普通話智能測試系統的語音識別網絡研究
2014-09-04 03:47:26陳彩華
西華大學學報(自然科學版) 2014年2期
關鍵詞:模型
陳彩華
(湖南三一工業職業技術學院,湖南 長沙 410129)
0 引言
計算機輔助普通話水平測試系統自試用以來,已經在全國十多個省市推廣。應用該系統不僅減少傳統人工現場評分帶來的人力、物力、財力成本,而且能較好地解決人工長時間工作所帶來的評分波動,實現評分的客觀公正。
現行系統屬于文本相關的評測,考生按照標準文本發音,計算機根據發音質量反饋出分數。實際推廣的普通話水平測試系統采用自動語音識別技術,即采用目前公認的最能反映標準度的基于隱馬爾科夫模型(HMM)的對數后概率算法,將考生的語音文本切分到音素,在音素基礎上計算出能夠反映考生發音標準度、流暢度的評分特征,再給出機器評分結果。HMM是一種基于統計的模型,各音素的發音分布描述只能依據高斯分布,各HMM之間易混淆,從而導致系統無法正確反映音段的發音質量,這將嚴重影響系統的評分性能,但語音識別中的語言模型能夠較好地消除HMM混淆影響;因此,本文借鑒語音識別中的語言模型思想,將普通話發音的語言學知識引入到對數后驗算法中,從語言模型的角度來重構對數后驗概率算法中的識別網絡,消除概率空間中HMM的混淆影響,解決不同音素之間后驗概率的不可比性。
如何削弱概率空間對語音測試系統的影響,提高系統的評測性能,學者進行了不懈努力。文獻 [1]提出 “根據聲韻母時長比例調整后驗概率”,根據時長加重聲母的權重,改善聲韻母間的后驗概率不一致問題。文獻 [2]提出音素混淆擴展網絡的后驗概率計算方法。這些方法的思想類似,都通過特定的方法減少概率空間中的音素個數,達到減少概率空間對評測任務影響的目的。
本文從目前已有的普通話水平測試自動評分系統出發,在文獻 [3]統計的4大類考生發音錯誤的基礎上,將絕大多數考生的發音錯誤規律引入到常用的后驗概率評價算法中,對算法的概率空間進行優化,并在500份普通話水平現場考試數據集上進行實驗。實驗結果表明,基于考生發音錯誤的概率空間能有效降低概率空間帶來的混淆。
1 普通話智能測試系統結構
受語音識別技術的限制,現行的普通話水平測試系統只能對考生完全按事先指定的文本朗讀的題型進行評測,屬于文本相關的語音評測。文本相關的發音質量自動評測系統的流程如圖1所示。

圖1 文本相關發音質量自動評測系統流程圖
預處理模塊接收考生語音和標準文本,得到語音的聲學特征和語音識別所需要的信息;語音識別模塊根據聲學模型進行識別,輸出音素及其邊界;評分特征提取模塊根據識別結果,結合文本和聲學模型,提取可量化的描述發音標準度、流暢度、完整度等評分特征;評分計算模塊根據評分特征計算并輸出考生的機器評分。
2 基于語言學知識的識別網絡重構
2.1 普通話評測系統中的識別網絡
普通話水平測試系統中的語音評測是基于對數后驗概率法的,即先在切分(forced alignment)[3]的音素邊界上按式(1)對單個音素進行計算,然后對考生的整個語流按式(2)進行規整,得到考生最終發音質量評分。
(1)
(2)
式中:Oi是根據考生的待測語音所提取的聲學特征,即觀測數據;di是Oi的時長(幀數);M為后概率空間;P(Oi|qi)是音素qi的似然度;N是考生整個語流中的音素個數。
式(1)中分母的輸出反映考生真實發音的音素級識別結果。實際發音評測中,因無法運用語言模型,因此由漢語聲韻母構成一個音素循環識別全網絡,如表1所示,再在全網絡中求各音素的最大似然度。

表1 漢語聲韻母列表
2.2 基于語言學知識的識別網絡重構
國內參加普通話水平測試的考生大都以漢語為母語,發音質量問題大都是受方言的影響產生的,有很強的規律性。普通話測試專家已經系統總結了帶方言口音普通話的各種音段錯誤和缺陷的基本類型[4]。典型的聲母錯誤包括: 1)將舌尖后音(翹舌音)讀作舌尖前音(平舌音);2)將舌尖前音(平舌音)讀作舌尖后音(翹舌音);3)將舌尖中鼻音讀作舌尖中邊音; 4)將舌尖中邊音讀作舌尖中鼻音。典型的韻母錯誤包括: 1)將后半高不圓唇元音e讀作前中元音,或前半高元音; 2)忽略卷舌韻母er的卷舌; 3)舌尖前元音-i(前)沒有保持單元音狀態,明顯向無元音的舌邊滑動; 4)舌尖后元音-i(后)沒有保持單元音的狀態,明顯向無元音的舌邊滑動,同時含卷舌成分。
語音識別系統的目標是要將不同人的發音差別盡可能模糊掉,還原發音者想要表達的原文,但是系統受語言模型限制。普通話發音質量評價系統的目標是要對不同考生的發音差別盡可能準確地進行判斷,并以此來評判考生發音的標準程度,因此,不能直接使用語音識別中的語言模型;但是系統可以借鑒語音識別中的語言模型思想,利用普通話測試中的語言學知識對算法的識別網絡進行精簡,即利用上述普通話常見聲韻母發音錯誤情況來限制式(1)中對數分母的最大值計算范圍。修改后的計算公式為
(3)
式(3)用音素qj的常見發音錯誤類型的模型集合Ej代替原來的全體聲韻母模型集合M,即用語言學知識[3]指導的精簡網絡代替原來的全網絡。
精簡網絡[1]是普通話測試專家在常見的語音錯誤和語音缺陷的基礎上,進一步實例化得到。“中國”一詞對應的聲韻母識別網絡如表2所示。

表2 詞語“中國”的精簡識別網絡
3 基于優化概率空間的后驗概率計算
普通話水平測試屬于文本相關的發音質量評測,與語音識別中基于詞圖的后驗概率有所區別。語音識別部分主要采用基于文本的切分方法,將考生的發音與標準文本強行對齊,得到由切分路徑構成的簡單識別網絡,構成式(1)的分子。式(1)的分母則為由精簡網絡決定的解碼網絡。以“中國”為例,對應式(1)中的分子、分母識別網絡如圖2所示。
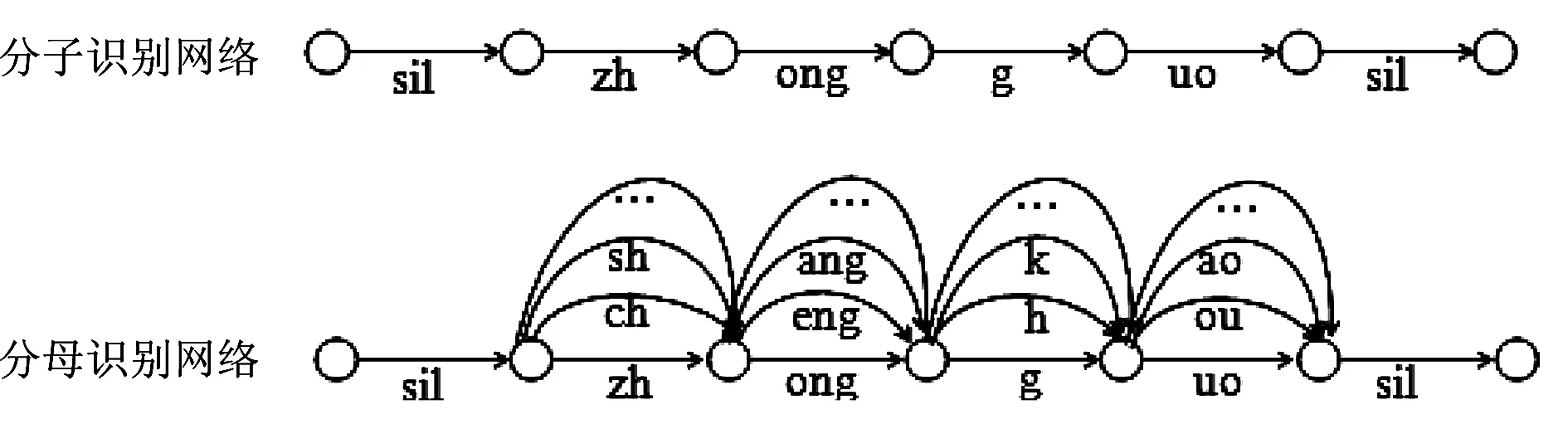
圖2 高斯后驗概率分子、分母識別網絡
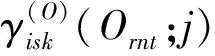
3.1 優化概率空間中弧后驗概率計算
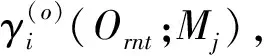
(4)
式(1)中基于分子識別網絡的后驗概率的計算公式為
(5)
3.2 優化概率空間中狀態后驗概率計算
在得到弧后驗概率的計算結果后,狀態后驗概率、高斯后驗概率的計算基本與語音識別一致。由于在指定弧下,利用Viterbi方法[5-7]得到的狀態后驗概率僅有0,1這2種值,因此,本文利用Viterbi算法計算狀態后驗概率。
先將式(1)中分子、分母識別網絡中的每條弧切分至狀態,再計算每幀的狀態后驗概率,如圖3所示。其中,ong[1]描述發音‘ong’的HMM的第1個有效狀態,ong[2]、ong[3]分別為第2、第3有效狀態。由Viterbi算法切分的狀態結果可知,在t時刻,狀態ong[2]的后驗概率為1,狀態ong[1]、ong[3]的后驗概率為0。

圖3 Viterbi算法中的弧狀態后驗概率示意圖
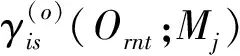
(6)
利用概率空間中各HMM對待測語音的聲學特征Or,n進行解碼。若弧i的第t幀狀態為s,則St(i,s,Or,n)=1,否則St(i,s,Or,n)=0。
3.3 優化概率空間中高斯后驗概率計算
在得到狀態后驗概率的計算結果后,指定狀態下的高斯后驗概率為當前高斯的加權似然度占所有高斯的加權似然度之和的比例。
分母的高斯后驗概率計算公式為
(7)
分子的高斯后驗概率計算公式為
(8)
其中
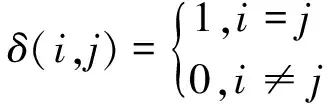
3.4 基于優化識別網絡的算法流程
基于優化識別網絡的語音評測算法的實現流程如圖4所示。
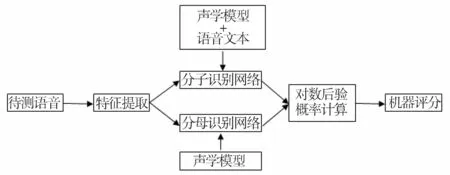
圖4 優化識別網絡語音評測算法流程
1)根據標準文本對考生語音進行語音識別,得到音素級識別結果。
2)根據考生的朗讀文本將音素HMM模型拼接構成強制匹配的分子識別網絡,同時生成一個無語法模型限制的音素循環識別網絡。
3)按上述后驗概率計算公式對音素和整個語流進行歸整,得到考生的發音質量評價得分。
4 實驗
4.1 實驗配置
普通話水平測試系統評測單字朗讀、雙字詞朗讀以及篇章朗讀3部分。實驗主要采用英國劍橋大學的HTK工具包[8]作為研究測試平臺,采用39維MFCC_0_D_A_Z聲學特征作為訓練參數,采用上下文無關的聲韻母模型作為聲學模型,共計67個HMM,包括聲母、韻母、零聲母、靜音、短時停頓、填充模型,每種模型壓縮至平均16高斯。
4.2 實驗數據庫
隨著普通話水平智能測試的推廣,全國各地的語音數據在數量上都有了極大的擴充。為保證實驗結果的普遍性,從全國各地普通話測試中心選擇有代表性的500份語音數據,共計約83 h,涵蓋普通話水平測試大綱中的全部字、詞、短文,每份數據都有專家的精細評分。
4.3 實驗結果
由于機器評分與專家評分間的相關度體現了人機評分的一致程度,因此算法選擇人機相關度作為評價系統性能的指標。人機相關度Corr計算公式為
(9)
實驗采用對比法,在全概率空間、典型錯誤概率空間分別考察后驗概率對評分性能的影響。具體實驗結果見表3。
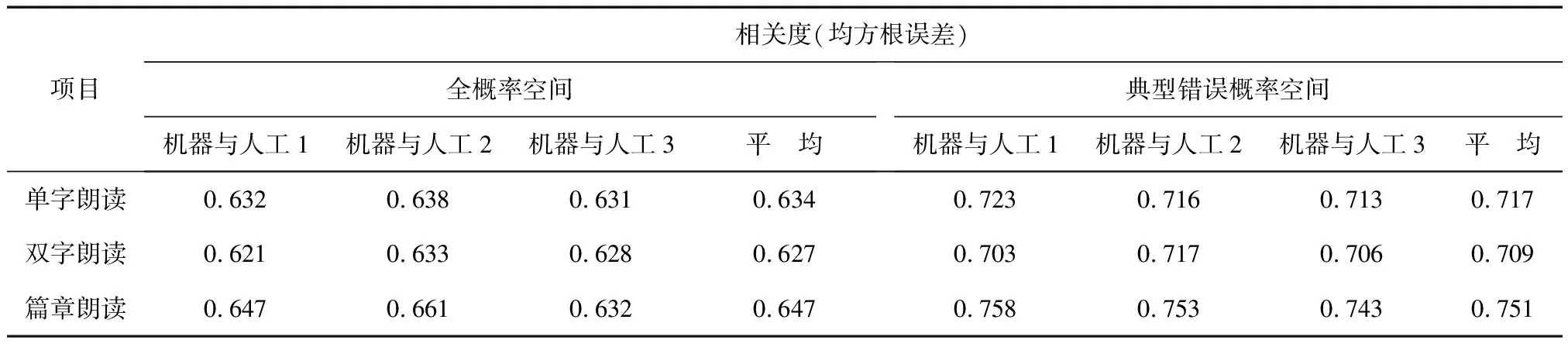
表3 不同概率空間中后驗概率算法評分性能
5 實驗結論
本文從普通話發音的角度,針對對數后驗概率算法中各HMM模型之間混淆率較大的不足,借鑒語音識別中的語言模型思想,從普通話的語言知識出發對算法的識別網絡進行簡化,進一步優化算法的概率空間,同時結合發音空間對后驗概率的計算進行研究。實驗表明,概率空間的優化不僅能夠提高系統評測模型的性能,同時由于概率空間音素個數遠小于全音素概率空間,因此還能顯著減少原有算法的運算量。
[1]WEI Si, LIU Qingsheng, HU Yu, et al. Automatic Mandarin Pronunciation Scoring for Native Learners with Dialect Accent [C] // Proceedings of Interspeech 2006. Pittsburgh, Pennsylvania: International Speech Communication Association, 2006: 1383-1386.
[2]Ge F P, Lu L, Yan Y H. Experimental Investigation of Mandarin Pronunciation Duality Assessment System[C] // International Symposium Computer Science and Society (ISCCS).Kota Kinabalu: [s.n.],2011:235-239.
[3]WANG Renhua, LIU Qingfeng, WEI Si. Putonghua Proficiency Test and Evaluation [M].[S.l.]:Advances in Chinese Spoken Language Processing,2006:407-429.
[4]宋欣橋.普通話水平測試員實用手冊[M].北京:商務印書館,2005:139-151.
[5]Liu Qingsheng, Si Wei, Yu Hu,et al. The Application of Phone Weight in Putonghua Pronunciation Quality Assessment [C]// The 5th International Symposium on Chinese Spoken Language Processing. Singapore :[s.n.],2006:603-608.
[6]Young S, Evermann G, Gales M. The Hidden Markov Model Toolkit [EB/OL]. (2005-10-20). http://htk.eng.cam.ac.uk/.
[7]Jang R. Audio Signal Processing and Recognition [EB/OL]. (2009-05-30). http://neural.cs.nthu.edu.tw/jang/books/audiSignalProcessing/.
[8] Young S , Kershaw D, Odell J , et al.The HTK Book :for HTK Version 3.0 [M]. Redmond :Microsoft Corporation, 2000:23-45.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
