數(shù)據(jù)挖掘在圖書(shū)館管理上的應(yīng)用
2014-02-10 18:20:56宋麗軍
科技創(chuàng)新與應(yīng)用 2014年5期
關(guān)鍵詞:數(shù)據(jù)挖掘
摘 要:隨著學(xué)生和圖書(shū)館里文獻(xiàn)資料的數(shù)量增漲,圖書(shū)館管理系統(tǒng)的數(shù)據(jù)正呈指數(shù)增長(zhǎng)。使用傳統(tǒng)的人工統(tǒng)計(jì)方法不可能進(jìn)行完整的、如此大量的數(shù)據(jù)分析,如何巧妙的提取需求的信息然后進(jìn)行充分的利用成為了一個(gè)讓人頭疼的問(wèn)題。而利用數(shù)據(jù)挖掘技術(shù)可以很輕松的解決上述問(wèn)題。文章通過(guò)使用k-means算法進(jìn)行聚類(lèi)挖掘得到了一個(gè)完整高效的統(tǒng)計(jì)結(jié)果,進(jìn)而根據(jù)統(tǒng)計(jì)結(jié)果對(duì)圖書(shū)館的管理進(jìn)行改善,可以提供更好、更人性化的服務(wù)。最后,文章對(duì)未來(lái)數(shù)據(jù)挖掘技術(shù)在圖書(shū)館的數(shù)據(jù)管理方面的應(yīng)用進(jìn)行了展望和暢想。
關(guān)鍵詞:數(shù)據(jù)挖掘;圖書(shū)館管理;個(gè)性化服務(wù)
隨著科學(xué)技術(shù)和文化水平的飛速發(fā)展,人們對(duì)知識(shí)的需求也越來(lái)越強(qiáng)烈,想要更好的工作環(huán)境和生活水平,與自身的知識(shí)水平是密不可分的。因此,越來(lái)越多的人選擇不斷汲取知識(shí)來(lái)武裝自己,而圖書(shū)館是汲取各種知識(shí)、了解國(guó)內(nèi)外最新動(dòng)態(tài)的最快捷、方便、省時(shí)省力的地方。由于越來(lái)越多的人選擇了圖書(shū)館,圖書(shū)館中的資料、讀者信息、借閱信息等等也越來(lái)越繁多和復(fù)雜,如何更好的處理與充分利用這些信息,成為了圖書(shū)館管理與發(fā)展的重大轉(zhuǎn)折點(diǎn)。
所謂數(shù)據(jù)挖掘是指從數(shù)據(jù)庫(kù)的大量數(shù)據(jù)中揭示出隱含的、先前未知的并有潛在價(jià)值的信息的非平凡過(guò)程。非常適合進(jìn)行圖書(shū)館數(shù)據(jù)的挖掘、管理和應(yīng)用。例如我們可以采用數(shù)據(jù)挖掘的方法分析讀者的行為,總結(jié)其一般的借閱規(guī)律,從而采取相應(yīng)的措施,為讀者創(chuàng)造方便的環(huán)境和提供不同的個(gè)性化的服務(wù)。
實(shí)例分析:分析讀者行為,獲取讀者需求
聚類(lèi)分析是將數(shù)據(jù)分類(lèi)到不同的類(lèi)或者簇這樣的一個(gè)過(guò)程,所以同一個(gè)簇中的對(duì)象有很大的相似性,而不同簇間的對(duì)象有很大的相異性。我們可以采用聚類(lèi)分析的方法把不同的讀者進(jìn)行分類(lèi),然后對(duì)不同類(lèi)型的讀者提供不同的服務(wù),這樣可以更好的管理讀者的借閱情況,也可以給有特殊需求的讀者提供特殊的服務(wù)。下面根據(jù)一些讀者的借閱數(shù)據(jù)進(jìn)行了具體的挖掘?qū)嶒?yàn),實(shí)現(xiàn)了聚類(lèi)分析在圖書(shū)館數(shù)據(jù)管理方面的應(yīng)用。
第1步:數(shù)據(jù)準(zhǔn)備
我們這里只是做一個(gè)比較簡(jiǎn)單的挖掘分析,所以我們只考慮近兩年讀者的借閱情況,因此我們要先做一下數(shù)據(jù)的預(yù)處理,把兩年之前的借閱信息棄掉不用,這兩年每年的借閱數(shù)量和總借閱數(shù)量留待下一步聚類(lèi)分析使用。由于讀者的情況變化可能會(huì)很大,因此近兩年的數(shù)據(jù)更具代表性,用來(lái)進(jìn)行分析也會(huì)更加貼近讀者的真實(shí)需求。
第2步:對(duì)數(shù)據(jù)進(jìn)行聚類(lèi)
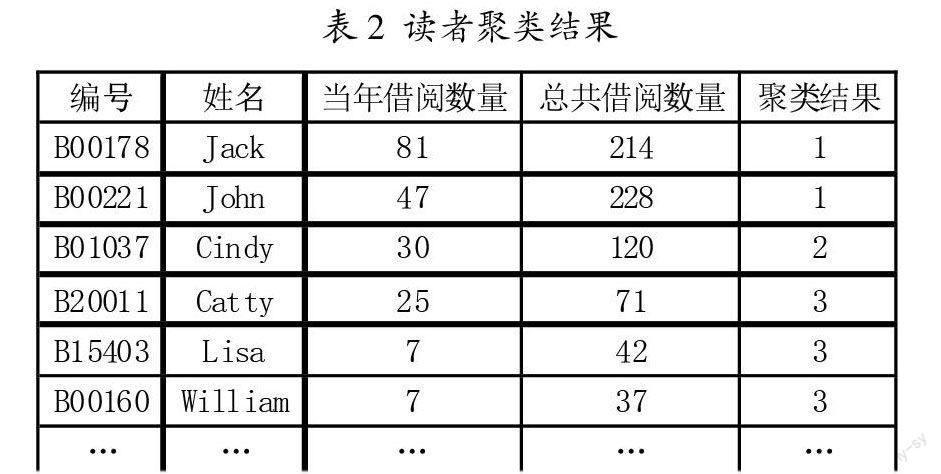
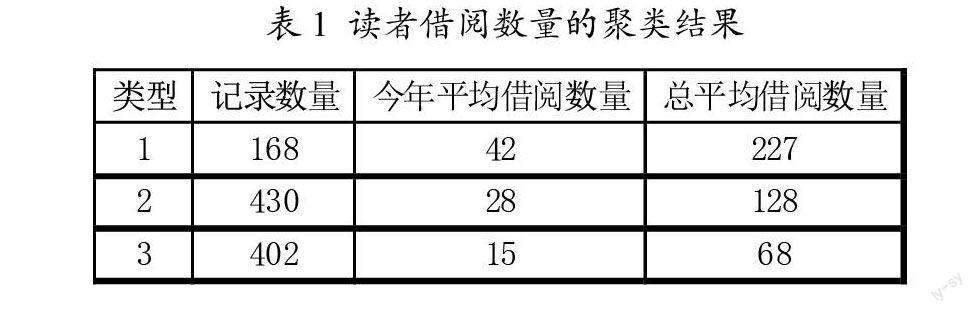
在這里我們使用k-means算法對(duì)第一步中清理出來(lái)的數(shù)據(jù)進(jìn)行聚類(lèi)挖掘,設(shè)置聚類(lèi)個(gè)數(shù)為3.代表把讀者一共分成3個(gè)大類(lèi),一類(lèi)為頻繁借閱者,一類(lèi)為普通借閱者,一類(lèi)為偶爾借閱者.分好類(lèi)之后我們就可以針對(duì)不同的讀者提供不同的、更加符合讀者需求的、個(gè)性化的服務(wù)了。
按照以下幾個(gè)步驟對(duì)收集的數(shù)據(jù)進(jìn)行聚類(lèi)分析:(1)把目標(biāo)對(duì)象劃分成n個(gè)非空子集(聚類(lèi));(2)計(jì)算每個(gè)聚類(lèi)中所有點(diǎn)的坐標(biāo)平均值,并將這個(gè)平均值作為每個(gè)聚類(lèi)的中心;(3)計(jì)算每個(gè)點(diǎn)到聚類(lèi)中心的距離,將每個(gè)點(diǎn)聚類(lèi)到離該點(diǎn)最近的聚類(lèi)中心的聚類(lèi)中去反復(fù)執(zhí)行(2)、(3),直到聚類(lèi)中心不再進(jìn)行大范圍移動(dòng)或者聚類(lèi)次數(shù)達(dá)到要求為止下面是虛擬的聚類(lèi)結(jié)果(見(jiàn)表1、表2):
第3步:挖掘統(tǒng)計(jì)結(jié)果分析
上文介紹的挖掘方法比較簡(jiǎn)單,僅僅是從借閱數(shù)量方面衡量了讀者的需求情況。但是在實(shí)際應(yīng)用中也有很大的可應(yīng)用、可擴(kuò)展?jié)撃堋?duì)于挖掘出來(lái)的第一類(lèi)頻繁借閱者,我們可以適當(dāng)?shù)脑黾悠浣栝啍?shù)量的上限,這樣可以更好的滿(mǎn)足他們的需求;對(duì)于第三類(lèi)偶爾借閱者,我們可以繼續(xù)采用其他的挖掘方法挖掘他們的興趣范圍和較少借閱的原因,從而相應(yīng)地改善圖書(shū)館的服務(wù),為讀者們創(chuàng)造更好的閱讀條件。這樣把讀者分類(lèi)之后再進(jìn)行數(shù)據(jù)分析,可以更加精確地挖掘出不同讀者的不同需求,可以給不同需求的讀者提供更加個(gè)性化的服務(wù)。
數(shù)據(jù)挖掘在圖書(shū)館中的應(yīng)用是多種多樣的,例如利用關(guān)聯(lián)規(guī)則分析圖書(shū)借閱種類(lèi)方面的聯(lián)系,從而改善圖書(shū)館的布局;利用決策樹(shù)的方法來(lái)對(duì)讀者的閱讀方向進(jìn)行分類(lèi)。從而提供個(gè)性化的推薦服務(wù)等等。本文僅從一個(gè)方面對(duì)于數(shù)據(jù)挖掘在圖書(shū)館的應(yīng)用進(jìn)行了分析,窺一斑而知全豹,數(shù)據(jù)挖掘在圖書(shū)館數(shù)據(jù)處理方面的應(yīng)用是廣泛而有效的,可以進(jìn)行更深一步的研究與開(kāi)發(fā)。在現(xiàn)如今這個(gè)知識(shí)大爆炸的年代,各方面的知識(shí)和數(shù)據(jù)都應(yīng)該受到廣泛的重視與深入的研究,然而,這些信息魚(yú)龍混雜,如何取其精華棄其糟粕就成為了當(dāng)務(wù)之急,通過(guò)一些現(xiàn)代化信息技術(shù)的使用,我們可以提升獲取信息的速度、分離出有價(jià)值的信息、根據(jù)這些信息改善服務(wù)水平。隨著技術(shù)的不斷發(fā)展,圖書(shū)館的服務(wù)也正在從被動(dòng)化服務(wù)轉(zhuǎn)向主動(dòng)化服務(wù),從簡(jiǎn)單的信息接收轉(zhuǎn)向?yàn)樾畔z索、信息利用。總而言之,數(shù)據(jù)挖掘技術(shù)在圖書(shū)館數(shù)據(jù)管理與應(yīng)用方面的應(yīng)用前景非常的廣闊,隨著科學(xué)技術(shù)和圖書(shū)館硬件設(shè)備的快速發(fā)展,數(shù)據(jù)挖掘技術(shù)在圖書(shū)館的應(yīng)用將實(shí)現(xiàn)巨大的發(fā)展和長(zhǎng)足的進(jìn)步。
參考文獻(xiàn)
[1]廖志平.數(shù)據(jù)挖掘在學(xué)校圖書(shū)館的應(yīng)用[J].科技創(chuàng)新導(dǎo)報(bào),2012,(12):211-213.
[2]Randall Matignon. Data Mining Using SAS Enterprise Miner[M]. Wiley-Blackwell (an imprint of John Wiley & Sons Ltd, 2007,(8):91-105.
[3]劉軍.數(shù)據(jù)挖掘在讀者閱讀需求偏好研究中的應(yīng)用[J].圖書(shū)館論壇,2012(5):89-93
[4]M.Goebel and L Grucnwald.A survey of data mining and knowledge discovery software tools [J].SIKDD Explorations.1999;1(1):22-33.
[5]J.Quinlan,C4.5 Programs for Machine Learning[M].Morgan Kaufmann Publishers,1993.
[6]牛根義.國(guó)內(nèi)圖書(shū)館數(shù)據(jù)挖掘研究[J].現(xiàn)代情報(bào).2009,29(1):128-133.
作者簡(jiǎn)介:宋麗軍(1988-),女,山東省嘉祥縣,現(xiàn)同濟(jì)大學(xué)軟件學(xué)院研究生,碩士學(xué)位,研究方向:信息系統(tǒng),分布式系統(tǒng)。
猜你喜歡
艦船科學(xué)技術(shù)(2022年14期)2022-09-22 03:10:36
大眾投資指南(2021年35期)2021-02-16 01:06:26
中國(guó)交通信息化(2020年1期)2020-07-27 02:50:04
電力與能源(2017年6期)2017-05-14 06:19:37
中國(guó)中醫(yī)藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(shù)(2015年6期)2015-12-26 01:16:46
西安工程大學(xué)學(xué)報(bào)(2014年2期)2014-02-28 18:03:05
河南科技(2014年23期)2014-02-27 14:18:43
電子設(shè)計(jì)工程(2014年18期)2014-02-27 12:00:13
電子設(shè)計(jì)工程(2014年18期)2014-02-27 12:00:12
