一種基于交叉驗證思想的半監督分類方法
2014-05-25 02:52:16趙建華
西南科技大學學報 2014年1期
趙建華
(1.西北工業大學計算機學院 陜西西安 710072;2.商洛學院計算機科學系 陜西商洛 726000)
機器學習作為人工智能一個重要研究方向,一直受到計算機科學家的關注。當前,機器學習面臨的現實情況是:未標記樣本數目眾多,易于獲得;標記樣本數據稀少,難于獲得。這種現象使傳統的機器學習算法無法得以有效應用,原因在于監督學習需要大量標記樣本對分類器進行迭代訓練。在這種情況下,半監督學習(Semi-Supervised Learning)和主動學習(Active Learning)應運而生并迅速發展,成為解決上述問題的重要技術[1]。
半監督分類[2-3]利用大量無標記數據擴大分類算法的訓練集,主要研究從有監督學習的角度出發,當已標記訓練樣本不足時,如何自動利用大量未標記樣本信息輔助分類器的訓練。根據每個樣本標記數目的不同,半監督分類可以分為單標記分類和多標記分類。對于單標記分類問題,也就是傳統的半監督分類,目前常見的分類方法很多,包括基于EM算法的生成式模型參數估計法[4]、協同訓練方法[5-7]、基于支持向量機的半監督分類方法[8-9]、基于流形的半監督分類方法[10]等;對于半監督多標記分類問題,目前出現的方法包括直推式多標記分類[11]和基于正則化的半監督多標記分類[12]等。
泛化誤差(Generalization)是統計機器學習模型的重要評價指標,在統計中,泛化誤差通常使用交叉驗證方法來估計,所以,交叉驗證方法廣泛地應用到模型選擇領域,實現對模型泛化誤差的估計和選擇[13-14]。有一些研究者或對交叉驗證進行改進,或將其應用到分類領域,取得了較好的效果。文獻[15]提出一種極限學習機的快速留一交叉驗證方法,文獻[16]提出了一種改進的交叉驗證容噪分類算法,文獻[17]將交叉驗證容噪分類算法應用到數據流分類領域,都取得了較好的效果。
通過對國內外大量文獻的查閱,就作者掌握的文獻來看,目前還沒有研究者將交叉驗證思想應用到半監督分類領域,實現對未標記樣本的標記。
本文將交叉驗證思想引入到半監督分類領域,提出一種基于交叉驗證思想的半監督分類算法(Cross Validation Semi-Supervised Support Vector Machine,CV-S3VM),提高半監督單標記分類器的性能。對所選未標記樣本進行偽標記后,形成新的標記集;將新的標記樣本集分為多組,使用SVM作為分類器進行交叉驗證,計算分類準確率,求出每種偽標記所對應的分類誤差率,最后選取能使分類器誤差最小的偽標記作為未標記樣本的最終標記,挖掘未標記樣本信息,擴充未標記樣本數量。最后對算法的性能進行分析,并在UCI數據集進行半監督分類實驗,驗證算法的有效性。
1 基于交叉驗證思想的半監督分類方法(CV-S3VM)
1.1 算法思想
該算法的主要思想是通過對未標記樣本進行偽標記,將偽標記后的樣本加入到標記樣本集中,參與訓練和測試,選取能使分類器誤差較小的標記作為最終的標記,實現對未標記樣本進行標記。依次挖掘未標記樣本的隱含信息,擴充標記樣本的數目。用最終的標記樣本訓練分類器,減少分類器誤差,直接提高學習算法的泛化能力。首先選取一個未標記樣本集U,把U中每一個未標記樣本都作為候選樣本,按照不同的分類類別分別進行不同的偽標記;其次,將標記后的候選樣本放入已標記樣例中形成新的訓練集,將訓練集進行分組、交叉驗證;接著,分別計算在各種偽標記下分類器訓練后誤差值,選取誤差值小的對應標記作為最終的樣本標記值;反復迭代,不斷擴充標記集的樣本數目,作為最終的訓練集。
1.2 算法實現
該算法借鑒交叉驗證思想中分組、交叉、驗證、求平均值等思想和方法挖掘未標記樣本的隱含信息,實現對未標記樣本的標記。具體實現算法描述如表1所示。

表1 交叉驗證半監督分類算法描述Table 1 The description of sem i-supervised classification algorithm based on cross validation
第1步,合理選取有標記樣本集L、未標記樣本集U作為初始的分類器訓練集。
第2步,從未標記樣本集U中選取未標記樣本w,分別給w進行偽標記Mi,其中Mi=1,2,…,m-1,m(假設是進行m分類,m≥2)。
第3步,對任意一個標記為Mi的樣本w,將其依次填加到有標記樣本集L中。
第4步,對于新的有標記樣本集L,按照交叉驗證的思想將其均勻分為k組。將每個子集數據分別做一次驗證集,同時其余的k-1組子集數據作為訓練集,得到k個模型。用這k個模型中的訓練集訓練分類器,使用驗證集進行驗證,得到最終的分類準確率,計算k個模型分類準確率的平均數,得出相應的誤差率。
第5步,選取使得誤差率最小的標記Mx,用其實現對樣本w的最終標記,并將標記后的w添加到L中,實現對L的擴充。
第6步,通過該方法反復迭代,不斷挖掘未標記樣本的隱含信息,擴充標記樣本集L,直到未標記樣本集U為空為止。
第7步,使用擴展后的標記樣本集作為最終的訓練集,訓練形成最終的半監督分類器。
特別地,對于二分類問題,即k=2時,為了能較好地提高標記正確率和分類準確率,采用下面的方式進行處理。當滿足公式(1)時,將未標記樣本標記為第1類,滿足公式(2)時,將未標記樣本標記為第2類。

其中,e1和e2分別表示將未標記樣本歸類為第1類和第2類時對應的誤差,η為可調參數,可以通過η調節分類準確率。
1.3 算法分析
該算法將交叉驗證思想引入半監督分類領域,通過迭代計算誤差,實現了對未標記樣本數據的標記。算法可以在某種意義下得到最優的解,可以有效避免選擇野點,有效避免過學習和欠學習狀態的發生。
算法通過選擇能夠最大程度縮減分類器誤差的樣本進行標記,是一種統計學分析方法,具有很強的統計學基礎,可以建立基于主動學習的統計學學習模型,即基于模型方差最小化的縮減策略[1,18]。期望誤差如式(3)所示,其中D為訓練集,x為輸入特征,y(x)代表x對應的實際類別,y^(x;D)為預測類別。ET(·)和ED(·)都表示在D上的期望誤差,但ED(·)表示通過主動學習,選取誤差小的樣本進行標記后,將新標記樣本擴充到有標記樣本集后的訓練集D。式(3)可以通過式(4)計算求出,式(4)中的第三項可以通過式(5)計算得出,式(5)可以通過式(6)計算。通過交叉驗證半監督學習的目的就是選取期望誤差最小的樣本進行標記。
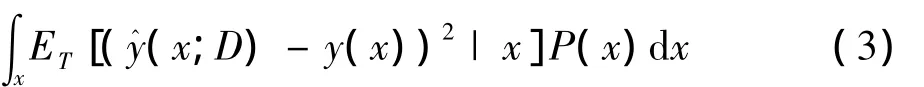
其中,ET(·)表示在D上的期望誤差。
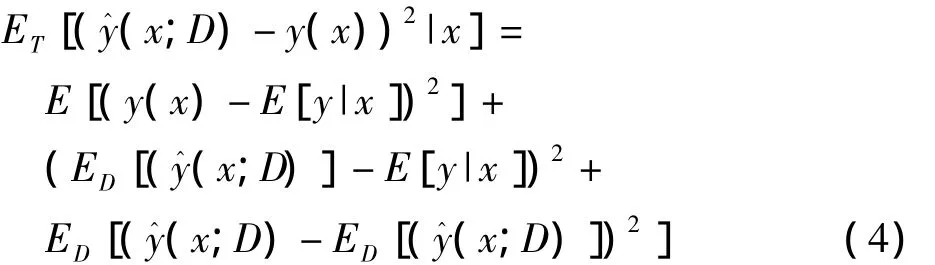
其中,ED(·)表示D更新后在D上的期望誤差。
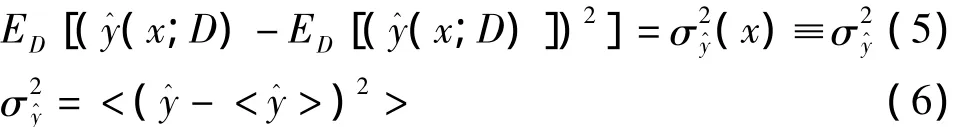
其中,<·>表示增加新的標記樣本后,在D上的期望誤差值。
同時,算法操作簡單,可行性強,較容易實現對未標記樣本的標記,同時能較容易實現2分類問題和多分類問題。當m的值為2時,算法可以解決2分類問題,當m>2時,算法很容易地轉化為解決多分類問題。該算法時間復雜度為O(n1*n2),其中n1表示選取的未標記樣本集中樣本數目,n2表示選取的標記樣本中樣本的數目,一般情況下n1?n2。
2 實驗
實驗平臺選用 Intel Core2 Duo CPU 2.0 GHz、內存2.0 GB的 PC;安裝 Windows XP操作系統和MATLAB 7.8.0(R2009.0a)編程環境;SVM 分類器選用臺灣大學林智仁等人開發的模式識別與回歸機軟件包 libsvm -mat-2.89-3。
實驗采用 UCI數據庫(http://archive.ics.uci.edu/ml/)中常用的5個數據集,數據集如表2所示。
對于表2所選取的樣本,將訓練集和測試集的樣本數目比例設為1:1。將訓練集分為標記樣本和未標記樣本兩種,按照標記樣本占訓練集樣本數目的比例(如式(7)所示)構造三類半監督分類實驗數據集。第一類,標記樣本占訓練集樣本的5%;第二類,標記樣本占訓練集樣本的10%;第三類,標記樣本占訓練集樣本的20%。
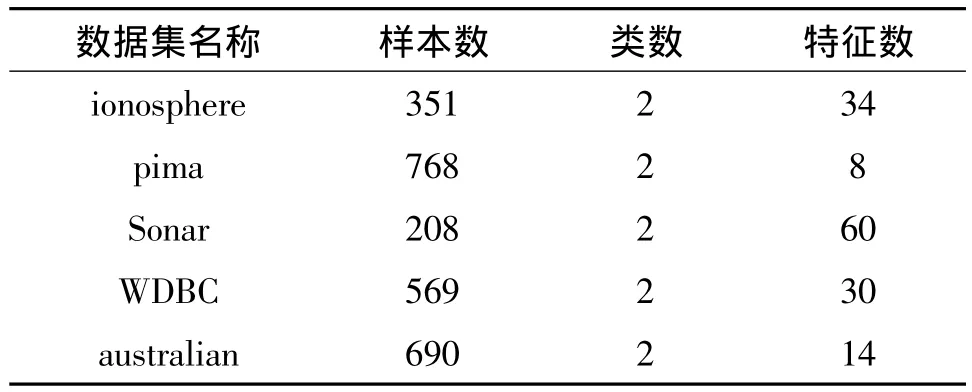
表2 實驗數據集Table 2 Experimental data sets
對于構造的三類半監督分類實驗數據集,分別使用普通的SVM方法(即訓練集僅僅使用初始的有標記樣本集)和CV-S3VM方法(通過交叉驗證方法對未標記樣本標記,擴充標記樣本集)進行分類實驗。按照公式(8)和(9)統計實驗結果,其中P1表示CV-S3VM方法對訓練集中未標記樣本進行標記擴充后,對未標記樣本進行標記的正確率,P2表示SVM和CV-S3VM對測試集樣本進行分類測試的分類正確率。

表3、表4和表5分別表示λ=5%,λ=10%和λ=20%時的實驗結果。圖1-圖5分別表示SVM和CV-S3VM使用5種數據集進行實驗的分類正確率P2和標記正確率P1的實驗結果對比圖。
通過圖表可以看出,CV-S3VM使用了交叉驗證方法對未標記樣本進行了標記和擴充,具有較高的標記率,因此其對測試集樣本的分類率明顯比SVM要高,尤其在Sonar數據集(圖3)中最為明顯。同時,我們也可以看到,在標記樣本集數目較少時,即λ=5%,相對SVM,CV-S3VM的分類率的優越性得到了充分體現。但隨著標記樣本集數目不斷增加,到達一定程度時,CV-S3VM和SVM的分類率差距越來越小。這是由于此時標記樣本數目已經非常充足,半監督學習已經演化成有監督學習。

表3 實驗結果(λ=5%)Table 3 The experimental result(λ=5%)

表4 實驗結果(λ=10%)Table 4 The experimental result(λ=10%)
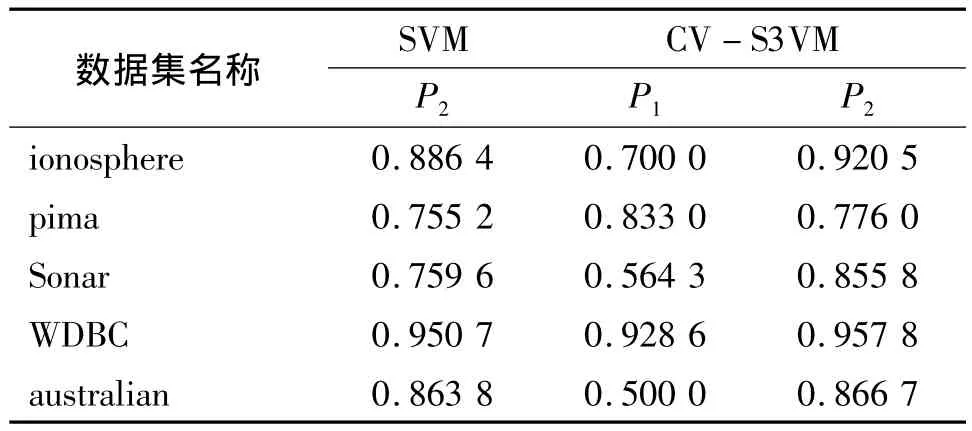
表5 實驗結果(λ=20%)Table 5 The experimental result(λ=20%)
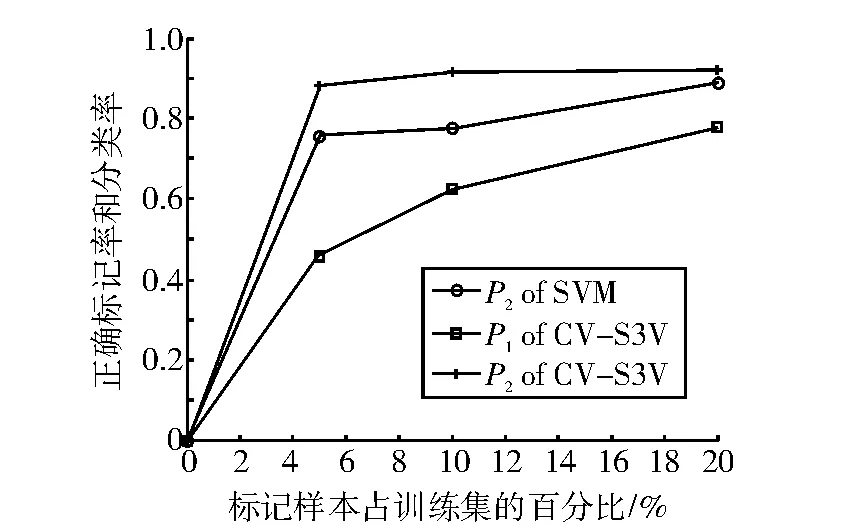
圖1 ionosphere樣本實驗結果對比圖Fig.1 The result comparison chart of sample ionosphere
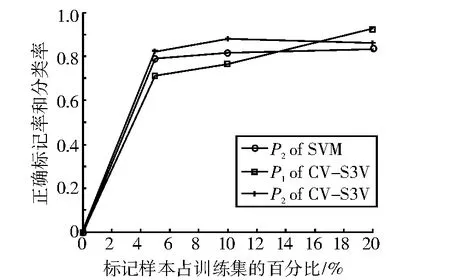
圖2 pima樣本實驗結果對比圖Fig.2 The result comparison chart of sample pima
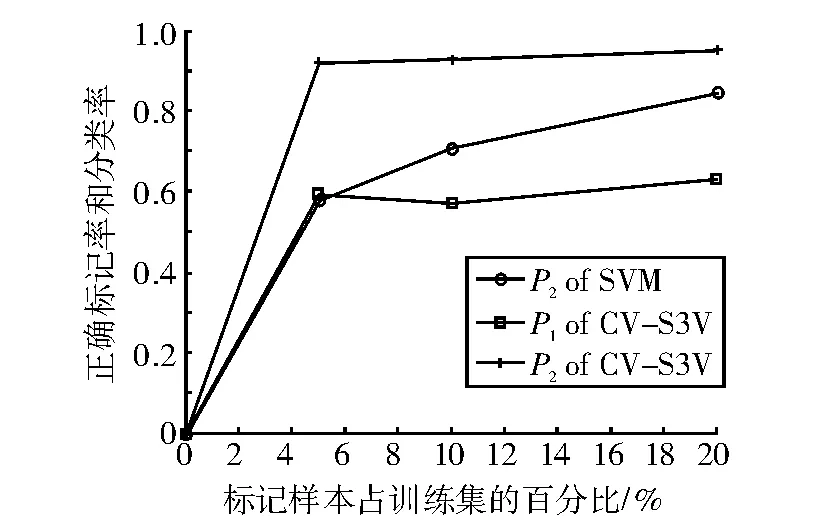
圖3 Sonar樣本實驗結果對比圖Fig.3 The result comparison chart of sample Sonar
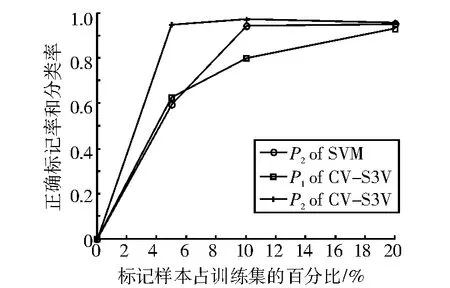
圖4 WDBC樣本實驗結果對比圖Fig.4 The result comparison chart of sample WDBC
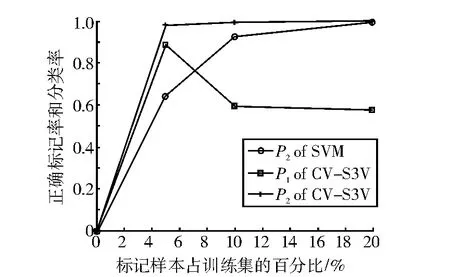
圖5 australian樣本實驗結果對比圖Fig.5 The result comparison chart of sample australian
3 結語
本文將交叉驗證思想引入到半監督分類領域,提出一種基于交叉驗證思想的半監督分類算法(CV-S3VM)。實驗結果表明,CV-S3VM操作簡單、能較容易實現對未標記樣本的標記,性能良好。尤其在標記樣本較少的情況下具有明顯的優越性。可以將該方法應用到病例分類、網絡數據流分類、入侵檢測等標記樣本稀缺領域。
[1]吳偉寧,劉揚,郭茂祖,等.基于采樣策略的主動學習算法研究進展[J].計算機研究與發展,2012,49(6):1162-1173.
[2]ZHU X J.Semi- supervised Learning Literature Survey[R].Madison:University ofWisconsin,2008.
[3]李昆侖,曹錚,曹麗蘋,等.半監督聚類的若干新進展[J].模式識別與人工智能,2009,22(5):735 -742.
[4]CH APELLE O,ZIEN A.Semi-supervised Classification by Low Density Separation[C].Proceedings of the 10th InternationalWorkshop on Artificial Intelligence and Statistics,Barbados,2005.57 -64.
[5]ZHOU ZH ,LIM.Tri-training:exploiting unlabeled data using three classifiers[J].IEEE Transactions on Knowledge and Data Engineering,2005,17(11):1529-1542.
[6]Zhang M L,ZHOU Z H.CoTrade:Confident co-training with data editing[J].IEEE Transactions on Systems,Man,and Cybernetics - Part B:Cybernetics,2011,41(6):1612-1626.
[7]趙建華,李偉華.一種協同半監督分類算法Co-S3OM[J].計算機應用研究,2013,30(11):3249 -3252.
[8]WANG Yun-yun,CHEN Song-cai,ZHOU Zhi- hua.New semi-supervised classification method based on modified cluster assumption[J].IEEE Transactions on Neural Networks and Learning Systems,2012,23(5):689-702.
[9]LIY F,KWOK J T,ZHOU Z H.Cost-Sensitive Semi-supervised Support Vector Machine[A].In:Proceedings of the 24th AAAI Conference on Artificial Intelligences(AAAI'10)[C].Atlanta,GE,2010,500 -505.
[10]MENG Jun,WU Li-xia,WANG Xiu-kun.Granulation-based symbolic representation of time series and semi-supervised classification[J].Computers and Mathematics with Applications,2011,62(9):3581 -3590.
[11]KONG Xiang-nan,NG M K,ZHOU Zhi-hua.Transductive multi-label learning via label set propagation[J].IEEE Transactions on Knowledge and Data Engineering(TKDE),2011.25(3):704 -719.
[12]李宇峰,黃圣君,周志華.一種基于正則化的半監督多標記學習方法[J].計算機研究與發展,2012,49(6):1272-1278.
[13]趙存秀,王瑞波,李濟洪.交叉驗證中類別切分不均衡對分類性能的影響分析[J].太原師范學院學報:自然科學版,2013,12(1):53-57.
[14]杜偉杰,王瑞波,李濟洪.基于均衡7×2交叉驗證的模型選擇方法[J].太原師范學院學報:自然科學版,2013,12(1):27 -31.
[15]劉學藝,李平,郜傳厚.極限學習機的快速留一交叉驗證算法[J].上海交通大學學報,2011,45(8):1141-1145.
[16]JOHN G H.Robust Decision Trees:Removing Outliers from Databases[A].Proceedings of the First International Conference on Knowledge Discovery and Data Mining[C].Menlo Park,CA:AAAIPress,1995.174 -179.
[17]張健沛,楊顯飛,楊 靜.交叉驗證容噪分類算法有效性分析及其在數據流上的應用[J].電子學報,2011,39(2):378-381.
[18]COHN D,GHAHRAMANI Z,JORDAN MI.Active learning with statistical models[J].Journal of Artificial Intelligence Research,1996,(4):129 -145.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
人大建設(2020年4期)2020-09-21 03:39:12
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
人大建設(2017年2期)2017-07-21 10:59:25
人大建設(2017年9期)2017-02-03 02:53:31
發明與創新(2016年38期)2016-08-22 03:02:52
