BP神經網絡在測井數據預測原煤灰分中的應用
2014-05-03 02:56:00謝小國曹莉蘋
四川地質學報 2014年2期
謝小國,曹莉蘋
(四川中成煤田物探工程院有限公司,成都 610000)
煤質的主要參數有灰分、水分、含碳量和揮發分等,在這些參數中,煤層灰分(Ad)是決定煤用途的重要質量指標,因而煤層的原煤灰分分析是煤質分析中的重要組成部分。以往利用統計模型法和體積模型法分析原煤灰分只是通過簡單的數學表達式表達測井參數與灰分之間的關系[1-2],大都沒有涉及到精度研究,所以有時分析結果會產生較大誤差。
BP(Back Propagation)神經網絡是目前應用最為廣泛的神經網絡之一[3]。采用BP神經網絡對原煤灰分進行研究,可建立利用測井資料分析原煤灰分的BP神經網絡模型,通過網絡訓練與測試,驗證BP神經網絡用于原煤灰分分析的可行性。
1 BP神經網絡
BP神經網絡屬于多層前饋神經網絡,網絡模型一般由輸入層、隱含層和輸出層構成,其中隱含層可以有多個。BP神經網絡是一種誤差反向傳播算法的學習過程,由信息的正向傳播和誤差的反向傳播兩個過程組成。正向傳播時,輸入樣本從輸入層傳入,通過各隱含層逐層處理后,傳向輸出層。若輸出層的實際輸出與期望輸出不符,則轉入誤差的反射傳播階段。誤差的反向傳播是將輸出誤差以某種形式通過隱含層向輸入層逐層反傳,并將誤差分攤給各層的所有單元,從而獲得各層單元的誤差信號,并以此作為修正單元權值的依據。通過正反向傳播的不斷迭代,不斷調整其權值,最后使信號誤差達到可接受的程度或達到預先設置的學習次數為止[4]。
2 基于BP神經網絡分析原煤灰分
測井某些參數與原煤灰分具有良好的相關性,在掌握川東某礦區大量實測井數據和部分煤質實驗數據的基礎上,利用測井數據建立預測原煤灰分的BP神經網絡模型。原煤灰分預測主要步驟如下:
1)煤質實驗數據和測井數據預處理;
2)選取網絡訓練樣本和測試樣本;
3)構建BP神經網絡,進行網絡訓練和網絡測試。
2.1 數據預處理
測井參數中自然伽馬(GR)、密度(DEN)和視電阻率(NR)是敏感反應煤質的重要參數,按0.20m的采樣間隔在煤層位置處采集這三種測井參數的測井響應值。由于相同測井數據測井環境不同,不同測井數據量綱不一致,因而需要對所有測井參數做環境校正及對測井響應值做歸一化處理,有助于數據的同等條件分析。
歸一化處理的計算公式為:
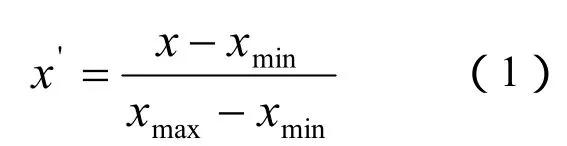
其中x是表示煤層的測井參數原始數據,x’是歸一化處理后的數據, xmax和xmin分別為采集區間內的測井參數最大值和最小值。通過(1)式計算出歸一化后樣本數據見表1。
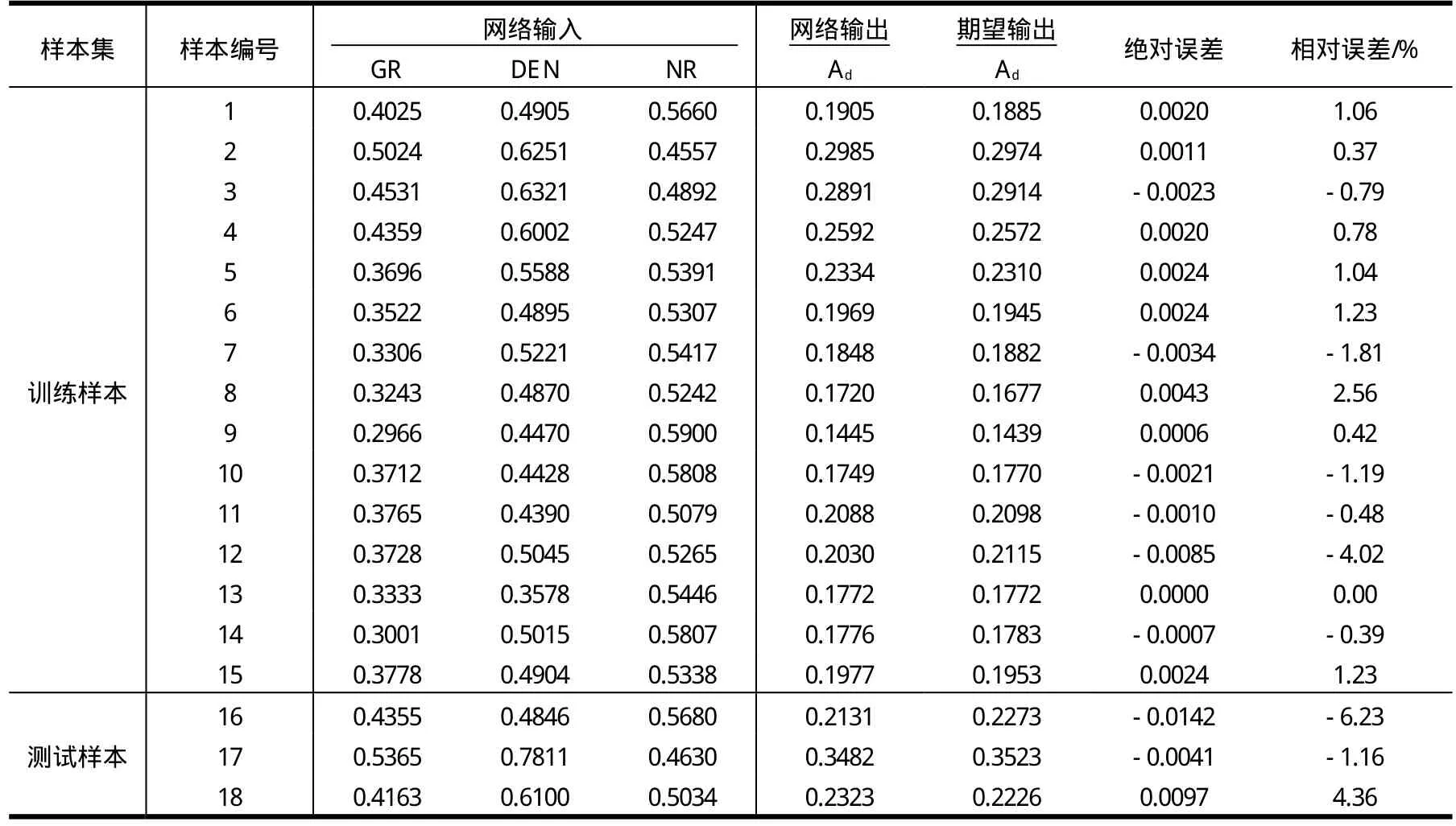
表1 網絡樣本數據及輸出結果分析表
2.2 訓練樣本與測試樣本
在歸一化樣本向量中,網絡輸入為自然伽馬、密度和視電阻率等3個因子,網絡輸出為相應的原煤灰分。目前,訓練樣本數目的確定還沒有通用的方法,一般認為,樣本過少可能使得網絡的表達不夠充分,從而導致網絡的外推能力不夠,因而從提高網絡精度的角度出發,網絡訓練樣本的數目越多越好,但是訓練樣本過多可能會出現樣本冗余現象,導致網絡訓練負擔增加,從而可能出現信息量過剩使得網絡出現過擬合現象[5]。根據樣本數據選擇的原則,結合本文實際問題,選擇18個樣本中的15個樣本數據作為訓練樣本集,用于訓練神經網絡,選擇3個樣本數據作為測試樣本集,用于測試網絡的訓練效果。
2.3 BP神經網絡結構模型
理論分析證明,單隱含層的感知器可以映射所有連續函數,因而具有三層(1個輸入層、1個隱含層和1個輸出層)的神經網絡結構即可實現任意非線性映射問題[6]。因此建立基于BP神經網絡的測井數據原煤灰分分析模型,選擇三層神經網絡拓撲結構:輸入層、隱含層(單隱含層)、輸出層。
網絡輸入向量有自然伽馬、密度和視電阻率等3個元素,所以輸入層神經元數為3個。網絡輸出向量為原煤灰分1個元素,所以輸出層神經元數為1個。隱含層神經元個數比較難確定,無統一規律,一般通過反復試驗確定。確定隱含層神經元數的常用方法是試湊法,通過逐漸增加隱含層節點數,對樣本進行訓練,確定誤差最小時對應的隱節點數。確定隱含層神經元數的經驗公式為:
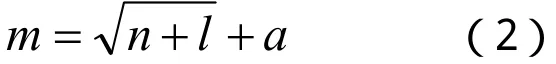
其中m為隱層節點數,n為輸入層節點數,l為輸出層節點數,a為1~10之間的常數。由(2)式確定隱含層神經元數為7個。因此BP神經網絡的結構為(1,7,1)型,網絡模型結構如圖1。
BP神經網絡的訓練次數最大為1000次,訓練目標為1×10-5。當訓練次數大于最大訓練次數或訓練誤差小于訓練目標時停止訓練。
2.4 網絡訓練與測試
為了測試網絡預測原煤灰分效果,分別用訓練樣本和測試樣本作為網絡輸入。用訓練樣本訓練神經網絡,經過14次迭代,網絡誤差精度達到要求(1×10-5),網絡訓練停止,如圖2。通過訓練好的網絡可能用測試樣本進行測試,網絡輸出結果與其期望輸出的對比見表1。
2.5 實驗結果分析
從表1可見,利用測井資料建立的BP神經網絡分析原煤灰分效果良好,訓練樣本輸出結果的誤差很小,相對誤差在-4.02%~2.56%,說明訓練精度較高。測試樣本輸出結果的絕對誤差較前者有所增加,但相對誤差最大也只有6.23%,說明網絡具有較好的泛化能力,對訓練樣本之外的數據可以給出相對準確的預測結果。
3 結論

圖1 網絡結構模型

圖2 BP神經網絡訓練結果
BP神經網絡的高度非映射性和自我學習能力,很好地解決了多種測井參數與原煤灰分的非線性關系,網絡輸出結果與期望結果一致性好,因而采用 BP神經網絡建立測井參數分析原煤灰分的模型具有較高的可行性和預測精度。但 BP神經網絡對樣本數據具有很大的依賴性,當樣本數據較少時,網絡學習能力差,預測效果則不理想。同時,網絡結構和網絡參數的確定非常關鍵,有待進一步優化。
[1] 王艷梅, 鄧霜嶺. 貴州某礦區煤中灰分與測井參數相關性研究[J]. 測井技術, 2006, 30(2): 173~176.
[2] 孟召平, 朱紹軍, 賈立龍, 等. 煤工業分析指標與測井參數的相關性及其模型[J]. 煤田地質與勘探, 2011, 39(2): 1~6.
[3] 飛思科技產品研發中心. 神經網絡與Matlab7實現[M]. 北京: 電子工業出版社, 2005.
[4] 李春輝, 陳日輝, 蘇恒瑜. BP神經網絡在煤與瓦斯突出預測中的應用[J]. 礦冶,2010, 19(3): 21~23.
[5] Sassan Saatchi, Kerry Halligan, et al. Estimation of forest fuel load from radar remote sensing [J]. IEEE Transactions on Geoscience and Remote Sensing, 2007, 45(6):1726~1740.
[6] 何長虹, 黃全義, 申世飛, 等. 基于BP神經網絡的森林可燃物負荷量估測[J]. 清華大學學報(自然科學版), 2011,51(2): 230~233.
