一種基于OpenCV的高效車牌識別系統實現
2014-03-16 05:51:54浙江萬里學院劉云鵬
電子世界 2014年9期
浙江萬里學院 劉云鵬 李 瑾
國網浙江寧波市鄞州區供電公司 潘 聞
1.緒論
車牌識別包括車牌定位、字符分割和字符識別。車牌定位技術有基于紋理特征的方法[1];基于顏色特征的方法[2];基于紋理和顏色結合的方法;基于Adaboost等各種分類器的方法;基于曲量場空間的方法[3]; 基于最近鄰鏈的方法[4]。字符分割技術有基于投影的方法[5];基于連通域的方法[6];將上述方法與其他技術進行結合[7];基于聚類方法[8]。字符識別技術有模版匹配法[9];機器學習訓練法[10-13]。
事實上,沒有一種特別通用的方法可以針對所有不同應用場景的車牌識別。本文所提出的基于OpenCV的車牌識別系統,主要針對車距在2-3米范圍內的靜態車輛圖像,光照可以有一定的模糊,并且允許車牌有輕微角度的傾斜。本文將灰度空間與HVS顏色空間結合來獲取垂直邊緣,可以獲取更加精確的車牌候選區域,并通過SVM(支持向量機)機器學習的方法定位最終車牌區域。由于本應用中,車牌定位區域相對精確,車牌圖像也不存在高光、模糊和遮擋等情況,使用連通域方法可以取得較好的字符分割效果。最后根據中國車牌的字符分布特點,不同字符位置使用不同的ANN(人工神經網絡)訓練,可以獲得較高的識別率。
2.系統實現
2.1 車牌定位
2.1.1 自適應二值化
(1)顏色空間轉換
原始圖像除了要轉為普通的灰度圖像,同時要轉為HVS色度空間,因為在本文所提的應用中,是近距離的車牌識別,大部分情況下車牌區域在S顏色空間有較為突出的效果。在OpenCV中通過函數cvtColor(src,dst,code)進行顏色轉換,對于灰度轉換code值為CV_BGR2GRAY,HVS轉為code值為CV_BGR2HSV。兩種顏色空間都要轉換和處理的目的會在“重疊區域選擇”部分詳細描述。
(2)高斯濾波
為了消除噪聲點,進行高斯濾波,使用OpenCV函數blur(src,dst,Size(5,5)),blur的缺省操作為高斯濾波,所以沒有設置類型,設置經驗值為5*5的模板。
(3)獲取垂直邊緣
車牌區域和圖像中其他區域相比,有著比較明顯的垂直邊緣,使用Sobel算子提取垂直邊緣,OpenCV函數為Sobel(src,dst,CV_8U,1,0,3,1,0)。
(4)自適應二值化
二值分割閾值由系統根據邊緣圖像內容自適應的確定,使用OpenCV函數threshold(src,dst,0,255,CV_THRESH_OTSU+CV_THRESH_BINARY),結果如圖1所示。
2.1.2 形態學閉操作
為了進一步獲取連通有效的車牌候選區域,要進行區域合并和剔除噪聲,使用形態學的閉操作可以有較好實現,OpenCV函數為morphologyEx(src,dst,CV_MOP_CLOSE,element),此處element為閉操作使用的結構化元素,根據經驗取形狀為矩形,大小為15*1,通過函數getStructuringElement(MORPH_RECT,Size(15,1))創建。操作結果如圖2所示。

圖1 自適應二值化圖像
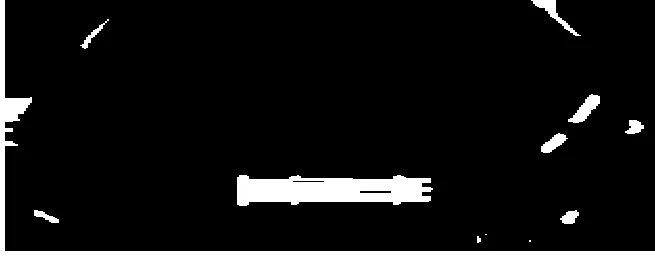
圖2 閉操作結果
2.1.3 區域過濾
調用OpenCV函數findContours(src,contours,CV_RETR_EXTERNAL,CV_CHAIN_APPROX_NONE)查找所有封閉區域的外輪廓,每個輪廓坐標保存在vector
2.1.4 重疊區域選擇
重疊區域選擇是為了更加準確的獲取到車牌區域,在前面所述的“顏色空間轉換”中,需要對普通灰度圖像和S顏色空間圖像同時處理,這是因為大多時候S顏色空間獲取的結果更加精確,當然有時也會出現普通灰度圖像獲取候選車牌區域更加準確的情況,不管何種情況,兩者的獲取區域都會有重疊,根據經驗取重疊區域中小的區域為候選,此處設定重疊比例閾值為40%。
2.1.5 候選區域標準化
對有傾斜的矩形區域進行水平旋轉處理,使用getRotationMatrix2D(rect.center,angle,1)產生變形矩陣對象rmat,rect為候選矩形區域,rect.center表示其中心點。有了變形矩陣對象,使用仿射變換進行旋轉。由于仿射變換會產生在原圖中沒有的像素點,需要插值處理,本文選用雙線性插值,如公式(1)所示:

式中G(x,y)表示仿射變化前對應像素,x和y為實數,j和u分別為x的整數和小數部分,k和v分別為y的整數和小數部分。對于仿射變換,可以表示為公式(2)形式:
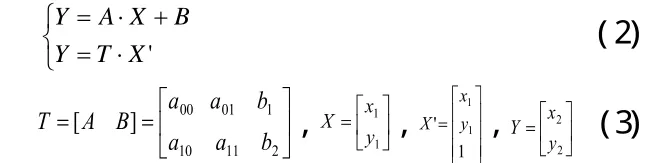
式中,(x1,y1)和(x2,y2)分別表示未轉換和已轉換坐標,T為仿射變換矩陣。仿射與插值調用OpenCV方法warpAffine(ori gin,rotated,rmat,origin.size(),INTER_LINEAR)實現,此處origin為原始輸入圖像,rotated為旋轉后的矩陣。旋轉后調用函數getRectSubPix(rotated,rect.size,rect.center,result)來提取水平像素矩陣。為了有效的訓練和分類圖像數據,將用于訓練的候選車牌區域標準化為144*33的大小,同時通過直方圖均衡來消除光線的影響。
2.1.6 學習與定位
SVM訓練樣本來自上面步驟中最終生成并保存的144*33標準圖像,如圖3所示,上面兩行為正確車牌圖像,下面兩行為非車牌圖像,將正確樣本與錯誤樣本分類到不同的目錄進行標識,并使用CvSVM類的train方法進行訓練,predict方法進行定位預測,如果返回值為1,說明該區域是車牌位置的可能性最高。

圖3 車牌正確區域與錯誤區域位置樣本圖

圖4 字符外接矩形
2.2 字符分割
本文使用連通域方法可以取得較好的字符分割效果,具體步驟如下:
Step1:對標準化的車牌圖像進行二值化,調用OpenCV函數threshold(src,dst,140,255,CV_THRESH_BINARY),此處取經驗值140作為黑白分割點;
Step2:獲取連通區域的輪廓與最小外接矩形,方法與“區域過濾”的方法一致,不再描述;
Step3:根據長寬比和高度進行過濾,長寬比例為33:20,取35%的誤差,最小高度為11,最大高度設置為33,由于數字1的寬度很小,所以將最小的長寬比設定為0.15。獲取外接矩形并過濾后結果如圖4所示。
Step4:將外接矩形中對應的字符圖像進行標準化處理。首先調用OpenCV的函數warpAffine(char_mat,dst,trans_mat,dst.size(),INTER_LINEAR,BORDER_CONSTANT,Scalar(0))對輸入的字符圖像char_mat仿射變換為正方形,所以dst為正方形矩陣,邊長取char_mat長和寬的最大值,trans_mat為2*3的變換矩陣。然后調用resize函數將dst轉為20*20的標準大小圖像;
Step5:如果未獲取ANN字符訓練樣本,則對所有標準化的字符圖像進行文件保存。
2.3 字符識別
本文采用ANN機器學習來進行單個字符的識別,使用最常用的MLP(多層感知器)算法。中國車牌中的7個字符從左到右,第一個是漢字,第二個是英文字母,第三個和第四個可能是英文字母或數字,最后三個是數字,根據這個特點,可以分成四種類型進行訓練,即:(1)全部使用漢字的訓練;(2)全面使用字母的訓練;(3)全部使用數字的訓練;(4)字母和數字一起的訓練。這樣可以大大提高字符識別率。每種類型的學習與識別過程是一致的,具體步驟如下。
Step1:讀取訓練樣本中標準化的字符圖像;
Step2:分別在5*5,10*10,15*15和20*20四種不同分辨率圖像上使用水平和垂直累計直方圖的方法進行特征提取。使用函數countNonZero計算每行或每列非零像素數量,并將結果存儲在一個矩陣對象m,通過所有元素除以m中最大值進行歸一化;
Step3:將特征矩陣和對應的分類標識進行存儲。全數字、全字母、數字字母和漢字分別對應訓練文件digi.xml、letter.xml、digi_letter.xml和chn.xml;
Step4:根據當前車牌字符的位置選擇對應的訓練文件進行讀入,選擇四種分辨率數據之一待訓練。對于如何選擇5*5,10*10,15*15和20*20,一般情況下是每種都進行訓練和識別,選擇效果最佳的一組分辨率;
Step5:定義每一層的神經元對ANN初始化。本文使用一個隱藏層,定義一行三列的矩陣,第一列為特征數,第二列為隱藏神經元數,第三列為分類數。OpenCV中ANN對應CvANN_MLP類,通過其create函數來初始化層數、神經元、激勵函數、alpha和 beta 參數。訓練通過CvANN_MLP類的train函數實現;
Step6:獲取當前待識別字符圖像的特征向量,方法與Step2中一致;
Step7:CvANN_MLP類調用predict函數來獲取特征向量的分類結果,分類結果為一個向量,長度與分類數一致,數據為特征向量屬于該分類的概率,再調用minMaxLoc函數得到概率最高的分類。

表1 實驗結果
3.實驗與分析
算法在CPU主頻2.7GHz,內存4Gb的WindowXP系統中實驗,開發工具為VS2010+OpenCV2.4.4。測試車輛圖片300張,拍攝距離2-3米,車牌傾斜在10%左右的小角度內,圖片分辨率為320*240,光照相對柔和。SVM訓練樣本數為170,樣本分辨率為144*33,正確車牌數100,非車牌數70。ANN訓練樣本總數為150,其中漢字、數字、字母以及數字字母訓練樣本數分別為40、30、40和40,樣本圖像分辨率為20*20。實驗結果如表1所示。
從實驗結果可以看出,本文中車牌定位準確率高達98.01%,識別準確率也有94.73%,每副平均識別時間60ms,達到了實時識別的需求。這是因為在本文的車牌識別應用中,車輛拍攝距離較近,光照較好,沒有任何遮擋和車牌相似的噪聲區域,只有少部分車牌有小角度的傾斜,所以車牌定位和識別的準確率都很高。
4.結論
本文針對車距在2-3米范圍內的靜態車輛圖像,提出一種基于SVM和ANN的車牌定位與識別算法,并使用OpenCV庫有效實現。首先將灰度空間和色度空間進行結合,在Sobel邊緣提取基礎上,進行自適應閾值下的二值化處理,通過對輪廓外接矩形的面積和長寬比初步定位車牌位置,然后利用SVM線下機器學習的方法更加精確的定位車牌位置。并采用尋找有效外部輪廓的方法進行字符分割,最后對漢字位置、英文位置、數字位置和英文數字混合位置分別使用ANN方法進行字符識別。實驗證明,該方法定位準確率和字符識別率高,有一定應用價值。進一步研究內容包括:(1)在圖像較模糊和噪聲較大情況下的車牌識別;(2)遠距離下的車牌識別。
[1]Lang Yao,Sun Yanpeng.The study of license plate location and character segmentation[C].Proceedings of SPI E,Singapore,Singapore;SPIE,2012,8349:83491W.
[2]鄭成勇.一種RGB顏色空間中的車牌定位新方法[J].中國圖象圖形學報,2010,15(11):1623-1628.
[3]姜文濤,劉萬軍.基于曲量場空間的車牌定位與識別[J].電子學報,2011,39(11):2554-2560.
[4]苗立剛.基于最近鄰鏈的車牌檢測算法[J].自動化學報,2011,37(10):1272-1279.
[5]Roy A,Ghoshal D P.Number plate recognition for use in different contries using an improved segmentation[C].Proceedings of International Conference on Emerging Trends and Applications in Computer Scence.Shillong,India;IEEE,2011:1-5.
[6]Yoon Y W,Ban K D,Yoon H,et al.Blob extraction based character segmentation method for automatic license plate recognition system[C].Proceedings of IEEE International Conference on System,Man,and Cybernetics.Gyeongiu,Kor ea;IEEE,2011:2192-2196.
[7]顧弘,趙光宙,齊冬蓮,等.車牌識別中先驗知識的嵌入及字符分割方法[J].中國圖象圖形學報,2010,15(5):749-756.
[8]李旭,徐舒暢,尤玉才,等.基于聚類分析的個性化美國車牌分割算法[J].浙江大學學報(工學版),2012,46(12):2155-2159.
[9]Gao Jianjun,Blasch Erik,Pham Khanh,et al.Automatic vehicle license plate recognition with color component texture detection and template matching[C].Proceedings of SPIE,Baltimore,MD,United states;SPIE,2013,8739:87390Z.
[10]Sedighi Amir,Vafadust Mansur.A new and robust method for character segmentation and recognition in license plate images[J].Expert Systems with Applicatio ns,2011,38(11):13497-13504.
[11]磨少清,劉正光,張軍.基于圖像模糊度與主成分分析的車牌漢字識別[J].光電子.激光,2010,21(3):444-447.
[12]劉高平,趙杜娟,黃華.基于自編碼神經網絡重構的車牌數字識別[J].光電子.激光,2011,22(1):144-148.
[13]Wan Yan,Yao Li.An efficient license plate character recognition algorithm based on shape context[C].Proceedings of SPIE,Sanya,China;SPIE,2013,8761:876109.
猜你喜歡
今日農業(2021年9期)2021-11-26 07:41:24
發明與創新·小學生(2021年3期)2021-03-25 11:48:49
兒童故事畫報(2019年5期)2019-05-26 14:26:14
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
電測與儀表(2015年5期)2015-04-09 11:30:52
