多核處理器中基于MapReduce的哈希劃分優(yōu)化
2014-08-07 12:18:07袁通劉志鏡劉慧王梓
西安交通大學(xué)學(xué)報(bào) 2014年11期
袁通,劉志鏡,劉慧,王梓
(西安電子科技大學(xué)計(jì)算機(jī)學(xué)院, 710071, 西安)
多核處理器中基于MapReduce的哈希劃分優(yōu)化
袁通,劉志鏡,劉慧,王梓
(西安電子科技大學(xué)計(jì)算機(jī)學(xué)院, 710071, 西安)
針對傳統(tǒng)的并行哈希劃分算法不能高效地利用多核處理器的并行資源,且不能較好處理有傾斜的輸入數(shù)據(jù)的問題,提出了一種在多核處理器中基于MapReduce的哈希劃分算法,并且提出了存儲結(jié)構(gòu)優(yōu)化、多步劃分優(yōu)化、數(shù)據(jù)傾斜優(yōu)化3種優(yōu)化策略。該算法將輸入數(shù)據(jù)分成若干塊后提交給各個(gè)線程并行處理,并選擇合適的策略避免寫沖突,使其能夠高效地利用多核處理器的并行資源。文中提出的哈希表能夠提高cache效率,從而提升算法的整體性能。引入MapReduce模型可使多步哈希劃分在Map過程和Reduce過程中分別進(jìn)行;數(shù)據(jù)傾斜優(yōu)化策略能使算法適應(yīng)有傾斜的輸入數(shù)據(jù),且具有較好的效果。實(shí)驗(yàn)結(jié)果表明:在多核處理器中,文中提出的算法能夠適應(yīng)各種分布的輸入數(shù)據(jù),并且使哈希劃分的整體性能得到提升。
數(shù)據(jù)劃分;哈希處理;多核處理器;MapReduce模型
劃分是數(shù)據(jù)庫中的重要操作,同時(shí)也是其他數(shù)據(jù)庫操作(如連接、聚集、排序等)的基本操作。劃分是將一個(gè)較大的任務(wù)分成若干個(gè)較小的子任務(wù),而處理若干個(gè)子任務(wù)所用的時(shí)間常常少于處理一個(gè)較大任務(wù)所用的時(shí)間,這是因?yàn)檩^小的任務(wù)能夠高效地利用cache和內(nèi)存。哈希劃分是使用范圍最廣的劃分算法。
當(dāng)今的硬件發(fā)展十分迅速,CPU擁有更多的核心,每個(gè)核心擁有更多的線程。最近,IBM推出了新一代的POWER 8處理器,支持12核心96線程,共享96 MB的三級緩存,這說明多核CPU具有廣闊的應(yīng)用前景。面對新型的硬件架構(gòu),傳統(tǒng)的并行哈希劃分算法存在以下不足:①不能高效地利用多核處理器的并行資源,包括不能有效地降低內(nèi)存存取延遲、減少cache丟失和TLB丟失等;②存儲結(jié)構(gòu)不能高效地支持多核并行讀寫;③不能較好地處理有傾斜的輸入數(shù)據(jù)。
針對這些問題,本文提出一種多核處理器中基于MapReduce的哈希劃分優(yōu)化方法,用基于共享內(nèi)存的MapReduce模型實(shí)現(xiàn)了哈希劃分算法,并比較了4種避免線程沖突的策略。MapReduce模型的使用可以使算法高效地利用多核并行資源。在此基礎(chǔ)上,提出了存儲結(jié)構(gòu)優(yōu)化、多步劃分優(yōu)化、數(shù)據(jù)傾斜優(yōu)化3種有效的優(yōu)化方法,以解決現(xiàn)有算法的不足。
1 相關(guān)工作
對于在不同應(yīng)用中的劃分操作,人們已經(jīng)進(jìn)行了大量的研究,這些研究主要是針對數(shù)據(jù)庫操作的。在連接操作[1]和聚集操作[2]中,劃分能夠明顯地提升操作性能。Balkesen等人的研究表明,在整個(gè)連接操作中劃分操作占用了大部分時(shí)間[3]。Manegold等人證明了當(dāng)劃分?jǐn)?shù)量較大時(shí),多步劃分比單步劃分效果要好,且多步劃分中第一步的劃分?jǐn)?shù)量等于第二步的劃分?jǐn)?shù)量時(shí)效果最好[4]。這是因?yàn)槎嗖絼澐直苊饬舜罅康腸ache丟失和TLB丟失,且內(nèi)存壓力較小。但是,他們提出的Radix-cluster劃分并不支持多核并行處理。Cieslewicz等人提出了在多核處理器中并行劃分的方法[5],但局限性是存儲結(jié)構(gòu)事先需知道每個(gè)劃分中的元組數(shù)量,且其算法只在處理均勻分布的輸入數(shù)據(jù)時(shí)有較好的效果,而多核負(fù)載均衡性并不理想。Lisa等人提出用硬件加速器來提升劃分性能[6],但這種方法受限于硬件系統(tǒng)。
MapReduce[7]自2004年問世以來,已經(jīng)證明其在處理海量數(shù)據(jù)時(shí)有巨大的優(yōu)勢。MapReduce最初是針對機(jī)群提出的,其性能經(jīng)常受硬盤IO和網(wǎng)絡(luò)IO的制約,而基于共享內(nèi)存的MapReduce[8]則避免了這些瓶頸,適合處理內(nèi)存數(shù)據(jù)。所以,數(shù)據(jù)庫管理系統(tǒng)(DBMS)可以利用基于共享內(nèi)存的Map-Reduce來優(yōu)化劃分算法。基于共享內(nèi)存的MapReduce模型適用于多核處理器,處理器的每一個(gè)線程被當(dāng)作一個(gè)計(jì)算節(jié)點(diǎn),計(jì)算節(jié)點(diǎn)之間的通信是以共享內(nèi)存的方式完成的。
2 基于MapReduce的哈希劃分
哈希劃分可以通過一個(gè)MapReduce任務(wù)來實(shí)現(xiàn),該MapReduce任務(wù)只實(shí)現(xiàn)Map任務(wù)即可。在Map任務(wù)中,根據(jù)鍵值對中鍵值的哈希值將該鍵值對寫入結(jié)果區(qū)域。由于多線程并行地將鍵值對寫入結(jié)果區(qū)域,所以可能會產(chǎn)生線程之間的沖突。為了避免寫沖突,常采用以下4種策略。
(1)加鎖策略。所有線程共享一個(gè)鍵值對存儲結(jié)構(gòu),每一個(gè)劃分區(qū)域是一個(gè)連續(xù)的存儲空間;線程需要加鎖后才能將鍵值對寫入相應(yīng)的劃分區(qū)域,寫入完成后需要解鎖以便其他線程繼續(xù)寫入該區(qū)域。該策略的優(yōu)點(diǎn)是內(nèi)存消耗較小,且不會隨著線程數(shù)量的增加而增加;缺點(diǎn)是頻繁的加鎖、解鎖操作影響性能。
(2)無鎖策略。每個(gè)線程有一個(gè)獨(dú)立的鍵值對存儲結(jié)構(gòu),由于每個(gè)線程只將數(shù)據(jù)寫入自己的存儲結(jié)構(gòu)中,所以避免了頻繁的加鎖解鎖操作。該策略的優(yōu)點(diǎn)是避免了加鎖解鎖操作;缺點(diǎn)是需要額外的操作將所有存儲結(jié)構(gòu)進(jìn)行合并,且內(nèi)存消耗隨著線程數(shù)量的增加而增加。
(3)兩次遍歷策略。該策略的思想來源于文獻(xiàn)[9],即每個(gè)線程2次遍歷分配給它的輸入鍵值對。如圖1所示,在一個(gè)用4線程將數(shù)據(jù)哈希劃分為4份的任務(wù)中,第一次遍歷時(shí)每個(gè)線程計(jì)算出屬于不同劃分的鍵值對的數(shù)量,根據(jù)這些數(shù)據(jù)可以計(jì)算出每個(gè)線程將不同的鍵值對寫入存儲結(jié)構(gòu)的位置
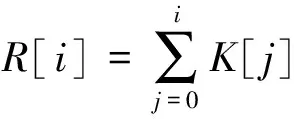
(1)
式中:R[i]為劃分i在最終存儲結(jié)構(gòu)中的起始位置;K[j]為劃分j中鍵值對的數(shù)量;i,j=t+pn,其中t為線程編號(本例中t=0,1,2,3),p為劃分編號(本例中p=0,1,2,3),n為線程總數(shù)(本例中n=4)。
在第二次遍歷時(shí),每個(gè)線程根據(jù)上一步的計(jì)算結(jié)果將鍵值對并行寫入中間鍵存儲結(jié)構(gòu)中。該策略的優(yōu)點(diǎn)是將最終的劃分結(jié)果連續(xù)存儲,提高了程序的局部性,而缺點(diǎn)是需要2次遍歷輸入數(shù)據(jù)。
(4)并行緩存策略[10]。該策略類似于加鎖策略,不同之處是在加鎖策略中每寫入一個(gè)中間鍵值對都需要加鎖解鎖,而在并行緩存策略中每個(gè)線程有大小一定的獨(dú)立存儲空間,將鍵值對寫入獨(dú)立存儲空間時(shí)不需要進(jìn)行加鎖解鎖操作,但當(dāng)該存儲空間耗盡時(shí),需要通過加鎖解鎖操作獲得新的存儲空間。
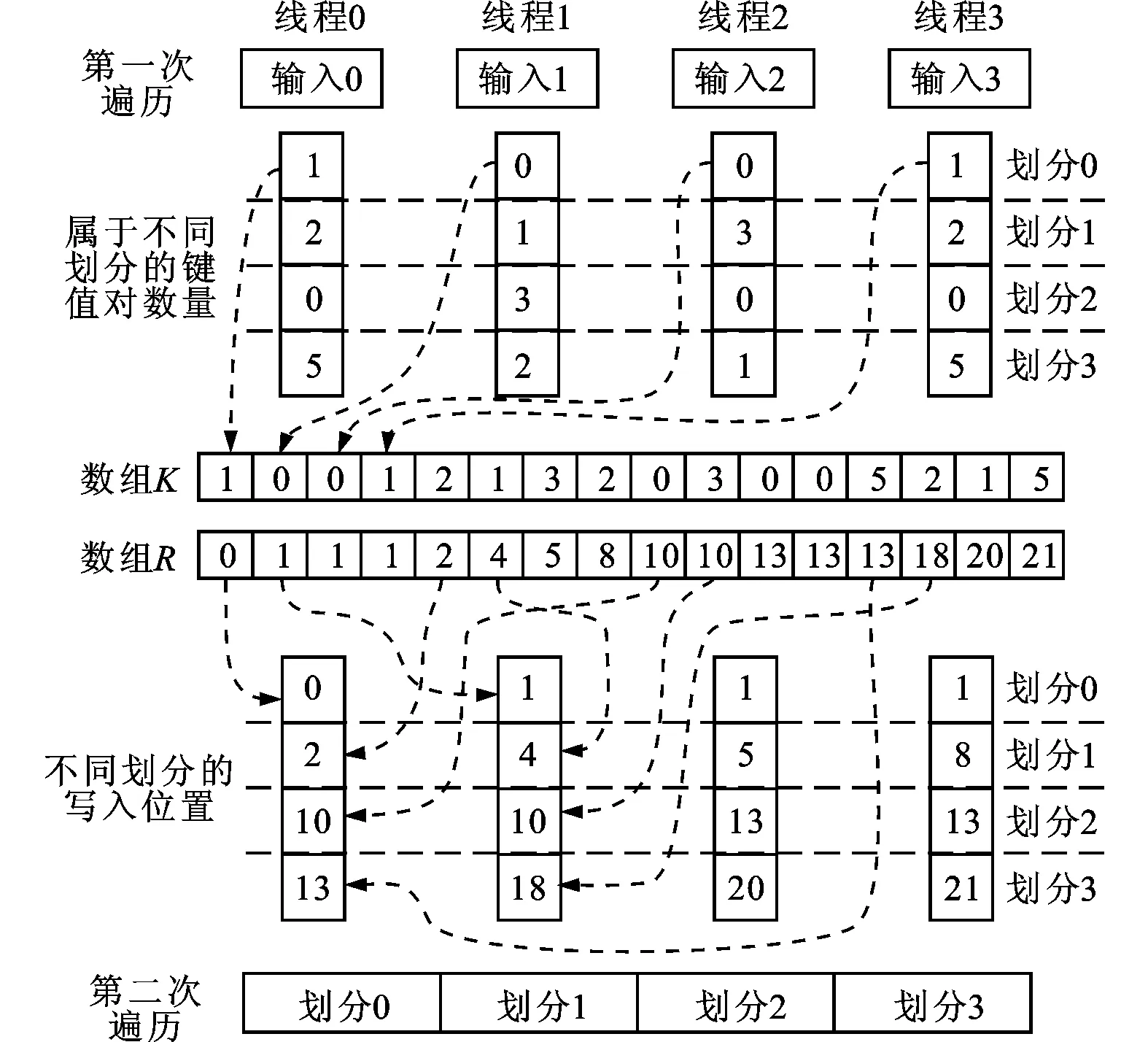
圖1 兩次遍歷策略
3 哈希劃分優(yōu)化方法
在多核處理器中每個(gè)線程被看作一個(gè)計(jì)算節(jié)點(diǎn),利用MapReduce思想可以優(yōu)化哈希劃分。本節(jié)主要從存儲結(jié)構(gòu)優(yōu)化、多步劃分優(yōu)化和數(shù)據(jù)傾斜優(yōu)化這3個(gè)方面來優(yōu)化哈希劃分。
3.1 存儲結(jié)構(gòu)優(yōu)化
哈希表的結(jié)構(gòu)直接影響整個(gè)算法的效果。傳統(tǒng)的哈希表用一個(gè)vector容器或一個(gè)數(shù)組來存儲某一劃分中的鍵值對,如圖2所示。
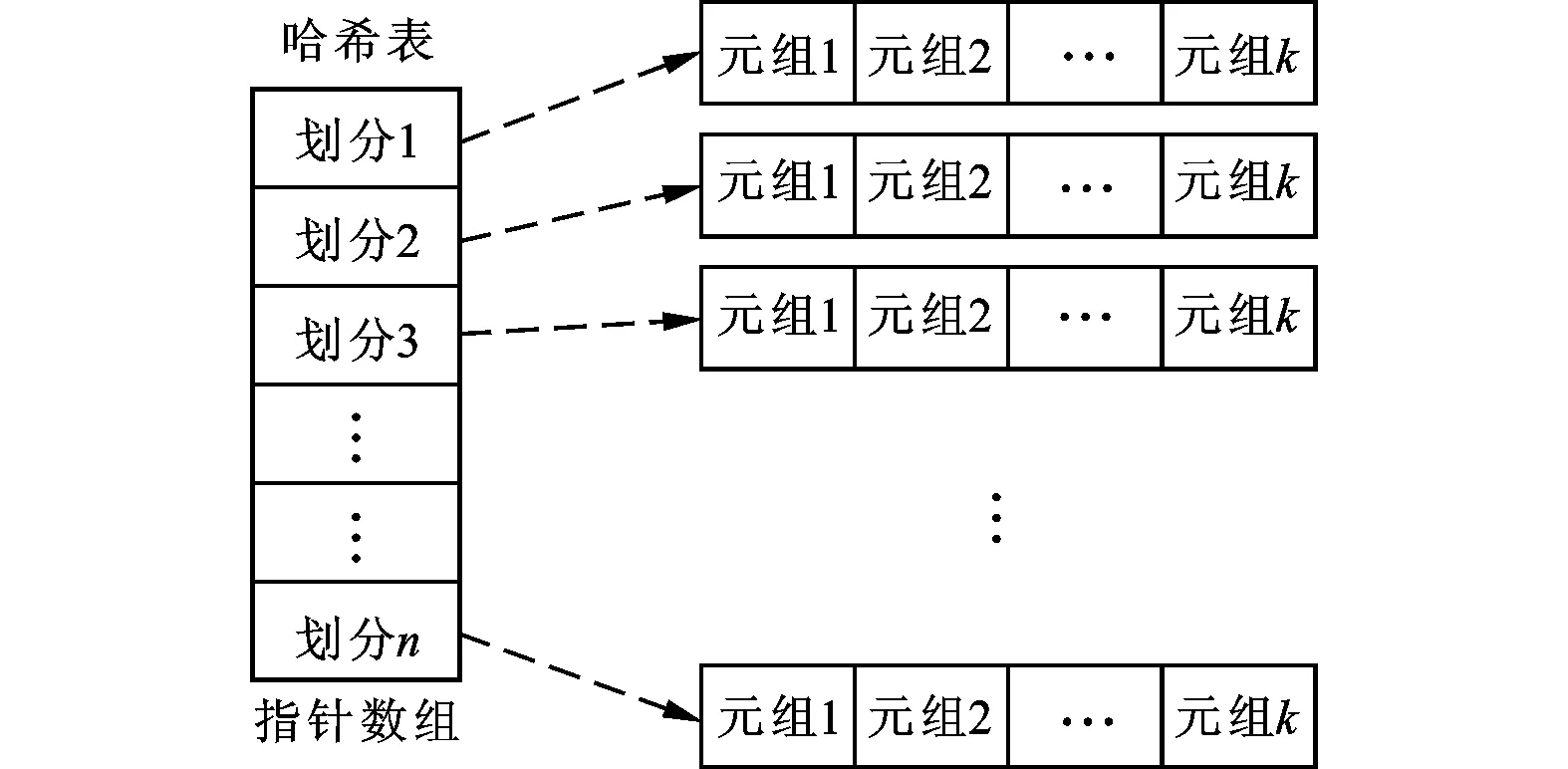
圖2 傳統(tǒng)的哈希表結(jié)構(gòu)
如果用一個(gè)vector容器來存儲某一個(gè)劃分中的鍵值對,當(dāng)已存元組的數(shù)量很大時(shí),元組的存儲效率會明顯降低。如果用一個(gè)數(shù)組存儲某一個(gè)劃分中的鍵值對,元組的存儲效率較高且效率不會隨著存儲元組數(shù)量的增加而降低,但初始化一個(gè)容量較大的數(shù)組所需的開銷卻比較可觀。
為此,在加鎖策略和無鎖策略中,為了提高cache的效率,我們采用一種優(yōu)化的哈希表存儲結(jié)構(gòu)。不同于傳統(tǒng)的哈希表,優(yōu)化的哈希表用一個(gè)連續(xù)的數(shù)組表示,數(shù)組的每一位表示一個(gè)哈希桶,每一個(gè)哈希桶集中存儲某一個(gè)劃分中的鍵值對,如圖3所示。每一個(gè)哈希桶由2個(gè)指針和一段連續(xù)的存儲空間組成,連續(xù)的存儲空間存儲屬于該劃分的元組,free指針指向該連續(xù)空間中下一個(gè)空閑元組的位置,當(dāng)此哈希桶溢出時(shí),next指針指向另外的哈希桶。此外,每一個(gè)哈希桶的大小等于CPU中cache line的大小,這樣在存取過程中可以避免大量的cache丟失。這樣的設(shè)計(jì)既保證了元組存取效率,又降低了初始化的開銷。
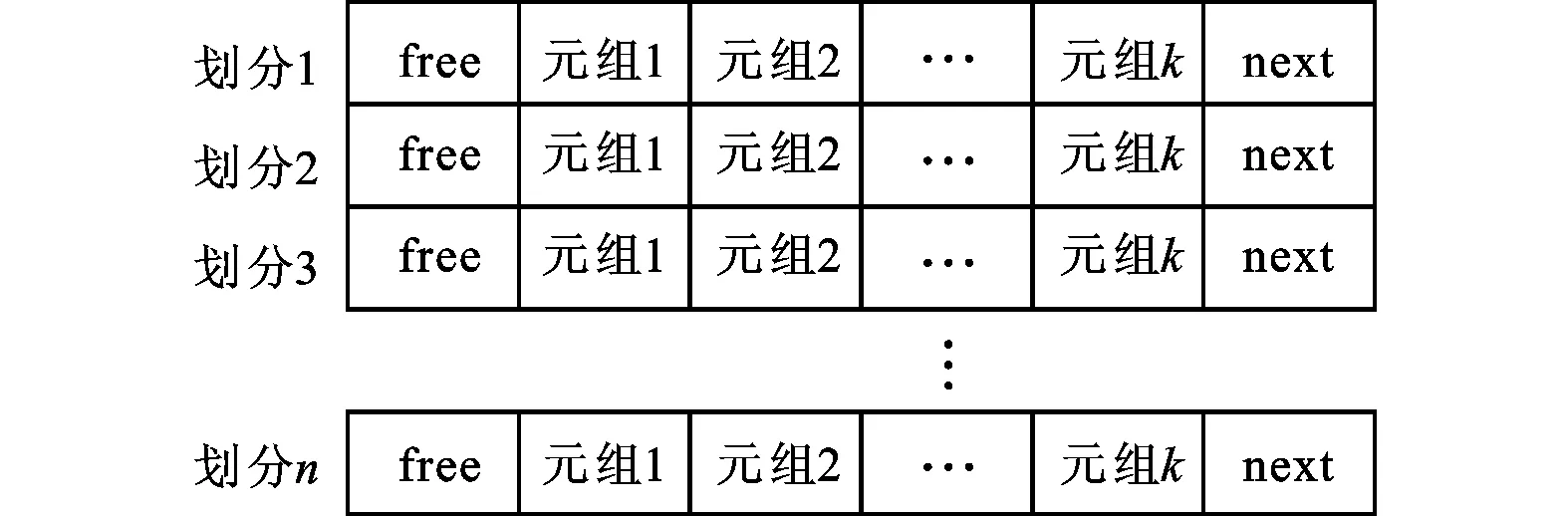
圖3 改進(jìn)的哈希表結(jié)構(gòu)
3.2 多步哈希劃分優(yōu)化
可以利用基于共享內(nèi)存的MapReduce模型來優(yōu)化多步哈希劃分,用Map過程進(jìn)行第一次劃分,用Reduce過程進(jìn)行第二次劃分。
圖4表示了利用基于共享內(nèi)存的MapReduce模型優(yōu)化兩步哈希劃分的流程,圖中p1表示第一次劃分的數(shù)量,p2表示第二次劃分的數(shù)量,所以最終產(chǎn)生p1p2個(gè)劃分結(jié)果。
首先將輸入數(shù)據(jù)分割成若干塊,每一塊數(shù)據(jù)交給一個(gè)Map線程進(jìn)行第一次哈希劃分,產(chǎn)生p1個(gè)劃分結(jié)果。Map線程之間的寫沖突問題可以用第2節(jié)中的4種策略之一解決。由于首先將輸入數(shù)據(jù)分割成大小相同的塊,所以第一次劃分中各個(gè)線程處理的數(shù)據(jù)量大致相同,有良好的負(fù)載均衡。
接下來,p1個(gè)劃分結(jié)果產(chǎn)生p1個(gè)Reduce任務(wù),每一個(gè)Reduce任務(wù)交給一個(gè)Reduce線程處理,進(jìn)行第二次哈希劃分,得到最終p1p2個(gè)劃分結(jié)果。這里需要注意2個(gè)問題:①p1個(gè)Reduce任務(wù)的大小可能不一致,這將導(dǎo)致某些Reduce線程處理較多的數(shù)據(jù),出現(xiàn)負(fù)載不均衡問題,從而導(dǎo)致總體處理時(shí)間的增加;②由于最終p1p2個(gè)劃分結(jié)果中的某一個(gè)劃分只可能來自第一次哈希劃分的p1個(gè)劃分結(jié)果中的某一個(gè)劃分,所以在第二次哈希劃分中,Reduce線程之間不會出現(xiàn)寫沖突。
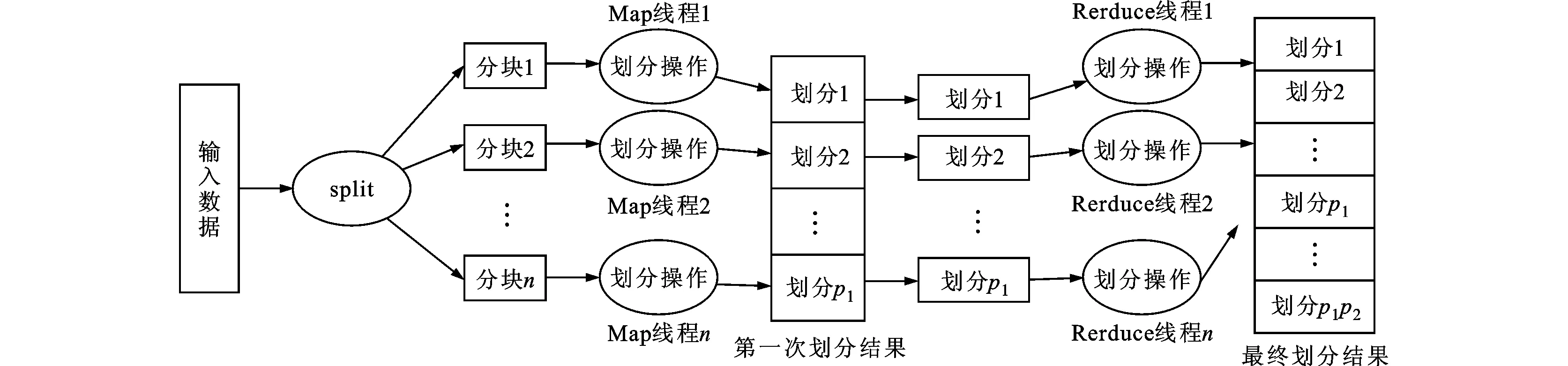
圖4 利用基于共享內(nèi)存的MapReduce模型優(yōu)化兩步哈希劃分
3.3 數(shù)據(jù)傾斜優(yōu)化
在多步哈希劃分中,由于第一次劃分產(chǎn)生的Reduce任務(wù)大小可能不一致,所以可能造成Reduce過程中的負(fù)載不均衡,導(dǎo)致總體處理時(shí)間增加。為此,提出以下優(yōu)化方法,具體步驟如下。
(1)設(shè)定一個(gè)閾值T,用于比較第一次哈希劃分的Reduce任務(wù)的大小。
(2)Reduce線程在處理Reduce任務(wù)之前,先比較Reduce任務(wù)的大小和閾值T,如果Reduce任務(wù)小于T,則Reduce線程處理該任務(wù);如果Reduce任務(wù)大于T,則將該任務(wù)加入隊(duì)列D中,并不進(jìn)行處理。至此,小于T的任務(wù)都已被處理,而大于T的任務(wù)都沒有被處理,且都保存在D中。
(3)將隊(duì)列D中的每一個(gè)任務(wù)平均分為n份(n為Reduce線程的數(shù)量),將n份任務(wù)交給n個(gè)Reduce線程并行處理。
(4)將隊(duì)列D中的每一個(gè)任務(wù)處理完后,得到最終的劃分結(jié)果。
上述優(yōu)化方法利用多核運(yùn)算能力解決了多步哈希劃分中Reduce任務(wù)負(fù)載不均衡的問題。通常將閾值T設(shè)定為2C/p1,其中C表示最初輸入數(shù)據(jù)的大小,p1表示第一次劃分產(chǎn)生的劃分結(jié)果的數(shù)量,也就是Reduce任務(wù)的數(shù)量。
4 實(shí)驗(yàn)與分析
4.1 實(shí)驗(yàn)環(huán)境
利用C++語言在Linux系統(tǒng)中實(shí)現(xiàn)了基于MapReduce的哈希劃分及其優(yōu)化方法。本文的實(shí)驗(yàn)環(huán)境基于新型英特爾Sandy Bridge架構(gòu)的Xeon 8核處理器(E5-2670 2.6 GHz),每核包含2個(gè)線程。具體配置如下:核數(shù)為8;線程數(shù)為16;一級緩存大小為每核32 KB;二級緩存大小為每核256 KB;三級緩存大小為共享20 MB;內(nèi)存大小為4×8 GB DDR3內(nèi)存(1 600 Hz);cache line大小為64 B;快表(TLB)大小為每核64個(gè)。
本實(shí)驗(yàn)采用了2種數(shù)據(jù)集:一種是均勻分布的數(shù)據(jù)集(用A表示);另一種是有數(shù)據(jù)傾斜的數(shù)據(jù)集(用B表示)。2種數(shù)據(jù)集均含有16×220條元組,其中每條元組的大小為16 B,含有8 B的編號和8 B的劃分值。這種元組結(jié)構(gòu)常應(yīng)用在列存儲數(shù)據(jù)庫之中。對于有數(shù)據(jù)傾斜的數(shù)據(jù)集,采用Zipf指數(shù)來衡量傾斜程度。詳細(xì)的數(shù)據(jù)集屬性見表1。

表1 實(shí)驗(yàn)數(shù)據(jù)集屬性
4.2 單步劃分實(shí)驗(yàn)與分析
圖5給出了4種不同寫策略下單步哈希劃分的實(shí)驗(yàn)結(jié)果。實(shí)驗(yàn)使用的是數(shù)據(jù)集A,且采用了前述的優(yōu)化方法。在加鎖策略中,當(dāng)Hash Bits較小時(shí),每一個(gè)劃分結(jié)果有較多的元組,頻繁的加鎖解鎖操作會影響整體性能。隨著Hash Bits的增加,每一個(gè)劃分結(jié)果的元組數(shù)量減少,線程之間的沖突減少,整體性能提升。隨著Hash Bits繼續(xù)增加,cache丟失和TLB丟失會影響程序的性能。在無鎖策略中,因?yàn)闆]有加鎖解鎖操作,在Hash Bits較小時(shí)程序性能大大優(yōu)于加鎖策略的程序性能。由于程序需要許多額外的變量記錄當(dāng)前寫入位置、劃分大小等信息,而這些變量的數(shù)量隨著線程數(shù)量的增加而增加,所以隨著Hash Bits的增加,無鎖策略承擔(dān)的內(nèi)存壓力增加。再考慮到cache丟失和TLB丟失的影響,隨著Hash Bits的增加,程序整體性能下降較為明顯。這些分析同樣適用于兩次遍歷策略和并行緩存策略。所以,當(dāng)Hash Bits較大時(shí),加鎖策略優(yōu)于其他3種策略,這說明Hash Bits較大時(shí)cache丟失和TLB丟失的影響大于加鎖解鎖操作的影響。需要說明的是,在兩次遍歷策略中程序的整體性能主要受限于計(jì)算寫入位置的操作。
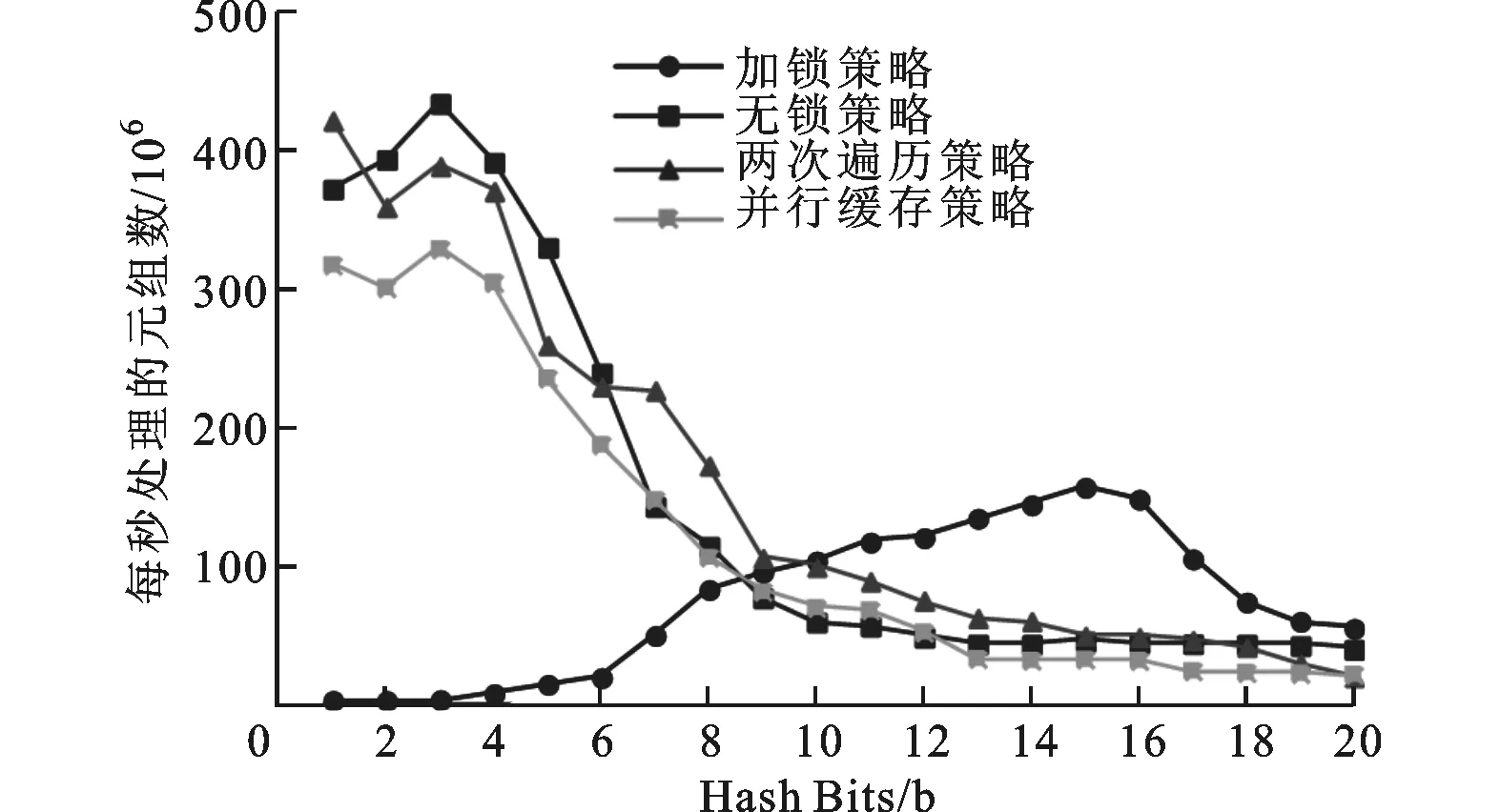
圖5 4種不同寫策略下的單步哈希劃分實(shí)驗(yàn)結(jié)果
圖6給出了本文算法與傳統(tǒng)哈希劃分算法的實(shí)驗(yàn)結(jié)果比較,圖中傳統(tǒng)哈希劃分算法的結(jié)果來自文獻(xiàn)[5]。實(shí)驗(yàn)使用的是數(shù)據(jù)集A,在加鎖策略和無鎖策略下進(jìn)行單步哈希劃分。實(shí)驗(yàn)結(jié)果表明,由于采用了MapReduce模型和本文提出的優(yōu)化方法,所以本文算法比傳統(tǒng)哈希劃分算法的效果更好。
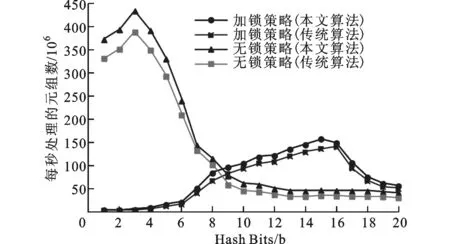
圖6 本文算法與傳統(tǒng)哈希劃分算法的比較
4.3 多步劃分實(shí)驗(yàn)與分析
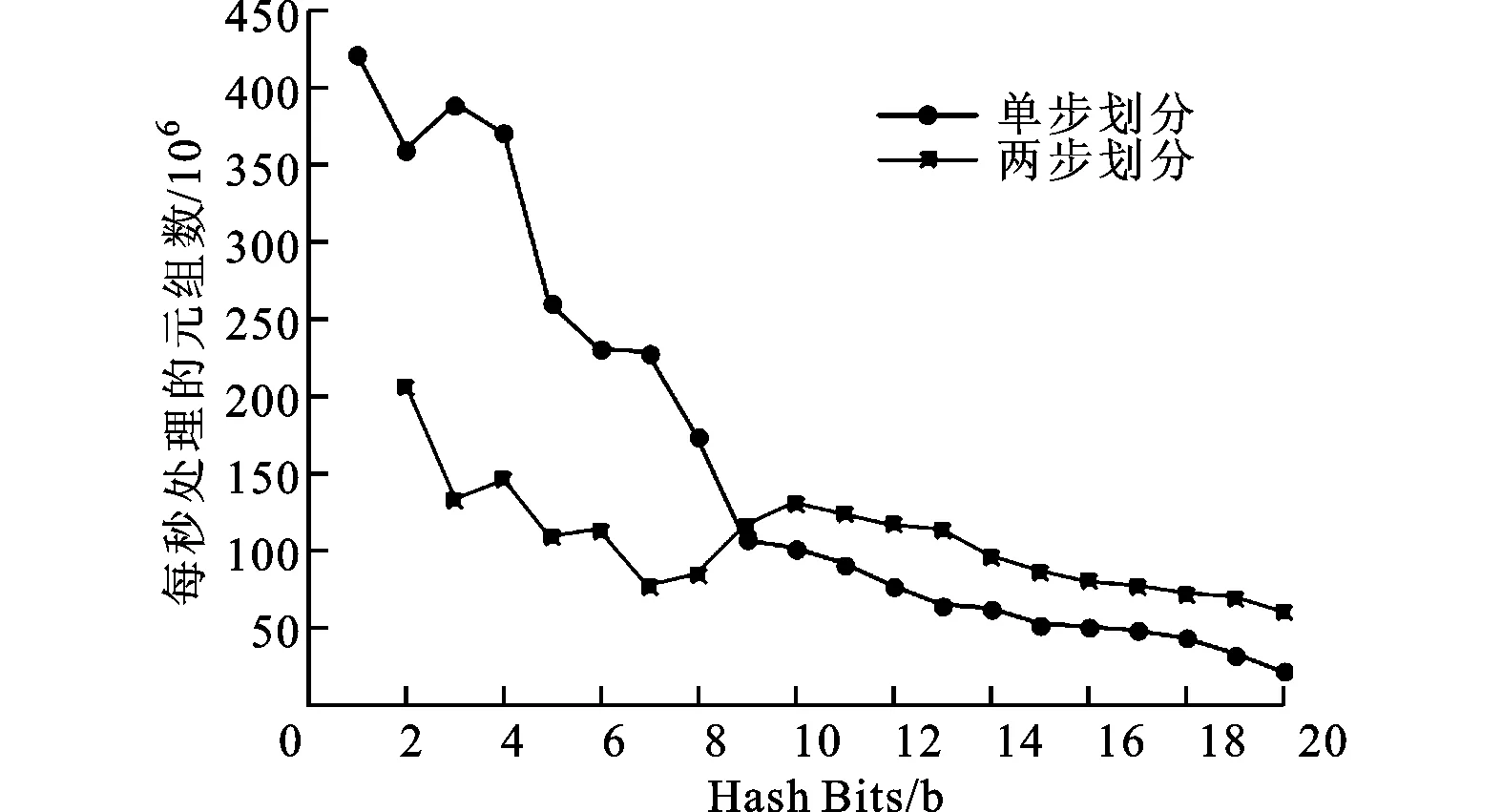
圖7 兩次遍歷策略下單步和兩步劃分的實(shí)驗(yàn)結(jié)果
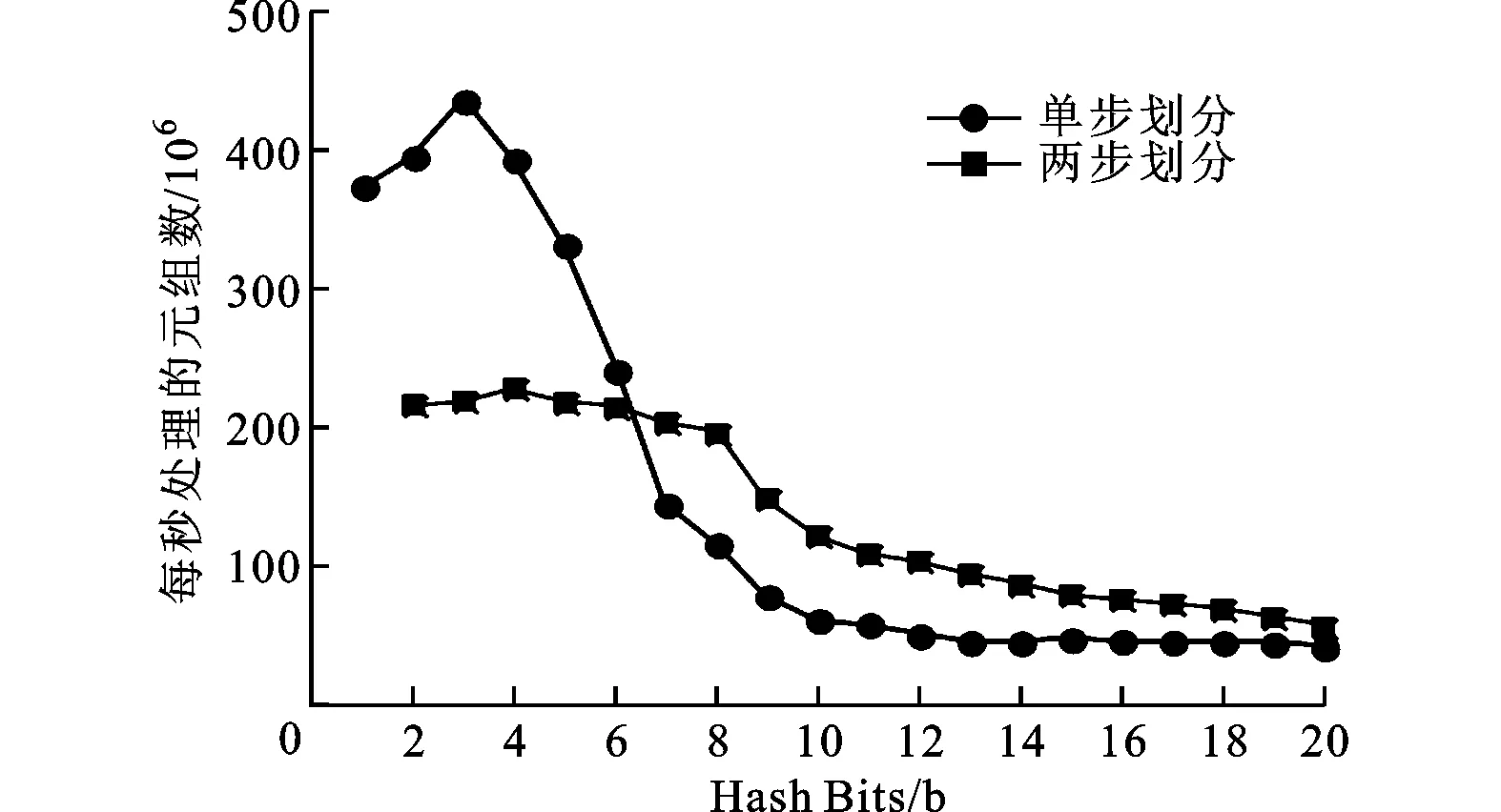
圖8 無鎖策略下的單步和兩步哈希劃分實(shí)驗(yàn)結(jié)果
4.4 數(shù)據(jù)傾斜實(shí)驗(yàn)與分析
圖9給出了兩次遍歷策略下使用數(shù)據(jù)傾斜優(yōu)化和未使用數(shù)據(jù)傾斜優(yōu)化的哈希劃分實(shí)驗(yàn)結(jié)果,該實(shí)驗(yàn)使用的是數(shù)據(jù)集B。實(shí)驗(yàn)結(jié)果表明,在多步劃分處理有傾斜的輸入數(shù)據(jù)時(shí),使用本文提出的優(yōu)化方法可明顯提高劃分性能。這是因?yàn)楸疚奶岢龅膬?yōu)化方法避免了多個(gè)空閑線程等待一個(gè)工作線程的情況,因此在處理有傾斜的輸入數(shù)據(jù)時(shí)可以有效提高整體劃分性能。
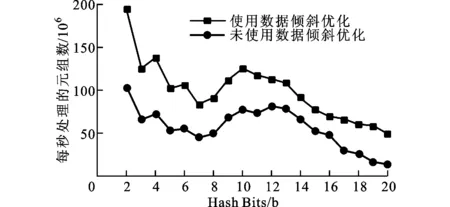
圖9 使用和未使用數(shù)據(jù)傾斜優(yōu)化的兩步劃分實(shí)驗(yàn)結(jié)果
5 結(jié) 語
本文提出了一種多核處理器中基于MapReduce的哈希劃分方法及其優(yōu)化策略。結(jié)合基于共享內(nèi)存的MapReduce模型和4種避免寫沖突的策略,本文從存儲結(jié)構(gòu)、多步劃分以及數(shù)據(jù)傾斜3個(gè)方面優(yōu)化了多核并行哈希劃分。實(shí)驗(yàn)結(jié)果表明,本文提出的方法能夠適應(yīng)多核處理器中各種分布的輸入數(shù)據(jù),并且使整體劃分性能得到提升。
[1] 鄧亞丹, 景寧, 熊偉.基于共享Cache多核處理器的Hash連接優(yōu)化 [J].軟件學(xué)報(bào), 2010, 21(6): 1220-1232.
DENG Yadan, JING Ning, XIONG Wei.Hash join query optimization based on shared-cache chip multi-processor [J].Journal of Software, 2010, 21(6): 1220-1232.
[2] YE Y, ROSS K, VESDAPUNT N.Scalable aggregation on multicore processors [C]∥Proceedings of the Seventh International Workshop on Data Management on New Hardware.New York, USA: ACM, 2011: 1-9.
[3] BALKESEN C, TEUBNER J, ALONSO G, et al.Main-memory hash join on multi-core CPUs: tuning to the underlying hardware [C]∥Proceedings of the 29th International Conference on Data Engineering.Piscataway, NJ, USA: IEEE, 2013: 362-373.
[4] MANEGOLD S, BONCZ P, KERSTEN M.Optimizing main-memory join on modern hardware [J].IEEE Transactions on Knowledge and Data Engineering, 2002, 14(4): 709-730.
[5] CIESLEWICZ J, ROSS K.Data partitioning on chip multiprocessors [C]∥Proceedings of the Fourth International Workshop on Data Management on New Hardware.New York, USA: ACM, 2008: 25-34.
[6] WU L, BARKER R, KIM M, et al.Navigating big data with high-throughput, energy-efficient data partitioning [C]∥Proceedings of the 40th Annual International Symposium on Computer Architecture.New York, USA: ACM, 2013: 249-260.
[7] DEAN J, GHEMAWAT S.MapReduce: simplified data processing on large clusters [C]∥Proceedings of the Sixth Symposium on Operating Systems Design and Implementation.Berkeley, USA: USENIX, 2004: 137-150.
[8] TALBOT J, YOO R, KOZYRAKIS C.Phoenix++: modular MapReduce for shared-memory systems [C]∥Proceedings of the Second International Workshop on MapReduce and Its Applications.New York, USA: ACM, 2011: 9-16.
[9] FANG Wenbin, HE Bingsheng, LUO Qiong, et al.Mars: accelerating MapReduce with graphics processors [J].IEEE Transactions on Parallel and Distributed Systems, 2011, 22(4): 608-620.
[10]CIESLEWICZ J, ROSS K, GIANNAKAKIS I.Parallel buffers for chip multiprocessors [C]∥Proceedings of the Third International Workshop on Data Management on New Hardware.New York, USA: ACM, 2007: 1-10.
(編輯 葛趙青)
HashPartitioningOptimizationsBasedonMapReduceforChipMultiprocessors
YUAN Tong,LIU Zhijing,LIU Hui,WANG Zi
(School of Computer Science and Technology, Xidian University, Xi’an 710071, China)
A hash partitioning method based on MapReduce framework and three efficient optimizations including storage structure optimization, multi-pass partitioning optimization and skew data optimization on chip multiprocessor (CMP) are proposed to address the problems that conventional hash partitioning method cannot take full advantage of CMP’s parallel execution resources and properly process the skew input data.The input data are split into several units which are later processed by all threads simultaneously, and suitable strategy is adopted to avoid writing collision hence CMP’s parallel execution resources could be fully unitized.The new hash table proposed in this paper can improve the overall performance by increasing the cache efficiency.The introduction of MapReduce framework makes it possible to multiply partition the data in Map phase and Reduce phase, respectively.In addition, the skew data optimization can make the proposed method suitable for processing various skew input data.Experiments have testified these advantages displayed by the proposed hash partitioning method.
data partitioning; hashing; multicore processors; MapReduce framework
2014-04-09。
袁通(1987—),男,博士生;劉志鏡(通信作者),男,教授,博士生導(dǎo)師。
國家科技支撐計(jì)劃資助項(xiàng)目(2012BAH01B05);陜西省科技統(tǒng)籌創(chuàng)新工程計(jì)劃資助項(xiàng)目(2012KTZD-02-05-2)
時(shí)間:2014-09-02
10.7652/xjtuxb201411017
TP392
:A
:0253-987X(2014)11-0097-06
網(wǎng)絡(luò)出版地址:http:∥www.cnki.net/kcms/detail/61.1069.T.20140909.0908.004.html
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
房地產(chǎn)導(dǎo)刊(2022年5期)2022-06-01 06:20:14
建材發(fā)展導(dǎo)向(2021年12期)2021-07-22 08:06:48
建材發(fā)展導(dǎo)向(2021年7期)2021-07-16 07:07:52
中學(xué)生數(shù)理化(高中版.高二數(shù)學(xué))(2021年12期)2021-04-26 07:43:48
中學(xué)生數(shù)理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50
小學(xué)生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
數(shù)學(xué)大世界(2018年1期)2018-04-12 05:39:14
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
