基于代價(jià)敏感支持向量機(jī)的推薦系統(tǒng)托攻擊檢測方法*
2014-01-24 06:55:26呂成戍
計(jì)算機(jī)工程與科學(xué) 2014年4期
呂成戍
(東北財(cái)經(jīng)大學(xué)管理科學(xué)與工程學(xué)院,遼寧 大連 116025)
基于代價(jià)敏感支持向量機(jī)的推薦系統(tǒng)托攻擊檢測方法*
呂成戍
(東北財(cái)經(jīng)大學(xué)管理科學(xué)與工程學(xué)院,遼寧 大連 116025)
基于標(biāo)準(zhǔn)支持向量機(jī)的托攻擊檢測方法不能體現(xiàn)由于用戶誤分代價(jià)不同對分類效果帶來的影響,提出了一種基于代價(jià)敏感支持向量機(jī)的托攻擊檢測新方法,該方法在代價(jià)敏感性學(xué)習(xí)機(jī)制下引入支持向量機(jī)作為分類工具,對支持向量機(jī)輸出進(jìn)行后驗(yàn)概率建模,建立了基于類別隸屬度的動(dòng)態(tài)代價(jià)函數(shù),更準(zhǔn)確地反映不同樣本的分類代價(jià),在此基礎(chǔ)上設(shè)計(jì)了代價(jià)敏感支持向量機(jī)分類器。將該分類器應(yīng)用在推薦系統(tǒng)托攻擊檢測中,并與標(biāo)準(zhǔn)的支持向量機(jī)方法、代價(jià)敏感支持向量機(jī)方法進(jìn)行比較,實(shí)驗(yàn)結(jié)果表明,本方法可以更精確地控制代價(jià)敏感性,進(jìn)一步提高對攻擊用戶的檢測精度,降低總體的誤分類代價(jià)。
支持向量機(jī);托攻擊檢測;代價(jià)敏感;類別隸屬度
1 引言
不斷提高托攻擊的檢測精度是實(shí)現(xiàn)高質(zhì)量個(gè)性化推薦的關(guān)鍵。托攻擊檢測就是根據(jù)各種反映用戶概貌特征的統(tǒng)計(jì)屬性,構(gòu)建合適的分類器,采用分類模式匹配的方法檢測攻擊[1]。常用的人工神經(jīng)網(wǎng)絡(luò)、決策樹、貝葉斯分類器等傳統(tǒng)的分類方法,在樣本數(shù)量有限的情況下檢測的準(zhǔn)確率不盡理想。Vapnik V N等人[2,3]根據(jù)統(tǒng)計(jì)學(xué)習(xí)理論提出的支持向量機(jī)非常適合解決小樣本、高維度、非線性的分類問題。Williams C A等人[4]將標(biāo)準(zhǔn)的支持向量機(jī)用于托攻擊檢測,并與KNN(K-Nearest Neighbor)、決策樹等方法進(jìn)行了比較,取得了較好的效果。由于推薦系統(tǒng)中用戶基數(shù)很大,推薦過程中錯(cuò)誤地屏蔽一些真實(shí)用戶并不會(huì)對推薦結(jié)果產(chǎn)生顯著影響,但誤判一些攻擊用戶就有可能會(huì)改變推薦結(jié)果[5]。標(biāo)準(zhǔn)的支持向量機(jī)是基于分類精度進(jìn)行優(yōu)化的,未對攻擊用戶和真實(shí)用戶的誤分代價(jià)加以區(qū)別,造成托攻擊檢測時(shí)雖然整體精度較高,但卻無法有效地對很多攻擊用戶進(jìn)行識別,阻礙了這一方法在實(shí)際中的廣泛應(yīng)用。因此,對于托攻擊檢測問題,須引入代價(jià)敏感學(xué)習(xí)機(jī)制[6],考慮不同類別的誤分代價(jià),基于最小化總體誤分代價(jià)的原理來設(shè)計(jì)分類器。
Veropoulos K 等 人[7]通 過 對 SVM(Support Vector Machine)方法進(jìn)行代價(jià)敏感改造,對不同類的樣本設(shè)置不同的誤分代價(jià),實(shí)現(xiàn)了代價(jià)敏感支持向量機(jī)。Burges C[8]基于支持向量機(jī)的結(jié)構(gòu)風(fēng)險(xiǎn)最小化原則提出代價(jià)敏感支持向量機(jī)的設(shè)計(jì)。Paola C等人[9]通過給不同類別賦予不同的經(jīng)驗(yàn)風(fēng)險(xiǎn)權(quán)值直接改進(jìn)標(biāo)準(zhǔn)SVM,使其具有代價(jià)敏感性。上述方法提高了SVM在代價(jià)敏感情況下的分類性能,但是這些方法只考慮了不同類別的誤分代價(jià),而忽略了同一類別內(nèi)樣本代價(jià)的差異,無法實(shí)現(xiàn)誤分代價(jià)敏感性的精確控制。在實(shí)際應(yīng)用中,每個(gè)樣本對劃分的影響應(yīng)該是不同的,通常以一定概率屬于某一類,代價(jià)不僅與樣本類別有關(guān),與樣本本身也有關(guān)系[10],因此用固定的誤分代價(jià)來表示每個(gè)樣本的代價(jià)取值并不恰當(dāng)。
針對存在的問題,本文將基于類別隸屬度的數(shù)據(jù)權(quán)重策略引入代價(jià)的重構(gòu)中,允許每個(gè)樣本有不同的誤分代價(jià),建立集成樣本不同誤分代價(jià)的代價(jià)敏感支持向量機(jī)模型。將實(shí)現(xiàn)后的軟件應(yīng)用于真實(shí)數(shù)據(jù),實(shí)驗(yàn)結(jié)果表明,本文方法有效地提高了托攻擊的檢測性能,進(jìn)一步降低了總體誤分類代價(jià)。
2 托攻擊檢測方法
2.1 基于類別隸屬度的動(dòng)態(tài)代價(jià)函數(shù)
支持向量機(jī)在本質(zhì)上屬于二類硬分類器,輸出非彼即此,不能反映出樣本屬于某一類別的隸屬度,即樣本的后驗(yàn)概率。目前大多采用的方法是用一個(gè)連續(xù)函數(shù)把SVM的硬判斷輸出f(x)映射到[0,1],實(shí)現(xiàn)SVM 后驗(yàn)概率輸出。Platt J C[11]對幾種單調(diào)性函數(shù)作為概率輸出函數(shù)進(jìn)行了對比分析,在支持向量機(jī)的輸出概率建模中,含有兩個(gè)參數(shù)A和B的Sigmoid函數(shù)具有靈活的函數(shù)形式,在實(shí)際應(yīng)用中表現(xiàn)出較好的分類精度。因此,本文選用該函數(shù)作為后驗(yàn)概率模型。在兩類分類問題中,其概率輸出形式為:

其中,pi是樣本的隸屬度值,coi是每個(gè)樣本的誤分代價(jià),C1是誤分攻擊用戶的代價(jià),C2是誤分真實(shí)用戶的代價(jià),實(shí)際應(yīng)用中C1和C2的取值可根據(jù)具體情況中漏檢率和誤報(bào)率的重要性不同進(jìn)行設(shè)置。式(3)反映了同一類別內(nèi)樣本誤分類代價(jià)的差異,實(shí)現(xiàn)了誤分類代價(jià)敏感性的精確控制,也體現(xiàn)了不同類別的誤分代價(jià)對分類結(jié)果的影響。
2.2 代價(jià)敏感支持向量機(jī)
對于二分類問題,考慮到每個(gè)樣本都有不同的誤分 類 代 價(jià),樣 本 集 可 重 構(gòu) 為 (xi,yi,coi),xi∈Rd,coi≥0。其中coi是由式(3)得到的每個(gè)樣本的誤分代價(jià)。設(shè)樣本集 (xi,yi,coi)能被超平面(w·x)-b=0分類,那么問題轉(zhuǎn)換為最小化目標(biāo)函數(shù):
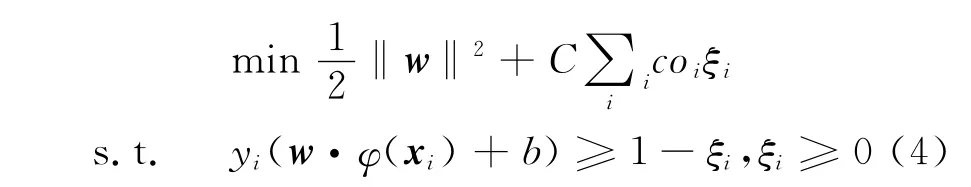
式(4)的經(jīng)驗(yàn)代價(jià)考慮到不同樣本的代價(jià)差異,使不同樣本具有不同的誤分代價(jià)。式(4)的對偶Lagrange表達(dá)式為:
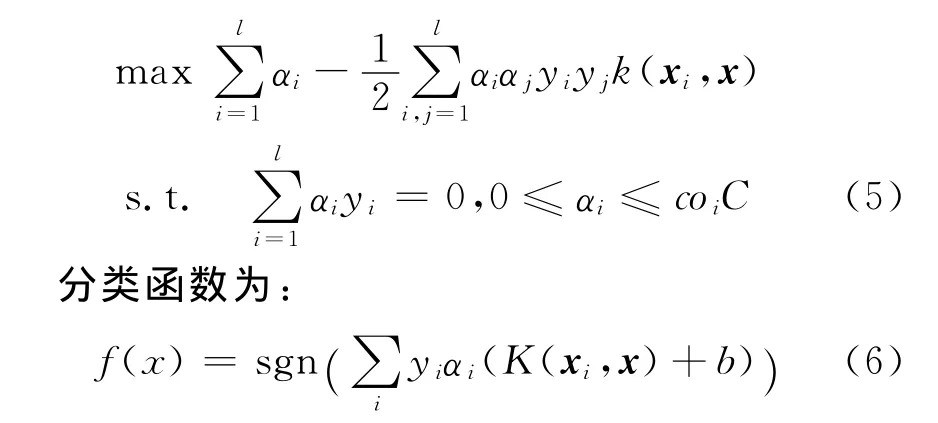
2.3 基于代價(jià)敏感支持向量機(jī)的托攻擊檢測
本文利用基于代價(jià)敏感學(xué)習(xí)的支持向量機(jī)對推薦系統(tǒng)進(jìn)行托攻擊檢測,其檢測模型框架見圖1。
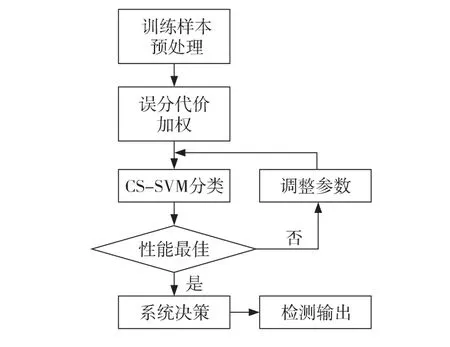
Figure 1 Framework of shilling attack detection model圖1 托攻擊檢測模型框架
首先根據(jù)檢測指標(biāo)對原始實(shí)驗(yàn)數(shù)據(jù)進(jìn)行預(yù)處理,然后利用基于類別隸屬度的動(dòng)態(tài)代價(jià)函數(shù)計(jì)算每個(gè)樣本的誤分代價(jià),最后利用集成樣本不同誤分代價(jià)的代價(jià)敏感支持向量機(jī)對訓(xùn)練集進(jìn)行學(xué)習(xí)和訓(xùn)練,得到支持向量機(jī)檢測模型。利用得到的檢測模型對測試集進(jìn)行檢測,輸出托攻擊的檢測結(jié)果。
3 仿真實(shí)驗(yàn)
3.1 實(shí)驗(yàn)數(shù)據(jù)
實(shí)驗(yàn)數(shù)據(jù)取自 MovieLens數(shù)據(jù)集[12],該數(shù)據(jù)集由明尼蘇達(dá)大學(xué)GroupLens研究小組通過MovieLens網(wǎng)站(http://movielens.umn.edu)收集,包含了943位用戶對1 682部電影的100 000條1~5的評分?jǐn)?shù)據(jù),每位用戶至少對20部電影進(jìn)行了評分。數(shù)據(jù)集被轉(zhuǎn)換成一個(gè)用戶——項(xiàng)目評分矩陣Rm×n= [u1u2… um]T,其中ui為用戶概貌,它包含了用戶i對系統(tǒng)中n部電影的評分。
3.2 特征提取
用戶概貌是高維數(shù)據(jù),支持向量機(jī)雖然對數(shù)據(jù)維數(shù)不敏感,但過高的特征維數(shù)使支持向量機(jī)訓(xùn)練時(shí)間過長,空間復(fù)雜度大,托攻擊檢測效率低下,因此在實(shí)際應(yīng)用中仍然要進(jìn)行特征選取。托攻擊檢測常用的特征信息包括[13]:用戶的預(yù)測變化值、用戶評價(jià)值背離程度、與其他用戶相適度、鄰居用戶相似程度和背離平均度等指標(biāo)。本文根據(jù)以上反映用戶評分信息異常度的統(tǒng)計(jì)屬性,對用戶的評分?jǐn)?shù)據(jù)進(jìn)行統(tǒng)計(jì)整理,得到五個(gè)檢測屬性,加上用戶編號(userID)和分類屬性(class)構(gòu)成一條關(guān)于某個(gè)用戶評分?jǐn)?shù)據(jù)的檢測數(shù)據(jù)。
3.3 實(shí)驗(yàn)設(shè)計(jì)與結(jié)果分析
實(shí)驗(yàn)采取3×4×5的設(shè)計(jì)模式,攻擊類型(隨機(jī)攻擊,均值攻擊,流行攻擊),攻擊強(qiáng)度(1%,3%,5%,10%),填充率(3%,6%,9%,12%,15%)。每組實(shí)驗(yàn)配置下,分別獨(dú)立地向數(shù)據(jù)集注入10次攻擊,最終實(shí)驗(yàn)數(shù)據(jù)是10次攻擊檢測的均值。本文選取標(biāo)準(zhǔn)SVM和CS-SVM方法作為性能比較的對象。SVM核函數(shù)采用高斯徑向基形式的核函數(shù)K(x,xi)=exp{-‖x-xi‖2/σ2}。根據(jù)相關(guān)研究與多次實(shí)驗(yàn),標(biāo)準(zhǔn)支持向量機(jī)C的取值為10。代價(jià)矩陣設(shè)定如下:正確分類的代價(jià)為0,誤分類攻擊概貌的代價(jià)C1為5,誤分類真實(shí)用戶概貌的代價(jià)C2為1。在實(shí)驗(yàn)中用托攻擊的檢測率和總體誤分類代價(jià)作為方法的評估標(biāo)準(zhǔn)。實(shí)驗(yàn)結(jié)果如圖2~圖7所示,其中,帶叉線代表SVM方法,帶三角線代表CS-SVM方法,帶星線代表本文提出的方法。從整體結(jié)果來看,本文方法比SVM和CSSVM檢測方法更加理想。具體實(shí)驗(yàn)結(jié)果如下:
(1)檢測率的比較。
檢測率的比較結(jié)果如圖2~圖4所示。

Figure 2 Detection recall rate of average attack圖2 均值攻擊的檢測率

Figure 3 Detection recall rate of bandwagon attack圖3 流行攻擊的檢測率
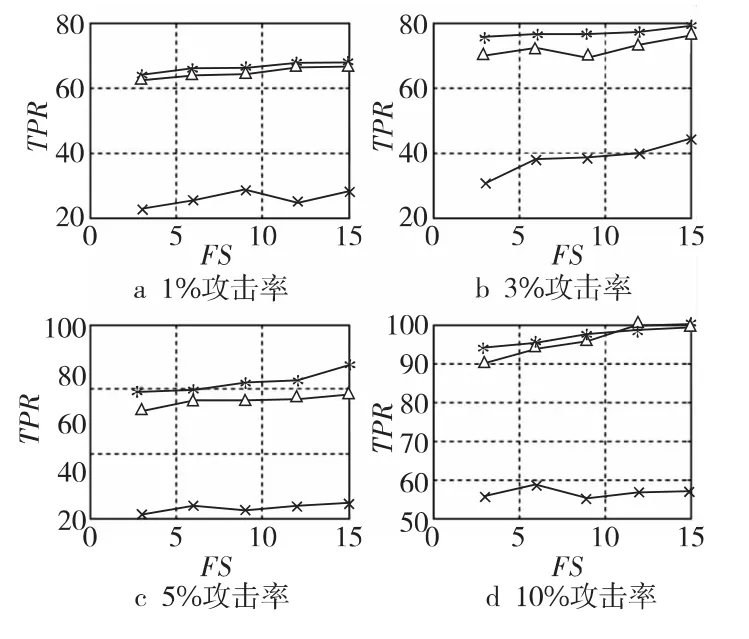
Figure 4 Detection recall rate of random attack圖4 隨機(jī)攻擊的檢測率
從圖2~圖4可看出,標(biāo)準(zhǔn)SVM方法在攻擊概貌數(shù)量較少(攻擊強(qiáng)度=1%、3%)時(shí),獲得的攻擊信息較少,對均值攻擊、流行攻擊和隨機(jī)攻擊的檢測率均不理想。最差情況:當(dāng)攻擊概貌為1%、填充率為3%時(shí),對隨機(jī)攻擊的檢測率僅為20.3%,即大部分攻擊概貌都被誤分成真實(shí)用戶概貌。隨著攻擊強(qiáng)度的增加 (攻擊強(qiáng)度=5%、10%),標(biāo)準(zhǔn)SVM方法對攻擊概貌的檢測率呈小幅上升趨勢;最好情況:當(dāng)攻擊強(qiáng)度為10%、填充率為15%時(shí),對流行攻擊的檢測準(zhǔn)確率達(dá)到58.5%。與標(biāo)準(zhǔn)SVM方法相比,CS-SVM方法的檢測效果有明顯改進(jìn),最差情況:當(dāng)攻擊概貌為1%、填充率為3%時(shí),對均值攻擊的檢測率為61.3%,仍然可以檢測出大部分攻擊數(shù)據(jù);該方法的最好情況:當(dāng)攻擊強(qiáng)度為10%、填充率為15%時(shí),對隨機(jī)攻擊的檢測率高達(dá)97.1%,比SVM方法的檢測率高出近一倍。雖然CS-SVM方法的檢測率很高,但是本文方法仍然能在此高水平上有所提高,最差情況:當(dāng)攻擊概貌為1%、填充率為3%時(shí),對均值攻擊的檢測率為67.3%,優(yōu)于同等實(shí)驗(yàn)配置下CSSVM方法62.4%的檢測率,隨著攻擊概貌數(shù)量和填充率的增加;本文方法最好情況:當(dāng)攻擊強(qiáng)度為10%、填充率為15%時(shí),對流行攻擊的檢測率最高達(dá)到了99.3%,能夠很好地幫助推薦系統(tǒng)得到真實(shí)的用戶評分?jǐn)?shù)據(jù),確保推薦的質(zhì)量。
(2)總體誤分類代價(jià)的比較。
總體誤分類代價(jià)按照公式:
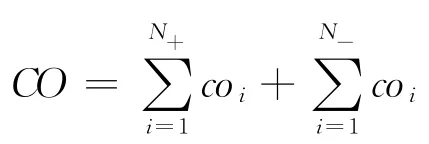
統(tǒng)一計(jì)算,其中變量的含義如上文所述。總體誤分類代價(jià)的比較結(jié)果如圖5~圖7所示。
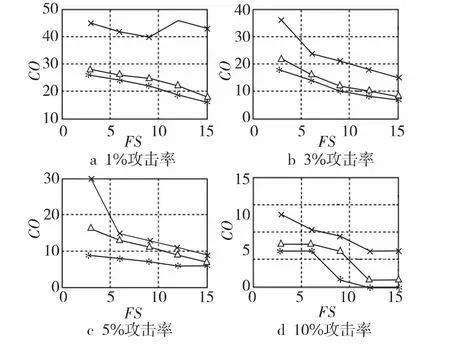
Figure 5 Total misclassification cost of average attack圖5 檢測均值攻擊的總體誤分類代價(jià)
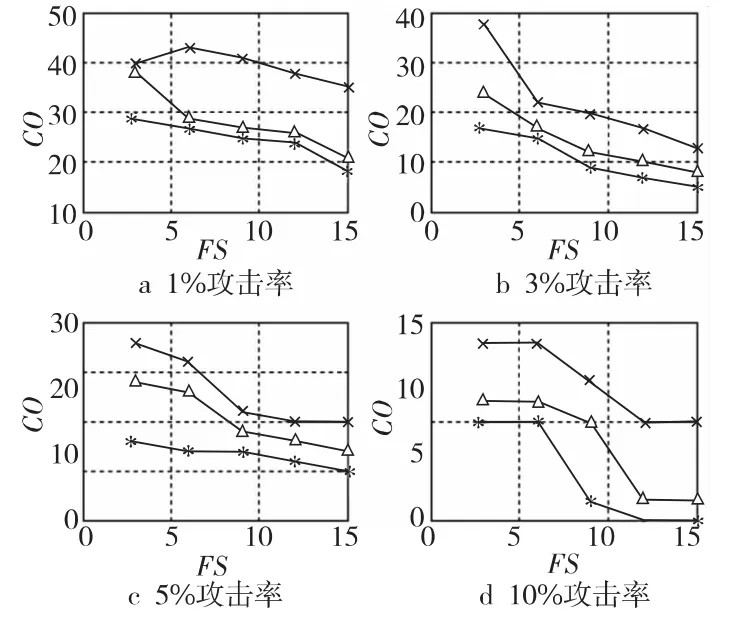
Figure 6 Total misclassification cost of bandwagon attack圖6 檢測流行攻擊的總體誤分類代價(jià)
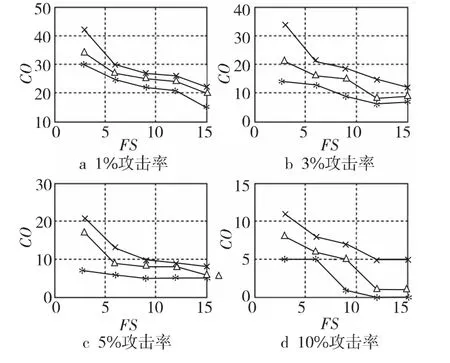
Figure 7 Total misclassification cost of random attack圖7 檢測隨機(jī)攻擊的總體誤分類代價(jià)
從圖5~圖7中可看出,在所比較的三種方法中,標(biāo)準(zhǔn)SVM方法的總體誤分類代價(jià)最高,本文方法的總體誤分類代價(jià)最低。標(biāo)準(zhǔn)SVM方法總體誤分類代價(jià)的最差情況:當(dāng)攻擊概貌為1%、填充率為3%時(shí),檢測均值攻擊的總體誤分類代價(jià)為45。隨著攻擊檢測率的提高,標(biāo)準(zhǔn)SVM方法的總體誤分類代價(jià)呈下降趨勢,最好情況:當(dāng)攻擊強(qiáng)度為10%、填充率為15%時(shí),檢測流行攻擊的總體誤分類代價(jià)為9。相對于SVM 而言,CS-SVM考慮了不同類型誤分的代價(jià),基于最小化總體誤分代價(jià)的原理來設(shè)計(jì)分類器,提高了攻擊概貌的檢測率,大幅降低了總體誤分類代價(jià)。該方法總體誤分類代價(jià)的最差情況:當(dāng)攻擊概貌為1%、填充率為3%時(shí),檢測流行攻擊的總體誤分類代價(jià)為38。隨著攻擊概貌數(shù)量和填充率的增加,CS-SVM方法的總體誤分類代價(jià)逐漸下降,最好情況:當(dāng)攻擊強(qiáng)度為10%、填充率為15%時(shí),檢測均值攻擊的總體誤分類代價(jià)為6。而本文方法則在CS-SVM方法的基礎(chǔ)上,引入基于類別隸屬度的數(shù)據(jù)權(quán)重策略,解決了CS-SVM方法不能精確控制誤分代價(jià)的弊端,在提高檢測率的前提下,進(jìn)一步降低了總體的誤分類代價(jià)。本文方法總體誤分類代價(jià)的最差情況:當(dāng)攻擊概貌為1%、填充率為3%時(shí),檢測均值攻擊的總體誤分類代價(jià)為30,和同等實(shí)驗(yàn)配置下的CSSVM方法相比總體誤分類代價(jià)降低了8。本文方法總體誤分類代價(jià)的最好情況:當(dāng)攻擊強(qiáng)度為10%、填充率為15%時(shí),檢測流行攻擊的總體誤分類代價(jià)趨近于0。
4 結(jié)束語
現(xiàn)有的基于SVM的推薦系統(tǒng)托攻擊檢測方法是普適機(jī)器學(xué)習(xí)方法,將托攻擊檢測當(dāng)作一個(gè)普通的模式識別問題來研究,忽略了問題的特殊性,即推薦系統(tǒng)數(shù)據(jù)集中兩類樣本的誤分代價(jià)的差異。本文將代價(jià)敏感機(jī)制引入標(biāo)準(zhǔn)的支持向量機(jī)算法中,同時(shí)考慮并有效解決了同一類別內(nèi)樣本誤分類代價(jià)不同的問題。仿真實(shí)驗(yàn)結(jié)果表明,本文算法進(jìn)一步提高了對攻擊用戶的檢測精度,降低了算法的總體誤分類代價(jià)。本文提出的托攻擊檢測算法限定在有監(jiān)督的樣本上,通過改進(jìn)算法來提高分類精度,這在一定程度上影響了算法的推廣應(yīng)用。因此,本文下一步的工作將集中在提高算法的無監(jiān)督程度上,即在缺少攻擊強(qiáng)度、攻擊模型等先驗(yàn)知識的情況下,仍可對托攻擊進(jìn)行可靠、準(zhǔn)確的檢測,為推薦系統(tǒng)的管理者與研究者提供更為實(shí)用的托攻擊檢測手段和新的研究思路。
[1] Zhang Jing,He Fa-mei,Qiu Yun.Inspection method of the attack on personalized recommendation system description file[J].Journal of University of Electronic Science and Technology,2011,40(2):250-254.(in Chinese)
[2] Vapnik V N.Statistical learning theory[M].New York:Wiley,1998.
[3] Vapnik V N .The mature of statistical learning theory[M].Germany:Springer,2000.
[4] Williams C A,Mobasher B,Burke R D.Defending recommender systems:Detection of profile injection attacks[J].Service Oriented Computing and Applications,2007,1(3):157-170.
[5] Li Cong,Luo Zhi-gang,Shi Jin-long.An unsupervised algorithm for detecting shilling attacks on recommender systems[J].Acta Automatica Sinica,2011,37(2):160-167.(in Chinese)
[6] Breiman L,F(xiàn)riedman J H,OlshenR A,et al.Classification and regression trees[M].California:Wadsworth International Group,1984.
[7] Veropoulos K,Campbell C,Cristianini N.Controlling the sensitivity of support vector machines[C]∥Proc of the International Joint Conference on AI(IJCAI’1999),1999:55-60.
[8] Burges C.A tutorial on support vector machines from pattern recognition[J].Data Mining and Knowledge Discovery,1998,13(2):121-167.
[9] Paola C,Elena C,Giorgio V.Support vector machines for candidate modules classification[J].Neurocomputing,2005,68(4):281-288.
[10] Japkowicz N.Concept-learning in the presence of betweenclass and within-class imbalances[C]∥Proc of CSCSI’01,2001:67-77.
[11] Platt J C.Probabilistic output for support vector machine and comparisons to regularized likelihood methods[M].Boston:MIT Press,1999.
[12] http://www.grouplens.org/node/73.
[13] Burke R,Mobasher B,Williams C.Classification features for attack detection in collaborative recommender systems[C]∥Proc of ICKDDM’06,2006:156-167.
附中文參考文獻(xiàn):
[1] 張靖,何發(fā)鎂,邱云.個(gè)性化推薦系統(tǒng)描述文件攻擊檢測方法[J].電子科技大學(xué)學(xué)報(bào),2011,40(2):250-254.
[5] 李聰,駱志剛,石金龍.一種探測推薦系統(tǒng)托攻擊的無監(jiān)督方法[J].自動(dòng)化學(xué)報(bào),2011,37(2):160-167.
Shilling attack detection method of recommender systems based on cost-sensitive SVM
The shilling attack detection method based on traditional Support Vector Machine(SVM)can not reflect the influence of the great difference of misclassification cost on classification effect.The paper proposes a novel shilling attack detection method based on cost-sensitive SVM.The method uses SVM as the classification tool under the cost-sensitive learning mechanism,and models the probabilistic outputs of SVM,presents dynamic misclassification cost function based on class membership value,thus accurately reflecting the misclassification cost of different samples.Hence,we design the classifier of cost-sensitive SVM and apply it in shilling attacks detection.Experimental results show that,compared with traditional SVM and different classes of cost-sensitive SVM (CS-SVM),our proposed method can more precisely control the cost of misclassification,improve the precision of the minority class samples,and decrease the total cost of misclassification.
support vector machine(SVM);shilling attacks detection;cost-sensitive;class membership
TP181
A
10.3969/j.issn.1007-130X.2014.04.021
2012-11-29;
2013-01-10
遼寧省社會(huì)科學(xué)規(guī)劃基金資助項(xiàng)目(L10BJL035);中央高校專項(xiàng)科研基金資助項(xiàng)目(DUT10RW302)
通訊地址:116025遼寧省大連市東北財(cái)經(jīng)大學(xué)管理科學(xué)與工程學(xué)院
Address:School of Management Science and Engineering,Dongbei University of Finance and Economics,Dalian 116025,Liaoning,P.R.China
1007-130X(2014)04-0697-05
呂成戍(1979-),女,黑龍江依安人,博士生,講師,研究方向?yàn)闄C(jī)器學(xué)習(xí)和電子商務(wù)。E-mail:lvcs@163.com
LüCheng-shu,born in 1979,PhD candidate,lecturer,her research interests include machine learning,and e-commerce.
猜你喜歡
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
