基于代數連通性的復雜網絡割邊模型研究
2014-04-03 01:45:54趙富強邢恩軍
計算機工程與應用 2014年11期
關鍵詞:模型
趙富強,張 爍,何 麗,邢恩軍
1 引言
隨著近 10年來許多社會網絡媒體的迅猛發展,例如Twitter、Facebook和Google+等社交網站,社會網絡擁有更龐大的數據量,節點個數達到百萬甚至上億的龐大數據[1]。龐大數據的處理也促使了復雜網絡模型和方法的發展。復雜網絡混合度上升,復雜網絡社區的個數不易確定,社區不平衡性問題也顯現出來。雖然一些社團發現算法通過一定的割邊模型可有效識別復雜網絡中的社區,但算法的復雜度依然很高,割邊效率不高,例如,經典社區發現算法Girvan-Newman,該算法的主要缺點是每次迭代只能刪除一條邊,算法復雜度較高,GN算法的總時間復雜度為O(m2n);對于稀疏網絡,GN算法的復雜度為O(n3) ,其中n為節點數,m為邊數。Radicchi等人從提高算法運行效率和如何選擇 GN算法層次劃分結果中的最優劃分出發[2],提出了一種自包含的GN算法變種[3]。Wilkinson、Huberman和 Tyler在通過采樣部分結點來計算邊的最短路徑介數的方法,提高了算法的計算速度,但計算精度有所降低。Chen和Yuan指出,因為在計算邊介數時考慮了所有可能的結點間最短路徑,GN算法給出的社團劃分往往是不均衡的,據此提出了一種只考慮結點間結點不相交的所有最短路徑來計算邊的介數的GN算法變種[4]。Fortunato等人則提出利用信息中心度(information centrality)的方法來判斷社團之間的邊,信息中心度高的結點往往對應于社團之間的邊[5]。雖然該 GN算法變種在網絡社團結構比較模糊的情況下有較好的劃分準確性,但其時間復雜度非常高,為O(m3n),即稀疏網絡上為O(n4)。一些學者提出的社團分割模型,但時間復雜度都相對較高,Clauset et al.[6]時間復雜度為O(n log2n),Duch & Arenas[7]時間復雜度為O(n2logn),Eckmann & Moses[8]時間復雜度為O(m<k2>),Capocci et al.[9]時間復雜度為O(n2);Zhou & Lipowsky[10]時間復雜度為O(n3)。如何在保證分割結果準確的基礎上,改進割邊模型效率,有效降低復雜網絡社區發現算法的時間復雜度,快速有效地將網絡中的社區挖掘出來,基于代數連通性提出了貪婪譜優化割邊模型(Greedy Algorithm Spectral Optimal Cut Edge Model, GACEM)和基于邊中心性測度的割邊模型(Edge Centrality Cut Model,ECCM)。
2 貪婪譜優化割邊模型
圖的拉普拉斯矩陣的第二小特征值2λ被定義為代數連通性,如果圖是連通的則代數連通性大于零,該值為零時,圖被二分;為了改善該方法一次只能把圖二分,文獻[11]提出了選擇頭兩個特征向量,一次劃分三個社區。代數連通性反應了網絡中節點間連接的緊密程度,可以用于計算網絡的健壯性和系統的可靠性。與傳統的連通性測量函數不同,代數連通性函數依賴于網絡中連通節點的數量。在隨機網絡中,代數連通性函數值與節點的個數和平均度負相關。
復雜網絡代數連通性函數λ2(L(x))是單調凸函數,如果G1=(V,E1)和G2=(V,E2)中E1?E2,則λ2(L1)≤λ2(L2)。在一個復雜網絡中如果邊越少,則代數連通性越差。可以通過利用L的第二特征向量最小化RatioCut[12]近似求得λ2(L(x)),公式如下:
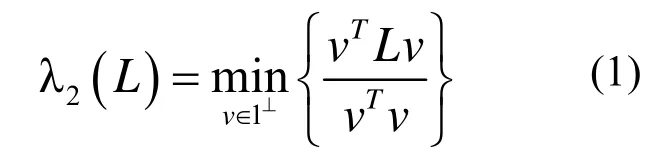
但其時間復雜度較高,可以通過Gossip算法[13]近似計算代數連通性函數,有效降低時間復雜度。由于第二特征值與復雜網絡的結構有直接關系,如果網絡相對稀疏則第二特征值較小,網絡連通性較差,相反則第二特征值較大,網絡連通性較好。模型將λ2定義為網絡連通性函數2(())L xλ。將通過優化模型選擇使網絡連通性下降最快的邊集。所以最優化問題定義如下:

對于復雜網絡社區發現問題,主要算法細節如下。給出網絡的原始圖G=(V,E)和一個常數k,我們將通過模型從E集合中選擇k條對代數連通性影響最大的邊,假設。公式2被定義為:
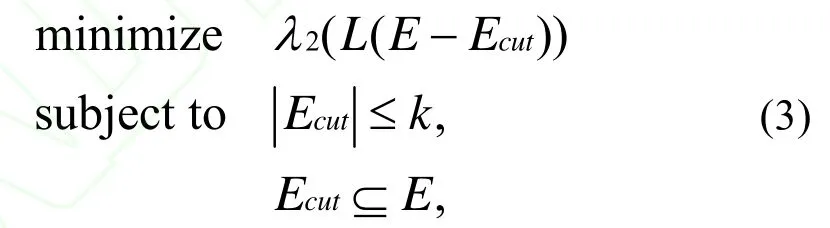
這個模型可以被構造為一個布爾函數。圖G的每條邊可以用一個布爾變量x∈{0,1}m表示。如果邊,則相應的xl= 1,否則為0。使L為G對應的拉普拉斯矩陣。公式3被重新定義,變量為x向量:

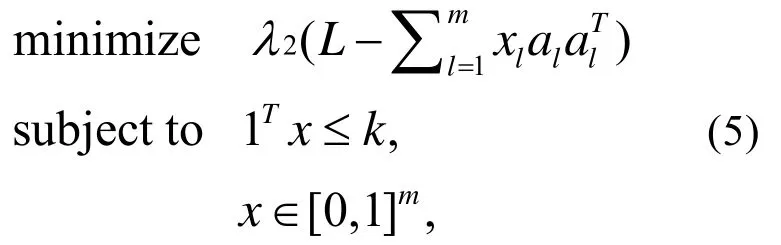
公式(5)給出了公式(4)的上確界,如果公式(5)的最優解是布爾向量,則其結果也是公式(4)的最優解;否則選擇x向量中最大的k個值為模型最優解。
邊的權重計算可有效用于社區分割中,社區內部的邊連接相對密集,社區間的邊連接相對稀疏[14]。當復雜網絡被分割為兩個非連通子圖時,是模型本次迭代的結束標志,但復雜網絡中節點的度符合冪律分布,大量節點的度小于k,所以刪除該節點的邊可將該節點剝離出來,形成兩個極不對稱的非連通子圖,從而影響模型社區發現的結果。所以模型根據每條邊符權重wl,0≤wl≤1,該權重使連接不同社區間的邊權重較大,連接同社區內部節點的邊權重較小。在模型優化過程中保持復雜網絡的連通特性。權重定義如下所示:

其中l~(i,j),fi與fj為費德勒向量第i和j分量。
兩個社區之間節點的鄰接節點往往均勻分布于兩個不同社區內部,其對應費德勒向量的值相對較小,所以模型對邊l取權重wl與該邊連接的兩個節點對應費德勒向量的值(fi和fj)成反比,當邊l連接兩個不同社區內的節點時,則該值權重較小,相反權重較大。考慮權重的優化模型為:

半正定規劃(SDP)[15]可以解模型(7)求最優解,但其時間復雜度較高,采用貪婪策略來解決大規模的復雜網絡分割問題。
模型首先根據 Newman給出的邊介數(edge betweenness)計算每條連接邊的中心性,然后根據邊中心性值選出前mc個邊作為候選刪除邊,其中k?mc?m 。利用模型(7)在mc中選擇k條對網絡代數連通性影響最大的邊。在解模型(7)時,可以采取梯度下降法求得最優解,目標函數的梯度為,代數連通性函數λ2(L(xl))對 xl的偏導數為,其中l~(i, j)。
貪婪策略的啟發性步驟如下:
(1) 計算復雜網絡中邊的介數;
(2) 根據中心性測度選出mc條邊作為候選刪除邊,通過刪邊學習器模型刪除k條邊。
由于算法需要計算邊的介數,只是在一次刪除邊的數量上有不同,算法的時間復雜度較高。
3 基于邊中心性測度的割邊模型
定義1 社會網絡的邊集中刪除一個使該網絡代數連通性下降最快的邊稱為中心邊,邊所具有的性質稱為邊中心性(Edge Centrality)。
定義2 社會網絡中處于每個社區核心位置的節點稱為中心節點。
基于邊中心性測度的割邊模型(ECCM)與傳統的社會網絡發現算法不同,模型采取譜分析方法對每條邊定義邊中心性測度,與傳統的利用最短距離,隨機游走和節點間的阻抗不同,速度更快,更適合處理大規模社區結構。刪除譜中心性最高的節點,然后重新計算剩余節點的譜中心性。快速復雜網絡割邊模型算法描述如下:
(1) 計算G中每條邊的譜中心性測度;
(2) 找到譜中心性最高的邊l,刪除那條邊;更新復雜網絡為Gnew。
本模型邊的中心性測度是基于代數連通性函數給出的。代數連通性函數的梯度為,其中l~(i, j),與第二節方法相同。
4 實證分析
(1)真實網絡實驗
在實驗中,采用了真實網絡中的football網絡,115個節點、613條邊。分別采用隨機刪除一條邊、GN方法刪除介數值最大的邊、GACEM方法刪除k條邊和ECCM方法;實驗結果如圖3所示。football網絡的初始λ2為1.459001,隨機刪除120條邊,λ2仍然大于1;GN方法,刪除60條介數值最大的邊后λ2為 0,網絡被成功分割,但割邊時間較長;GACEM 方法刪除 23次后λ2為 0,網絡被成功分割,割邊時間較GN短,ECCM方法時間更快,后三種方法的分割結果完全一致,即準確率得到驗證;實驗結果如圖1所示。

圖1 真實網絡割邊模型比較
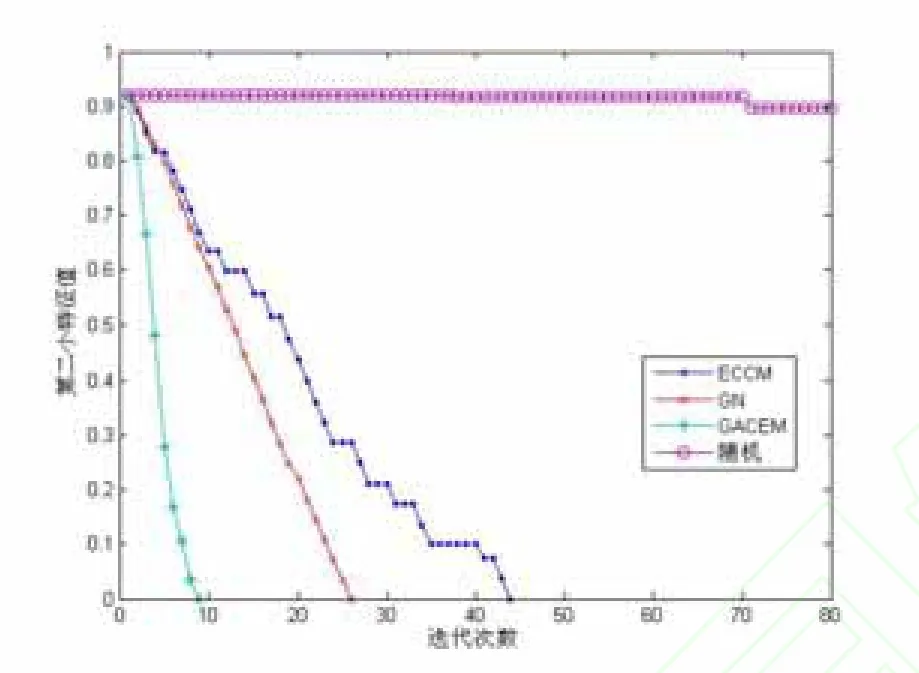
圖2 模擬網絡割邊模型比較
(2)模擬網絡實驗
模擬網絡的pout值為0.1,1000個節點,7572條邊。網絡的初始λ2為0.919444,隨機刪除80條邊,λ2仍然大于0.8;GN方法,刪除25條介數值最大的邊后λ2為0,網絡被成功分割,但割邊時間較長;GACEM方法刪除8次后λ2為0,網絡被成功分割,割邊時間較GN短,ECCM方法時間最快,分割結果一致;實驗結果如圖2所示。
(3)模型復雜度分析
傳統的GN分割算法在每次迭代過程中刪除一條邊中心性最高的邊,每次迭代算法的時間復雜度為O(n2m),其中n為節點數量,m為邊數量。與之相較,復雜網絡被分割為兩個非連通子圖前,譜優化社區發現模型每次迭代通過割邊學習模型刪除k條邊,基于Lanczos算法計算拉普拉斯矩陣第二小特征值對應的特征向量(費德勒向量),時間復雜度為O(m1×n),其中m1為算法迭代的次數,通常要上百次,該算法空間復雜度較高,需要存儲m1個n維的 Lanczos向量;然后基于費德勒向量為每條邊計算其譜中心性測度,算法時間復雜度為O(m);從中刪除一條譜中心性最高的邊時間復雜度為O(m);使用代數連通性函數λ2(L(Gnew))計算更新后網絡的代數連通函數,基于Gossip算法的時間復雜度為O(m2×log(n)),其中m2為算法迭代次數m2為常數。所以割邊學習模型執行一次操作的時間復雜度為當復雜網絡被分割為兩個非連通子圖時,算法在每個非連通子圖中遞歸執行,如果并行地在每個子圖中執行割邊模型,算法執行效率更會顯著提升。
5 結論
拉普拉斯矩陣的第二小特征值決定復雜網絡的連通性,當該值為零時,網絡被二分。傳統的割邊模型時間復雜度高,為了降低時間復雜度,基于代數連通性提出了貪婪譜優化割邊模型和基于邊中心性測度的割邊模型,通過對真實網絡和模擬網絡的實驗,割邊模型使得時間復雜度降低同時,分割結果與GN一致。但模型是否適用于大規模復雜網絡、如何把兩個模型結合起來進一步降低時間復雜度,值得今后進一步深入研究。
[1]Charu, C., Aggarwal. Social Network Data Analytics[M].Springer Science + Business Media, LLC (2011).
[2]Girvan M, Newman M E J. Community structure in social and biological networks[J].Proceedings of the National Academy of Sciences of the United States of America,2002,99(12):7821-7826.
[3]Radicchi F, Castellano C, Cecconi F, et al. Defining and identifying communities in networks[J]. Proceedings of the National Academy of Sciences of the United States of America, 2004, 101(9):2658-2663.
[4]Chen J, Yuan B. Detecting functional modules in the yeast protein–protein interaction network[J]. Bioinformatics,2006, 22(18):2283-2290.
[5]Fortunato S, Latora V, Marchiori M. Method to find community structures based on information centrality[J].Phys. Rev. E, 2004, 70(5):056104.
[6]Clauset, M.E.J. Newman, C. Moore, Finding community structure in very large networks, Phys. Rev. E 70 (6),2004, 066111.
[7]J. Duch, A. Arenas, Community detection in complex networks using extremal optimization, Phys. Rev. E 72(2), 2005, 027104.
[8]J.-P. Eckmann, E. Moses, Curvature of co-links uncovers hidden thematic layers in the World Wide Web, Proc. Natl.Acad. Sci. USA 99 (2002) 5825-5829.
[9]Capocci, V.D.P. Servedio, G. Caldarelli, F. Colaiori, Detecting communities in large networks[J], Physica A 352,2005, 669-676.
[10]H. Zhou, R. Lipowsky, Network brownian motion: A new method to measure vertex-vertex proximity and to identify communities and subcommunities[J], Lect. Notes Comput. Sci. 3038, 2004, 1062-1069.
[11]Thomas Richardson, Peter J. Mucha, and Mason A. Porter.Spectral tripartitioning of networks[J]. Physical Review E,2009, 80(3):036111:89.
[12]Ren-Cang Li. Accuracy of Computed Eigenvectors via Optimizing a Rayleigh Quotient[J]. BIT Numerical Mathematics 2004,44(3) :585-593.
[13]S. Boyd, A. Ghosh, B. Prabhakar, and D. Shah, Gossip algorithms: Design, analysis and applications[J], Proceedings of IEEE Infocom ,2005, 3:1653-1664.
[14]Z. Xia, Z. Bu, Community detection based on a semantic network[J], Knowledge Based Systems, 2012, 26:30-39.
[15]Y. Kim and M. Mesbahi, On maximizing the second smallest eigenvalue of a state-dependent graph laplacian[J], IEEE Transactions on Automatic Control, 2006,51(1):116-120.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
