基于Hadoop云計(jì)算平臺(tái)的圖像分類與標(biāo)注*
2014-02-28 06:16:28陸寄遠(yuǎn)黃承慧
電信科學(xué) 2014年2期
陸寄遠(yuǎn),黃承慧,侯 昉,李 斌
(1.廣東金融學(xué)院計(jì)算機(jī)科學(xué)與技術(shù)系 廣州510521;2.甲骨文研究開發(fā)中心(深圳)有限公司 深圳518057)
1 引言
隨著網(wǎng)絡(luò)的普及以及多媒體數(shù)據(jù)獲取設(shè)備的發(fā)展,圖像和視頻的數(shù)量都飛速增長(zhǎng),多媒體資料的存儲(chǔ)和檢索成為熱門的研究領(lǐng)域。基于內(nèi)容的圖像檢索、對(duì)象識(shí)別、標(biāo)注等都是現(xiàn)在的研究重點(diǎn)。各種分類算法、模型和系統(tǒng)不斷涌現(xiàn),如基于SVM(support vector machine,支持向量機(jī))、pLSA(probabilistic latent semantic analysis,概率潛在語(yǔ)義分析)或決策樹的圖像分類方法[1]。其中,基于內(nèi)容的圖像檢索是形成基于內(nèi)容的標(biāo)注和圖像之間的映射。有了這些標(biāo)注,就可以將用戶的查詢分解到標(biāo)注的概念,以檢索出結(jié)果。
圖像分類和標(biāo)注的問題可以理解為模式識(shí)別的問題,計(jì)算機(jī)無(wú)法像人類一樣具有抽象概括的能力,只能利用圖像的底層特征進(jìn)行識(shí)別分類。現(xiàn)有的圖像分類系統(tǒng)大部分是按照如圖1所示的工作流程:從圖像中提取視覺描述子向量;利用已經(jīng)學(xué)習(xí)到的碼本(codebook)對(duì)這些描述子向量進(jìn)行編碼,使得相似的描述子向量得到相近的標(biāo)簽;根據(jù)每個(gè)標(biāo)簽的出現(xiàn)頻率統(tǒng)計(jì)出圖像內(nèi)容的全局直方圖,得到圖像的視覺特征表示;將直方圖導(dǎo)入分類模型中,估計(jì)該圖像的類別標(biāo)簽。

圖1 圖像分類系統(tǒng)的一般工作流程
目前已經(jīng)有兩類圖像檢索系統(tǒng):基于文本的圖像檢索(text based image retrieval,TBIR)系統(tǒng)和基于內(nèi)容的圖像檢索(content based image retrieval,CBIR)系統(tǒng)。在基于文本的系統(tǒng)中,圖像要進(jìn)行人工標(biāo)注,然后通過這些標(biāo)注信息進(jìn)行檢索。然而,在CBIR中是由圖像的視覺特征(如顏色、紋理、形狀等)建立索引。很多人在該領(lǐng)域中取得了出色的研究成果,現(xiàn)在已經(jīng)可以使用的CBIR系統(tǒng)有QBIC、Informedia-Ⅱ、ALIPR、GazoPa等[2,3]。隨著研究的深入,人們發(fā)現(xiàn)CBIR系統(tǒng)存在兩個(gè)明顯的不足:低層可視特征和高層語(yǔ)義概念之間存在巨大鴻溝;與人類視知覺機(jī)制具有明顯的不一致性。為了縮小圖像底層特征和用戶檢索語(yǔ)義概念之間的“語(yǔ)義鴻溝”,部分研究者開始進(jìn)行語(yǔ)義圖像檢索的研究。微軟亞洲研究院開發(fā)了一個(gè)Web圖像檢索系統(tǒng)[4],目的是將傳統(tǒng)Web圖像檢索返回的結(jié)果重新進(jìn)行聚類。搜索的結(jié)果被聚類成不同的語(yǔ)義類別,對(duì)每個(gè)類別,都會(huì)選出幾張代表性的圖片,使用戶能夠馬上了解到這一類的主題。每一類里面的圖片則根據(jù)它們的視覺特征進(jìn)行組織,使其顯示結(jié)果更符合用戶的需求。其中,訓(xùn)練集的大小和質(zhì)量是影響分類效果的重要因素,現(xiàn)在基本使用人工收集訓(xùn)練集,這是件復(fù)雜的工作,當(dāng)需要分類的對(duì)象越多,要收集的訓(xùn)練集越大,消耗的人力也越多時(shí)。本文的重點(diǎn)是要解決該問題,高效地獲取訓(xùn)練分類模型所需的訓(xùn)練集圖像。本文所提出的解決方案為:一是依靠云計(jì)算技術(shù)解決訓(xùn)練集大小的問題,二是通過pLSA主題聚類的方式實(shí)現(xiàn)人機(jī)交互的訓(xùn)練集選取,從而提高效率。
2 基于Hadoop的圖像分類與標(biāo)注系統(tǒng)
云計(jì)算是一種新的IT資源提供模式,依靠強(qiáng)大的分布式計(jì)算能力,使成千上萬(wàn)的終端用戶能夠依靠網(wǎng)絡(luò)連接的硬件平臺(tái)的計(jì)算能力實(shí)施多種應(yīng)用。Hadoop[5]是一個(gè)分布式系統(tǒng)基礎(chǔ)架構(gòu),由Apache基金會(huì)開發(fā)。使用者可以在不了解分布式底層細(xì)節(jié)的情況下,搭建分布式計(jì)算平臺(tái)。Hadoop的核心組件有兩個(gè):Hadoop分布式文件系統(tǒng)(HDFS)和MapReduce,如圖2所示。HDFS是一個(gè)隱藏下層負(fù)載均衡、冗余復(fù)制等細(xì)節(jié)的分布式文件系統(tǒng),適合部署在廉價(jià)的機(jī)器上。它能提供高吞吐量的數(shù)據(jù)訪問,非常適合大規(guī)模數(shù)據(jù)集上的應(yīng)用,并對(duì)上層程序提供一個(gè)統(tǒng)一的文件系統(tǒng)API(應(yīng)用程序接口)。從圖2(a)可以知道,HDFS只有一個(gè)名字節(jié)點(diǎn),負(fù)責(zé)管理元數(shù)據(jù)操作和控制數(shù)據(jù)塊的放置,由數(shù)據(jù)節(jié)點(diǎn)實(shí)際保存數(shù)據(jù)塊。另外,MapReduce代表了map和reduce兩種操作,如圖2(b)。大多數(shù)分布式運(yùn)算可以抽象為MapReduce操作。map是把輸入分解成中間的key/value對(duì),reduce把key/value合成最終輸出。這兩個(gè)函數(shù)由程序員提供給系統(tǒng),下層設(shè)施把map和reduce操作分布在集群上運(yùn)行,并把結(jié)果存儲(chǔ)在分布式文件系統(tǒng)上。從圖2(b)可以知道,用戶提交MapReduce任務(wù)給主節(jié)點(diǎn),JobTracker負(fù)責(zé)將任務(wù)分配到各個(gè)子節(jié)點(diǎn)上,實(shí)現(xiàn)并行處理。
考慮到Hadoop的開源以及容易進(jìn)行開發(fā)的特點(diǎn),同時(shí)為了保證平臺(tái)的穩(wěn)定性,本系統(tǒng)以Hadoop+Ubuntu的方式進(jìn)行構(gòu)建。Ubuntu是一個(gè)完全以Linux為基礎(chǔ)的操作系統(tǒng),可自由地獲得,并提供社區(qū)和專業(yè)的支持。本系統(tǒng)的框架設(shè)計(jì)如圖3(a)所示。首先,利用云技術(shù)發(fā)揮互聯(lián)網(wǎng)中多臺(tái)硬件的計(jì)算能力,加快圖像抓取的速度,并獲取所需要的原始圖像集。其次,當(dāng)抓取到足夠的原始數(shù)據(jù)集以后,使用訓(xùn)練集提取模塊通過交互的方式幫助用戶選取恰當(dāng)?shù)挠?xùn)練集。第三,通過分類器學(xué)習(xí)模塊訓(xùn)練分類器。最后,分類標(biāo)注模塊利用這些分類器對(duì)新圖像進(jìn)行分類標(biāo)注。系統(tǒng)的硬件拓?fù)洌鐖D3(b)所示。從圖中可以看出,圖像抓取平臺(tái)中有一個(gè)主節(jié)點(diǎn),抓取任務(wù)通過安全外殼(SSH)協(xié)議提交到主節(jié)點(diǎn),由該節(jié)點(diǎn)負(fù)責(zé)將任務(wù)分配到所有的子節(jié)點(diǎn)。

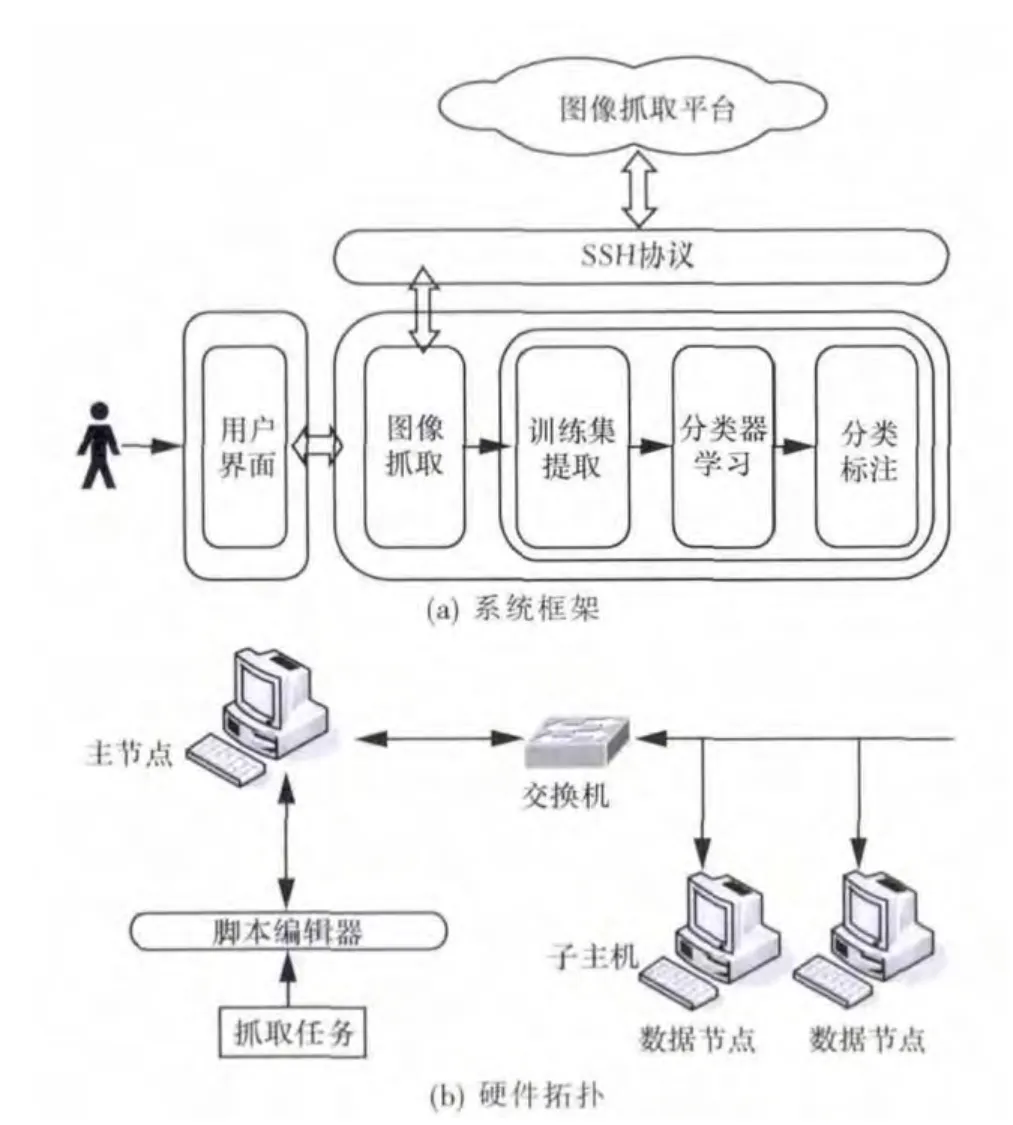
圖3 基于Hadoop+Ubuntu的系統(tǒng)架構(gòu)
從圖3(a)可以知道,分類標(biāo)注系統(tǒng)要滿足4個(gè)功能需求:原始圖像抓取、訓(xùn)練集提取、分類器模型學(xué)習(xí)和分類標(biāo)注。用戶通過訓(xùn)練集提取可以從原始數(shù)據(jù)集中生成訓(xùn)練集,然后學(xué)習(xí)分類器模型,利用分類器模型進(jìn)行圖像的分類和標(biāo)注,并對(duì)分類標(biāo)注結(jié)果進(jìn)行存儲(chǔ),以供用戶查詢或者檢索系統(tǒng)。本節(jié)將介紹分類標(biāo)注系統(tǒng)功能模塊設(shè)計(jì)。結(jié)合系統(tǒng)的架構(gòu),把系統(tǒng)分為圖像抓取模塊、訓(xùn)練集提取模塊、分類器學(xué)習(xí)模塊、分類標(biāo)注模塊,如圖4所示。

圖4 分類標(biāo)注系統(tǒng)的模塊結(jié)構(gòu)
其中,圖像抓取模塊負(fù)責(zé)將用戶的抓取任務(wù)提交到圖像抓取平臺(tái),通過SSH協(xié)議連接到云計(jì)算平臺(tái)的主節(jié)點(diǎn),從互聯(lián)網(wǎng)中抓取所需的原始圖像集;訓(xùn)練集提取模塊負(fù)責(zé)對(duì)原始圖像集進(jìn)行基于pLSA模型的主題聚類分析,通過用戶交互的形式選取出訓(xùn)練集圖片;分類器學(xué)習(xí)模塊的任務(wù)是根據(jù)用戶提供的訓(xùn)練集圖像學(xué)習(xí)分類器模型,并保存為分類器模型文件;分類標(biāo)注模塊完成對(duì)圖像或者圖像序列進(jìn)行分類標(biāo)注的任務(wù),并生成分類標(biāo)注文件。
訓(xùn)練集提取模塊分為3個(gè)子模塊:更新參數(shù)模塊、pLSA聚類模塊和選取訓(xùn)練集模塊。用戶通過更新參數(shù)模塊設(shè)置訓(xùn)練集提取任務(wù)的參數(shù),pLSA聚類模塊根據(jù)用戶的參數(shù)設(shè)置進(jìn)行原始圖像的主題聚類分析,完成后用戶可以通過訓(xùn)練集選取模塊選取所需的訓(xùn)練集圖片。
分類器學(xué)習(xí)模塊進(jìn)一步分為更新參數(shù)、SVM學(xué)習(xí)和更新分類器模型3個(gè)子模塊。用戶通過更新參數(shù)模塊設(shè)置分類器學(xué)習(xí)任務(wù)的參數(shù),SVM學(xué)習(xí)模塊根據(jù)用戶的參數(shù)設(shè)置從訓(xùn)練集中學(xué)習(xí)分類器模型,運(yùn)行成功后更新分類器模塊負(fù)責(zé)存儲(chǔ)更新分類器模型。
分類標(biāo)注模塊分為更新參數(shù)、SVM分類和生成類別標(biāo)注3個(gè)子模塊。用戶通過更新參數(shù)設(shè)置模塊設(shè)置任務(wù)的參數(shù),SVM分類模塊根據(jù)用戶的參數(shù)設(shè)置對(duì)圖像(或圖像序列)進(jìn)行分類標(biāo)注,并通過生成類別標(biāo)注模塊生成類別標(biāo)注文件。
3 實(shí)驗(yàn)結(jié)果
系統(tǒng)使用操作系統(tǒng)平臺(tái)為Ubuntu Desktop 9.10,分布式系統(tǒng)平臺(tái)為Hadoop 0.19.2。圖像抓取模塊主要用Java開發(fā),開發(fā)工具為Eclipse,運(yùn)行環(huán)境為sun-6-jdk、sun-6jre。選取2組測(cè)試集,第一組是 “Caltech-256 object category dataset”[6],第二組是利用網(wǎng)絡(luò)抓取平臺(tái)抓取的原始數(shù)據(jù)集,如圖5所示。通過實(shí)驗(yàn)發(fā)現(xiàn),對(duì)原始圖像集進(jìn)行10個(gè)主題的聚類,取得了較好的效果。下面將展示摩托車、蝴蝶測(cè)試的結(jié)果。
利用訓(xùn)練集提取模塊對(duì)原始圖像集進(jìn)行10個(gè)主題的聚類,結(jié)果見表1。從表1中可以看出,大部分聚類還是比較理想,可以直接去掉如聚類1、聚類3、聚類4、聚類7、聚類8、聚類10,從而實(shí)現(xiàn)了“按類選取”,加快了訓(xùn)練集的篩選速度。

圖5 原始圖像集

表1 摩托車和蝴蝶的10個(gè)主題聚類測(cè)試結(jié)果
4 結(jié)束語(yǔ)
隨著網(wǎng)絡(luò)的普及和多媒體數(shù)據(jù)獲取設(shè)備的發(fā)展,圖像和視頻的數(shù)據(jù)量都在飛速增長(zhǎng),多媒體資料的存儲(chǔ)索引成為熱門的研究領(lǐng)域。本文針對(duì)當(dāng)前圖像分類技術(shù)中都要面對(duì)的提取訓(xùn)練集問題,提出了一個(gè)基于Hadoop云平臺(tái)的解決方案。該方案基于現(xiàn)有文本圖像搜索引擎的圖像抓取器,實(shí)現(xiàn)基于云計(jì)算的圖像抓取平臺(tái),并在此基礎(chǔ)上利用pLSA模型,采用MSER和STAR區(qū)域特征,實(shí)現(xiàn)了主題聚類的訓(xùn)練集提取,同時(shí)通過對(duì)原始圖像集進(jìn)行基于主題的聚類,使得用戶可以“按類”篩選訓(xùn)練集,比“逐張”篩選要有效率得多。
1 Moosmann F,Nowak E,Jurie F.Randomized clustering forests for image classification.IEEE Transactions on Pattern Analysis and Machine Intelligence,2008,30(9):1632~1646
2 ALIPR.Automatic photo tagging and visual image search.http://www.alipr.com/,2012
3 GazoPa.Similar image search.http://www.gazopa.com/,2010
4 Cai D,He X F,Ma W Y,et al.Organizing www images based on the analysis of page layout and web link structure.Proceedings of 2004 IEEE International Conference on Multimedia and Expo,ICME’04,Sorrento,Italy,2004
5 Grangier D,Bengio S.A discriminative kernel-based approach to rank images from text queries.IEEE Transactions on Pattern Analysis and Machine Intelligence,2008,30(8):1371~1384
6 Griffin G,Holub A,Perona P.Caltech-256 Object Category Dataset.Technical Report,California Institute of Technology,2007
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
商用汽車(2016年11期)2016-12-19 01:20:16
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
