問答社區問句中多字詞表達提取
2014-09-06 10:13:18吳瑞紅呂學強
吉林大學學報(理學版) 2014年6期
關鍵詞:搜索引擎
吳瑞紅, 呂學強, 李 卓, 舒 燕
(1.北京信息科技大學 網絡文化與數字傳播北京市重點實驗室, 北京 100101;2.北京拓爾思信息技術股份有限公司, 北京 100101)
問答社區問句中多字詞表達提取
吳瑞紅1, 呂學強1, 李 卓1, 舒 燕2
(1.北京信息科技大學 網絡文化與數字傳播北京市重點實驗室, 北京 100101;
2.北京拓爾思信息技術股份有限公司, 北京 100101)
基于互動問答社區問句中多字詞表達和問句理解的關系, 提出針對互動問答社區問句進行多字詞表達抽取, 并基于互動問答社區問句中多字詞表達的特點, 提出適用于互動問答社區的多字詞表達提取方法.該方法在利用互信息和停用詞表的方法從問句中抽取候選多字詞表達的基礎上, 將候選多字詞表達分為正確串、殘缺串、冗余串和錯誤串4類, 借助搜索引擎對查詢串的優化和候選多字詞表達在互聯網上的檢索結果, 設計候選多字詞表達校正方法, 實現對多字詞表達的提取.以新浪愛問知識人問題庫中的問句進行實驗, 結果表明, 多字詞表達抽取的準確率、召回率和F值分別達到84%,52%和0.64, 驗證了該方法的有效性.
多字詞表達; 問句理解; 互信息; 搜索引擎
多字詞表達(MWEs)指內部結合緊密、使用穩定、整體表示一個概念意義, 可作為一個固定短語使用的信息單元[1].多字詞表達廣泛存在于詞典中, 因其組成結構多樣、成分復雜, 因此其提取是大規模自然語言處理技術發展的關鍵問題之一[2].多字詞表達也廣泛存在于日常交流中, 如食物宜忌、紅糖姜茶等, 這些多字詞表達在信息檢索、本體構建、文本對齊和機器翻譯等領域應用廣泛.
近年來, 隨著互聯網的迅速發展, 互動問答社區應運而生, 互動問答社區的問句中蘊含大量的縮略語、歇后語、成語和慣用表達等多字詞表達, 它們是問句理解[3]的核心.由于給出回答的用戶人數眾多且回答質量參差不齊, 因此對回答質量進行自動判斷對用戶更加重要, 問句理解是進行這項工作的首要任務, 問句中多字詞表達提取也因此變得尤為緊迫.
針對多字詞表達提取的研究, 早期主要集中在詞語搭配方式上[4].Pecina[5]在MWEs測評提供的3種標準語料上針對德語中的Adj-N和PP-Veb搭配做實驗, 比較了55種不同的關聯方法, 實驗表明, 應用統計方法對多個不同的搭配進行融合比單個搭配抽取效果更好.文獻[6]研究表明, 互信息方法和對數似然比方法優于其他統計方法.隨著語言學規則的發展, 統計方法與語言學規則相結合的方法被大量應用到多字詞表達抽取中.Ramisch等[7]以英語中人工構建的Verb-Particle結構和德語中人工構建的Adj-N進行實驗, 發現加入語言學規則要比單純使用統計方法的效果更好; Al-Haj等[8]針對希伯來語提出結合語言學形態規則和句法規則對多字詞表達進行抽取, 結果表明, 應用語言學規則與統計結合的抽取效果更好; Tsvetkov等[9]針對希伯來語-英語語料中提出了雙語語料中語言學特征的融合方法, 提高了多字詞表達抽取的準確率; 文獻[10]通過引入詞典, 同樣提高了識別的準確率; Duan等[11]針對雙語語料中多字詞表達抽取, 從生物基因得到啟發, 提出了一種生物啟發的多字詞表達抽取方法, 將最長公共子序列和語言學方法進行融合, 提高了雙語多字詞表達提取的效果.劉榮等[1]利用高頻詞和互信息對特定領域進行了多字詞表達提取.文獻[12]針對特定領域, 利用統計量和語言學規則提取多字詞表達; 胡玉溪[13]針對中英文雙語語料對多字詞表達進行研究, 取得了一定的進展.
上述方法均以較規范的語料庫作為研究對象, 對互動問答社區這種大眾參與的非正規文本語料中多字詞表達提取不完全適用.本文首次提出針對互動問答社區問句進行多字詞表達抽取, 且充分結合互動問答社區及社區問句中多字詞表達的特征提出互動問答社區問句中多字詞表達抽取的方法.
1 語料特點
互動問答社區即“互動式知識問答分享平臺”, 是目前備受關注的網絡應用, 其內容來源于用戶, 并服務于用戶.新浪愛問知識人是中國第一個中文互動型問答產品, 為用戶提供發表提問、解答問題和搜索答案等服務.以愛問知識人為例, 分析問句特點如下:

圖1 問句在搜索引擎中的檢索結果Fig.1 Retrieval result of the questions in search engines
1) 互動問答社區屬于互聯網應用, 社區中的問句也屬于互聯網資源, 這些問句均可通過搜索引擎在互聯網上找到與其相同或相關的資源.如問題: “得了白內障, 怎么辦”在百度搜索引擎中的部分檢索結果如圖1所示.
2) 互動問答社區中的真實問題與傳統問答系統中的問題不同, 傳統問答系統中的問題一般直切主題, 而互動問答社區中的真實問題一般會先對要提問主題的一段場景進行描述, 然后加一個或幾個與所述場景相關的問題.
例1“我家女兒6.5歲, 前兩天帶她測了骨齡和成長激素, 醫生說她的骨齡與年齡相符, 根據測試結果孩子只能長到1.53~1.55 cm, 不知這種測試準不準確? 能不能改變? 應該怎樣才能讓她再長高一點?”
例2“大家好, 我有過敏性鼻炎, 原來一直沒有明顯癥狀, 但從去年開始一直犯不停, 尤其是在辦公室, 尷尬極了!我也知道這個病不是能夠徹底治愈的, 但是希望大家出主意, 能減緩癥狀即可, 不至于在辦公室鼻涕流不停就行了.拜托了!”
由此可見, 互動問答社區的問句與一般問句不同, 蘊含豐富的提問背景信息, 用戶為了清晰、準確地描述所在場景, 通常會選擇豐富的多字詞表達進行闡述, 因此多字詞表達對互動問答社區中的問句理解具有重要作用.
3) 問句中表達不規范, 語言描述簡練、隨意.
例3“以前不知道從幾歲開始 我的2棵虎牙都有點向外生長 有點暴起 可現在我都22了 這段時間我發現我又在長大牙 這到沒什么 不過下面的還好 上面兩邊的大牙都在向外長 而且很斜 現在都已經頂到口腔壁了 吃東西有時候要咬到 影響太大了 有高手給我提提建議呀 要不要去拔掉 但是我想 大牙對于吃東西那么重要 要是拔掉了 以后老了就沒牙了 老火啊”.
例3中用戶的表達非常隨意: 沒有添加任何標點符號, 而且存在多處句子成分不完整的情況, 如:“不過下面的還好”、“要不要去拔掉”等.由于漢語語法的復雜性和現有漢語詞法、句法理論體系的不完備, 對表達不規范的問句做詞法、句法、語義分析準確率非常低, 所以在互動問答社區中的多字詞表達研究中, 傳統相對正規的語料上基于語言學規則提取多字詞表達的方法并不適用.
4) 問句中出現大量普通文本語料中不常出現或出現頻率較低的詞語, 如: 高手、幫忙、解答和咨詢等.
多字詞表達蘊含于問句中, 多字詞表達具有如下特點:
1) 多字詞表達由術語、命名實體、專有名詞和縮略語等組成, 利用現有分詞工具[14]進行分詞時, 準確率較低, 通常被切分成多個單元.
例4“磷酸 肌 酸 激酶 英文 名 CK 結果 1596 狀態 單位 U/L 參考范圍 24~195 肌 酸 激酶 同工酶 英文 名 CK-MB 37 U/L & lt; 24 是 心臟病 嗎 ? ? 是 檢查 出來 的”.
例4中, 多字詞表達“磷酸肌酸激酶”被切分成“磷酸”、“肌”、“酸”、“激酶”; “肌酸激酶同工酶”被切分成“肌”、“酸”、“激酶”、“同工酶”.
2) 由于問句中用戶表達不規范和多字詞表達成分復雜, 此時的多字詞表達一般很難找到規范語料庫中多字詞表達的搭配規則.
例5“不/d 知道/v 安/g 基酸/n 對/p 乙肝/n 有/v 沒/d 有/v 害處/n ?/w 還/d 請/v 各/r 位/q 專家/n 指點/v!”.
例6“我/r 老婆/n 懷孕/v 八/m 個/q 月/n 了/y, /w 一直/d 喝/g 的/u 都/d 是/v 圣/g 元/q 的/u, /w 現在/t 優/g 聰/g 都/d 出/v 問題/n 了/y,/w 不知/v 優/g 博/g 孕婦/n 奶粉/n 到底/d 有/v 沒/d 有/v 問題/n, /w 急/ad 死/v 人/n 了/y, /w 請/v 各位/r 知道/v 的/u 多多/d 指教/v !/w 謝謝/v !/w”.
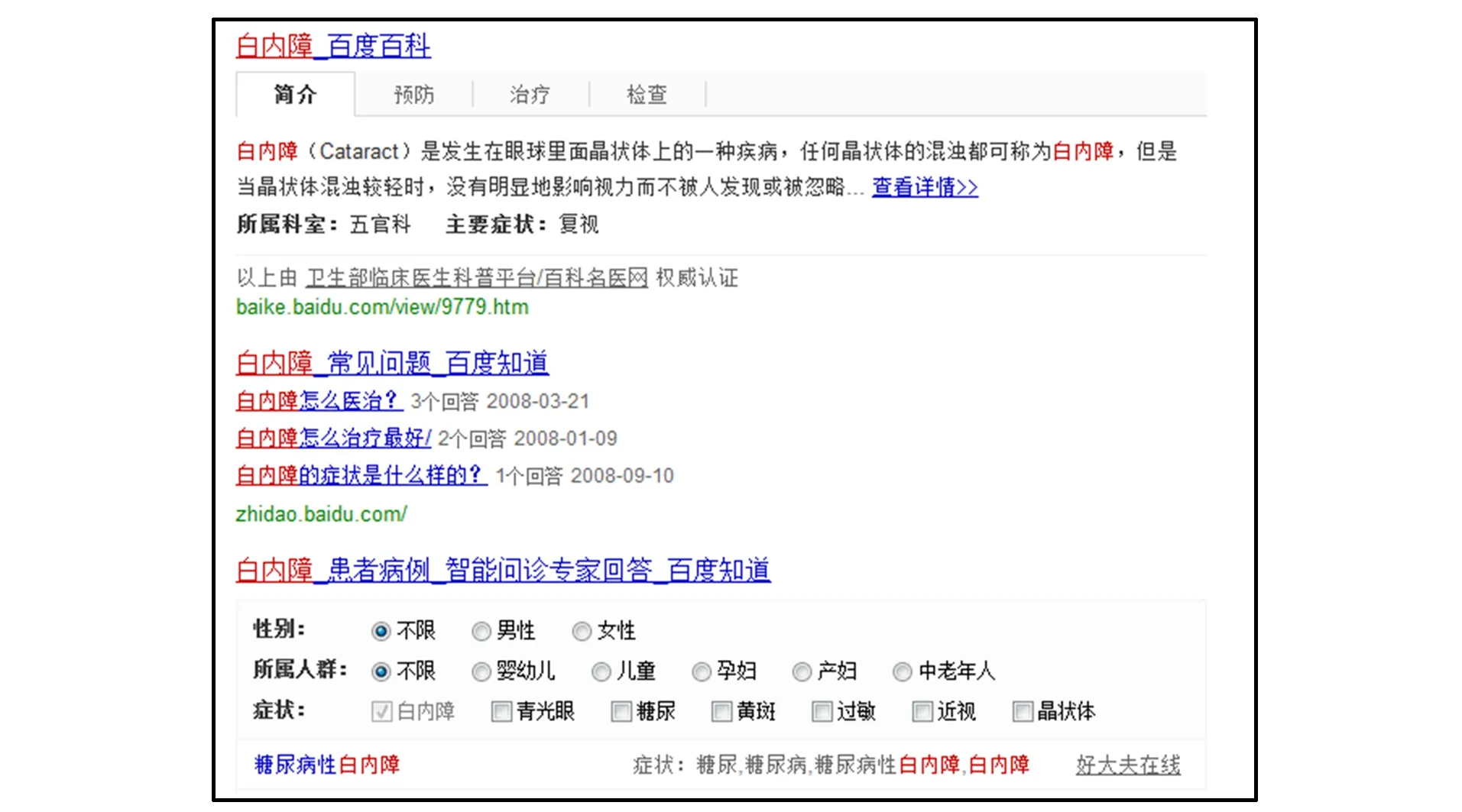
圖2 多字詞表達“白內障”在搜索引擎中的檢索結果Fig.2 Retrieval result of the MEWs “cataract”
一般語料中的多字詞表達遵循一定的搭配規律, 如n+v型等的詞性搭配規律.例5和例6中, “安/g 基酸/n”的詞性構成規則為“g+n”, “圣/g 元/q”的詞性構成規則為“g+q”, “優/g 聰/g”的詞性構成規則為“g+g”, “優/g 博/g 孕婦/n 奶粉/n”的詞性構成規則為“g+g+n+n”.問句中多字詞表達不遵循一般多字詞表達詞性構成規則.
3) 由于互動問答社區的問句屬于互聯網資源, 問句中蘊含的多字詞表達在互聯網上有其相關的資源, 如問句“得了白內障, 怎么辦”中的多字詞表達“白內障”在搜索引擎中的檢索結果如圖2所示.
2 候選多字詞表達的生成
從問句中多字詞表達的構成特點1)可見, 多字詞表達一般由多個有序詞串組合而成, 組成多字詞表達的多個有序詞串在語料庫中出現的頻次較大, 其間的結合緊密度也較大; 而不能組成多字詞表達的有序詞串在語料庫中出現的頻次較小, 其間的結合緊密度也較小, 因此通過計算有序詞串間的結合緊密度可判定有序詞串是否組成多字詞表達.
詞串間的結合緊密度通過互信息體現, 受候選詞串各自詞頻及其共現詞頻的影響, 而在語料中存在一些類似“高手幫忙”、“怎么回事”的詞, 這些詞出現頻次較高, 但缺乏實際區分性意義, 本文將這些詞統稱為問句型停用詞.在結合緊密度較高的一部分詞組中, 不可避免地包含有問句型停用詞, 因此, 為了提高多字詞表達抽取的準確率, 本文結合問句特點構建問句型停用詞表對詞串進行過濾.用以上方法生成的詞串中含有很多公共子串, 為了提高多字詞表達抽取的準確率, 減少對后續工作的影響, 需要對候選詞串進行合并, 進而得到候選多字詞表達.
2.1基于互信息的詞串生成
互信息能較好地度量詞串間的結合緊密程度, 對于詞串X和Y, 互信息計算方法如下:
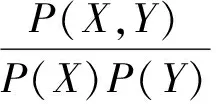
(1)
多字詞表達至少包含2個字, 根據劉榮等[12]的統計, 2~4個切分單元構成的多字詞表達已占94%, 本文以2~4個切分單元為主要研究對象.為此, 將二元互信息擴展為多元詞串內部的互信息.對于多元詞串內部的互信息, 采用Magerman等[15]提出的廣義互信息概念進行計算, 對于詞串x1…xn(2≤n≤4), 互信息計算公式為
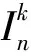
(2)
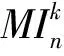
互信息越高, 表明X和Y相關性越大, 詞串X和Y組成多字詞表達的可能性就越大.通過該方法可初步選定共現可能性較大的詞串.設置閾值, 將互信息值大于設定閾值的詞串作為候選詞串, 過濾掉小于該閾值的詞串.
2.2問句型停用詞過濾
由互動問答社區問句中的特點4)可知, 在互動問答社區問句文本中, 存在很多不同于新聞語料等普通文本語料的常用搭配, 這些搭配出現的頻次較高, 且內部結合緊密度也較高, 但這些搭配缺乏實際意義, 并不是多字詞表達, 它們對多字詞表達提取帶來干擾.如問句: “我兒子得了腸炎, 請高手幫忙?急急!!”, 此句中“高手幫忙”會被識別, 在問句中還有很多類似的搭配.人工觀察語料中出現的此類停用詞, 可結合常用停用詞和問句中的停用詞構建適合問句特征的停用詞表.為了減少這些詞語對多字詞表達提取帶來的影響, 可利用構建的停用詞表, 將含停用詞的候選詞串刪除.
2.3融合公共子串的候選多字詞表達生成
經過詞串生成和停用詞過濾后的詞串中存在大量的公共子串, 若不對其進行處理, 會產生眾多無意義的詞串, 不僅會降低識別的準確率, 而且會產生大量重復計算.候選詞串合并包含: 1) 具有包含關系的子串合并; 2) 具有公共子串的相鄰候選串合并.具有公共子串的相鄰候選詞串是指將候選詞串按照其在語料中首次出現的順序排序后, 相鄰具有公共子串的詞串.互為包含關系的子串是指兩詞串之間存在包含與被包含的關系, 如在本文中互為包含關系的子串體現在部分三字詞詞串被四字詞詞串包含, 部分二字詞詞串被三字詞詞串或四字詞詞串包含.這部分詞串合并方法為: 將被四字詞詞串包含的三字詞詞串刪除, 被三字詞串和四字詞詞串包含的二字詞詞串刪除.
具有公共子串的相鄰詞串合并: 為了減少合并的次數, 降低計算的復雜度需先對四字詞詞串進行合并, 然后是三字詞詞串和二字詞詞串.對于去除了互為包含關系的子串, 先將候選詞串按照其在語料中出現的順序排序, 然后合并窗口為window, 合并方法為: 在window個詞串范圍內,n字詞詞串stri=“ti,1ti,2…ti,n”, stri+1=“ti+1,1ti+1,2…ti+1,n”, 其中ti,j(1≤i 分析得到的候選多字詞表達, 存在如下4類詞串. 1) 正確串: 內部結合緊密、使用穩定、完整的、具有獨立意義的多字詞表達, 如“非結合膽紅素”、“氯化鈉滴眼液”等. 2) 殘缺串: 完整多字詞表達的一部分詞串, 一般不具備獨立語義, 在語言結構上不具備完整結構, 如“丙氨酸氨基轉移酶”被處理成“丙氨酸氨基轉移”、“乳酸左氧氟沙星”被處理成“乳酸左氧氟沙”. 3) 冗余串: 完整多字詞表達是其子串, 有的具有獨立語義, 有的不具有獨立語義, 如“參考范圍”被處理成“106參考范圍”、“女貞子”被處理成“女貞子12克”. 4) 錯誤串: 不具備任何語義的串或包含錯別字的串.如“瓶六味”、“勁椎病”等. 多字詞表達校正是指對候選多字詞表達進行類型判別和更正, 包括對正確串的識別、殘缺串的補全、冗余串中蘊含正確串的抽取和錯誤串的去除.根據互動問答社區是互聯網資源的特點和問句中多字詞表達的構成特點可知, 問句中多字詞表達抽取不適合用語言學規則進行抽取, 因此, 本文利用問句中多字詞表達在互聯網資源中有其相關檢索結果的特點, 提出一種新思路: 結合不同類型候選多字詞表達在搜索引擎中查詢優化和搜索結果中的分布特征進行多字詞表達校正. 3.1基于互聯網的多字詞表達類型判別 候選多字詞表達類型判別是指區分出候選多字詞表達的類型, 包括正確串、冗余串、殘缺串和錯誤串4種類型. 搜索引擎在對查詢串進行檢索前, 通常先對查詢串進行優化, 這些優化方式包括查詢擴展和重構等.查詢優化對多字詞表達抽取具有很大幫助; 重構可將部分冗余串進行切分, 也能對部分殘缺串進行一定補足.搜索引擎返回的搜索結果是與查詢串最相關的信息, 問句及其中的多字詞表達來源于互聯網, 可借助查詢返回結果校正多字詞表達.將候選多字詞表達作為查詢串在搜索引擎中進行檢索, 獲取候選多字詞表達在搜索引擎檢索結果中的前20條結果標題及摘要信息, 作為搜索結果語料. 3.1.1 候選多字詞表達在搜索結果中的出現規律 記待判別類型的候選多字詞表達為candiateExp, 對每個候選多字詞表達進行如下定義. 定義1將candiateExp的搜索結果語料按中英文標點符號和空格進行劃分后形成的單元稱為詞串單元. 定義2將candiateExp搜索結果語料劃分成詞串單元后, 該詞串單元在所有詞串單元中出現的次數稱為詞串單元頻次. 定義3詞串單元-頻次對集合定義為SenPairSet={〈s1,c1〉,〈s2,c2〉,…,〈sn,cn〉}, 其中:n為candiateExp搜索結果語料中詞串單元的個數;si(1≤i≤n)為任一詞串單元;ci為詞串單元si的頻次; len(si)為si的長度. 定義4切分單元來源于兩種切分方法: 正向切分和逆向切分.正向切分指將candiateExp從左向右刪除字, 直至僅剩下兩個字; 逆向切分指將candiateExp從右向左刪除字, 直至僅剩下兩個字.將每次刪除后剩下的單元稱為切分單元. 定義5切分單元-頻次對集合記為CandiateExpSet, 獲取candiateExp的切分單元及切分單元在candiateExp搜索結果語料中的頻次, 形成candiateExp的切分單元-頻次對集合,CandiateExpSet={〈splitCan1,splitCanNum1〉,〈splitCan2,splitCanNum2〉,…,〈splitCann,splitCanNumn〉},其中: splitCanj(1≤j≤n)為candiateExp的任一切分單元; splitCanNumj為splitCanj(1≤j≤n)在candiateExp搜索結果中出現的頻次;n為切分單元的總個數. 正確多字詞表達是一種具有穩定性、特指性的語義概念單元, 它通常會被互聯網知識庫收錄, 表現在檢索結果中是該多字詞表達的下一個詞串單元中包含“百科”二字; 還有一部分正確多字詞表達雖未被互聯網知識庫收錄, 但卻在檢索結果中多次獨立成為一個詞串單元, 可利用這兩條規則對正確多字詞表達進行判別.冗余串中包含正確多字詞表達, 搜索引擎在對冗余串進行檢索時, 會對其進行一定的切分, 使冗余串作為一個整體在檢索結果中出現的頻次會很低, 而冗余串的切分單元在搜索結果中出現的頻次會相對較高.殘缺串是正確多字詞表達的子串, 將其在搜索引擎中檢索時, 搜索引擎會對殘缺串進行一定的補全, 表現在檢索結果上是殘缺串可能在一定的窗口范圍內, 與詞串單元存在被包含關系, 且該詞串單元在搜索結果中多次獨立出現; 此外, 殘缺串在搜索結果語料中出現的次數相對較高, 且殘缺串的切分單元出現次數均大于或等于殘缺串的出現次數.錯誤串不含有任何語義或包含錯別字, 其在搜索結果中的出現規律不明顯, 因此不作為單獨類型進行判斷. 3.1.2 基于規則的候選多字詞表達類型判別 根據不同類型候選多字詞表達在搜索結果中出現的規律, 候選多字詞表達類型判別較易解決. 1) 正確多字詞表達判別規則. 正確多字詞表達在搜索結果中出現的規律有兩個特點, 相應判別規則為: ① 在candiateExp搜索結果語料劃分成的詞串單元中, candiateExp為一個詞串單元, 且candiateExp緊鄰的下一個詞串單元包含“百科”二字, 則candiateExp為正確多字詞表達; ② 若存在candidateExp∈SenPairSet, 即在SenPairSet集合中存在si, 使得candidateExp=si; 且SenPairSet集合中ci高于一定閾值FreqThreshold, 則candidateExp為正確多字詞表達. 2) 殘缺串判別規則. 記c(candidateExp)為candidateExp在檢索結果中出現的頻次, 殘缺串在搜索結果中出現的規律也有兩個特點, 殘缺串類型判別規則為: ① 若集合SenPairSet存在〈si,ci〉, 使得candidateExp是si的子串,ci高于一定閾值FreqThreshold, 且len(si)-len(candidateExp) ② 在candidateExp的CandidateExpSet集合中, ?splitCanNumi≥c(candidateExp)(1≤i≤n), 且c(candidateExp)>FreqThreshold, 則candidateExp為殘缺串. 3) 冗余串判別規則. 冗余串在搜索結果中出現的頻次較低, 將在檢索結果中出現頻次低于閾值threshold的候選多字詞表達判斷為冗余串.綜合考慮候選多字詞表達在切分后所有切分單元出現的次數, 候選多字詞表達為冗余串的類型判斷閾值為 其中: threshold為candiateExp的類型判斷閾值, 1≤j≤n;n為切分單元總個數.若候選多字詞表達在搜索結果中出現規律不符合正確串、殘缺串和冗余串的判定規則, 則將其刪除, 不作為研究對象. 4) 候選多字詞表達類型判別算法. 綜合以上候選多字詞表達判別的規則, 候選多字詞表達類型判別算法如下. 輸入: 候選多字詞表達; 輸出: 已分類的候選多字詞表達; ① 讀入一條候選多字詞表達candidateExp; ② 將candidateExp作為查詢串在搜索引擎中進行搜索, 獲取搜索結果的前20條標題和摘要信息作為搜索結果語料; ③ 對搜索結果語料進行切分, 并獲取candidateExp的SenPairSet集合; ④ 判斷candidateExp出現的特點是否符合正確串判別規則, 如果符合, 判定candidateExp為正確串, 轉⑨; 否則轉⑤; ⑤ 對candidateExp進行切分, 統計切分單元頻次并構建candidateExp的CandiateExpSet集合; ⑥ 判斷candidateExp出現的特點是否符合殘缺串的判別規則, 若符合, 判定candidateExp為殘缺串, 轉⑨; 否則轉⑦; ⑦ 根據式(3)計算冗余串類型判斷閾值threshold; ⑧ 如果candidateExp在搜索結果中出現的次數小于threshold, 則判斷其為冗余串; 否則將其刪除; ⑨ 如果讀完最后一個候選多字詞表達, 則退出; 否則轉①, 讀入下一條候選多字詞表達. 3.2殘缺串和冗余串的糾正 殘缺串和冗余串的糾正是將殘缺串和冗余串中蘊含的正確多字詞表達抽取出來.根據正確多字詞表達是冗余串的子串特點, 在冗余串的切分單元集合中, 必存在被包含的多字詞表達.因此, 對冗余串進行切分, 將切分出的子串作為殘缺串進行處理. 殘缺串的糾正是根據殘缺串相鄰出現字與殘缺串間的共現程度進行擴展, 若殘缺串與其相鄰字共現程度較大, 則認為該殘缺串與相鄰字同屬于一個多字詞表達.因此, 可用相鄰差率的概念衡量兩個詞串的共現程度, 相鄰差率是指一個詞串在語料中出現的頻數與相鄰字出現頻數的絕對差占該詞串頻數的比率.左、右相鄰差分別為詞串左側的相鄰差率和詞串右側的相鄰差率, 分別統計串左、右兩側相鄰出現的字及其頻數, 記詞串str出現的頻數為f(str), 其左側相鄰出現的字l_str及其頻數為f(l_str), 則左相鄰差率leftRate計算方法為 同理, 串str右側相鄰出現的字r_str及其頻數為f(r_str), 右相鄰差率rightRate計算方法為 rightRate=|f(str)-f(r_str)|/f(str). (5) 對殘缺串str的所有相鄰差率進行計算后, 形成左相鄰差率集合: leftRateSet={leftRate1,leftRate2,…,leftRateln}, 其中ln為左相鄰差率的個數.則左相鄰差率的閾值選取方法為 同理, 右相鄰差率閾值選擇方法為 其中rn為右相鄰差率的個數.若str的相鄰差率小于閾值, 則向相應邊界添加一個字, 然后迭代計算其左右相鄰差率, 直至大于閾值或迭代次數大于一定次數, 將擴展出的詞串作為糾正的多字詞表達. 對殘缺串進行補全時可能會由一個串得到多個串, 因此需要對得到的多字詞表達在原問句語料庫中進行驗證, 將不屬于原語料庫中的多字詞表達刪除, 最終得到多字詞表達列表. 實驗選用新浪愛問知識人中健康與醫學領域已解決問題的154 003個問句作為實驗對象, 從中提取多字詞表達. 4.1實驗結果 本文采用多字詞表達抽取的準確率(precision,P)、召回率(recall,R)和F值(F-measure,F)評價指標對實驗結果進行評價, 計算方法為: 實驗中, 過濾掉在語料中出現次數小于3的字符串.選用多組實驗對參數進行最優選擇, 最終選定結果為: 互信息閾值經過實驗觀察, 選取-10作為閾值; 詞串合并窗口window為4; 判斷詞串單元獨立出現次數的閾值FreqThreshold=4, 判斷為殘缺串在搜索結果中出現的次數最低為10, 窗口window為3; 殘缺串補全迭代次數最多為4次.本文未將分詞詞表中已有的詞列入考察范圍, 實驗共獲取候選多字詞表達10 326個, 經過本文方法處理, 最終獲得9 822個多字詞表達. 為驗證本文方法的有效性, 參考文獻[1]并結合本文語料的特點, 選用文獻[1]中提出的互信息和停用詞過濾方法作為對比實驗.隨機從實驗得到的多字詞表達列表中抽取1 000個多字詞表達, 人工標注其正確的個數, 并計算其準確率; 再隨機從實驗語料中抽取1 000個多字詞表達, 統計其在實驗抽取的多字詞表達中正確識別的個數, 計算其召回率.準確率、召回率和F值的計算結果列于表1. 表1 實驗結果對比Table 1 Comparison of experimental results 實驗過程中, 在對候選多字詞表達類型進行判別時, 被剔除的候選多字詞表達共有13個, 其余均被判別到3個類別中; 分別從正確串、冗余串、殘缺串類別中各隨機抽取500個多字詞表達, 統計其識別的準確率, 結果列于表2. 表2 3個類別的準確率對比Table 2 Three categories of precision comparison 選取部分候選多字詞表達和其經過本文候選多字詞表達類型判斷、糾正后的結果列于表3. 表3 實驗抽取的部分多字詞表達對比Table 3 MWEs comparison of experimental results 4.2實驗分析 由表1可見, 對比實驗存在準確率和召回率均偏低的問題, 而本文方法中, 借助搜索引擎對候選多字詞表達進行類型判別, 并對其中的冗余串和殘缺串進行糾正, 使準確率和召回率都得到了提高, 表明本文方法具有較好的實驗效果. 由表2和表3可見, 對判別為正確串的多字詞表達, 識別準確率較好; 對殘缺串和冗余串的識別效果較未進行校正的結果有較大提高.由于將詞頻小于3的候選串過濾掉, 存在一些僅出現一次的人名、地名、機構名等不能被識別出來, 導致召回率低; 停用詞表過濾時, 像“阿”等類別字, 對大部分詞串均是停用詞, 而對小部分的多字詞表達如“阿奇霉素”卻不是停用詞, 將這類詞作為停用詞, 也是導致召回率低的原因.在分析識別錯誤的多字詞表達時, 發現大部分不正確的多字詞表達類似: “谷丙轉氨酶58”等冗余串和不具有實際意義的錯誤串, 多字詞表達后加一個數字的情況主要是由于這兩部分經常共現的緣故, 而錯誤串本身的統計特征不明顯, 是識別的難點. 綜上所述, 本文首次在互動問答社區的問句中進行多字體表達提取, 提出了互動問答社區問句中多字詞表達提取的方法.在分析互動問答社區中用戶提問問題特點的基礎上, 結合這些特點和已有的研究結果, 采用互信息方法及停用詞表的方法獲取問句中的候選多字詞表達.進一步分析了候選多字詞表達的特點, 并結合問句中多字詞表達屬于互聯網資源的特點, 提出了基于搜索引擎的多字詞表達校正方法.利用搜索引擎對查詢串的優化和其在互聯網的搜索結果, 對候選多字詞表達進行類型判別, 并根據不同類型進行糾正, 最終在原語料中對得到的多字詞表達進行驗證, 達到了較好的實驗效果. [1]劉榮, 王麗娟, 張志平, 等.利用高頻詞和互信息面向特定領域提取多字詞表達 [J].太原理工大學學報, 2009, 40(3): 210-214.(LIU Rong, WANG Lijuan, ZHANG Zhiping, et al.The Extraction of Multiword Expression in Special Field with High Frequency Words and Mutual Information [J].Journal of Taiyuan University of Technology, 2009, 40(3): 210-214.) [2]Sag I A, Baldwin T, Bond F, et al.Multiword Expressions: A Pain in the Neck for NLP [C]//Proceedings of the Third International Conference on Computational Linguistics and Intelligent Text Processing.Berlin: Springer, 2002: 1-15. [3]王恒.中文問答系統的研究與實現 [D].哈爾濱: 哈爾濱工業大學, 2008.(WANG Heng.Research and Implement of Chinese Q & A System [D].Harbin: Harbin Institute of Technology, 2008.) [4]Kenneth W C, Hanks P.Word Association Norms, Mutual Information and Lexicography (rev) [J].Comput Linguist, 1990, 16(1): 22-29. [5]Pecina P.A Machine Learning Approach to Multiword Expression Extraction [C]//Proceedings of the LREC 2008 Workshop towards a Shared Task for Multiword Expressions.Marrakech, Morocco: [s.n.], 2008: 54-57. [6]Aline V, Kordoni V, ZHANG Yi, et al.Validation and Evaluation of Automatically Acquired Multiword Expressions for Grammar Engineering [C]//Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL).Prague, Chech: [s.n.], 2007: 1034-1043. [7]Ramisch C, Schreiner P, Idiart M, et al.An Evaluation of Methods for the Extraction of Multiword Expressions [C]//Proceedings of the LREC 2008 Workshop towards a Shared Task for Multiword Expressions.Marrakech, Morocco: [s.n.], 2008: 50-53. [8]Al-Haj H, Wintner S.Identifying Multi-word Expressions by Leveraging Morphological and Syntactic Idiosyncrasy [C]//Proceedings of the 23rd International Conference on Computational Linguistics.Beijing: IEEE, 2010: 10-18. [9]Tsvetkov Y, Wintner S.Identification of Multi-word Expressions by Combining Multiple Linguistic Information Sources [C]//Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing.Edinburgh, England: [s.n.], 2011: 836-845. [10]Fazly A, Stevenson S.Automatically Constructing a Lexicon of Verb Phrase Idiomatic Combinations [C]//Proceedings of the 11th Conference of the European Chapter of the Association for Computational Linguistics (EACL).Trento, Italy: [s.n.], 2006: 337-344. [11]DUAN Jianyong, ZHANG Mei, TONG Lijing, et al.A Hybrid Approach to Improve Bilingual Multiword Expression Extraction [C]//Advances in Knowledge Discovery and Data Mining.Berlin: Springer, 2009: 541-547. [12]劉榮, 王奕凱.利用統計量和語言學規則提取多字詞表達 [J].太原理工大學學報, 2011, 42(2): 133-137.(LIU Rong, WANG Yikai.Extracting Multiword Expressions with Statistics and Linguistic Rules [J].Journal of Taiyuan University of Technology, 2011, 42(2): 133-137.) [13]胡玉溪.基于雙語語料的漢語多詞表達抽取 [D].北京: 北京郵電大學, 2011.(HU Yuxi.Multi-word Expression Extraction Based on Chinese-English Bilingual Corpus [D].Beijing: Beijing University of Posts and Telecommunications, 2011.) [14]ZHANG Huaping, YU Hongkui, XIONG Deyi, et al.HHMM-Based Chinese Lexical Analyzer ICTCLAS [C]//Proceedings of the 2nd SigHan Workshop on Chinese Language Processing.Sapporo, Japan: ACL, 2003: 184-187. [15]Magerman D M, Marcus M P.Parsing a Natural Language Using Mutual Information Statistics [C]//National Conference on Artificial Intelligence.Palo Alto, USA: AAAI, 1990: 984-989. ExtractionofMultiwordExpressionsinQuestionsofQuestionAnsweringCommunities WU Ruihong1, Lü Xueqiang1, LI Zhuo1, SHU Yan2 The multiword expressions (MWEs) in the questions of question answering communities have direct relationship with question interpretation.We first proposed the idea of extracting MWEs from the questions of question answering communities.According to the characteristics of multiword expressions in the questions, we proposed a method of extracting MWEs in questions of question answering communities.In this method, we first used mutual information method and stop words filtering method to get the candidate MWEs.Then we classified the candidate MWEs into four types: right string, incomplete string, redundancy string and error string.At last, with the help of query optimization in search engines and the candidate MWEs retrieval results on the internet, we designed a revising method to get the MWEs.We took the questions in Sina iask question library as the experimental corpus.And the results show that the precision, recall and theF-measure can reach 84%, 52%, 0.64 respectively, which proves the effectiveness of the proposed method. multiword expressions; question interpretation; mutual information; search engine 2013-09-09. 吳瑞紅(1988—), 女, 漢族, 碩士研究生, 從事自然語言處理的研究, E-mail: ruihong0417@163.com. 國家自然科學基金(批準號: 61171159; 61271304)和北京市教委科技發展計劃重點項目暨北京市自然科學基金B類重點項目(批準號: KZ201311232037). TP391.1 A 1671-5489(2014)06-1230-09 10.13413/j.cnki.jdxblxb.2014.06.25 韓 嘯)3 多字詞表達校正
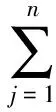
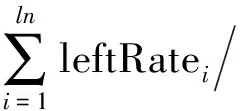

4 實驗結果與分析
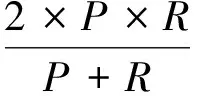



(1.BeijingKeyLaboratoryofInternetCultureandDigitalDisseminationResearch,
BeijingInformationScienceandTechnologyUniversity,Beijing100101,China;
2.BeijingTRSInformationTechnologyCo.Ltd.,Beijing100101,China)
猜你喜歡
計算機與網絡(2022年2期)2022-03-17 22:48:16中國衛生(2015年12期)2015-11-10 05:13:38警察技術(2015年3期)2015-02-27 15:37:09新疆大學學報(自然科學版)(中英文)(2014年2期)2014-11-06 07:49:12技術經濟與管理研究(2014年11期)2014-03-11 17:02:44科學導報·學術論壇(2013年5期)2013-06-26 05:41:54百科知識(2012年11期)2012-04-29 08:30:15中原工學院學報(2011年4期)2011-12-27 09:19:14微型計算機·Geek(2009年1期)2009-12-15 05:37:32計算機應用文摘(2009年17期)2009-04-29 00:44:03
