基于優化支持向量機的高校教師績效評價研究
2014-07-25 03:08:38肖永良朱韶平劉文彬李香寶
赤峰學院學報·自然科學版 2014年24期
肖永良,朱韶平,劉文彬,李香寶
(1.湖南財政經濟學院 信息管理系,湖南 長沙 410205;2.中南大學 信息科學與工程學院,湖南 長沙 410075)
基于優化支持向量機的高校教師績效評價研究
肖永良1,2,朱韶平1,劉文彬1,李香寶1
(1.湖南財政經濟學院 信息管理系,湖南 長沙 410205;2.中南大學 信息科學與工程學院,湖南 長沙 410075)
為了提高高校教師的績效評價效果,本文提出一種基于優化支持向量機的高校教師績效分類方法.采用支持向量機的非線性逼近能力描述績效等級與影響因子間的復雜關系,同時利用改進的遺傳算法對支持向量機參數進行優化處理,進而提高績效識別分類精度.實驗結果表明,與經典支持向量機和神經網絡相比,該模型具有更好的泛化性能,能夠明顯提高高校教師績效的評價效果.
高校教師績效;支持向量機;遺傳算法;參數優化
目前,高校普遍實行了教師聘任制,學校管理部門需要對教師進行全面、公正的績效評價.然而,現有的高校教師績效評價成效并不令人滿意,其中,受批評最多的是評價過程存在過多的主觀因素[1-3].目前,傳統的高校教師績效評價方法主要有層次分析法[4],主成分分析法[5]和模糊綜合評價法[6]等,這些方法大都是基于線性規律進行評價,而高校教師績效與教學、科研、服務社會等多種因素有關,且它們之間存在復雜的非線性關系,很難用這些傳統的評價方法進行準確而全面的描述.近年來,有些學者采用非線性分析能力非常優異的神經網絡建立績效評價模型,取得了不錯的評價效果[7],但也存在以下缺點:不適合信息有限的小樣本,當樣本數目較小時,容易出現過擬合現象;同時迭代過程中也容易產生局部極小的問題.為進一步提高高校教師績效的評價效果,本文提出一種采用自適應遺傳算法和支持向量機結合的高校教師績效評價方法.采用支持向量機的非線性逼近能力描述績效等級與影響因子間的復雜非線性關系.針對采用反復試驗確定模型參數存在的主觀性較強,且難以獲得最優參數的問題,提出利用改進的遺傳算法對支持向量機參數進行優化處理.
1 支持向量機
支持向量機(SVM)是一種統計學理論下的VC維理論和結構風險最小化原則的學習算法[8].其核心思想就是建立一個最優分類面作為決策函數,將已知樣本準確劃分為兩類,同時滿足分類間隔最大的約束條件.由于支持向量機相比于神經網絡對已知樣本的數量要求不高,且求解的是一個凸優化問題,有效的解決了神經網絡存在的過擬合問題,更加適合于小樣本、非線性的分類問題[9].
給定一個獨立分布的樣本集X={(xi,yi),i=1,2,…,n},xi∈Rd,關于它的分類問題簡單介紹如下:若樣本xi屬于第1類,則標記為正(yi=+1),否則標記為負(yi=-1).對于線性分類問題,為獲得最佳分類效果,需要構建以下優化問題:

其中ω為模型參數,b為分類閾值,參數C為樣本的懲罰系數.利用Wolf對偶定律可以將上述優化問題轉化為求解其對偶問題:
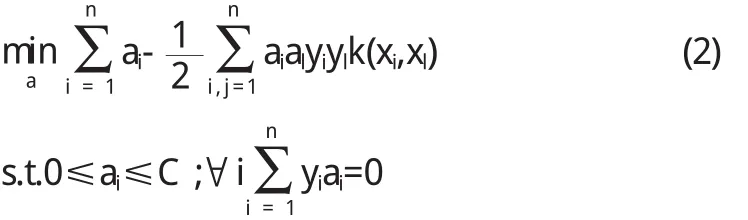
上述優化問題是一個關于Lagrange乘子a的二次規劃問題,存在唯一解.若ai>0,則稱其對應的樣本為支持向量.求解上述對偶問題后,可以得到最優分類函數:

對應非線性分類情況,可以利用非線性函數將訓練樣本從原始輸入空間投影至高維Hilbert空間,然后在該空間中構造出最優分類超平面,能夠使訓練樣本在該空間中進行線性分類.根據泛函理論基礎,利用一種滿足Mercer條件的內積核函數k(xi,x)=?(xi)·?(x),就可以實現某一非線性變換后的線性分類要求.此時,分類函數可表示為:

考慮到徑向基核函數在一般情況下,泛化能力要優于其他的核函數,如線性函數、多項式函數和Sismoid核函數等,因此本文選擇徑向基核函數k(xi,x)=exp(-||x-xi||2/2σ2)構建分類函數,高校教師績效評價模型可表示為:

2 基于優化SVM的教師績效評價模型
在運用徑向基核函數SVM建立績效評價模型過程中,需要預先確定參數C和σ.選取恰當的C可改善模型的抗噪聲能力,從而提高SVM的穩定性;參數σ則在一定程度上決定了模型預測的精度和泛化能力.當前常采用反復試驗的方法確定模型參數,主觀性較強,且難以獲得最優參數來保證模型的評價效果.為解決此問題,本文對遺傳算法中的交叉和變異概率進行改進,自適應獲取SVM模型的最優參數.
2.1 采用遺傳算法自適應優化模型參數
遺傳算法在解空間中利用隨機方法產生多個起始點并同時進行搜索,是一種能夠在復雜空間快速搜索全局最優解的智能優化方法[10,11].本文采用自適應遺傳算法來優化評價模型參數C和σ,參數優化流程如圖1所示.

圖1 績效評價模型參數優化流程
(1)種群初始化處理.采用隨機的方式對種群進行初始化,種群中的每一個個體為一個參數C和σ的組合.
(2)參數編碼.考慮到參數C和σ的優化是一個連續優化的過程,為了防止二進制需要反復譯碼和編碼操作,本文采用實數編碼的策略.
(3)適應度函數設計.在參數C和σ尋找最優解的過程中,搜索方向由適應度函數來引導,本文采用樣本識別率(PR)作為自適應度函數:

(4)遺傳操作.遺傳操作是參數尋優的關鍵步驟,包括選擇、交叉和變異等過程.為了保證適應度比較大的個體進入下一代的幾率也相應增大,本文采用輪盤賭選擇法對個體進行選擇.考慮到個體適應度低于平均適應度時,表明該個體已經嚴重退化,需要采用較大的概率進行交叉和變異處理,才能夠產生新的種群.而適應度較大的個體隨著種群的不斷進化,其交叉和變異概率則應適當減少.本文中交叉概率(pc)和變異概率(pm)根據如下公式計算:

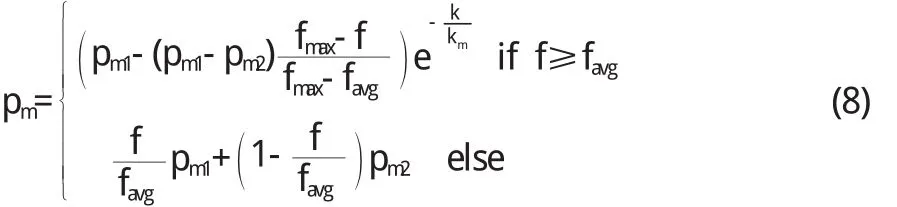
式中,pc1和pc2分別表示最大和最小交叉概率,pm1和pm2分別表示最大和最小變異概率,fmax和favg分別表示個體中最大和平均適應度,f表示變異個體的適應度,f'為交叉個體中較大的適應度,k和km分別為第k次遺傳代數和最大遺傳代數.
(5)最優參數確定.當算法的迭代次數達到預定次數時,尋優過程停止,并將得到的參數作為參數C和σ的最優值.
從式(7)和式(8)可以看出,改進的交叉和變異概率隨種群的不斷進化而不斷自適應調整.在種群進化早期,采用較大的交叉和變異概率可以促使優良個體不斷的生長.到進化晚期,采用逐漸減小的交叉和變異概率可以確保種群穩定,最大限度保留優秀的個體.
2.2 建立教師績效多分類器模型
本文利用支持向量機構建高校教師績效評價模型.首先組織專家根據考核指標對部分高校教師績效進行綜合測評,然后將評價特征作為評價模型的輸入,評價結果作為評價模型的輸出,通過自適應學習算法不斷學習專家的經驗、知識及對指標重要性的傾向,獲得具有最優參數的高校教師績效評價模型.考慮到高校教師績效存在多個等級,一般分為1級(優秀)、2級(良好)、3級(合格)、4級(不合格),而支持向量機只適合于兩分類問題,因此必須對支持向量機的兩分類情況進行擴展,構造一個績效評價多分類器,從而實現績效的自動分類.本文采用一對一的策略構造績效評價多分類器,具體構造過程如圖2所示.
具體而言,首先利用績效評價模型將教師劃分為優秀和非優秀兩類,然后將非優秀教師劃分為良好和非良好兩類,其他依此類推.考慮到師德指標的重要性,如教師存在師德問題,則直接將該教師的績效評價結果評定為不合格等級.
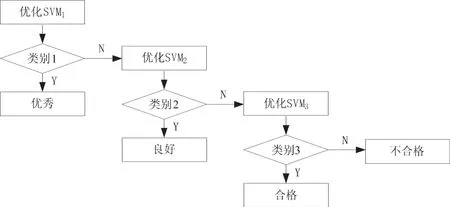
圖2 績效多分類器構建過程
3 實驗結果與分析
3.1 數據樣本及指標選取
本文從職業道德、教學水平和科研能力三個大方面對高校教師績效進行評價,將其細化為以下具體指標:職業道德、教學態度、學術道德、學生滿意度、教學工作量、教學方法、教學效果、教學評價,學術論文、學術專著、科研項目、發明專利、科研經費、成果獎勵、學科建設、學術交流、學生獲獎和團隊精神等.考慮到沒有公開的標準數據進行分析,實驗所用科研和教學部分數據通過已公開信息整理獲取,其余數據通過人工調研獲取.從教師績效數據庫中選擇100個樣本,其中55個樣本用來對支持向量機進行訓練,剩余的樣本用來進行測試.
3.2 績效數據預處理
為了避免各個績效指標之間的量級差別,同時消除各個指標由于量綱和單位不一致產生的影響,在進行建模之前,利用最小-最大準則對績效指標進行歸一化處理,計算公式如下:

式中xi為第i個績效評價指標原始值,xi'為歸一化后的值,xmax和xmin分別表示每個績效指標的最大值和最小值.
3.3 績效評價結果
為了驗證本文算法的有效性,采用經典SVM和神經網絡作為對比模型,建立高校教師績效評價模型.利用自適應遺傳算法優化評價模型參數時,種群數目設為10,參數km=100,pc1=0.9,pc2=0.7,pm1=0.1,pm2=0.08,參數C的取值范圍為[1,100],σ的取值范圍為[0.0001,10].經典SVM模型的參數設定為c=30,σ=2.00,神經網絡采用Sigmoid激活函數.利用自適應遺傳算法對支持向量機模型參數進行優化得到c=11.76,σ=1.12.采用識別率對模型性能進行評價,3種模型評價結果如圖3所示.
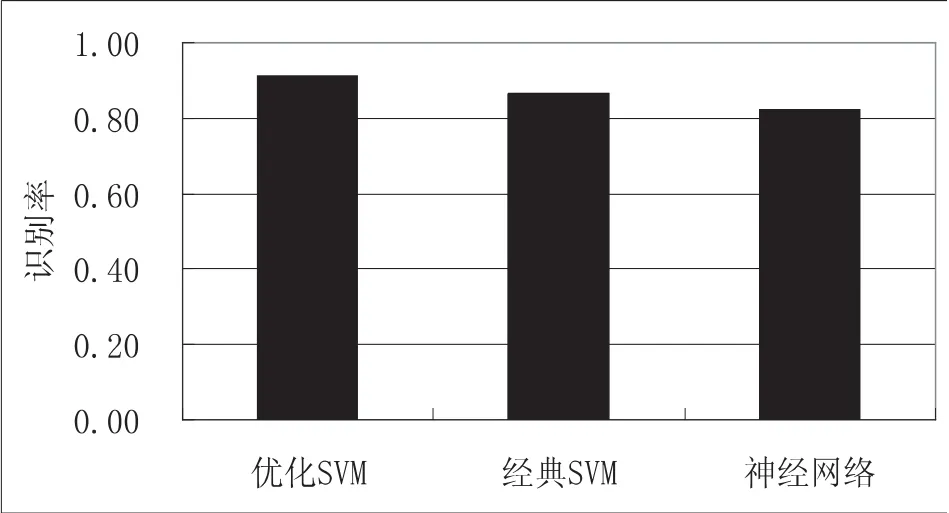
圖3 3種績效評價模型的性能對比
對比圖中各種績效評價模型性能可知:
(1)在3種績效評價模型中,本文提出的優化支持向量機模型具有最好的教師績效評價效果,其評價準確率達到91.1%,分別超過經典支持向量機和神經網絡4.4%和8.9%.這表明采用遺傳算法優化支持向量機參數建立的評價模型比傳統的評價模型具有更好的性能.
(2)對比優化支持向量機和經典支持向量機評價結果可知,參數C和σ對模型評價效果影響很大,利用自適應遺傳算法對評價模型參數進行優化處理,可獲得更好的績效評價效果.
(3)采用優化SVM和經典SVM模型的績效評價效果都明顯優于神經網絡模型,這是因為支持向量機可以有效解決神經網絡學習過程中存在的過擬合和局部最優問題.同時,支持向量機可以從有限的樣本信息中獲得更好的績效評價效果,比神經網絡更加適合于小樣本問題.
3.4 績效評價模型修正
如對所得到的評價結果有疑問,可將其與專家的評判結果進行對比.如確屬誤判,則將該樣本重新加入訓練集進行訓練,以獲得匹配率更高的評價模型.對高校教師績效進行評定時,考慮到評價模型的時間連續性,可利用本年度所有的測評結果訓練評價模型后,對來年的教師績效進行評價.如來年的評價標準發生了變化,則必須根據專家的綜合評價結果重新確定模型參數再進行績效評價.
4 結束語
本文利用支持向量機的小樣本、非線性特點,構建了支持向量機績效評價模型,同時利用自適應遺傳算法對支持向量機的參數進行優化處理,獲得了最優績效評價模型.實驗結果表明本文提出的優化支持向量機績效評價方法比其他方法具有更好的評價效果,能夠最大程度再現專家對指標重要性的傾向,實現定性與定量的有機結合,保證評價的客觀性和一致性.進一步的研究工作是,與高校管理部門合作收集業績數據來驗證績效評價模型的實際效果.
〔1〕王光彥,李元元,邱學青,等.高校教師績效評價指標體系的實證研究與思考[J].中國高教研究,2008,18(2):46-49.
〔2〕王曉峰.高校教師績效考核的環境分析與路徑選擇[J].湖南科技大學學報:社會科學版,2012,15(5):178-180.
〔3〕喬錦忠,韓莉莉,石興娣.高校教師績效與晉升[J].新疆師范大學學報:哲學社會科學版,2012,33(5):87-93.
〔4〕王璟.基于層次分析法的高校教師績效評價實證研究[J].閩江學院學報,2011,32(6):124-128.
〔5〕周雙喜,馮俊文.基于PCA的高校教師績效考核指標體系構建研究[J].南京理工大學學報:社會科學版,2011,24(3):90-95.
〔6〕王宏,杜麗萍,張帥.基于模糊綜合評價法的高校教師績效評價模型[J].河北理工大學學報:社會科學版,2011,11(1):56-58.
〔7〕王向,李媚,張坤.基于模糊神經網絡的績效評價體系研究[J].河北省科學院學報,2013,30(1):5-10.
〔8〕CortesC,VapnikV.Supportvectornetworks[J].Machine Learning,1995,20(8):273-293.
〔9〕ZhaoJW,ChenQS,HuangXY,etal.Qualitative identification of tea categories by near infrared spectroscopy and support vector machine [J]. Pharmaceuticaland BiomedicalAnalysis,2006,41(4):1198-1204.
〔10〕Deng G F,Huang X X,Gao Q H,etal. Developmentofan improved geneticalgorithm for resolvinginversekinematicsofvirtualhuman’supper limbkinematicschain[J].LectureNotesinControland InformationSciences,2014,452(1):189-211.
〔11〕田豐,邊婷婷.自適應遺傳算法的交通信號配時優化[J].計算機仿真,2010,27(6):305-308.
TP18;TP273
A
1673-260X(2014)12-0025-03
湖南省教育科學規劃課題《基于自適應學習的高校教師績效評價方法研究》(XJK013CGD083)終結性成果;湖南省教學改革研究項目(湘教通【2014】247-612);湖南財政經濟學院教學改革研究項目
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
學習月刊(2016年4期)2016-07-11 02:54:18
中國商論(2016年33期)2016-03-01 01:59:53
人間(2015年19期)2016-01-04 12:46:58
中國鄉鎮企業會計(2015年9期)2015-12-30 16:47:21
中國工程咨詢(2015年5期)2015-02-16 05:35:26
繼續教育研究(2014年2期)2014-02-27 16:10:46
