主從結構,單點失效對系統的影響較為嚴重,GFS、HDFS的結構就是采用元數據方法構建,在Hadoop中的Namenode就是負責存儲元數據的管理節點,元數據方法系統在存儲數據時的策略通常會根據各節點當前的存儲負載來判斷,為了避免主從結構對單節點失效的敏感,文獻[21]通過元數據復制方法實現Hadoop系統的高可用性,Hadoop也可以通過Zookeeper組件利用主備機方案來提升系統的可用性。
采用元數據方法可以較為容易地利用集群系統當前的工作狀態作為依據實現分布式系統負載均衡,這時主節點會根據監控系統獲得的數據利用一定的調度算法對數據的存儲和計算的進行分配實現系統的負載均衡,并將相應的分配信息作為元數據進行保存。不少針對集群負載均衡的算法都可以用在元數據方法中作為主節點分配資源的依據,這類方法學者已進行了較為充分的研究。例如,文獻[22]研究了由海量不同性能的PC構成的異構集群的負載均衡算法,使弱計算節點不再成為異構集群的性能瓶頸;文獻[23]提出了一種基于分布式架構的動態自適應集群負載均衡算法,該算法具備在線負載預測機制,通過調整負載信息的采樣方式,有效降低網絡交換壓力,提高算法響應速度;文獻[24]提出了一種基于認知可信模型的動態優先級調度算法,確保任務在安全的環境中運行,提高了集群任務分配的成功率;文獻[25]總結了3種分布式集群負載均衡算法:蜂群算法、隨機抽樣算法和動態聚集算法,比較分析了使用這3種算法時集群性能與節點數和節點性能的關系;文獻[26]提出一種基于指數平滑預測的加權最小連接算法,根據系統的當前任務對集群的負載進行動態預測,提高集群的資源使用率;文獻[27]提出了一種基于遺傳算法的任務調度策略,將智能算法運用于集群調度。
元數據映射方法雖然在面對網絡信息搜索這類大塊數據應用時特別有效,也非常便于大量成熟的負載均衡算法的應用,但在面對有大量小文件的系統時由于元數據服務器需要維護大量的路由數據,查詢的效率會變低。
3.3 哈希映射方法
哈希算法是一種從稀疏值范圍到緊密值范圍的映射方法,在存儲和計算定位時可以被看作是一種路由算法,通過這種路由算法文件塊能被唯一地定位到一個節點的位置。傳統的哈希算法容錯性和擴展性都不好,無法有效地適應面向數據系統節點的動態變化。1997年David Karger提出了一致性哈希算法來定位數據[28],實現了機群系統在節點變化時的單調性,實現了較小的數據遷移代價。Amazon的云存儲系統Dynamo改進了基本的一致性哈希算法,引入虛擬節點,使系統具有更加均衡的存儲定位能力。Facebook開發的Cassandra系統也采用了一致性哈希算法的存儲管理算法。一致性哈希算法及其改進算法已成為分布式存儲領域的一個標準技術。使用一致性哈希算法的系統無需中心節點來維護元數據,解決了元數據服務器的單點失效和性能瓶頸問題,但對于系統的負載均衡和調度節點的有效性提出了更高的要求。
一致性哈希算法的基本實現過程為:對Key值首先用MD5算法將其變換一個長度32位的16進制數值,再用這個數值對232取模,將其映射到由232個值構成的環狀哈希空間,對節點也以相同的方法映射到環狀哈希空間,最后Key值會在環狀哈希空間中找到大于它的最小的節點值作為路由值。
基于一致性哈希的原理可以給出計算和存儲的一致性哈希方法,從而使計算能在數據存儲節點發起。對于多用戶分布式存儲系統來說:“用戶名+邏輯存儲位置”所構成的字符串在系統中是唯一確定的,如屬于用戶wang,邏輯存儲位置為/test/test1.txt的文件所構成的字符串“wang/test/test1.txt”在系統中一定是唯一的,同時某一個計算任務需要對test1.txt這個文件進行操作和處理,則它一定會在程序中指定用戶名和邏輯位置,因此存儲和計算test1.txt都利用相同的一致性哈希算法就能保證計算被分配的節點和當時存儲test1.txt文件時被分配的節點是同一個節點。
現在以下面這個應用場景為例,說明一致性哈希算法實現計算和存儲位置一致性的方法:
(1)面向相對“小”數據進行處理,典型的文件大小為100MB之內,通常不涉及對文件的分塊問題,這一點與MapReduce框架不同;
(2)待處理數據之間沒有強的關聯性,數據塊之間的處理是獨立的,數據處理是不需要進行數據塊之間的消息通訊,保證節點間發起的計算是低偶合的計算任務;
(3)程序片的典型大小遠小于需要處理的數據大小,計算程序片本質上也可以看作是一種特殊的數據,這一假設在大多數情況下成立;
(4)數據的存儲先于計算發生。
根據一致性哈希算法的基本原理在面向數據的分布式系統中計算和存儲位置一致性方法如圖6所示,其主要步驟如下:
(1)將服務器節點以IP地址用為Key值,以一致性哈希方法映射到哈希環上;
(2)在數據存儲時以(用戶名+文件邏輯位置)作為唯一的Key值,映射到哈希環上,并順時針找到離自己哈希值最近的節點作為實際數據存儲的位置;
(3)在發起計算任務時提取計算任務所要操作的數據對應的(用戶名+文件邏輯位置)值作為Key值,映射到哈希環上,并順時針找到離自己哈希值最近的節點注入程序并發起計算的節點。由于相同用戶的相同數據其(用戶名+文件邏輯位置)在一致性哈希算法作用下一定會被分配到相同的節點,從而保證了計算所發起的節點剛好就是計算所需要處理的數據所在的節點。
在這種算法的支持下只要計算程序片需要處理的數據邏輯位置是確定的,系統就會將計算程序片路由到數據存儲位置所在的節點,這時節點間的負載均衡性是由數據分布的均衡化來實現。
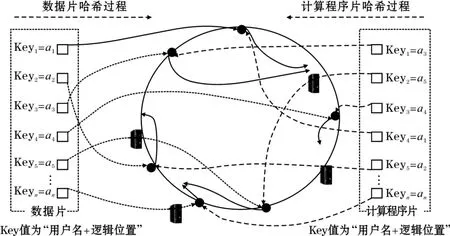
圖6 一致性哈希算法實現計算與數據的位置一致性
一致性哈希算法可以實現無中心節點的計算和數據定位,使計算可以唯一地找到其所要處理和分析數據,使計算能最大可能地在數據存儲的位置發起,節約大量的網絡資源,同時避免了系統單點失效造成的不良影響,利用一致性哈希方法在面對海量文件時系統不用維護一個龐大的元數據庫用于保存文件的存儲信息,計算尋找數據的速度非常直接,路由算法復雜度低。
4 計算和數據的流式拓樸協作機制
多數大數據系統(如Hadoop,HPCC)的實現都是以非實時批處理方式進行的,在實時處理領域不能有效的發揮作用,實時大數據系統的出現填補了大數據系統在實時處理上的弱點,Storm就是一種較為典型的實時大數據處理系統。
4.1 典型的流式分布式系統——Storm系統
在高性能數據處理中流水線(pipelining)技術[29]是一項重要的并行技術,基本思想為:將一個任務 t分成一系列有先后關系的子任務t1,t2…,tm,在流水線模式中ti任務的啟動依賴于ti-1任務的完成。對于數據具有強的先后相關性的數據分析任務十分適用。采用流式技術作為分布式系統計算和數據協作機制的框架,已越來越顯示出其靈活性和生命力,與Dynamo和MapReduce等采用的技術形成鼎立的關系,微軟發布Dryad[30]就是將任務表示為一個有向無環圖(Directed Acycline Graph,DAG)實現分布式任務設計,與其相似的開源實現Storm中采用的Topology也是這種模式,本節以Storm為例進行介紹。
Storm是由Twitter推出的面向實時應用的流式分布式系統[31],集群由一個主節點和多個工作節點組成,主節點用于分配代碼,布置任務及故障檢測。
如圖7所示,Storm要完成一個實時計算任務需要建立一個Topology,Topology對數據處理的邏輯計算規劃,在Storm系統中數據流的基本單位為元組tuple,tuple可以看作是一個被封裝的數據結構,Storm最高一級的執行單元就是Topology,Topology是由一個個計算節點構成的拓撲,拓撲上的每一個節點完成一定的計算邏輯,圖中的箭頭表示數據的流向。流水線技術也叫管道技術,所以Storm的設計者把數據流的生成器叫做Spout,把每一個處理位置叫做Bolt。由于Spout是數據流的源頭,Spout讀取數據并形成流傳送給Bolt,Bolt可以接收任意多個輸
入流,并對流中的數據進行特定的處理。相比在高性能計算領域傳統的流水線并行化技術,Storm采用Topology結構后使數據處理更為靈活功能更為強大。在Storm中主節點依據Topology的邏輯任務圖分配Bolt任務,最終的任務會被分配到相應的物理節點上。從Storm的架構上看,在計算和數據協作機制的處理上Storm是由主節點依據Topology進行物理分配,元組tuple數據流按Topology的描述逐步被相應Bolt節點上的計算程序所處理,并由主節點將這一邏輯過程映射為物理節點的順序。
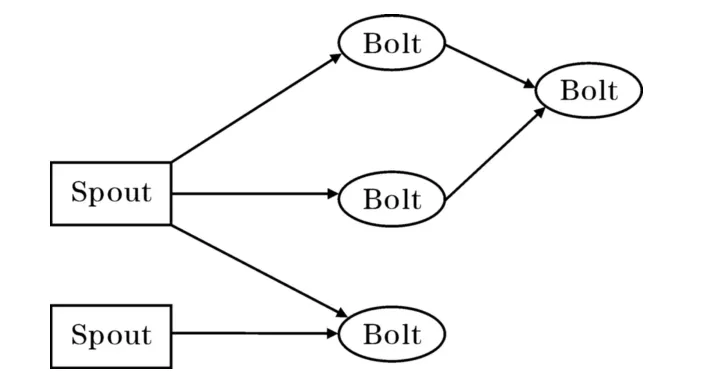
圖7 Storm的Topology結構示意
4.2 計算和數據協作機制的流式拓樸映射模型
Storm的系統結構提示利用類似Topology這樣的邏輯結構可以靈活地實現非常復雜的分布式數據處理任務。圖8將計算和數據協作機制的流式拓樸映射方法進行了抽象,在這種方法中Topology相當于是對一個計算任務的邏輯規劃,并不直接對應于物理節點,系統的主節點可能維護大量的這種Topology結構,每一個Topology結構都相當于是處理某一個問題的邏輯規劃。Topology結構幾乎可以描述大多數問題的處理方法。圖中的操作相當于是Storm系統的Bolt,數據發生器相當于是Spout。系統主節點監控和管理著大量的處理節點,對于每一個維護的Topology邏輯規劃主節點都會依據一定的策略為其分配相應的物理節點以完成指定的計算任務。如圖8中所示,主節點為操作1分配物理節點1,為操作2分配物理節點2,為操作3分配物理節點3,為操作4分配物理節點1,這種分配完畢后Topology邏輯結構就被映射為集群中的物理結構,并能實際地完成相應的計算任務。作為編程人員只需要定義問題的Topology邏輯,Topology邏輯物理映射工作由主節點上的系統來維護,程序設計人員不用擔心節點的失效問題,因為當某一操作對應的節點失效時,主節點會將對應的操作重新映射給一個完好的物理節點,從而保證整個Topology規劃能順利地執行。
下面舉例說明Topology的映射過程,定義操作1是對輸入整型數據流的加2計算并輸出,操作2是對輸入整型數據流的加3計算并輸出,操作3是對輸入整型數據流的乘2計算并輸出,操作4是對輸入整型數據流的乘3計算并輸出,數據發生器不斷的產生整型數據。按照這一Topology的邏輯規劃,系統將操作1的計算程序注入物理節點1,操作2的計算程序注入物理節點2,操作3的計算程序注入物理節點3,操作4的計算程序注入物理節點1,并按Topology描述的流向建立節點1和節點2之間的流消息傳遞機制,節點3和節點1之間的流消息傳遞機制。啟動運算后如數據發生器1生成一個整型數據5后,節點1對其加2后將結果7傳送給節點2,節點2將其加3后輸出結果10,同時根據Topology的描述數據發生器1的數據也會送給節點3,節點3對其乘2后將結果10傳送給節點1,節點1將其乘3后輸出最后結果為30。數據發生器2產生的數據處理方法與此相似。
可以看出利用計算和數據協作機制的流式拓樸映射方法集群系統可以根據Topology的描述自動組合成不同的集群計算結構,從而能靈活面對復雜問題的處理。在這里主節點起到計算和數據的路由工作,計算和數據的協作機制就是依據Topology的描述來跟蹤定位的。
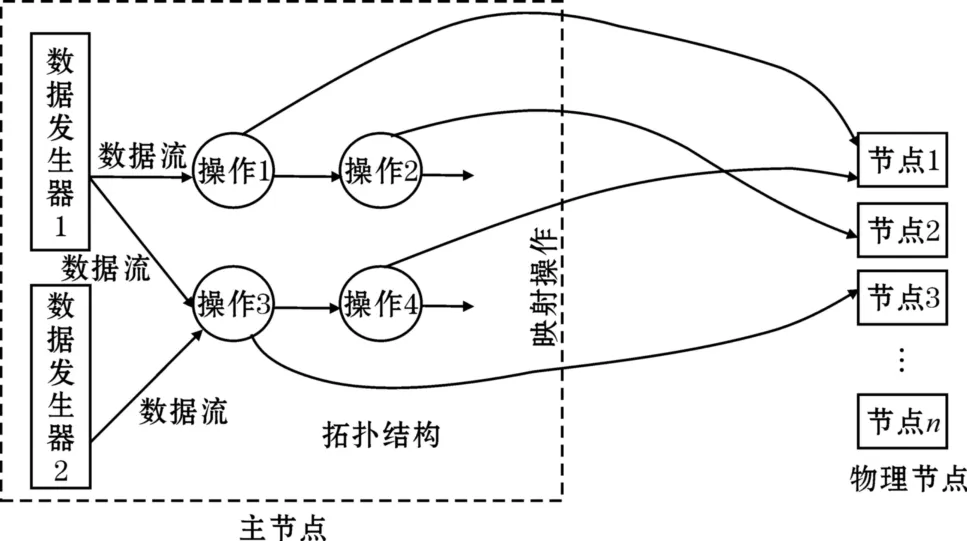
圖8 計算和數據協作機制的流式拓樸映射方法
用MPI來形式化的模擬從Topology到物理的映射過程,節點間通過MPI-Send()函數將流數據元組注入指定節點,在該節點上發起相應的操作,并通過MPI-Recv()函數接收前端發來的數據,實現節點間的通訊,如圖9所示。

圖9 用MPI模擬流式拓撲映射
主節點即節點0為數據發生器,發起兩個數據流。在數據流1中,節點0將其產生的數據通過MPI-Send()函數發送到節點1,節點1通過MPI-Recv()函數接收節點0發送來的數據,并發起加2的操作,將結果通過MPI-Send()函數發送到節點2,節點2通過MPI-Recv()函數接收節點1發送來的數據,并發起加3的操作。如果主節點不斷產生數據并向子節點發送數據就形成了流式系統的模式,MPI的靈活性在這里也體現得非常明顯。
從以上分析可以看出流式拓樸協作機制由于是基于機群結構的因此可以實現海量數據的實時處理,避免了一些大數據系統只能對數據進行非實時批處理的問題,同時利用拓樸結構可以實現更為靈活的分布式計算規劃,使大數據系統能靈活的設計數據分析算法。
5 結束語
從計算和數據的協作機制這一視角對大數據技術的發展歷程,主要的系統架構分類,主流系統的實現機制進行了介紹、對比和分析。認為計算和數據的協作機制是實現大數據系統的關鍵核心技術,協作機制的實現與分布式系統的整體架構有緊密的聯系,特別是分布式文件系統與計算的融合是解決協作機制的關鍵,單獨地考慮存儲和單獨考慮計算在面向數據的分布式系統中都是不全面的,由于數據的分析處理也是非常重要的,所以大數據系統應該是一種計算和數據都密集的系統。
未來大數據時代的數據會朝著:數據量更大,數據的關聯性更強,數據類型更多樣化的方向發展。同時大數據技術未來會呈現出以下發展趨勢和特點:(1)大數據系統中機群結構會成為主流架構;(2)對單個節點計算能力和穩定性的要求會下降;(3)傳統的面向計算的高性能計算技術會重新被人們認識并與大數據技術相結合,通過大數據系統使陽春白雪式的高性能計算變的更為貼近人們的生活;(4)新的大數據實現技術會涌現,如實時大數據處理、大規模圖處理技術;(5)數據挖掘算法特別是大數據架構下的數據挖掘算法會得到更多的關注。
致謝:感謝成都市科技局創新發展戰略研究項目(11RKYB016ZF)對本文的資助
[1] Parkhill,D F.The challenge of the computer utility(Addison-Wesley Publishing Company Reading,1966.1966).
[2] http://en.wikipedia.org/wiki/John-Gage.
[3] Li,G.Scientific value of big data research[J].Communications of the CCF,2012,8(9):8-15.
[4] Batcher,K E.Design of a massively parallel processor[J].Computers,IEEE Transactions on,1980,100(9):836-840.
[5] Duncan,S H,Keefer,C D,McLaughlin T A.High performance I/O design in the AlphaServer 4100 symmetric multiprocessing system[J].Digital Technical Journal,1996,8(4):61-75.
[6] Wang,P.Cloud Computing:Key Technique and Application[M].Posts&Telecom Press,2010.
[7] Wang F Y,Carley K M,Zeng D.Social computing:From social informatics to social intelligence[J].Intelligent Systems,IEEE,2007,22(2):79-83.
[8] Dean J,Ghemawat S.MapReduce:simplified data processing on large clusters[J].Communications of the Acm,2008,51(1):107-113.
[9] Borthakur D.HDFS architecture guide[EB/OL].Hadoop Apache Project.http://hadoop.apache.org/common/docs/current/hdfs-design.pdf,2008.
[10] Peng D,Dabek F.Large-scale incremental processing using distributed transactions and notifications[R].Proc.Proceedings of the 9th USENIX conference on Operating systems design and implementation,2010:1-15.
[11] Bhatotia P,Wieder A,Rodrigues R.Incoop:MapReduce for incremental computations[R].Proc.Proceedings of the 2nd ACM Symposium on Cloud Computing,2011:7.
[12] Elnikety E,Elsayed T,Ramadan H E.iHadoop:asynchronous iterations for MapReduce[R].Proc.Cloud Computing Technology and Science(CloudCom),2011 IEEE Third International Conference on,2011:81-90.
[13] Ekanayake J,Li H.Zhang B.Twister:a runtime for iterative mapreduce[R].Proc.Proceedings of the 19th ACM International Symposium on High Performance Distributed Computing,2010:810-818.
[14] Malewicz G,Austern M H,Bik A J.Pregel:a system for large-scale graph processing[R].Proc.Proceedings of the 2010 ACM SIGMOD International Conference on Management of data,2010:135-146.
[15] http://wuyanzan60688.blog.163.com.
[16] Guo,B,Wang P,Chen G.Cloud Computing Model Based on MPI[J].Computer Engineering,2009,35(24).
[17] Zhai Y,Liu M,Zhai J.Cloud versus in-house cluster:evaluating Amazon cluster compute instances for running MPI applications[R].Proc.State of the Practice Reports,2011:11.
[18] Lu X,Wang B,Zha L.Can mpi benefit hadoop and mapreduce applications[R].Proc.Parallel Processing Workshops(ICPPW),2011 40th International Conference on,2011:371-379.
[19] Hoefler T,Lumsdaine A,Dongarra J.Towards efficient mapreduce using mpi[R].:Recent Advances in Parallel Virtual Machine and Message Passing Interface(Springer,2009),2009:240-249.
[20] Luo X,Shu J.Summary of Research for Erasure Code in Storage System[J].Journal of Computer Research and Development,2012,49(1):1-11.
[21] Wang F,Qiu J,Yang J,Dong B.Hadoop high availability through metadata replication[R].Proc.Proceedings of the first international workshop on Cloud data management,2009:37-44.
[22] Bohn C A,Lamont G B.Load balancing for heterogeneous clusters of PCs,Future Generation Computer Systems[J].2002,18(3):389-400.
[23] Dong B,Li X,Wu Q.A dynamic and adaptive load balancing strategy for parallel file system with large-scale I/O servers[J].Journal of Parallel and Distributed Computing,2012,(1).
[24] Wang W,Zeng G,Tang D.Cloud-DLS:Dynamic trusted scheduling for Cloud computing[J].Expert Systems with Applications,2012,39(3):2321-2329.
[25] Randles M,Lamb D,Taleb-Bendiab A.A comparative study into distributed load balancing algorithms for cloud computing[R].Proc.Advanced Information Networking and Applications Workshops(WAINA),2010 IEEE 24th International Conference on,2010:551-556.
[26] Ren X,Lin R,Zou H.A dynamic load balancing strategy for cloud computing platform based on exponential smoothing forecast[R].Proc.Cloud Computing and Intelligence Systems(CCIS),2011 IEEE International Conference on,2011:220-224.
[27] Ge Y,Wei G.Ga-based task scheduler for the cloud computing systems[R].Proc.Web Information Systems and Mining(WISM),2010 International Conference on,2010:181-186.
[28] Karger D.Sherman A.Berkheimer A.Web caching with consistent hashing,Computer Networks,1999,31(11):1203-1213.
[29] Shires D.Mohan R.Mark A.A Discussion of Optimization Strategies and Performance for Unstructured Computations in Parallel HPC Platforms',2001.
[30] Isard M.Budiu M.Yu Y.Dryad:distributed data-parallel programs from sequential building blocks,ACM SIGOPS Operating Systems Review,2007,41,(3):59-72.
[31] http://storm-project.net/.
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
公民與法治(2022年5期)2022-07-29 00:47:28
教學考試(高考物理)(2021年5期)2021-11-08 10:31:22
中醫眼耳鼻喉雜志(2021年1期)2021-07-22 07:38:14
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
文苑(2018年21期)2018-11-09 01:23:06
家庭影院技術(2017年9期)2017-09-26 03:41:45
燕山大學學報(2015年4期)2015-12-25 02:19:49
中國衛生(2015年9期)2015-11-10 03:11:12
