大數(shù)據(jù)基準測試流程與測試工具
2014-05-18 08:12:04姜春宇孟苗苗
信息通信技術 2014年6期
關鍵詞:數(shù)據(jù)處理
姜春宇 孟苗苗
1 工業(yè)和信息化部電信研究院標準所,云計算標準與測試驗證北京市重點實驗室 北京 100191
2 中國聯(lián)合網(wǎng)絡通信有限公司 北京 100033
引言
互聯(lián)網(wǎng)的普及已經(jīng)連接了全世界近30億人口,目前,互聯(lián)網(wǎng)上的網(wǎng)頁數(shù)目已經(jīng)突破10億[1],大量的數(shù)據(jù)在網(wǎng)絡中產生,而新的互聯(lián)網(wǎng)技術和應用的結合形成了豐富的數(shù)據(jù)源,并帶來數(shù)據(jù)量爆發(fā)式的增長。大數(shù)據(jù)在數(shù)據(jù)量、數(shù)據(jù)類型和處理時效性等方面帶來了新的挑戰(zhàn),應運而生的大數(shù)據(jù)處理技術采用分布式文件系統(tǒng)、分布式并行計算框架等模型以低廉的價格解決大數(shù)據(jù)的挑戰(zhàn)。新的計算框架和數(shù)據(jù)庫系統(tǒng)層出不窮,大數(shù)據(jù)產品和系統(tǒng)不斷推陳出新,催生出對這些產品和技術進行基準對比的需求。
大數(shù)據(jù)基準測試從具體應用中抽象出有代表性的負載,根據(jù)真實數(shù)據(jù)的特征和分布生成可擴展的數(shù)據(jù)集,以相應的指標衡量負載處理數(shù)據(jù)集的效果,以此來比較大數(shù)據(jù)處理系統(tǒng)的性能。本文結合大數(shù)據(jù)處理系統(tǒng)的特點,闡述大數(shù)據(jù)基準測試的要素和構建流程,最后從數(shù)據(jù)、負載和軟件棧等方面比較現(xiàn)有基準測試工具,并展望未來基準測試工具的發(fā)展方向。
1 大數(shù)據(jù)起源和特點
隨著互聯(lián)網(wǎng)技術的發(fā)展,產生了越來越多的數(shù)據(jù)來源。互聯(lián)網(wǎng)應用記錄著用戶每天在網(wǎng)上的行為數(shù)據(jù),用戶的社交數(shù)據(jù)、搜索數(shù)據(jù)、購物數(shù)據(jù)都被一一記錄下來。而線下的生活也處處與網(wǎng)絡相關,通話記錄、醫(yī)療數(shù)據(jù)、環(huán)境數(shù)據(jù)、財務數(shù)據(jù)也通過網(wǎng)絡留存下來。工業(yè)互聯(lián)網(wǎng)中的機器配備了傳感器和網(wǎng)絡傳輸裝置,積累了大量機器數(shù)據(jù)。物聯(lián)網(wǎng)連接地球上所有的人和物,感知并跟蹤著物體和人的狀態(tài)。據(jù)IDC預測,從2005年到2020年,全球數(shù)據(jù)量將會從130EB增長到40ZB[2]。
隨著數(shù)據(jù)源種類的激增,新的數(shù)據(jù)不僅在數(shù)據(jù)量上有了很大的體量,其數(shù)據(jù)結構也不同于以往的關系型數(shù)據(jù)結構,智能設備、傳感器和各種應用的興起,視頻、圖片、音頻、文檔、網(wǎng)頁和日志等大量非結構化的數(shù)據(jù)蜂擁而來,為當前的數(shù)據(jù)處理帶來新的挑戰(zhàn)。互聯(lián)網(wǎng)服務的進化,使得用戶對數(shù)據(jù)處理的速度有了更高要求,數(shù)據(jù)量規(guī)模和數(shù)據(jù)類型復雜性的增加對大數(shù)據(jù)處理速度帶來挑戰(zhàn)。IBM從四個維度定義大數(shù)據(jù),即數(shù)量(Volume)、種類(Variety)、速度(Velocity)、真實性(Veracity)[3]。大數(shù)據(jù)具備大體量、多樣性、高時效性和真實性等特征。
2 大數(shù)據(jù)處理平臺的構成
大數(shù)據(jù)的大體量、多樣性和處理的時效性是傳統(tǒng)單設備縱向擴展無法解決的,這種挑戰(zhàn)首先在互聯(lián)網(wǎng)搜索中體現(xiàn)出來,搜索引擎需要檢索和存儲的網(wǎng)站數(shù)量龐大,以非結構化數(shù)據(jù)為主,為此谷歌率先于2004年提出一套分布式數(shù)據(jù)處理的技術體系,即能夠橫向擴展的分布式文件系統(tǒng)(GFS)、分布式計算系統(tǒng)(MapReduce)和分布式數(shù)據(jù)庫(BigTable)等技術,以較低成本很好地解決了大數(shù)據(jù)面臨的困境,奠定了大數(shù)據(jù)技術的基礎。受谷歌論文啟發(fā),Apache Hadoop實現(xiàn)了自己的分布式文件系統(tǒng)(HDFS)、分布式計算系統(tǒng)(MapReduce)和分布式數(shù)據(jù)庫(Hbase),并將其開源,從而加速了大數(shù)據(jù)技術和應用的發(fā)展。大數(shù)據(jù)處理平臺主要由分布式文件系統(tǒng)、分布式計算平臺、分布式存儲系統(tǒng)等構成。以Hadoop為例,其基本組件如圖1所示。
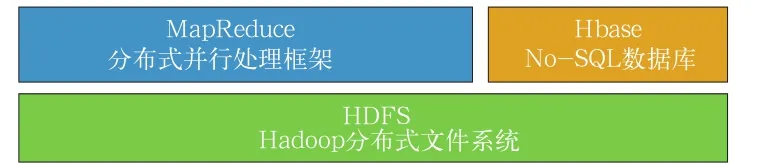
圖1 Hadoop基本組件
3 大數(shù)據(jù)基準測試要素
基于Hadoop和Spark原理的大數(shù)據(jù)處理平臺在工業(yè)界和學術界都得到了廣泛應用,谷歌、Facebook、百度、阿里巴巴等互聯(lián)網(wǎng)公司早已研發(fā)部署了大數(shù)據(jù)處理系統(tǒng),越來越多的中級企業(yè)開始在大數(shù)據(jù)基礎平臺之上開發(fā)大數(shù)據(jù)應用,IDG調研了751家企業(yè),其中49%的企業(yè)反饋已經(jīng)或正在實現(xiàn)大數(shù)據(jù)項目[4]。盡管大數(shù)據(jù)的平臺和應用發(fā)展迅速,但缺少基準來衡量大數(shù)據(jù)平臺的性能,而且大數(shù)據(jù)系統(tǒng)的復雜性、多樣性和變化性為評估帶來很大困難。
大數(shù)據(jù)基準測試能夠評估和比較大數(shù)據(jù)系統(tǒng)和架構,其主要作用有三個方面。1)它能提升大數(shù)據(jù)領域的技術、理論和算法,并挖掘出大數(shù)據(jù)的潛在價值和知識。2)它能幫助系統(tǒng)開發(fā)人員設計系統(tǒng)功能、調優(yōu)系統(tǒng)性能、提升部署方法[5]。3)它容許用戶比較不同系統(tǒng)的性能,幫助選購產品。
設計大數(shù)據(jù)基準測試通常包含以下考慮。1)選擇數(shù)據(jù)和生成數(shù)據(jù),確定數(shù)據(jù)集的大小、類型以及覆蓋的應用場景,提供數(shù)據(jù)集或者數(shù)據(jù)生成的工具。2)確定測試負載,負載需要覆蓋不同的應用場景,具有代表性,能夠較全面地反應系統(tǒng)的特性。3)明確測試指標,大數(shù)據(jù)基準測試主要從性能、能效、性價比、可靠性等角度衡量大數(shù)據(jù)系統(tǒng)和架構。4)確定基準測試所針對的軟件系統(tǒng)和框架,不同框架處適用的場景不同。
4 測試流程
大數(shù)據(jù)基準測試主要有三個流程,即數(shù)據(jù)生成、負載選擇和指標選擇。簡要來說,數(shù)據(jù)生成主要生成不同的數(shù)據(jù)類型并滿足大數(shù)據(jù)的四V特點;負載選擇主要是選擇合適的負載以運行數(shù)據(jù)產生結果;指標選擇確定衡量的維度,以便從不同方面評估大數(shù)據(jù)框架。
4.1 數(shù)據(jù)生成
大數(shù)據(jù)基準測試通常要么采用現(xiàn)實數(shù)據(jù),要么合成數(shù)據(jù)。使用現(xiàn)實數(shù)據(jù)存在兩個困難,首先,大多數(shù)情況下數(shù)據(jù)都是企業(yè)比較敏感的部分,企業(yè)通常不愿意公開提供數(shù)據(jù);其次,現(xiàn)實數(shù)據(jù)只適應于特定應用場景,有其局限性,無法適應所有負載;所以,用數(shù)據(jù)生成工具合成數(shù)據(jù)成為大數(shù)據(jù)基準測試通常采用的方法。數(shù)據(jù)生成分為數(shù)據(jù)篩選、數(shù)據(jù)處理、數(shù)據(jù)生成和格式轉換四步。
4.1.1 生成步驟
1)數(shù)據(jù)篩選。在篩選數(shù)據(jù)時,①需要考慮數(shù)據(jù)和負載的匹配性,數(shù)據(jù)類型應該符合特定負載的要求,數(shù)據(jù)集需要來源于特定的大數(shù)據(jù)應用場景,如電子商務、搜索引擎、社交網(wǎng)絡等,并符合真實數(shù)據(jù)的數(shù)據(jù)特征和分布特征;②根據(jù)測試機器的數(shù)量和應用的特點,評估數(shù)據(jù)量的大小。2)數(shù)據(jù)處理。待處理的數(shù)據(jù)是建立在能保持原始數(shù)據(jù)的特性并能消除其中敏感信息的基礎上進行相關操作的。針對不同的數(shù)據(jù)類型,應該采用該類領域中有代表性的數(shù)據(jù)建模方法對真實數(shù)據(jù)進行建模,抽取出數(shù)據(jù)的特征,并將這些特征存儲在模型文件中。3)數(shù)據(jù)生成。數(shù)據(jù)生成通常需要特定的生成工具來完成,生成工具依據(jù)不同類型的數(shù)據(jù)處理過程來設計。首先需要提出數(shù)據(jù)的模型特征,基于提取出的模型和所需的數(shù)據(jù)量生成測試數(shù)據(jù)。除了需要保證所選用建模方法的模型特性外,還要滿足在數(shù)據(jù)生成過程中通過參數(shù)來控制數(shù)據(jù)生成的并發(fā)量和大小,不同的參數(shù)可以模擬出不同的應用場景;不同的數(shù)據(jù)生成工具通過建模步驟,保證生成的測試數(shù)據(jù)保持原有數(shù)據(jù)的數(shù)據(jù)特征,并且可以縮放至大數(shù)據(jù)規(guī)模。4)數(shù)據(jù)格式轉換。這個流程保證生成數(shù)據(jù)能通過格式轉換工具生成符合特定應用的輸入格式。
4.1.2 示例
例如,通過分析應用和負載需求,假設現(xiàn)在要生成1T左右的文本數(shù)據(jù)。首先選擇網(wǎng)絡上開放維基百科的數(shù)據(jù)源,以此數(shù)據(jù)源為樣本,利用開源的數(shù)據(jù)生成工具并提取出數(shù)據(jù)的特征,數(shù)據(jù)生成工具根據(jù)數(shù)據(jù)特征和需要擴展的數(shù)據(jù)量(這里是1T)來生成數(shù)據(jù)集,這樣就能得到基于實際應用中數(shù)據(jù)擴展的數(shù)據(jù)集。最后,根據(jù)負載需要的輸入格式再對數(shù)據(jù)集的格式進行轉化。
4.2 負載選擇
負載是大數(shù)據(jù)基準需要執(zhí)行的具體任務,用來處理數(shù)據(jù)并產生結果,負載將大數(shù)據(jù)平臺的應用抽象成一些基本操作。由于行業(yè)和領域的不同,其應用有很多不同的特點,從系統(tǒng)資源消耗方面負載可分為計算密集型、I/O密集型和混合密集型的任務。例如運營商的話單查詢需要多次調用數(shù)據(jù)庫,是典型的I/O密集型任務;而互聯(lián)網(wǎng)的聚類過程需要大量的迭代計算,是典型的計算密集型任務;搜索引擎中的PageRank算法既需要數(shù)據(jù)交換又要不斷地迭代計算,屬于混合型任務。
選擇負載有兩種策略。第一種是從企業(yè)應用的場景出發(fā),模擬企業(yè)應用流程,采用應用中的真實數(shù)據(jù)進行測試。例如一家從事搜索的企業(yè),其應用場景可以基本抽象為Nutch、Index和PageRank三種負載;銀行的典型應用主要是賬單查詢、帳目的更改等,可以抽象為對數(shù)據(jù)庫表的查詢和更改。第二種是從通用的角度來考量,從測試整個大數(shù)據(jù)平臺的角度出發(fā),選擇負載時需要覆蓋大數(shù)據(jù)處理平臺主要組件即分布式計算框架、分布式文件系統(tǒng)和分布式存儲的能力。以Hadoop平臺為例,負載主要需要測試Hadoop(包括HDFS和MapReduce)、數(shù)據(jù)倉庫(Hive)和NoSQL數(shù)據(jù)庫的能力。測試負載需要覆蓋多種應用類型和任務的資源特點。如表1所示,選取TeraSort、PageRank和Na?ve Bayes來測試Hadoop,這三個算法分別屬于I/O資源密集、混合和計算資源密集的任務;選取Join Query來測試Hive組件,Read/Write/Scan負載來測試HBase組件,它們分別屬于計算密集和I/O密集負載。
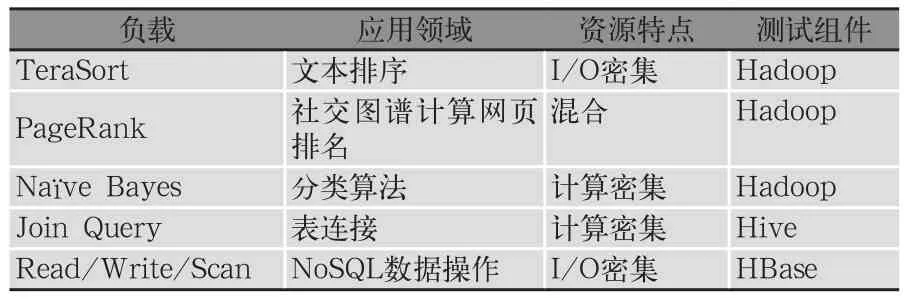
表1 測試負載示例
4.3 指標
測試指標主要分為兩類,一類是從用戶角度出發(fā)的指標,這類指標注重于直觀化,讓用戶容易理解[6];第二類指標是從架構的角度出發(fā)的,主要考量系統(tǒng)架構的能力。第一類的指標主要有每秒執(zhí)行的請求數(shù),請求延遲和每秒執(zhí)行的操作數(shù);第二類指標注重比較系統(tǒng)性能間的差異,主要有每秒浮點計算速度和每秒數(shù)據(jù)吞吐量等。在實際測試中,為比較不同平臺之間的差異,可以從以下四個維度來評估大數(shù)據(jù)平臺:性能、能耗、性價和可靠性,具體介紹和計算方式見表2。

表2 測試指標
5 大數(shù)據(jù)測試工具
當前大數(shù)據(jù)基準工具有很多,主要分為三種類型。一類屬于微型負載,這類負載測試只測試大數(shù)據(jù)平臺的某個特定組件或應用,例如GridMix是面向Hadoop集群的測試基準;TeraSort只針對文本數(shù)據(jù)的排序;雅虎開發(fā)的YCSB對比NoSQL數(shù)據(jù)庫的性能,其目的是評估鍵值和云數(shù)據(jù)庫[7];Facebook的LinkBench專門用于測試存儲社交圖譜和網(wǎng)絡服務的數(shù)據(jù)庫[8]。第二類是綜合類的測試工具,模擬幾類典型應用,覆蓋大數(shù)據(jù)軟件平臺的多個功能組件,比如英特爾的Hibench是針對Hadoop和Hive平臺的基準測試工具,其負載按照業(yè)務能分為微型負載、搜索業(yè)務、機器學習和分析請求等四類[9];BigDataBench是中科院計算所提出的大數(shù)據(jù)測試工具,覆蓋了結構數(shù)據(jù)、半結構數(shù)據(jù)和非結構數(shù)據(jù),其負載模擬了搜索引擎、社交網(wǎng)絡和電子商務等業(yè)務模型[6]。第三類測試工具是具體應用領域端到端的大數(shù)據(jù)測試工具,這類的測試工具主要有BigBench,是基于TPC-DS開發(fā)的端到端大數(shù)據(jù)測試工具,面向零售業(yè)務,模擬電子商務的整個流程,主要測試MapReduce和并行DBMS[10],其優(yōu)點是應用場景結合非常緊密,行業(yè)針對性很強。
這三類測試工具各有其應用場景,微型測試工具測試的應用較單一,效率高、成本低,但無法通體衡量大數(shù)據(jù)平臺的性能,綜合類測試工具覆蓋面比較廣,考慮到應用類型和不同平臺組件,能夠較全面考量大數(shù)據(jù)平臺執(zhí)行不同類型任務的性能,通用性好。端到端的大數(shù)據(jù)測試工具滿足了對企業(yè)特定業(yè)務的模擬,與企業(yè)應用場景結合緊密,覆蓋了企業(yè)大數(shù)據(jù)業(yè)務全流程的模擬和測試,是未來大數(shù)據(jù)測試工具發(fā)展的趨勢。
6 總結
大數(shù)據(jù)基準測試負載、數(shù)據(jù)、指標的選擇都應該基于企業(yè)具體業(yè)務場景和應用需求,對于業(yè)務種類較多、覆蓋多個平臺組件的企業(yè)應該考慮抽象一些共性的負載,選擇通用性的測試工具。對于行業(yè)領域比較明確,業(yè)務種類比較集中的企業(yè),應該多考慮抽象出特定的場景的負載,選用實際數(shù)據(jù)進行擴展,最好定制端到端的測試工具。目前來看,大數(shù)據(jù)測試工具都屬于微型工具,其負載均模擬真實業(yè)務中的一些簡單操作,主要從性能角度衡量大數(shù)據(jù)基礎平臺(Hadoop或者Spark平臺),目前比較缺少端到端的面向具體業(yè)務場景的測試負載和測試數(shù)據(jù)。隨著企業(yè)的大數(shù)據(jù)應用的逐步發(fā)展,企業(yè)更加了解自身需求,未來大數(shù)據(jù)基準測試的發(fā)展將注重以下兩點。1)面向具體行業(yè)的應用場景,模擬典型的應用類型,針對特定行業(yè)端到端的測試工具,比如模擬搜索引擎、社交網(wǎng)絡、上網(wǎng)流量查詢、銀行賬單查詢等業(yè)務的負載。2)簡化測試部署、執(zhí)行的復雜性,提供更好的可視化工具。
[1]Total Number of Websites.Internetlivestats[EB/OL].[2014-10-11].http://www.internetlivestats.com/total-number-ofwebsites/
[2]John Gantz,David Reinsel.The Digital Universe In 2020:Big Data,Bigger Digital Shadows,and Biggest Growth in the Far East[R/OL].[2014-10-11].http://www.emc.com/leadership/digital-universe/2014iview/executivesummary.htm
[3]The Four V's of Big Data[EB/OL].[2014-10-11].http://www.ibmbigdatahub.com/infographic/four-vs-big-data
[4]The 2014 IDG Enterprise Big Data research[R/OL].[2014-10-11].http://www.idgenterprise.com/report/bigdata-2
[5]Rui Han,Xiaoyi Lu.On Big Data Benchmarking[C]//The Fourth workshop on Big Data Benchmarks,Performance Optimization,and Emerging Hardware.Salt Lake City,Utah,USA,2014:3-18
[6]Wang L,Zhan J,Luo C,et al.BigDataBench:a Big Data Benchmark Suit from Internet Services[C]//The 20th IEEE International Symposium On High Performance Computer Architecture.Orlando,USA,2014
[7]Brian F.Cooper,Adam Silberstein,Erwin Tam,et al. Benchmarking Cloud Serving Systems with YCSB[C]//The 1st ACM symposium on Cloud computing,SoCC'10.Indianapolis,Indiana,USA,2010:143-153
[8]Timothy G.Armstrong,Vamsi Ponnekanti,DhrubaBorthaku.LinkBench:a Database Benchmark Based on the Facebook Social Graph[C]//SIGMOD,ACM,USA,2013:1185-1196
[9]Shengsheng Huang,Jie Huang,Jinquan Dai,et al.The HiBench Benchmark Suit:Characterization of the MapReduce-Based Data Analysis[C]//Data Engineering Workshops.I IEEE 26th International Conferenace on IEEE,2010:41-51
[10]Ahmad Ghazal,TilmannRabl,Minqing Hu,el al.BigBench:Towards an Industry Standard Benchmark for Big Data Analytics[C]//SIGMOD ACM.NewYork,2013:197-208
猜你喜歡
中學生數(shù)理化·自主招生(2022年9期)2022-05-30 10:48:04
心理學報(2022年4期)2022-04-12 07:38:02
水泵技術(2021年3期)2021-08-14 02:09:20
電子測試(2018年4期)2018-05-09 07:28:12
當代化工研究(2016年9期)2016-03-20 16:22:13
中國慣性技術學報(2015年1期)2015-12-19 13:12:17
計算機工程(2015年4期)2015-07-05 08:28:04
西華師范大學學報(自然科學版)(2015年3期)2015-02-27 15:31:22
聯(lián)合國青年技術培訓(2014年7期)2014-04-12 00:00:00
中國質量與標準導報(2014年7期)2014-02-28 22:24:35
