家庭網絡后臺流量分析與識別
2014-05-18 08:12:09郭志鑫喬美華
信息通信技術 2014年6期
郭志鑫 喬美華
1 山東大學 濟南 250100
2 河海大學 南京 210098
引言
隨著互聯網的迅速普及和發展,家庭網絡化已經成為信息社會的一個發展趨勢。通過現有的計算機網絡技術,家庭內各種家電和電子設備可以通過網絡為人們提供各種服務,獲取外部信息。逐漸增加的帶寬壓力使網絡運營商必須提高對網絡流量的管理控制能力,而業務流量識別技術則是實現下一代網絡的可控、可信、可擴展的一個重要因素。先進的流量識別技術不僅可以提高網絡管理的能力,從一定程度上預測網絡的未知流量,還可廣泛應用于網絡管理、業務監控、服務質量管理等各個系統,對下一代網絡業務管理、服務質量控制等都有重大的現實意義[1-2]。
1 常用應用的流量特征分析
由于流量識別和分類是根據抓包特征的不同進行的,所以抓包特征的合適與否決定了識別的準確度,抓包特征是否容易得到決定了下一步編程識別的難度。我們選用抓包工具Wireshark,該工具使用方便,可用于對網卡上的流量進行分析和統計,從而得到流量特征信息。
根據人們日常生活習慣,本文選取了在電腦端和智能電視端常用的占據帶寬較大的幾類應用作為抓包分析的對象。選取的應用有:QQ視頻聊天、無線傳屏和VOD視頻點播等。其他一些常用的網絡應用如E-mail、QQ文字聊天等由于占據帶寬有限,不會對整個網絡的性能造成明顯影響,不作為本文的研究對象。
本文采用五元組信息(包括源IP地址、目的IP地址、源端口號、目的端口號和協議類型號五個信息)、上行流量包長、下行流量包長、上行流量包數、下行流量包數作為識別特征。這些信息不一定要單獨使用,可以進行組合處理得到更適合識別的新的數據形式[3-5]。
下面將分析采用上述幾種信息作為識別特征的可行性,最后得到用于編程識別的幾種特征。
1)五元組信息的可行性分析。五元組信息是抓包數據中最重要的信息,一個五元組能夠唯一地確定一個網絡會話。所以,如果在抓包過程中發現某應用始終采用某一固定的IP地址或者端口號,則可以用五元信息作為識別特征,準確地識別該應用。
2)包長信息的可行性分析。包長同樣是封包數據中十分重要的信息,但是單獨一個或幾個包的包長難以體現出某類應用的總體特征,可在編程部分設置一個定時器,統計在一段時間內包長之和,即這段時間內流量的數據量。另外,考慮到數據量的大小受網絡條件的影響較大,本文采用的處理方法為:分別統計一段時間內上行流量和下行流量的數據量,然后以下行數據量/上行數據量作為最終的識別特征。該信息還能比較明確地顯示出該應用的數據流向。
3)包數信息的可行性分析。為較好地體現不同應用的特征,參考包長信息的處理方式,包數信息的使用也采用同樣的處理方式,以下行包數/上行包數作為最終的識別特征。為得到各類應用的特征,本文采取的抓包方式是每天早上、下午和晚上分別對某一應用抓包三次,連續抓包兩周,最后將得到的數據統一分析,得到各類應用的特點[6],總結見表1。

表1 各類應用的特征總結
通過分析這些特征,綜合考慮識別的準確度和編程的難度,本文采取的識別方法為:在接收到封包并對封包信息進行分析后,首先對封包的遠端端口進行判斷,如果該端口為16 000或50 021,則可直接識別為QQ視頻聊天或無線傳屏應用;然后設置定時器,每隔20秒對還未識別的流量上下行數據量進行統計,如果下行數據量/上行數據量大于20,則判定為VOD視頻點播。
由于智能應用市場發展十分迅速,每天都會出現新的應用,為了程序的適應性并為未來能夠識別更多的應用作準備,本文將識別條件寫為正則表達式的形式存放在數據庫的表中,在識別時對正則表達式進行一一匹配。這樣當需要識別新的應用時,只需根據新應用的特點寫成新的正則表達式添加到已有的表中,識別流程不需要進行改動。
2 后臺流量統計與識別系統的實現
經過第1章的抓包分析工作,各類應用的流量特征已經基本確定,本章的工作是根據這些特征編程實現流量的統計與識別功能,識別環境為Linux,流量特征和識別結果均通過數據庫存放。
2.1 系統框架
本系統的框架如圖1所示,分為后臺管理系統和Linux下的流量識別兩部分,通過數據庫進行交互。下面將對后臺管理部分和流量識別部分的原理分別進行詳細的分析。

圖1 系統框架圖
2.2 后臺管理子系統
后臺管理系統的結構如圖2所示。下面將詳細分析該系統的工作原理。
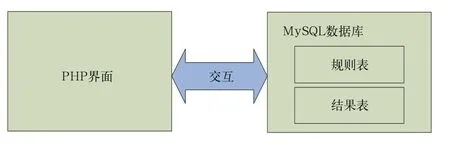
圖2 后臺管理系統結構圖
MySQL是一個關聯式數據庫管理系統,由于它體積較小、運行速度快、源碼開放等優點而被廣泛應用于中小網站的開發中[7-8]。本文同樣選擇MySQL數據庫作為工作數據庫。
1)規則表。規則表用于存放識別各類應用的正則表達式,它的結構如表2所示。其中order_number為規則表的主鍵,AppID為各類應用的序號,regular_expression為應用的正則表達式,用于識別路由器上的流量是否符合某一類應用的特征。
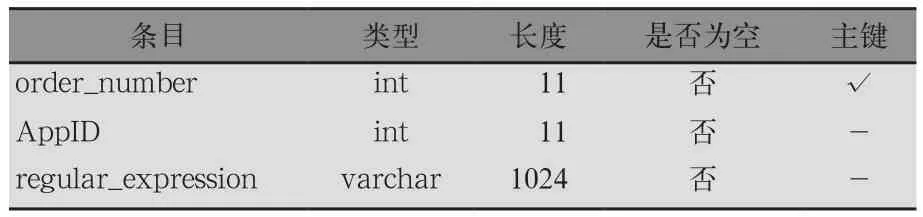
表2 規則表結構
正則表達式是一種邏輯公式,是用已經定義好的一些某些特定字符或字符組合組成的一個“規則字符串”。這個“規則字符串”的作用是用來匹配某個字符串,檢查該字符串是否符合這個“規則字符串”的規則[9]。
2)結果表。結果表用于在成功識別某應用后存儲其五元組和其他信息,它的作用是在識別開始時首先將未知流量與已經識別過的結果進行匹配,如果匹配成功則直接識別為已有應用類型,避免進行重復識別,降低效率。另外,結果表中的標志符current_run_flag用于標識目前正在進行的應用,并將該信息傳遞給PHP界面。
結果表的結構如表3所示。其中order_number為結果表的主鍵,AppID為各類應用的序號,local_ip、remote_ip、local_port、remote_port、protocolID為封包的五元組信息,current_run_flag為標識符,當值為1時表示該應用正在運行,每20秒會對所有記錄的標識符進行清零。
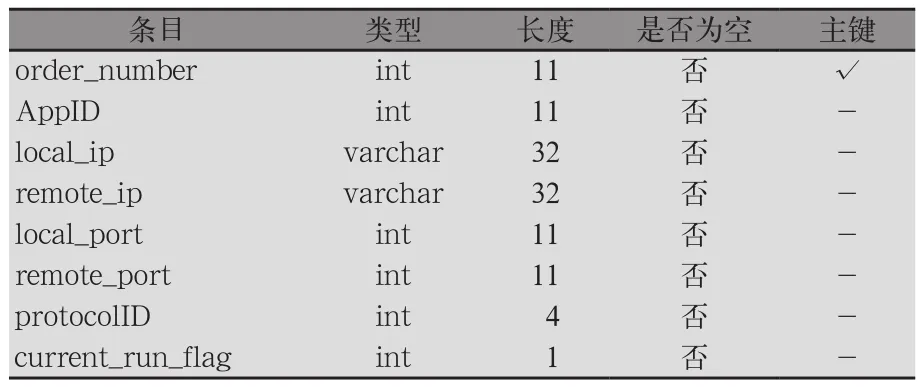
表3 結果表結構
2.3 流量識別子系統
流量識別子系統的編程環境為Linux系統,工作流程如圖3所示。下面將對系統的運行過程進行詳細的分析。
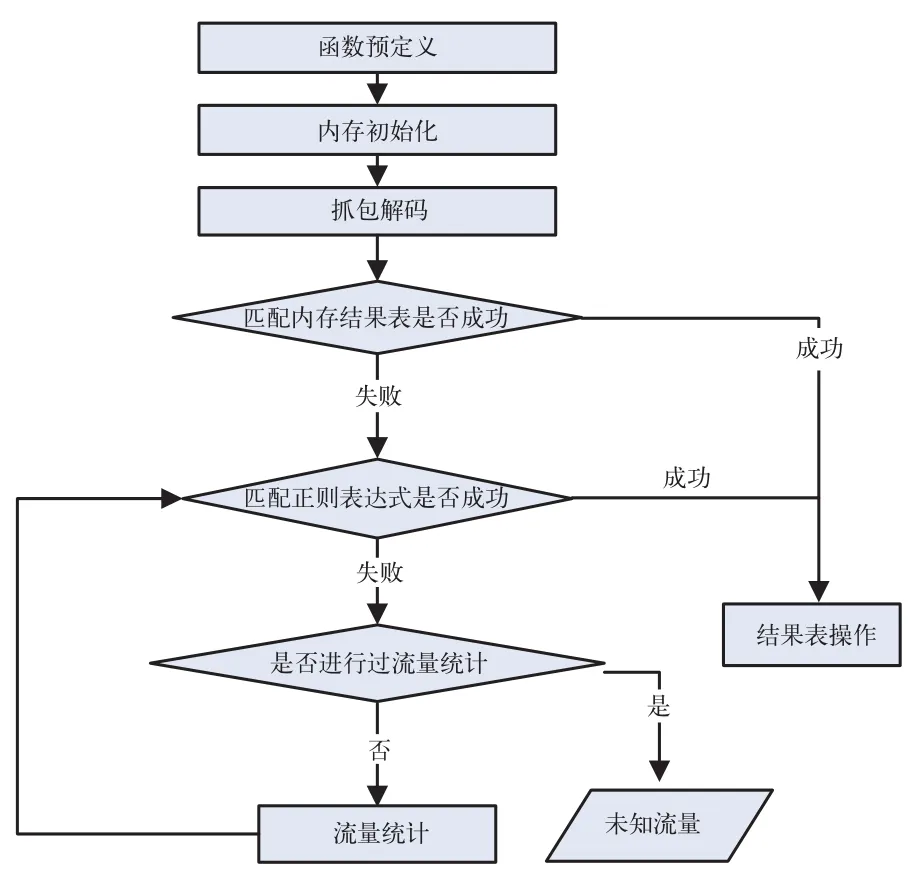
圖3 流量識別子系統流程圖
在函數預定義的過程中定義了結果表鏈表頭指針和規則表鏈表頭指針兩個全局變量,在初始化時使用結果表初始化函數,將數據庫中結果表信息存入結果表鏈表,同時使用規則表初始化函數將規則表信息存入規則表鏈表。兩個鏈表將用于后面的封包匹配。
抓包解碼時主要使用的是入侵檢測系統Snort。這是一個用C語言開發的,開放源代碼的網絡入侵檢測防御系統,能夠進行實時流量分析和網絡數據包記錄。用于截取網絡流量中的數據包,分析其中的內容并將里面的信息存入流量特征信息結構體中,用于后續的流量識別部分[10]。
下一步進入流量識別的關鍵步驟,將得到的封包進行識別。
根據圖3所示的流量識別流程圖,對一個封包進行一次完整的匹配分為以下三步,每次匹配成功后需要對結果表進行相應的操作。
1)匹配結果表信息。將當前流量特征信息結構體的五元組與結果表五元組進行匹配,如果匹配成功,則說明該結果在之前已經被成功識別過,直接將相應結果表消息的Flag位設為1,表示該應用正在進行;如果不成功,繼續進行正則表達式的匹配。
2)匹配正則表達式。由于結果表匹配不成功,說明該結果在之前沒有被識別過,需要使用正則表達式進行匹配。正則表達式就是從數據庫的規則表中取出的邏輯公式,用于檢查該結果是否符合某類應用的特征。如果匹配成功,則將該條結果的識別記錄增加到結果表中,并同時將Flag位設置為1,表示該應用正在進行。
3)流量統計。對于VOD視頻點播的識別需要對一段時間的上下行流量比進行統計計算。在每種五元組的起始流量包到來時記錄起始時間,每次來一個相同五元組的流量包時,對其上下行流量分別進行累加,存入流量統計鏈表。每隔一段時間將統計后的信息輸出,用于再次進行正則表達式的匹配。
除了流量統計,定時器的另一個作用是判斷應用是否正在進行。每隔一定時間,讀取一次系統時間,與結果表鏈表中某結果的最后一次更新時間相減,如果間隔超過默認設置的時間,則判定為此段時間內沒有該應用的新包到來,將標志位Flag設置為0,表示該應用已經停止運行。
3 Socket通信模塊
前面已經實現了流量的統計與識別功能。這部分通信模塊的設計目的是將該功能移植到網關上,網關部分只負責收包和識別,而后臺部分暫時負責數據庫的管理和識別結果界面等,隨著后續開發的進行,后臺將會承擔更多的功能,使系統更加智能。這樣就需要增加網關和后臺系統之間的通信機制。本文采用的通信方式是Socket通信,為TCP方式。
3.1 通信模塊框架
1)網關側處理流程。網關側處理流程如圖4所示。在網關開始識別功能前,首先要向后臺發送注冊請求,只有在得到后臺允許注冊的回復后才能正常工作。然后根據從后臺收到的規則表和結果表對封包信息進行匹配,如果匹配成功,將結果表更新,并將識別后的結果傳到后臺。2)后臺側處理流程。后臺側處理流程如圖5所示。在每次收到網關側的包時,首先判斷該網關是否已經注冊,如果未注冊則丟棄該包。每次收到網關側的識別結果后,將后臺的結果表進行刷新。
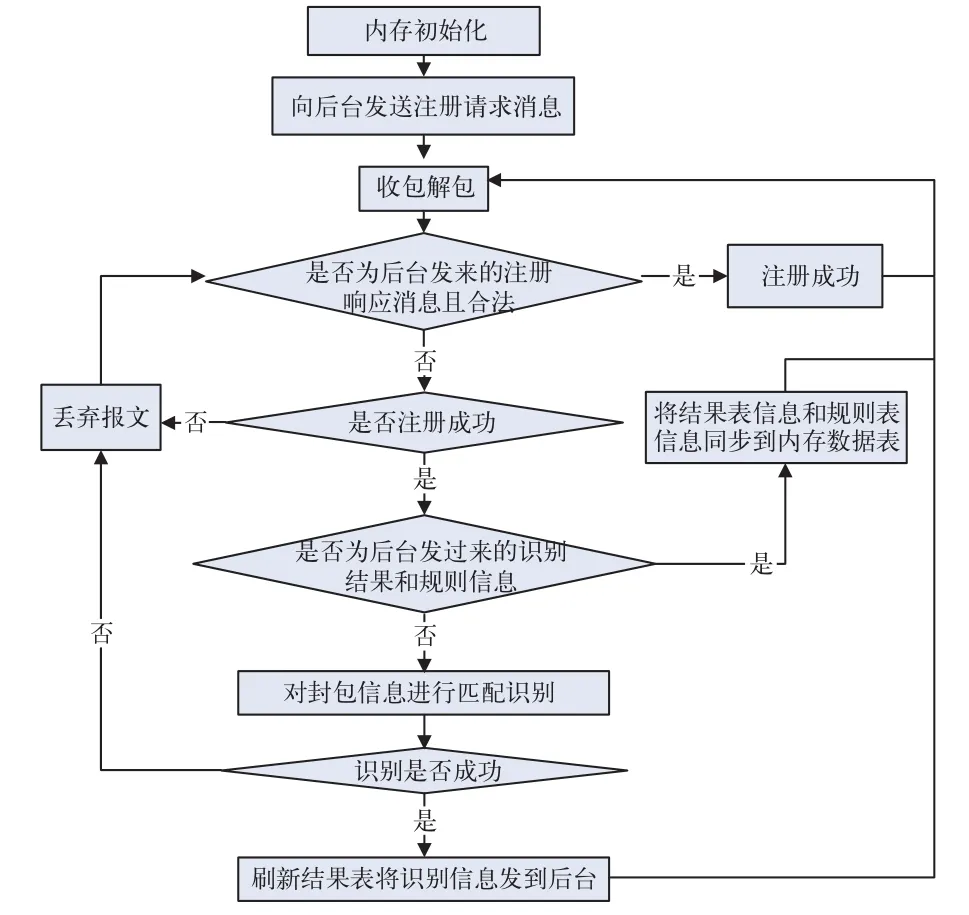
圖4 網關側處理流程圖
3.2 通信模塊工作原理
Socket又稱“套接字”,用于網絡進程之間的相互通信,應用程序通過Socket向網絡發出請求或接收網絡請求。服務器端與客戶端通過Socket建立連接后,可以調用IO函數進行讀寫操作。在阻塞模式下,網關側或后臺側調用IO函數收發信息都需要等待對方的回應,在此期間系統不能進行其他工作,這樣的工作方式不符合通信模塊的工作流程且效率很低;因此,通信模塊在信息收發時均調用select函數使其工作在非阻塞方式之下,通過函數的返回值判斷在緩沖區是否有新的信息,然后根據消息ID進入相應的處理流程。本文通信模塊的消息處理流程如圖6所示[11-13]。
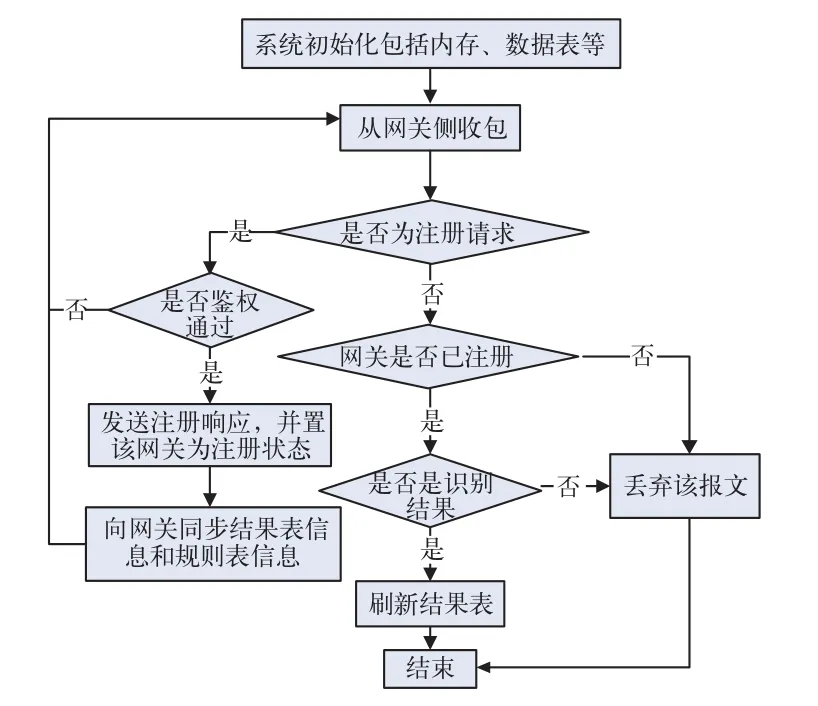
圖5 后臺側處理流程圖
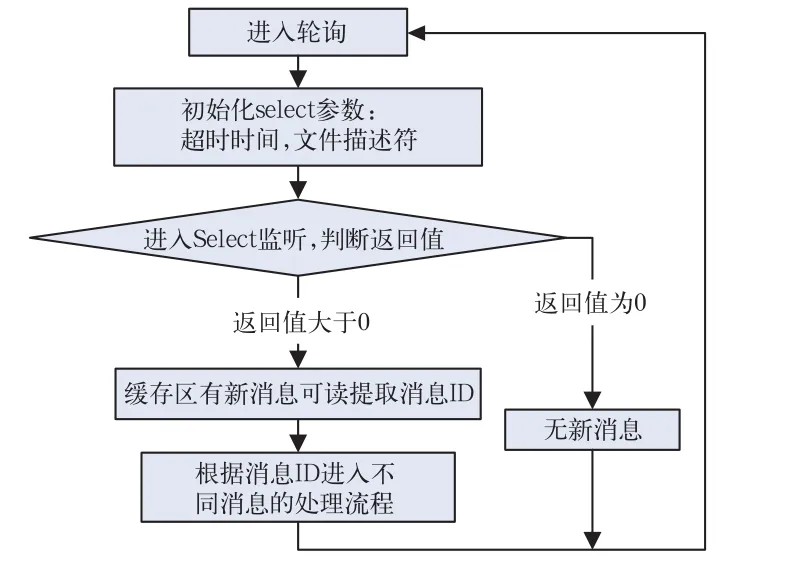
圖6 通信模塊消息處理流程
4 識別結果
流量識別系統識別成功后,識別結果被寫入數據庫的結果表。每條結果信息的內容包括:識別結果ID、本地IP地址、遠端IP地址,本地端口號、遠端端口號、協議類型號。結果信息的內容與2.2節后臺管理子系統中描述的結果表結構相對應,此處不再詳述。
5 結束語
在對家庭生活中的常用應用進行匯總分類時,本文只選取了其中占據帶寬較多的幾類應用,其他占據帶寬有限的應用不作為本文的研究對象。本文的識別方法能夠對家庭成員的網絡活動進行較為準確地識別,在此基礎上,下一步的計劃是QoS管理系統的實現。對各類應用的優先級進行設置,在網絡帶寬有限的情況下,優先級低的應用不能影響優先級高的應用的運行,采用這樣的方式盡量保證家庭成員的重要業務能夠順利進行。
[1]朱川,韓光潔.家庭網關平臺與IMS融合技術[M].北京:科學出版社,2012:5-20
[2]薛家勇.嵌入式Linux家庭網關系統研究與實現[D].西北工業大學碩士學位論文,2005:1-4
[3]高彥剛.實用網絡流量分析技術[M].北京:電子工業出版社,2009:8-18
[4]郭明亮.高速網絡中實時流量識別系統的研究與設計[D].北京郵電大學碩士學位論文,2010:1-6
[5]左建勛.網絡流量識別技術研究及其應用[D].重慶大學碩士學位論文,2007:2-8
[6]Chris Sanders.Practical Packet Analysis:Using Wireshark to Solve Real-World Network Problems (2nd Edition)[M].USA:No Starch Press,2009:3-89
[7]潘景昌,劉杰.操作系統實驗教程(Linux版)[M].北京:清華大學出版社,2010:59-72
[8]吉爾摩.PHP與MySQL程序設計[M].朱濤江,譯.北京:人民郵電出版社,2011:372-410
[9]Jan Goyvaerts.Regular Expressions Cookbook[M].USA:O'Reilly Media,2009:8-103
[10]李鳳霞.C語言程序設計教程[M].北京:北京理工大學出版社,2008:246-268
[11]W.Richard Stevens.TCP/IP詳解卷1:協議[M].北京:機械工業出版社,2000:313-349
[12]丁國華,胡榮強.Linux的Socket編程及其在嵌入式網關中的應用[J].電子元器件應用,2004,6(10):1-4
[13]W.Richard Stevens.UNIX網絡編程(第1卷)[M].北京:清華大學出版社,2010:47-149
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
Coco薇(2017年11期)2018-01-03 20:59:57
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
