基于GIS的紅松籽物流集散點選址研究
——以吉林省汪清林區為例
2014-08-23 03:38:22閆慧凝邢艷秋孫術發劉勁風李慧子尤號田
森林工程 2014年4期
閆慧凝,邢艷秋*,孫術發,劉勁風,李慧子,尤號田
原始紅松林(PinuskoraiensisSieb.etZucc.)是長白山生態系統的頂級群落,具有極其珍貴的經濟價值和生態價值。作為紅松果實的紅松籽主要生長于樹齡70~130 a的紅松上,生長周期約15個月,具有重要的食用保健價值,業已成為長白山等紅松籽主產區主要經營管理對象[1]。目前,越來越多的研究集中在紅松籽采摘和深加工方面,但是,對于其物流集散點的研究卻未見報道。研究紅松籽物流集散點選址,直接影響了整個紅松籽物流系統的運行效率[2-5]。
因此,本文以吉林省汪清林區為研究區研究紅松籽物流集散點選址問題。結合GIS空間分析功能從自然因素、環境因素、地形因素等方面分析,選取出若干區域作為備選地,建立基于混合整數規劃法的經濟模型和影響因素輔助模型優化選址,確定選地。最后,用模糊數學理論計算各個選地與理想目標的貼近度,評價選址的優劣,根據實際情況確定選址地點。
1 數據收集
根據紅松籽的物質特性,本研究選取產品來源(采摘區)、人文環境(居民區)、基礎設施(道路交通條件)、自然環境(河流)和地形(地面坡度)等5個要素作為紅松籽物流集散地選址的影響因素。其主要數據來源于研究區小班數據、居民區分布圖、道路專題圖、河流專題圖、數字高程圖(Digital Elevation Model,DEM)。這些數據采用統一的地圖投影及坐標系(WGS-84)。
本文將考慮到影響選址的因素眾多,要進行重要性排序,在研究中采用了問卷調查的形式,對相關從業人員進行問卷調查分析,對道路交通條件、采摘區、居民區、河流和地面坡度對紅松籽物流集散點選址的影響程度打分。在處理過程中,按非常重要、重要、一般重要、不重要、很不重要分別賦予5 分、4 分、3 分、2 分、1 分。再通過數據分析與層次分析法統計出因子的權重,將所得的權重代入計算模型,得到影響選址因素的權重見表1。

表1 影響因素權重表
2 集散點位置確定
2.1 初始位置選定
2.1.1 影響因素數據提取
(1)采摘區提取。本文選擇小班數據中樹種組成50%以上為紅松林的地區作為紅松籽的采摘區。在ArcGIS平臺下對小班數據圖層屬性中的樹種組成進行篩選,獲取本文所需的采摘區分布如圖1所示。
(2)坡度提取。研究區域海拔為360~1477 m,研究區域范圍內地形坡度在0°~88.6°。由于設定運材線路所走坡度要求在10°以下,因此,將坡度圖按照坡度屬性值分為0°~10°和>10°兩類,坡度分類圖如圖1所示。
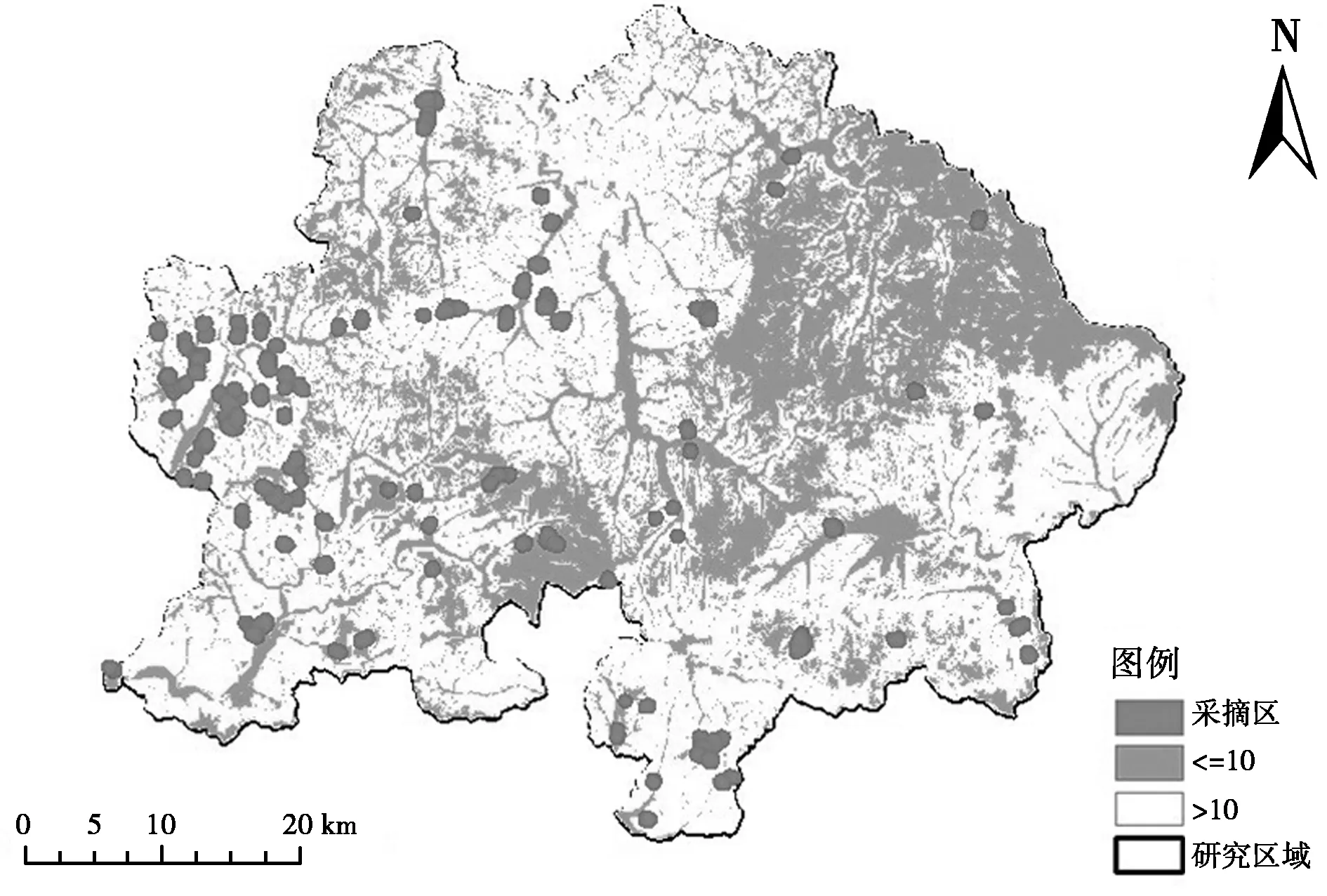
圖1 數據提取圖
2.1.2 初選位置
本文為獲得紅松籽物流的初選位置主要用到了緩沖區分析以及疊置分析:在Arcgis平臺下分別對各個矢量圖層建立緩沖區,緩沖區分析是不破壞原有空間目標的關系,只是檢索得到該緩沖區范圍內涉及到的空間目標并建立新的圖層;疊置分析是疊加并累計超過兩層的地圖要素,生成新的要素層。將采摘區緩沖區、居民區緩沖區、道路緩沖區、地形坡度≤10°的地區疊置分析,并擦除河流緩沖區。用畫圖工具繪制出疊加得到的32個可選點,形成初選地位置圖如圖2所示。
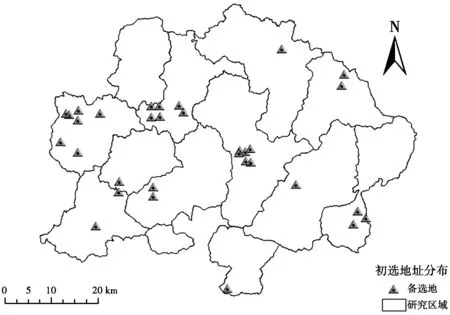
圖2 初選地位置圖
2.2 集散點位置確定
2.2.1 優化模型建立
在獲得初選位置后建立優化模型對初選地優化。目前,CFLP法、重心法、運輸規劃法、混合0-l整數規劃法、Baumol-Wolfe法等都是常用的定量分析方法[6-10]。通過對比物流中心選址方法中常用方法,混合整數規劃法模型所得到的解更準確,考慮因素更加全面。根據紅松籽物流集散點選址的實際情況考慮了固定費用與可變費用,所以在混合整數規劃法模型基礎上增加了備選地吞吐能力、可興建的備選地最大數目和集散點年均固定費用三項要素。并且現在所研究的選址問題基本都只局限于考慮經濟因素,那么本文建立混合整數規劃法的經濟模型外還建立了影響因素的輔助模型。
(1)經濟模型(混合整數規劃法模型)。
目標函數:
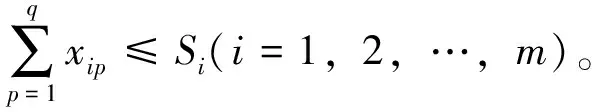
xip,ypj≥0。
(1)
式中:c表示運輸成本,l表示運輸距離,x、y表示運輸量,g表示運輸單價,F表示集散點年均固定費用,S備選地紅松籽容量,Q備選地最大吞吐能力,d表示紅松籽需求量,M表示可興建的備選地最大數目。
(2)影響因素輔助模型。
maxF=(L1)·a+(L2)·b+…+(L5)·e。
(2)
式中:L1,L2,…,L5分別表示5個影響因素,a,b,…,e表示各個影響因素所對應的權重。
2.2.2 集散點確定
基于圖2得到的32個初選位置,將表1中的影響因素及權重應用于輔助模型公式(2)中,通過經濟模型公式(1)的運算,得出了紅松籽物流集散點的最終選址21個。如圖3所示。
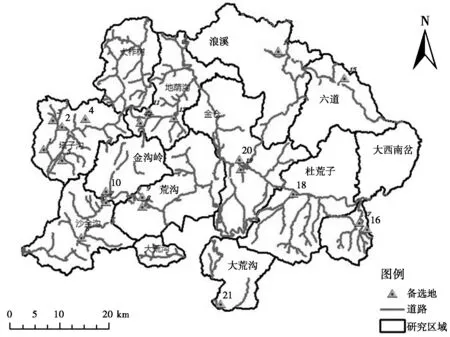
圖3 紅松籽物流集散點選址分布
集散點位置的選擇基本輻射所有采摘區,并且集散點的選址在鐵路或者公路附近,符合經濟性原則。從圖上生成的集散點選址可以得到該地點的一切屬性,例如:該地的坡度情況、海拔高度、附近的采摘區和居民區等等。這一結果證明本文的研究方法科學可靠,能夠應用于紅松籽物流集散點選址,并可以為類似的科學研究提供理論依據。
3 選址結果評價
3.1 評價模型建立
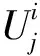
假設模糊集表示為F,集合F包括所有備選地址。要首先確定其隸屬函數,才能計算兩個模糊集F的貼近度。用N(A,B)表示兩個模糊集F的貼近度。可以按照下列公式定義隸屬函數:
(3)
a=minU(j)b=maxU(j)。
(4)
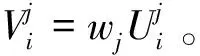
(5)
建立理想目標I,將最佳的指標值從備選地址中選擇出來。σ(Vi,I)表示理想目標I與備選地址Vi的貼近度。
貼近度可以用下列公式進行計算:
(6)
3.2 評價結果
為了方便計算,地形坡度按0~3度、3~7度、7~10度分別賦值為3、2、1;河流按500、1 000、1 500 m的多環緩沖區分別賦分值1、2、3,其它3個影響因素按500、1 000、1 500 m分別賦分值3、2、1。以塔子溝林場為例進行數據分析計算,塔子溝林場各備選地址如圖4所示,有標注1、2、3、4、5五個地址分布。
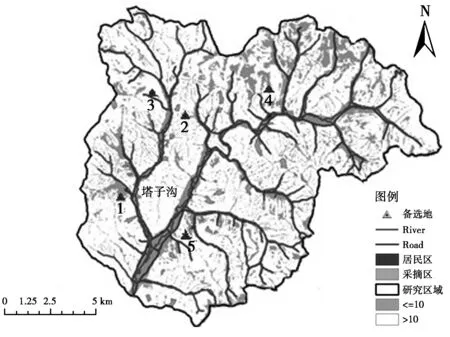
圖4 塔子溝林場集散點選址示意圖
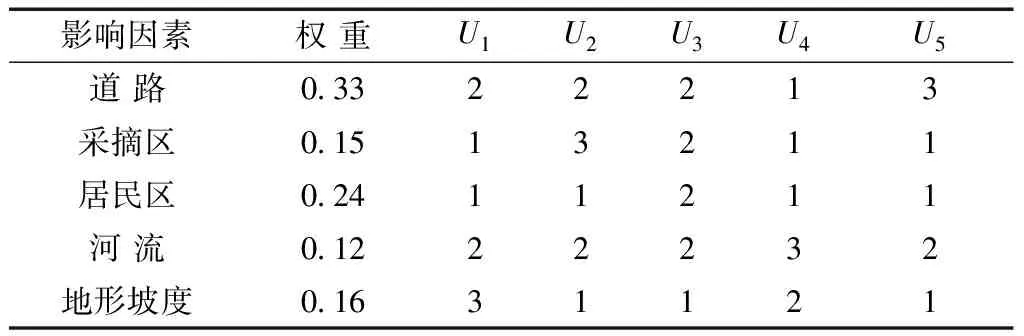
表2 集散點地址及其影響因素權重
根據式(5)得到隸屬度值,見表3。
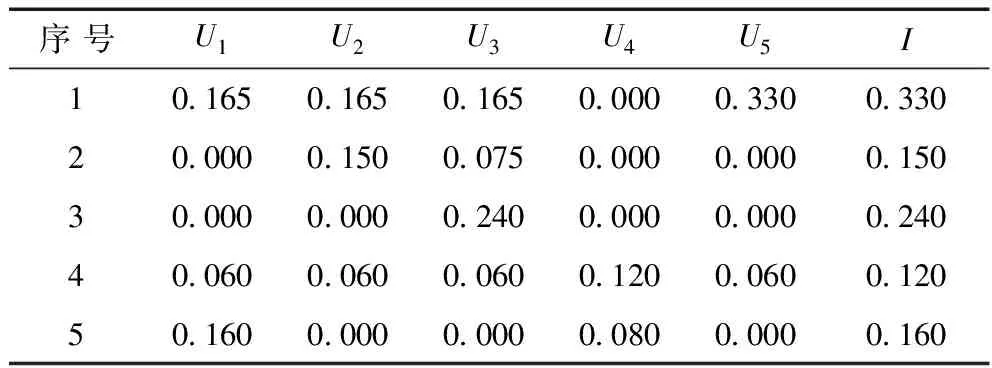
表3 隸屬度
根據式(6)計算貼近度,見表4。
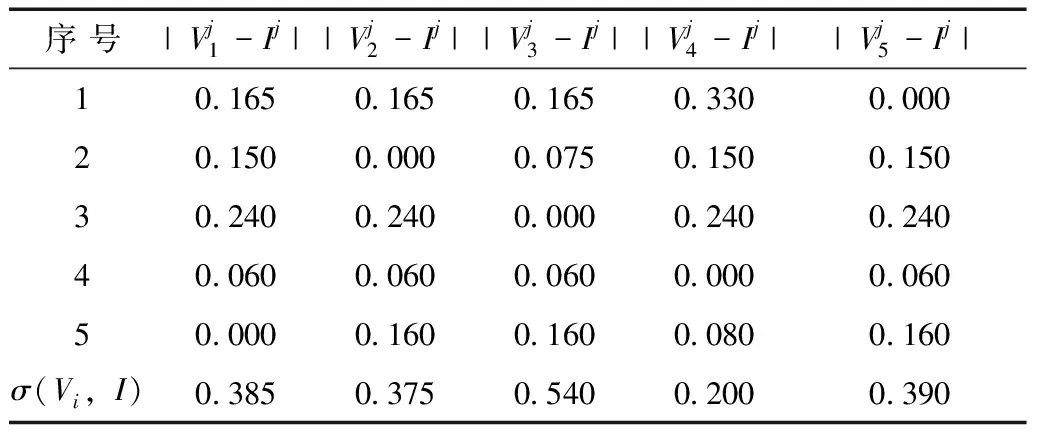
表4 貼近度
由表4的σ(Vi,I)值可以看出,塔子溝林場紅松籽物流集散點備選地址的優劣次序為U3≥U5≥U1≥U2≥U4。地蔭溝林場:U13≥U11≥U12;金倉林場:U19≥U20;大西南岔林場:U17≥U16;沙金溝林場:U6≥U7;荒溝林場:U9≥U8。
4 結 論
在現有的選址工作集中在城市選址時,本文進行了紅松籽的物流集散點選址工作研究,為林業企業、林業工人提供了一個符合實際需要的決策方案。在GIS初選地址的基礎上建立數學模型對初選地址優化,并且該模型不僅考慮到了經濟模型而且考慮到了影響因素權重的輔助模型。將GIS選址與傳統的數學方法選址相結合,使選址的問題更加準確。得到集散點選之后,建立了模糊決策分析模型,計算各備選地址與理想目標的貼近度,由此來得出各備選地的優劣排序。本文的研究工作為紅松籽物流集散點的選址提出一種新的構想以及實現思路,具有一定的借鑒價值,符合今后林業物流的發展方向。
但是限于現實物流選址的復雜性和多樣性,下面的問題需要在今后的研究中加以解決。
(1)由于對紅松籽知識的不完備性,本文從樹種來判斷林下經濟作物,僅以50%以上的紅松林區假設為采摘區。在實際工作中,還需要進一步了解紅松籽的具體生長環境,從而更準確的研究紅松籽物流集散點的地址。
(2)對紅松籽物流集散點選址考慮的因素不夠,簡化了選址的影響因素,對實際的預算,人力資源,基礎設施等問題沒有考慮。
【參 考 文 獻】
[1]王春燕.開發紅松產業,推動吉林經濟可持續發展[J].實踐與探索,2009(1),227-228.
[2]Simchi-Levi.D,Kaminsky P,Simchi-Levi E.Designing and managing the supple chain:concepts,strategies,and case studies[M].Boston:McGraw-Hill,2000.
[3]Ballou R H.Business logistics management:planning,organizing,and controlling the supply chain(Fourth Edition)[M].NJ:Prentice-Hall,1999.
[4]吳信才.地理信息系統原理與方法[M].北京:電子工業出版社,2002.
[5]羅啟云,曾 琨,羅 毅.數字化地理信息系統建設與MapInfo高級應用[M].北京:清華大學出版社,2003.
[6]付鵬程,劉金華.物流配送中心的選址決策應用[J].交通科技,2003(1):80-82.
[7]楊 波,梁木梁,唐啟鶴.配送中心選址的隨機數學模型[J].中國管理科學,2002,10(5):57-61.
[8]魏光興.物流配送中心選址方法綜述[J].物流與交通,2005(9):48-49.
[9]Elon S C,Maria T A S,Alex A F,et al.A genetic algorithm for solving a capacitated P-median problem[J].Numeric Algorithm,2003,35(4):373-388.
[10]Laporte G.The vehicle routing problem:an overview of exact and approximate algorithms[J].European Journal of Operational Research,1992,59(3):345-358.
[11]朱軼群.GIS與模糊數學理論在商服中心空間選址中的應用[J].地理空間信息,2006(4)1:49-51.
[12]韓冰源,肖生靈.配送中心線路優化方法的探討[J].森林工程,2005,21(2):67-68.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
物流技術與應用(2020年11期)2020-03-11 03:11:36
汽車觀察(2018年12期)2018-12-26 01:05:44
消費導刊(2018年8期)2018-05-25 13:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
現代企業(2015年2期)2015-02-28 18:45:09
商界(2014年12期)2014-04-29 00:44:03
