一種基于語義相似度的P2P數(shù)據(jù)查詢方法
2014-02-24 08:59:23南京航空航天大學210000
電子測試 2014年23期
林 曉(南京航空航天大學,210000)
一種基于語義相似度的P2P數(shù)據(jù)查詢方法
林 曉
(南京航空航天大學,210000)
目前P2P網(wǎng)絡中數(shù)據(jù)查詢在語義方面的研究較少,而基于DHT的數(shù)據(jù)檢索只支持準確查詢,導致查詢準確率不高,但是好的索引項的建立會給查詢帶來很大的方便。本文結合了RDF和WordNet在語義方面的特點提出了一種新的簡易RDF概念列表來表示文檔,并通過計算語義相似度來決定輸出結果的P2P數(shù)據(jù)查詢方法。仿真實驗證明本文方法可以較好的提高查詢成功率。
P2P網(wǎng)絡;簡易RDF概念列表;語義相似度;數(shù)據(jù)查詢
0 引言
在是P2P網(wǎng)絡應用中,數(shù)據(jù)查詢是經(jīng)常需要使用到一個基本功能,如何在大數(shù)據(jù)、大應用的P2P系統(tǒng)中快速準確地找到滿足給定條件的數(shù)據(jù),是P2P網(wǎng)站能夠順利運行關鍵環(huán)節(jié)。但是當前許多研究都只是單純地考慮節(jié)點或文檔間的距離因素而忽略了語義對查詢結果的影響,而基于分布式哈希表DHT(Distributed Hash Table)的方法也只支持精確查詢,對文檔的搜索返回不相關的內容經(jīng)常會對搜索準確率產(chǎn)生影響,再者由于索引不當,搜索不到有關文檔還會影響到搜索的召回率。為此,本文提出一種新的簡易RDF概念列表表示法來表示文檔,并通過基于語義相似度的計算來進行數(shù)據(jù)查詢的P2P搜索方法。使用簡易RDF概念列表來表示文檔,提高索引方面的能力,并通過計算查詢消息和表示文檔的概念列表之間的語義相似度來決定二者的匹配程度,從而提高查詢準確率。
1 文檔表示方法
1.1 現(xiàn)有文檔表示方法
節(jié)點上的文檔如何表示對P2P系統(tǒng)中的數(shù)據(jù)查詢尤為重要,因為它決定著整個查詢的索引效率。一個好的索引項的建立對于整個系統(tǒng)的查詢效率的提高起著舉足輕重的作用。目前大多數(shù)文檔表示方法是基于向量空間模型的,以單一向量表示一篇文檔,每個向量的元素作為文檔中單詞的出現(xiàn)頻率和權重。另外,文獻提出的方法未考慮單詞出現(xiàn)頻率對語義相似度的影響,而只是單純將名詞列表作為文檔的搜索形式。
1.2 簡易RDF概念列表表示法
本文采用簡易RDF概念列表表示法對文檔進行表示。RDF(Resource Description Framework)是一個應用程序框架,允許將資源描述為結構化的數(shù)據(jù)并在不同的應用程序之間交換和重用這些資源。它可以提供結構化的元數(shù)據(jù)來標記資源,資源擁有的屬性可以被定義為一個擁有相應屬性值的屬性類。例如我們可以把文檔所屬的類別作為文檔的一個屬性來描述,關于體育方面的文檔我們將其類別屬性標識為sports,娛樂方面的文檔我們將其類別屬性標識為entertainment等等。根據(jù)RDF的這個特殊性能,我們提出的簡易RDF概念列表把文檔表示為單詞和詞頻組成的二元組列表的形式:
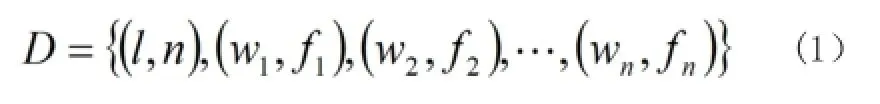
2 語義相似度的計算
在WordNet對語義相似度計算的研究中,一個最顯著的特征是以單詞的含義來代替原有的拼寫形式來組織詞匯信息,單詞間的三種主要語義關系分別為:整體部分關系(meronymy)、遺傳關系(inheritance)、以及反義關系(antonymy),這些關系將對我們計算語義相似度提供很大幫助。
2.1 單詞間語義相似度的計算
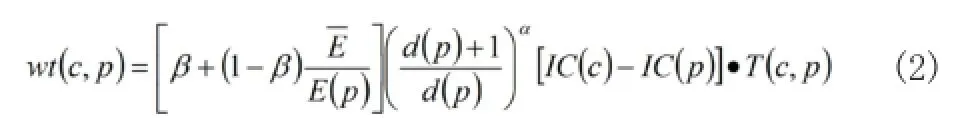
文獻[4]給出了兩個單詞間的語義距離的定義

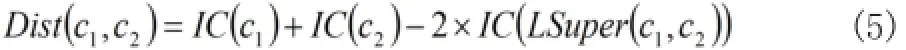
當單詞有多個含義時,單詞間的語義距離是兩個單詞中任意兩個含義間語義距離的最小值,即
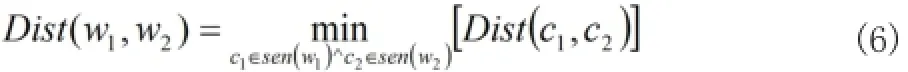
2.2 查詢相似度的計算

本文中查詢相似度定義如下:
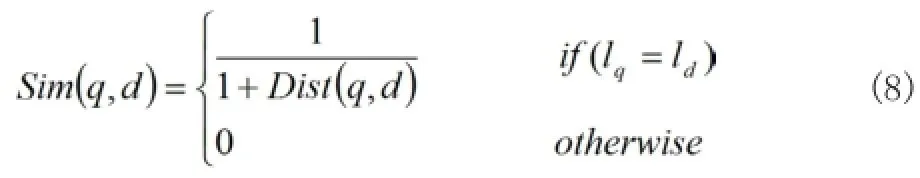
由于事先已有簡易RDF概念列表中的一項作為屬性來標識文檔主題,不屬于同一主題的文檔我們認為其相似度為0,如兩篇分別類屬于entertainment和sports的文檔,可以認為二者沒有相似性。在兩個文檔屬于同一主題的情況下比較二者的語義相似度可以避免更多的計算來提高查詢效率。
3 數(shù)據(jù)查詢過程
我們用圖1給出的圖形簡單的表示網(wǎng)絡拓撲結構,圖中字母標識的圓圈用來表示網(wǎng)絡中的節(jié)點,各圓圈之間的連線表示節(jié)點之間的連接關系,有連線的表示節(jié)點為鄰居關系,可以相互通信。把這種機制應用到P2P網(wǎng)絡中,可以增強節(jié)點之間的聯(lián)通性,因為節(jié)點不僅可以查詢到自己的鄰居節(jié)點信息,還可以查詢鄰居的鄰居甚至更多,將會提高查全率從而更好地提高查準率。
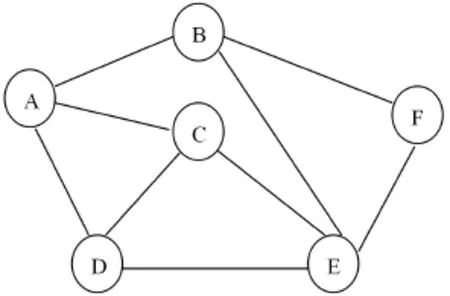
圖1 拓撲結構圖
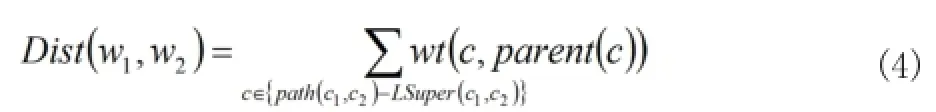
3.1 相關工作
單個節(jié)點的數(shù)據(jù)表為:(1)節(jié)點自身建立的本地資源索引表LRIT(Local Resource Indexed Table),用來記錄本地文檔列表。節(jié)點A的LRIT如下表1所示:(2)與該節(jié)點相關聯(lián)的鄰居節(jié)點資源索引表NRIT(Neighbor Resource Indexed Table),用來保存鄰居節(jié)點所包含的文檔列表。節(jié)點A的NRIT如下表2所示:

表1 節(jié)點A的LRIT
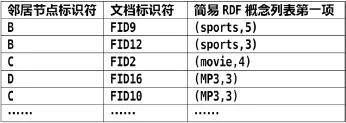
表2 節(jié)點A的NRIT
3.2 查詢過程
第一步:對LRIT進行檢查,若無合適選項,則跳入步驟四;
第五步:若查詢無返回標志,則輸入NULL。
這里使用生存值TTL(Time To Live)來防止消息的無限轉發(fā)帶來的網(wǎng)絡堵塞問題。由查詢過程可以看出最后的返回結果可能不能包含所有用戶給出的關鍵詞,這也是區(qū)別于精確查詢的地方。
4 實驗結果與分析
為了驗證本文提出的基于語義相似度的P2P查詢方法的有效性,通過仿真實驗針對不同查詢次數(shù)下的查詢成功率與Gnutella方法做了對比,結果證明本文方法查詢成功率較高。
5 結束語
本文通過結合RDF和WordNet在語義方面的特征提出一種新的文檔表示方法——簡易RDF概念列表法,并通過計算查詢和文檔之間的語義相似度來確定查詢結果。仿真實驗證明本文方法可以很好的提高查詢成功率,但是下一步的工作還要對其在帶寬利用率和查詢路徑方面的高效性做深一步的研究,以便進一步證明該方法的實用性和科學性。
[1] John Rission,Tim Moors.Survey of research towards robust peer-to-peer networks:Search methods [J] Computer Networks 50(2006)3485-3521.

圖2 查詢成功率比較(查詢次數(shù)數(shù)量級為104)
[2] Pandya A,Bhattacharyya P.Text similarity measurement using concept representation of texts[C]//Proceedings of First International Conference on Pattern Recognition and MachineIntelligence.Berlin,Germany:Springer,2005:678-689.
[3] Roy R ,Mili H ,Blettner M .Development andapplication of a metric on semantic nets[J]. IEEE Transaction of a metric on System,Man and Cybernetics,1989,19(1):17-30
[4] Song Shaoxu,,Li Chunping.TCUAP: a novel approach of text clustering using asymmetric proximity[C]// Proceedings of the 2nd Indian International Conference on Artificial Intelligence.India: IICAI 2005:604-613
[5] 顏偉,荀恩東.基于WordNet的英語詞語相似度計算[A].第二屆全國學生計算語言學研討會[C],2004.
[6] Sai Ho Kwok.P2P Searching trends:2002-2004. Information Processing and Management 42(2006):237-247
[7] 孫爽,章勇.一種基于語義相似度的文本聚類算法[J].南京航空航天大學學報,2006,389(6):712-716.
Research of P2P Data Query Based on Semantic Similarity
Lin Xiao
(Nanjing University of Aeronautics & Astronautics,210000)
There is less research on data query of P2P network based on semantic,and data query based on DHT can only support precise query ,so the precision is not high.But a good query index can play an important role and help enhance the success ratio.This paper introduced a new data query approach,which integrated RDF with WordNet based on their semantic feature and use a new description method to describe document ,which is called simple RDF concept list.The query result is decided by the semantic similarity computed by our new formula.It is approved that the new method is advanced in improving the query success ratio.
P2P network;simple RDF concept list;semantic similarity;data quer
林曉(1979-),女,浙江溫州人,南京航空航天大學黨政辦公室對外聯(lián)絡辦公室主任,碩士,助理研究員,研究方向為高等教育管理。
中央高校基本業(yè)務費項目(NR2014024,NR2014059)
猜你喜歡
現(xiàn)代裝飾(2022年1期)2022-04-19 13:47:32
開放教育研究(2020年2期)2020-03-31 01:54:14
現(xiàn)代裝飾(2020年2期)2020-03-03 13:37:44
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
中學生數(shù)理化·高一版(2018年9期)2018-10-09 06:46:48
智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18
中學生數(shù)理化·高一版(2017年9期)2017-12-19 12:15:14
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
七彩語文·低年級(2011年19期)2011-04-12 00:00:00
