淺談大數據處理技術架構的演進
2014-05-18 08:12:04任桂禾
信息通信技術 2014年6期
任桂禾 王 晶
1 北京郵電大學網絡與交換技術國家重點實驗室 北京 100876
2 東信北郵信息技術有限公司 北京 100191
引言
Hadoop誕生于大數據時代,是Apache基金會受到Google開發的GFS(Google File System,谷歌文件系統)和MapReduce計算框架的啟發引入的開源項目。Hadoop使用大量的廉價Linux PC機組成集群,可謂是大數據處理商用技術架構的開端。Hadoop作為經典的大數據離線處理技術架構,很好地滿足了人們對于大數據的離線處理需求[1]。
然而,隨著Web2.0的興起,琳瑯滿目的各式應用和服務如雨后春筍般地涌現。這其中出現了以微博為代表的一批典型應用,海量的用戶、碎片化的信息流、極快的傳播速度,使得它們對業務實時性的要求大幅度提高[2]。當業務需求允許的時延降低到一定限度時,Hadoop架構會達到本身的瓶頸,已經不能滿足大數據處理的需求。Twitter出于自身的業務需求開發了Storm實時處理框架,使用流式處理架構,對傳統離線處理技術架構進行了變革。
1 Hadoop架構的瓶頸
Hadoop是優秀的大數據離線處理技術架構,主要采用的思想是“分而治之”,對大規模數據的計算進行分解,然后交由眾多的計算節點分別完成,再統一匯總計算結果[3]。Hadoop架構通常的使用方式為批量收集輸入數據,批量計算,然后批量吐出計算結果。然而,Hadoop結構在處理實時性要求較高的業務時,卻顯得力不從心。本章內容對Hadoop架構這種瓶頸的產生原因進行了探究。
1.1 Hadoop架構簡介
Hadoop架構的核心組成部分是HDFS(Hadoop Distributed File System,Hadoop分布式文件系統)和MapReduce分布式計算框架。HDFS采用Master/Slave體系結構,在集群中由一個主節點充當NameNode,負責文件系統元數據的管理,其它多個子節點充當Datanode,負責存儲實際的數據塊[4]。如圖1所示。
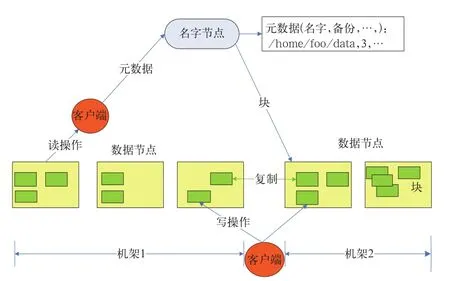
圖1 HDFS架構
MapReduce分布式計算模型由JobTracker和TaskTracker兩類服務進程實現,JobTracker負責任務的調度和管理,TaskTracker負責實際任務的執行。
1.2 Hadoop架構的瓶頸
在筆者實施的某運營監控系統項目中,業務需求為處理業務平臺產生的海量用戶數據,展現業務中PV(Page View,頁面瀏覽量)、UV(Unique Visitor,獨立訪客)、營收和付費用戶數等關鍵運營指標,供領導層實時了解運營狀況,做出經營決策。在一期項目的需求描述中,允許的計算時延是15分鐘。
根據需求,在一期項目的實施中,搭建了Hadoop平臺與Hive數據倉庫,通過編寫Hive存儲過程完成數據的處理,相當于是一個離線的批處理過程。不同的運營指標擁有不同的算法公式,各公式的復雜程度不同導致各運營指標算法復雜度不同,因此,所需要的計算時延也各不相同,如PV指標的計算公式相對簡單,可以在5分鐘內完成計算,而頁面訪問成功率指標的計算公式相對復雜,需要10分鐘以上才能完成計算。項目到達二期階段時,對實時性的要求有了進一步提高,允許的計算時延減少到5分鐘。在這種應用場景下,Hadoop架構已經不能滿足需要,無法在指定的時延內完成所有運營指標的計算。
在以上的應用場景中,Hadoop的瓶頸主要體現在以下兩點。
1)MapReduce計算框架初始化較為耗時,并不適合小規模的批處理計算。因為MapReduce框架并非輕量級框架,在運行一個作業時,需要進行很多初始化的工作,主要包括檢查作業的輸入輸出路徑,將作業的輸入數據分塊,建立作業統計信息以及將作業代碼的Jar文件和配置文件拷貝到HDFS上。當輸入數據的規模很大時,框架初始化所耗費的時間遠遠小于計算所耗費的時間,所以初始化的時間可以忽略不計;而當輸入數據的規模較小時,初始化所耗費的時間甚至超過了計算所耗費的時間,導致計算效率低下,產生了性能上的瓶頸。
2)Reduce任務的計算速度較慢。有的運營指標計算公式較為復雜,為之編寫的Hive存儲過程經Hive解釋器解析后產生了Reduce任務,導致無法在指定的時延內完成計算。這是由于Reduce任務的計算過程分為三個階段,分別是copy階段、sort階段和reduce階段。其中,copy階段要求每個計算節點從其它所有計算節點上抽取其所需的計算結果,如圖2所示。copy操作需要占用大量的網絡帶寬,十分耗時,從而造成Reduce任務整體計算速度較慢。
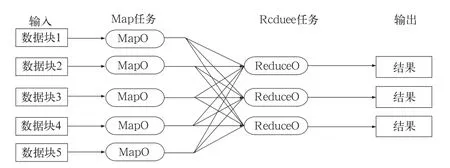
圖2 copy操作示意圖
2 Storm架構的優點
Storm的流式處理計算模式保證了任務只需進行一次初始化,就能夠持續計算,同時使用了ZeroMQ作為底層消息隊列,有效地提高了整體架構的數據處理效率,避免了Hadoop的瓶頸[5]。
2.1 Storm架構的設計
與Hadoop主從架構一樣,Storm也采用Master/Slave體系結構,分布式計算由Nimbus和Supervisor兩類服務進程實現,Nimbus進程運行在集群的主節點,負責任務的指派和分發,Supervisor運行在集群的從節點,負責執行任務的具體部分。
Storm架構中使用Spout/Bolt編程模型來對消息進行流式處理。消息流是Storm中對數據的基本抽象,一個消息流是對一條輸入數據的封裝,源源不斷輸入的消息流以分布式的方式被處理。Spout組件是消息生產者,是Storm架構中的數據輸入源頭,它可以從多種異構數據源讀取數據,并發射消息流。Bolt組件負責接收Spout組件發射的信息流,并完成具體的處理邏輯。在復雜的業務邏輯中可以串聯多個Bolt組件,在每個Bolt組件中編寫各自不同的功能,從而實現整體的處理邏輯[6]。
2.2 Storm架構與Hadoop架構對比
Storm架構和Hadoop架構的總體結構相似,各個組成部分的對比如表1所示。

表1 Storm架構與Hadoop架構對比
在Hadoop架構中,主從節點分別運行JobTracker和TaskTracker進程,在Storm架構中,主從節點分別運行Nimbus和Supervisor進程。在Hadoop架構中,應用程序的名稱是Job,Hadoop將一個Job解析為若干Map和Reduce任務,每個Map或Reduce任務都由一個Child進程來運行,該Child進程是由TaskTracker在子節點上產生的子進程。在Storm架構中,應用程序的名稱是Topology,Storm將一個Topology劃分為若干個部分,每部分由一個Worker進程來運行,該Worker進程是Supervisor在子節點上產生的子進程,在每個Worker進程中存在著若干Spout和Bolt線程,分別負責Spout和Bolt組件的數據處理過程。
從應用程序的比較中可以明顯地看到Hadoop和Storm架構的主要不同之處。在Hadoop架構中,應用程序Job代表著這樣的作業:輸入是確定的,作業可以在有限時間內完成,當作業完成時Job的生命周期走到終點,輸出確定的計算結果。而在Storm架構中,Topology代表的并不是確定的作業,而是持續的計算過程。在確定的業務邏輯處理框架下,輸入數據源源不斷地進入系統,經過流式處理后以較低的延遲產生輸出。如果不主動結束這個Topology或者關閉Storm集群,那么數據處理的過程就會持續地進行下去。
通過以上的分析,我們可以看到Storm架構是如何解決Hadoop架構瓶頸的。
1)Storm的Topology只需初始化一次。在將Topology提交到Storm集群的時候,集群會針對該Topology做一次初始化的工作。此后,在Topology運行過程中,對于輸入數據而言,是沒有計算框架初始化耗時的,有效地避免了計算框架初始化的時間損耗。
2)Storm使用ZeroMQ作為底層的消息隊列來傳遞消息,保證消息能夠得到快速的處理。同時,Storm采用內存計算模式,無需借助文件存儲,直接通過網絡直傳中間計算結果,避免了組件之間傳輸數據的大量時間損耗。
3 實施架構變更的關鍵技術
根據業務實時性需求的變化,進行大數據處理技術架構由Hadoop向Storm變更時,需要進行業務邏輯開發變更和計算結果輸出方式變更,在變更的同時要注意對開發成本和開發效率的考量。
3.1 業務邏輯開發變更
當從Hadoop架構轉向Storm架構后,業務邏輯需要進行重新開發。在Hadoop架構中,業務邏輯使用HiveQL語言開發。HiveQL是Hadoop平臺提供的類SQL語言,供開發工程師編寫存儲過程以操作Hive數據倉庫中的表和數據,從而完成所需的數據處理過程。在運行Hive存儲過程時,Hive解釋器會生成執行計劃,將HiveQL語句解析成底層的MapReduce程序,提交給JobTracker去執行[7];因此,HiveQL的開發效率較高,開發工程師無需使用JAVA語言直接編寫底層MapReduce程序,而且HiveQL的開發門檻也較低。傳統的數據處理一般都是在關系型數據庫如Oracle中進行,當需要將業務邏輯從Oracle平臺遷移至Hive平臺時,Oracle數據庫開發工程師可以十分容易地進行Hive開發。
而從Hadoop架構轉向Storm架構后,需要開發工程師使用JAVA語言來完成業務邏輯的二次開發,對開發效率和開發成本會產生一定的影響,這是項目規劃中需要重點考量評估的一個關鍵點。
同樣的業務邏輯,由Hadoop架構遷移至Storm架構中時,主要的工作量在于使用Storm編程組件實現HiveQL中可以直接使用的AVG、SUM、COUNT、DISTINCT以及GROUP BY等標準SQL操作。在實現這些功能模塊時,可以巧妙地利用Storm架構的stream grouping特性。stream grouping定義了一系列分組方式,分組方式決定了消息流在各組件間如何傳遞,分組的類型主要包括shuffle grouping(隨機分組)、fields grouping(字段分組)、all grouping(全部分組)和direct grouping(直接分組)等。
例如,可以使用fields grouping字段分組機制來實現GROUP BY操作的功能。在運營商業務邏輯中,經常需要統計分省指標,利用fields grouping機制實現的GROUP BY操作可以用來進行分省指標的計算。fields grouping是這樣一種消息傳遞模式,在spout組件和bolt組件之間,按照消息中指定的某個字段來決定該消息分發至哪一個bolt。在統計分省指標時,可以將省份字段設置為分組的依據。這樣,不同省份的消息可以進入不同省份對應的bolt中,然后在每個省份對應的bolt中對其進行處理,可以得到分省的計算指標。
3.2 計算結果輸出方式變更
在實際應用場景中,大數據分析處理的計算結果往往要寫入到傳統的關系型數據庫中,以方便對計算結果進行展示和管理。在Hadoop架構中,可以使用Hadoop生態環境中的Sqoop工具來完成這一功能。Sqoop可以將計算結果從HDFS或Hive數據倉庫傳輸至傳統關系型數據庫(如Oracle和Mysql),也可以將傳統關系型數據庫中的數據傳輸至HDFS或Hive數據倉庫。出于程序簡潔性的考慮,可以直接將Sqoop傳輸程序插入到Hive存儲過程的結束處,在Hive計算過程完成后直接調用Sqoop傳輸程序來傳送計算結果[8]。
在Storm架構中,輸入數據源源不斷地進入計算系統,每時每刻都在更新計算結果。Storm的設計出于計算速度的考量,采用了內存計算的模式,所以計算結果是存在于內存中的。因為是使用JAVA語言進行程序編寫,所以可以直接使用JDBC的方式連接關系型數據庫,來傳輸計算結果。可以在流式處理系統的最后增加一個bolt組件,來完成這一功能[9]。
如果在每條輸入數據更新計算結果后,都寫入關系型數據庫的話,會對關系型數據庫造成較大的壓力。可以根據時延的要求,選擇以固定的時間頻率寫入關系型數據庫。
4 結束語
隨著互聯網的飛速發展,新的業務對數據處理的實時性要求不斷提高。當傳統的離線處理架構難以滿足實時性要求的時候,可以適時考慮更換大數據處理技術架構來完成業務需求。信息社會瞬息萬變,我們需要不斷地變革和創新,才能為社會創造更好的互聯網服務。
[1]崔杰,李陶深,蘭紅星.基于Hadoop的海量數據存儲平臺設計與開發[J].計算機研究與發展,2012(49):12-18
[2]李美敏.解讀Web 2.0時代的微博文化[EB/OL].[2014-10-20].http://media.people.com.cn/GB/22114/206896/239176/17143067.html
[3]董新華,李瑞軒,周灣灣,等.Hadoop系統性能優化與功能增強綜述[J].計算機研究與發展,2013(50):1-15
[4]林偉偉.一種改進的Hadoop數據放置策略[J].華南理工大學學報,2012(40):152-158
[5]趙建紅.基于Twitter Storm的數據實時分析處理工具研究[J].商情,2013(8):274-275
[6]胡宇舟,范濱,顧學道,等.基于Storm的云計算在自動清分系統中的實時處理應用[J].2014(34):96-99
[7]沙恒,貼軍.基于Hadoop子項目——Hive的云計算性能測試[J].軟件導刊,2012(11):14-16
[8]NextMark.Sqoop在Hadoop和關系型數據庫之間的數據轉移[EB/OL].[2014-10-20].http://www.linuxidc.com/Linux/2014-02/97305.htm
[9]韋海清.淺談Java通過JDBC連接Oracle數據庫技術[J].計算機光盤軟件與應用,2014(7):298-300
猜你喜歡
心理學報(2022年4期)2022-04-12 07:38:02
水泵技術(2021年3期)2021-08-14 02:09:20
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
當代化工研究(2016年9期)2016-03-20 16:22:13
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
西華師范大學學報(自然科學版)(2015年3期)2015-02-27 15:31:22
測繪科學與工程(2013年3期)2013-03-11 15:07:36
