健康問題和醫生匹配機制的研究
2014-08-07 12:18:53朱利岳愛珍
西安交通大學學報 2014年12期
朱利,岳愛珍
(西安交通大學軟件學院, 710049, 西安)
健康問題和醫生匹配機制的研究
朱利,岳愛珍
(西安交通大學軟件學院, 710049, 西安)
針對醫療社區問答系統中的健康問題,提出了一種新的問題回答者推薦機制,以提高問題解決的效率。該機制引入了醫生回答問題的態度,將問題-醫生的專業匹配程度和醫生回答問題的態度關聯起來一同考慮;使用概率超圖和查詢似然語言模型對問題-醫生的專業匹配進行建模,利用歷史數據對醫生的態度進行建模;使用回歸模型對問題-醫生的專業匹配和態度進行自適應權衡。進行了大量基于真實數據集的實驗對所提出的機制進行了驗證。實驗結果表明:與常用的方法相比,本文所提出的機制準確度能提高30%;很大程度上提高了問題解決的效率。
醫療社區問答系統;問題推薦;概率超圖;態度建模
隨著信息技術和互聯網的發展,醫療社區問答系統作為一種健康知識交流和分享的有效平臺開始出現,例如HealthTap、HaoDF和39健康網等。醫療社區問答系統不僅允許咨詢者免費咨詢健康問題,而且鼓勵醫生提供可靠的答案,同時也為健康咨詢者提供相似問題的檢索。
醫療社區問答系統中,問題的增長速度通常比醫生的增長速度快得多。一方面,健康咨詢者不得不長時間等待醫生的回答,等待數小時甚至數天;另一方面,醫生往往會淹沒在海量的問題中。因此,健康咨詢者和醫生之間存在一個日漸變寬的鴻溝,急需一個高效的“問題-醫生”映射機制來彌補這個鴻溝。
已有的問題回答者推薦研究可以分為兩類:全局專家發現方法和主題級專家發現方法。前者是在特定論壇使用來自帖子和回復的鏈接來衡量專家的權威度[1]。例如Bouguessa等提出使用入度(最優答案數目)來找專家[2];基于鏈接的HITS算法比入度算法性能要高[3]。除了HITS算法外,另外一個基于鏈接的PageRank算法在社交媒體中也取得了很大的成功[4]。全局專家發現方法只能找到特定論壇的專家,沒有考慮問題內容和專家的專業是否匹配;主題級的專家發現方法則在更細粒度上考慮了問題敏感的專業匹配問題。Zhou等在文獻[5]中提出了基于專業的在線論壇問題推薦。Li等在文獻[6]中深入研究了分類敏感的語言模型。除了專業估算外,在文獻[7]中提出了考慮專家是否在線問題的基于語言模型的框架。主題級專家發現方法雖然可以根據問題的內容找到相應領域的專家,但不能獲取專業能力與問題的匹配程度。更重要的是,目前尚未發現考慮專家態度問題的研究。為此,我們提出了一種針對醫療社區問答系統中醫生推薦的機制QDM(question-doctor mapping),同時考慮了問題和醫生的專業匹配以及醫生的態度,能夠準確地解決“健康問題醫生”之間的映射問題,提高了問題解答的效率。機制主要由3部分組成:①問題和醫生的專業匹配建模;②醫生的態度建模;③問題-醫生的專業匹配和醫生態度的自適應權衡。其中,①用來表示醫生對問題的專業程度,②用來表示醫生回答問題的態度。對于不同的問題,對醫生的專業和態度有不同的傾向。因此,③用來自適應地權衡問題-醫生專業匹配和醫生態度的重要性。
1 問題和醫生的專業匹配建模
使用D={d1,d2,d3,…,dn}表示n個醫生集合,di表示一個醫生。每個醫生的信息包括兩部分:醫生的信息簡介和醫生回答過的問題答案對。簡介部分包括醫生的教育背景、出版物、獎勵以及來自其他醫生和健康咨詢者的投票等信息。問題答案對包括問題、答案、和答案相關的標簽以及其他醫生對答案的贊同情況。我們將醫生回答過的問題答案對看作其積累的經驗。
使用E(di,q)表示醫生di對問題q的專業程度。受文檔主題生成模型(latent dirichlet allocation, LDA)的啟發,我們認為每個醫生的專業知識是綜合的,呈現加權分布特征。每種專業被解釋為可以使用相同專業知識回答的問題集合。因此,可以得到醫生和所給問題的相關程度為
(1)
式中:p(εj|di)表示醫生di在專業εj上的專業程度,即醫生-專業分布,而p(q|εj)表示問題q需要專業εj解決的概率,即專業-問題分布。
1.1 醫生-專業分布
通過對HealthTap上的3 000多個醫生的簡介進行分析,發現每個醫生平均有3.4個專業技能。因此,p(εj|di)的計算就可以看作是在醫生集合D上的模糊專業聚類。不像傳統的硬聚類,每個醫生只屬于一個集合。在這里,醫生可根據相應概率p(εj|di)屬于多個集合。
目前存在多種計算p(εj|di)的聚類技術,例如K均值、LDA和基于簡單圖[8]的聚類,可是這些方法都存在一些約束。首先,這些方法通常假設所感興趣的物體之間的關系成對存在。在我們研究的工作中,醫生之間的關系比成對關系更復雜,如果簡單地將這種復雜關系轉換成成對關系將會導致我們想要了解的信息丟失。其次,它們不能處理異構信息。在醫療社區問答系統中,醫生通常同時擁有幾種關系,例如醫生間的社交關聯、相似的簡介和經驗等。為了解決這些問題,我們構建概率超圖,然后在超圖上進行模糊劃分。超圖允許超邊連接兩個及以上的頂點。同時,不同類型的超邊可以表示不同的異構關系。
超圖(V,E,W)由頂點集合V、超邊集合E和超邊的權重集合W組成。每條超邊e連接兩個或兩個以上的頂點,且e都分配一個權值w(e)。在所研究的問題中,醫生集合D中的n個醫生被看作n個頂點。根據醫生的信息,可以構建3種類型的超邊。對于第一種類型的超邊,每個醫生作為一個頂點,該醫生和與他簡介相似度最高的k個醫生組成一條超邊。這種構建超邊的方式在文獻[9]中第1次被采用。第1種類型的超邊集合定義為E1。第2種類型的超邊是基于醫生積累的經驗。對于每個醫生,將他回答過的所有問題答案對合并成一個文檔,使用這個文檔來表示該醫生積累的經驗。將具有相同積累經驗的醫生構建成一條超邊,這種超邊集合定義為E2。第3種類型的超邊利用了醫生之間的社交關系。對于超圖中的每個醫生,將該醫生和與他回答過相同問題的醫生組成一條超邊,這種超邊集合定義為E3。
概率超圖G可以被表示為|V|×|E|的關聯矩陣H,H中的元素為

(2)
式中:p(di,ej)是超邊ej連接頂點di的概率。p(di,ej)的定義為

(3)
式中:dej是超邊ej連接的醫生;S(di,dej)是醫生di和醫生dej簡介(第1類超邊)或積累的經驗(第2類超邊)的相似度。
超邊的權重大小表示超邊中的頂點屬于同一組的可能程度。對于一條超邊,它的權重定義為
(4)
式中:di∈ej表示超邊ej連接頂點di。
對于每條超邊,它的度定義和權重相同
(5)
根據H的定義,頂點di的度為
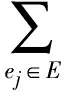
(6)
在本文中,利用了一種高效且實現簡單的算法[10]來劃分超圖,但是與算法中的超圖不同,我們構建的超圖是一個概率模型。在構建的超圖上定義了正則項
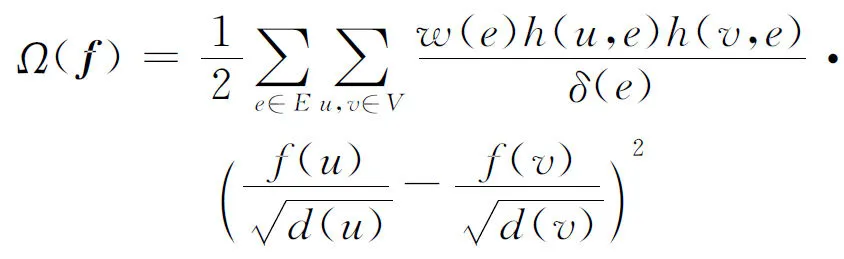
(7)
式中:矩陣f∈RD包含了每個醫生和想要學習的、潛在的專業類別相關概率。通過定義,可得

(8)
式中:I是單位矩陣。定義Δ=I-Θ,Δ是一個半正定矩陣,即超圖的拉普拉斯算子[10]。Ω(f)可被重新寫為
(9)
1.2 專業-問題分布
p(q|εj)=p(q|qεj)
(10)
(11)
根據Jelinek-Mercer平滑法得
P(w|qεj)=(1-α)P(w|qεj)+αP(w|C)
(12)
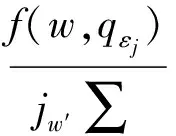
(13)
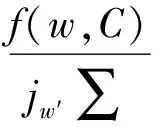
(14)
式中:C是所有的問題集合;α是一個調整平滑權重的加權系數;f(w,qεj)表示項w在專業εj的問題集合qεj中出現的頻率;f(w,C)表示項w在所有問題集合C中出現的頻率。根據經驗值,設置α=0.8。至此,可以得到每個醫生和給定問題的專業相關程度E(di,q)。
2 醫生態度建模
除了問題和醫生的專業匹配外,根據文獻[12]中的研究,我們假設問題答案的質量也取決于醫生的態度。根據醫療問題回答系統中的可用信息,本文從積極性、責任感和聲譽3個不同的角度對醫生的態度進行建模。這些都需要使用歷史數據進行估算,它們的乘積表示醫生的態度。
積極性可用來測量問題出現時醫生的積極程度。積極性的定義為
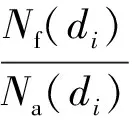
(15)
式中:Nf(di)表示醫生di是第1個問題回答者的問題數目;Na(di)表示醫生di回答的問題數目;A(di)表示醫生di回答問題的積極性,A(di)越大,醫生di回答問題的時間就越短。
責任感用來測量醫生對給定問題回答的滿意程度,它直接反映在答案質量上。我們認為如果一個醫生di回答了問題q,則di有相應的專業能力解決q。同時,如果提供的答案被其他醫生選為最優答案,我們認為醫生di對該答案有責任。di的責任感的估算為
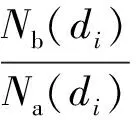
(16)
式中:Nb(di)表示醫生di提供的答案被選為最優答案的數目。
醫生的聲譽是指其他醫生和健康咨詢者對這個醫生的看法或想法。本文使用取值范圍在0~1之間的Sigmoid函數來估算名聲。
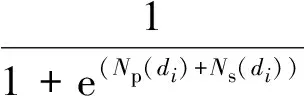
(17)
式中:Np(di)和Ns(di)分別表示支持醫生di的醫生和健康咨詢者的數目。
3 專業匹配和態度自適應權衡
對于一個新的用自然語言描述的問題q,我們的目標是從D中選擇出一些匹配的醫生,并且將q推薦給這些醫生。匹配分數為
S(di,q)=(1-λ)E(di,q)+λA(di)
(18)
式中:E(di,q)是問題和醫生的專業匹配模型,表示從專業的角度考慮醫生di可以回答問題q的可能性。A(di)是態度模型,可以從歷史行為中推測出來。另外,λ是一個自適應的參數,用來平衡專業和態度的影響。
根據觀察,不同的問題對專業和態度有不同的傾向。對于簡單問題,入門級醫生就可以回答。這種問題答案的質量主要由醫生的態度決定而不是醫生的專業知識。對于高難度問題,需要根據病人癥狀找出發病的原因以及告訴病人應該如何做,此時醫生的專業知識對于給出高質量回答起到了主要作用。因此可以得出結論,參數λ是一個關于給定問題的自適應函數,它平衡專業和態度對答案質量的重要性。當λ=1時,給定的問題將被推薦給態度最好的醫生,而他們的專業能力將被忽視。相反,如果λ=0,將不考慮醫生的態度問題。
將λ的自適應估計任務看作監督回歸問題,其目標是根據類似訓練問題的有效權重,為每個新的問題預測一個合適的權重。對于訓練集中的每個問題,首先使用固定的λ來估算問題推薦的性能。λ的最優值通過在[0,1]之間使用固定步長得到。利用這些最優值作為真實值來訓練回歸模型。在實驗中,使用了線性回歸、保序回歸和pace回歸等不同的回歸模型。
4 實 驗
4.1 實驗設置
在實驗中使用了從HealthTap上收集的3 123個醫生的簡歷。每個醫生的簡歷包括醫生的簡介和該醫生以前回答過的問題答案對。表1展示了我們統計的實驗數據。
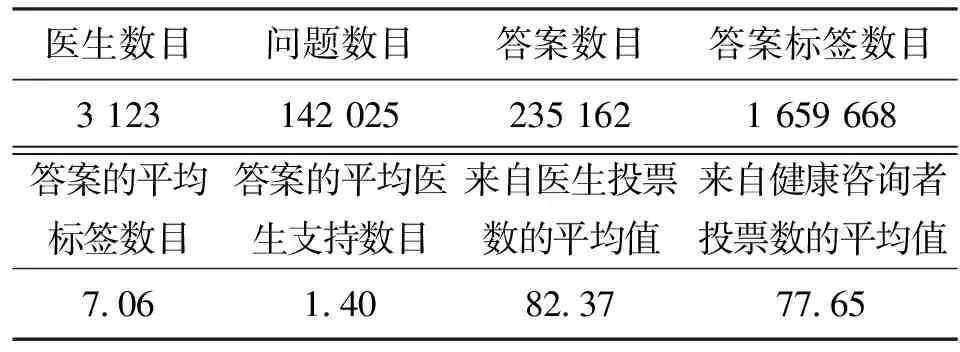
表1 收集到的數據的統計
本文使用了基于LDA的主題級別的數據表示。對于一個數據集,LDA按照語義將內部相關聯的健康概念分配到一個潛在的組,它可以按照主題描述健康數據的底層語義結構。每個潛在組被視為一維特征。特征空間維度通過困惑度(perplexity)[10]得到。困惑度是一種計算統計模型,設為
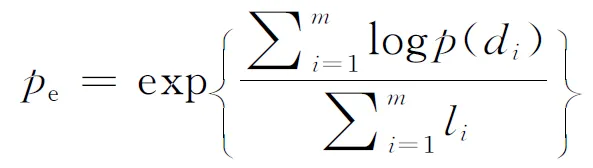
(19)
式中:li表示di的詞數。困惑度的值越小表示所用的LDA模型越好。我們將醫生的簡歷分為兩部分,80%的數據用來訓練LDA模型,20%用來評估性能。LDA建模和困惑度矩陣通過Stanford建模工具集來實現。當潛在組的組數變化時,困惑度取值如圖1所示。由圖1可知,當潛在組數為110時,困惑度最低。因此,對于給定的一個醫生或者問題,它可以表示成110個語義主題級別特征的混合。
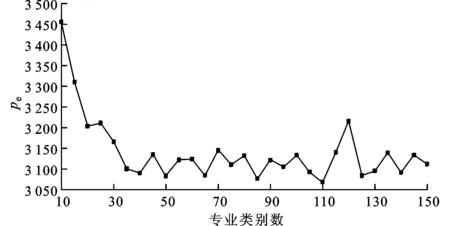
圖1 困惑度隨專業類別數變化曲線
對于隨后的主觀評價,我們邀請了3個來自不同背景的自愿者并進行了訓練。在3個志愿者中采用多數表決方案來解決有分歧的問題。對于那些有兩類選票數相同的情況,通過討論來獲得最后的決定。
4.2 問題推薦性能比較
對于專家推薦問題,準確度是最重要的性能指標。因此,采用了客觀評估和主觀評估兩種指標從不同的方面獲取準確度。從數據集中隨機選擇了1000個問題作為測試樣本。對于客觀評估,采用了平均的H@K[13]。如果真正回答該問題的醫生排在前K位,則認為H@K=1,否則H@K=0。這種評估方法的優點是使用了真實數據且不需要構建其他的真實值。可是這種評估方法可能受這種場景的影響,醫生di回復了問題q,盡管醫生dj有能力回答問題q,但由于未知的原因沒有回答問題。盡管本文提出的機制很可能將dj排在一個高的位置,但是H@K卻忽略了。因此,H@K不能全面公平地評估本文提出的推薦機制。
作為對H@K的補充,采用了主觀的指標S@K,來測量在推薦的K個醫生中能找到一個匹配的醫生回答問題的概率,即如果推薦的前K個醫生中有能力回答該問題,則S@K=1,否則S@K=0。不同于主觀評估,此時的真實值需要志愿者手動構建。他們需要查看醫生的簡介和歷史數據,如果認為某個醫生有能力并且有可能回答這個問題,將標記該醫生有能力回答該問題,否則標記不能回答該問題。本文中使用Kappa分析[14]來評估志愿者間的一致性。Kappa的值在0~1之間,值越大,一致性越高。Kappa值大于0.7表示一致性很強。在本文的工作中,采用了在線的Kappa計算工具。表2展現了分析結果,結果證明它能標記志愿者之間的一致性。
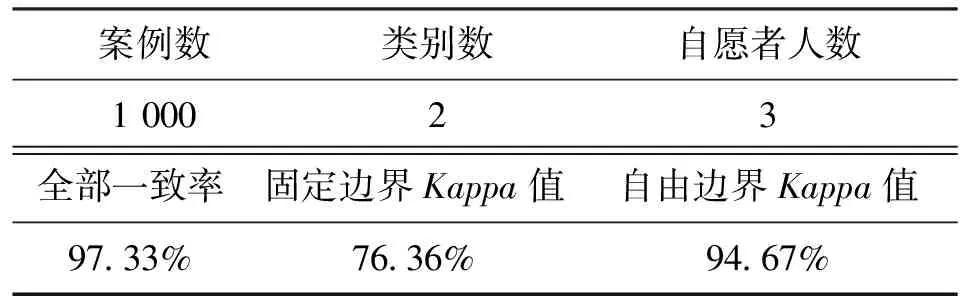
表2 使用Kappa方法的志愿者之間的一致性評估
我們將本文提出的問題推薦機制與最新技術進行了比較。為了確保公平,它們將同時考慮或不考慮態度問題。
K均值為醫生-專業相關程度使用K均值估算的機制。LDA為醫生-專業相關程度使用LDA估算的機制。
由于K均值的結果是離散的,只能得到一個醫生是否屬于某個專業類別,而得不到該醫生屬于某個專業類別的概率。為了得到醫生屬于某個專業類別的概率,本文使用下式計算

(20)
式中:半徑參數σ是所有醫生對之間的歐氏距離的均值,cj是專業類別εj的中心。
圖2和圖4分別列出了使用H@K和S@K來評估推薦性能的對比結果。當引入醫生的態度時,結果在圖3和圖5中給出。由圖可見,本文方法的性能明顯高于其他方法。綜合分析這4個圖可以看出,考慮醫生態度時的性能要高于不考慮醫生態度時的性能,這證明了醫生的態度確實影響答案的質量。另一方面,實驗結果也證明使用自適應的λ來平衡專業匹配和態度的影響比使用固定λ的要優越。
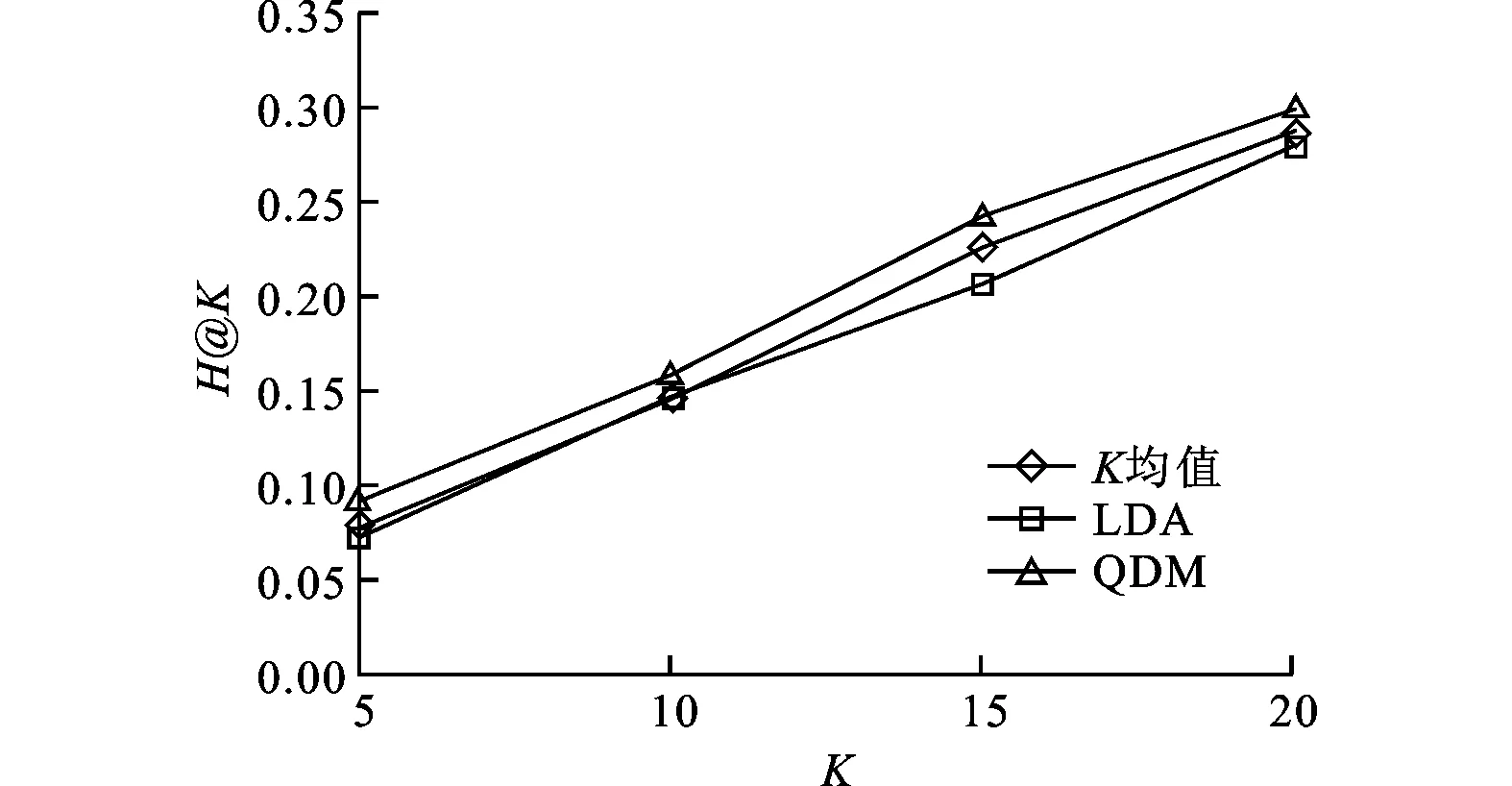
圖2 不考慮醫生態度時使用H@K評估的性能比較
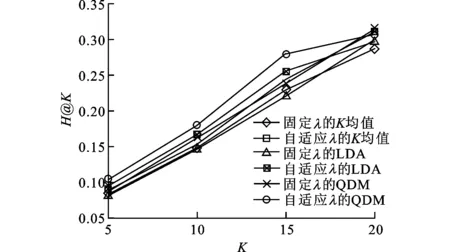
圖3 考慮醫生態度時使用H@K評估的性能比較
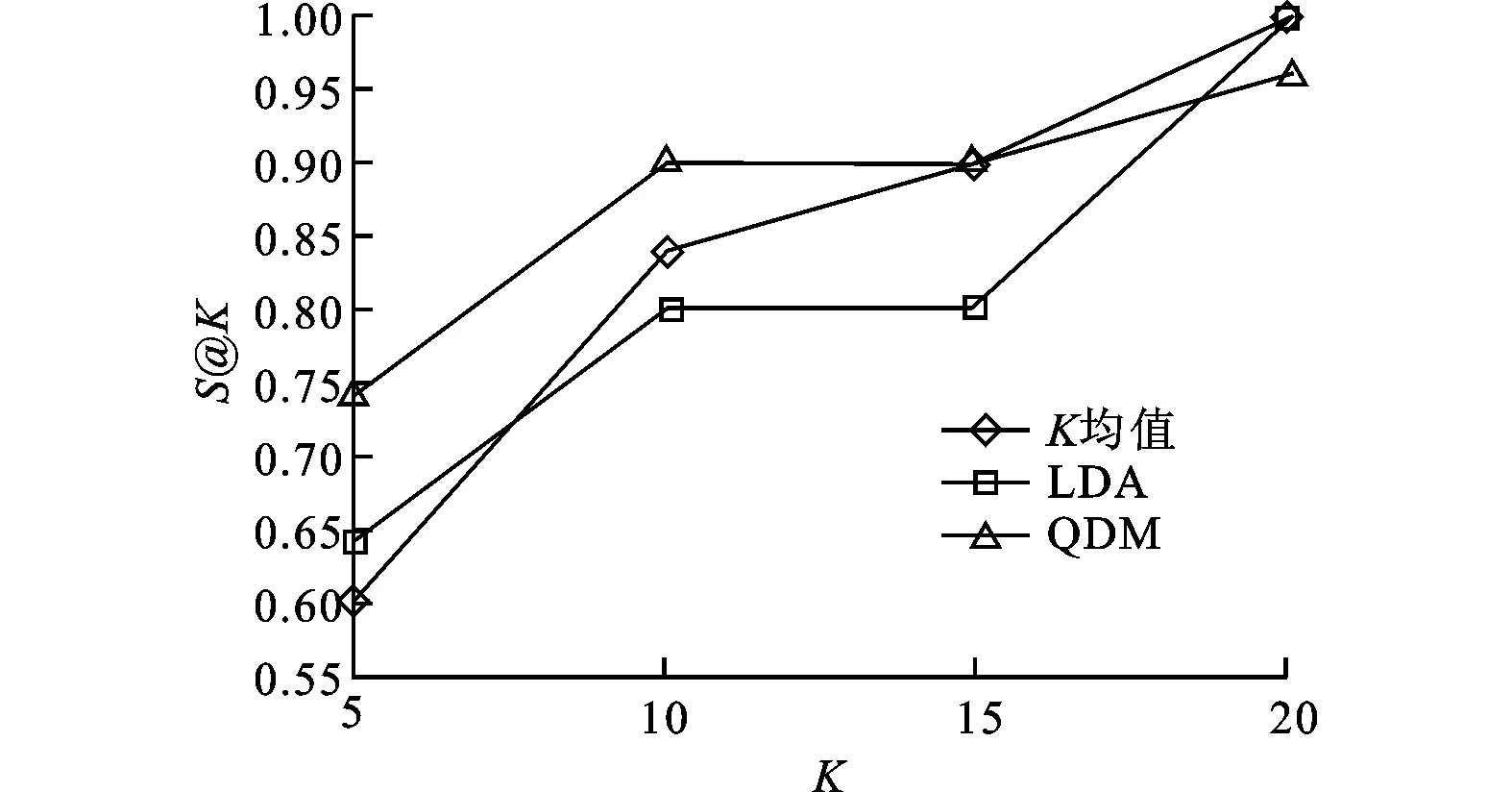
圖4 不考慮醫生態度時使用S@K評估的性能比較
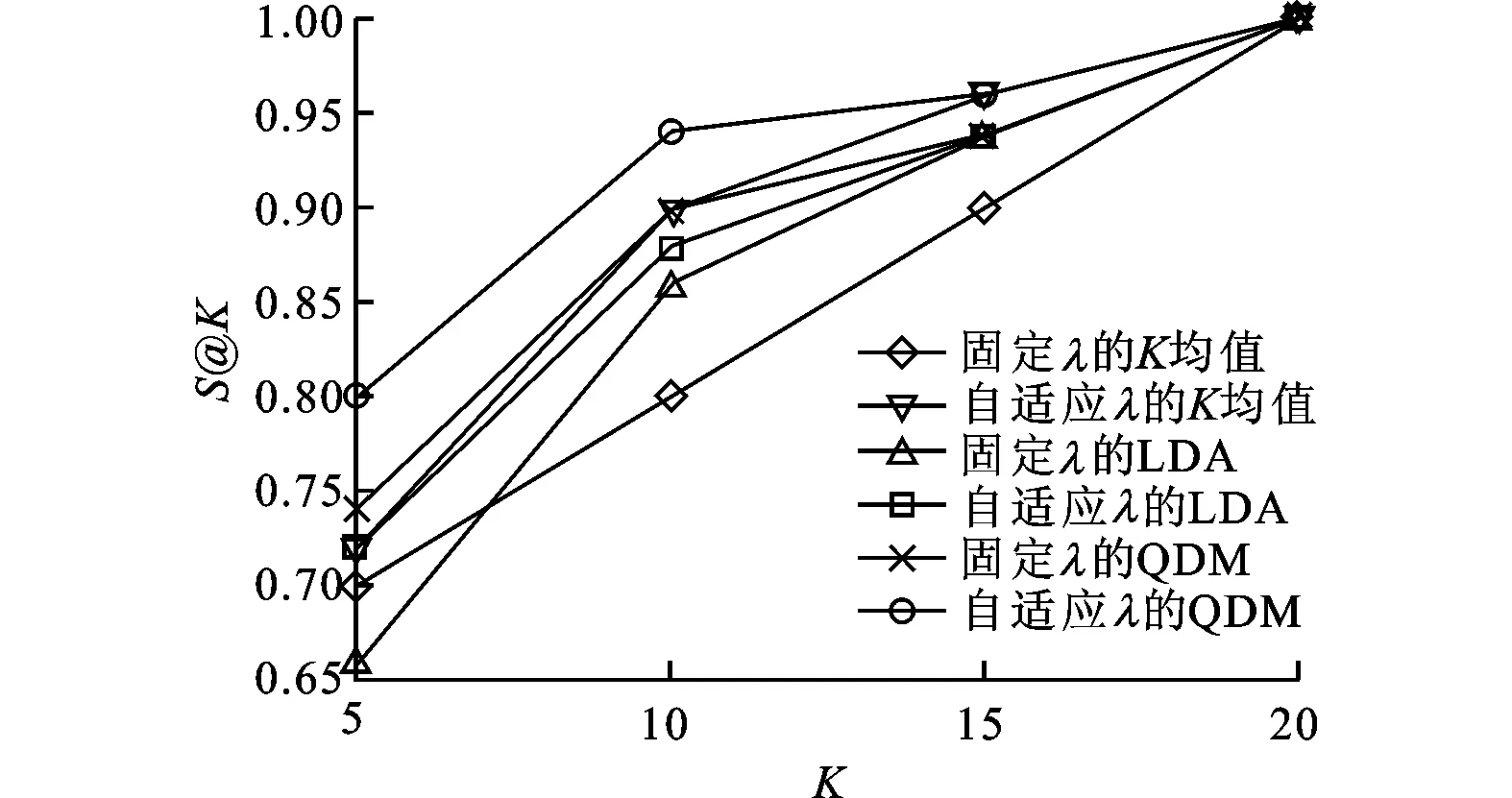
圖5 考慮醫生態度時使用S@K評估的性能比較
4.3 專業和態度權衡
從數據集中隨機選擇了1000個問題。對于每個問題,使用固定步長0.05在[0,1]之間找到了最優性能。為了節省時間,性能通過H@K測量。這些問題分為兩部分,80%用來訓練,20%用來測試。我們采用了4種回歸模型,它們的性能比較見表3。可以看出,pace回歸模型取得了最好的性能。對于一個新問題,它的自適應參數λ是可預測的,這個值影響到問題需要對醫生的專業更關注還是對態度更關注。

表3 使用平均絕對誤差回歸模型的性能比較
5 結 語
本文研究的醫療社區中的問題推薦方法包含3個主要步驟:①對醫生和問題的專業匹配度進行建模;②從積極性、責任感和名聲3個角度對醫生的態度進行建模;③根據問題的內容自適應地權衡問題和醫生的專業匹配和醫生態度的影響。實驗證明,本文提出的“健康問題-醫生”推薦機制具有很高的準確度和問題回答效率,可實際應用于網上醫療社區中,能夠彌補目前這個應用方面的空白。
由于目前很難獲得中文的問題集,本文的方法和實驗都是針對英文問題集的。后面我們將通過技術方法收集中文數據集,來驗證本文提出機制的通用性,并嘗試將該機制應用到其他領域。
[1] JURCZYK P, AGICHTEIN E. Discovering authorities in question answer communities by using link analysis [C]∥Proceedings of the 16th ACM Conference on Information and Knowledge Management. New York, USA: ACM, 2007: 919-922.
[2] MOHAMED B, BENOIT D, WANG Shengrui. Identifying authoritative actors in question-answering forums: the case of yahoo! answers [C]∥Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York, USA: ACM, 2008: 866-874.
[3] KLEINBERG J M. Authoritative sources in a hyperlinked environment [J]. Journal of the ACM, 1999, 46(5): 604-632.
[4] ZHOU Guangyou, LAI Siwei, LIU Kang, et al. Topic-sensitive probabilistic model for expert finding in question answer communities [C]∥Proceedings of the 21st ACM International Conference on Information and Knowledge Management. New York, USA: ACM, 2012: 1662-1666.
[5] ZHOU Yanhong, CONG Gao, CUI Bin, et al. Routing questions to the right users in online communities [C]∥Proceedings of the 25th IEEE International Conference on Data Engineering. Piscataway, NJ, USA: IEEE, 2009: 700-711.
[6] LI Baichuan, KING I, LYU M R. Question routing in community question answering: putting category in its place [C]∥Proceedings of the 20th ACM International Conference on Information and Knowledge Management. New York, USA: ACM, 2011: 2041-2044.
[7] LI Baichuan, KING I. Routing questions to appropriate answerers in community question answering services [C]∥Proceedings of the 19th ACM International Conference on Information and Knowledge Management. New York, USA: ACM, 2010: 2041-2044.
[8] 蘇金樹, 張博鋒, 徐昕. 基于機器學習的文本分類技術研究進展 [J]. 軟件學報, 2006, 17(9): 1848-1859. SU Jinshu, ZHANG Bofeng, XU Xin. Advances in machine learning based text categorization [J]. Journal of Software, 2006, 17(9): 1848-1859.
[9] HUANG Yuchi, LIU Qingshan, ZHANG Shaoting, et al. Image retrieval via probabilistic hypergraph ranking [C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE, 2010: 3376-3383.
[10]HUANG Yuchi, LIU Qingshan, LV Fengjun, et al. Unsupervised image categorization by hypergraph partition [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(6): 1266-1273.
[11]ZHAI Chengxiang, LAFFERTY J. A study of smoothing methods for language models applied to information retrieval [J]. ACM Transactions on Information Systems, 2004, 22(2): 179-214.
[12]GUAGNANO G A, STERN P C, DIETZ T. Influences on attitude-behavior relationships [J]. Journal of Environment and Behavior, 1995, 27(5): 699-718.
[13]XUAN Huiming, YANG Yujiu, PENG Chen. An expert finding model based on topic clustering and link analysis in CQA website [J]. Journal of Network and Information Security, 2013, 4(2): 165-176.
[14]WARRENS M J. Inequalities between multi-rater kappas [J]. Advances in Data Analysis and Classification, 2010, 4(4): 271-286.
[15]NIE Liqiang, YAN Shuicheng, WANG Meng, et al. Harvesting visual concepts for image search with complex queries [C]∥Proceedings of the ACM International Conference on Multimedia. New York, USA: ACM, 2012: 59-68.
(編輯 武紅江)
RoutingHealth-OrientedQuestionstoAppropriateDoctors
ZHU Li,YUE Aizhen
(School of Software Engineering, Xi’an Jiaotong University, Xi’an 710049, China)
A novel mechanism connecting health seekers to appropriate doctors is proposed to improve the efficiency of question resolving in community-based health service systems. Attitudes of doctors answering questions are introduced in the mechanism, and both the professional matching degree between doctors and questions and the doctor’s attitudes are associated and considered at the same time. The probabilistic hypergraph and the query likelihood language model are used to model the professional matching degree, and a doctor’s attitude is modeled from his historical data. Meanwhile, a regression model is used to trade off between the professional matching degree and the doctor’s attitude. Extensive experimental results on several real-world datasets show that the matching precision of the proposed mechanism increases by about 30%, and the efficiency of resolving problems is greatly improved.
community-based health service system; question routing; probabilistic hypergraph; attitude modeling
2014-5-20。
朱利(1968—),男,副教授。
國家重點基礎研究發展規劃資助項目(2012CB327902HZ)。
時間:2014-10-31
10.7652/xjtuxb201412009
TP181
:A
:0253-987X(2014)12-0057-06
網絡出版地址:http:∥www.cnki.net/kcms/detail/61.1069.T.20141031.1643.017.html
