基于CPSO-AdaBoost算法的人臉檢測方法
2014-09-18 00:16:20梁嵐珍
電視技術 2014年19期
閆 斌,梁嵐珍,2
(1.新疆大學電氣工程學院,新疆烏魯木齊830047;2.北京聯(lián)合大學自動化學院,北京100101)
人臉檢測是人臉識別研究中的首個環(huán)節(jié),人臉檢測性能的好壞直接影響整個應用系統(tǒng)的性能。AdaBoost算法是一種基于學習的方法,2001 年,P.Viola[1]將其應用于人臉檢測,是第一個實時的人臉檢測算法。使用AdaBoost算法訓練分類器的缺點在于特征數(shù)目過多,且訓練耗時較大。因此,許多研究者則致力于改進Ada-Boost分類器的訓練算法。文獻[2]提出用多塊LBP特征(MB-LBP)替代Haar特征,在同樣大小的窗口中,MB-LBP特征數(shù)量較Haar特征要少很多,從而加快了訓練和檢測速度。文獻[3]采用Floating搜索方法優(yōu)化AdaBoost算法,用較少的分類器提高了分類性能。文獻[4]利用粒子群算法優(yōu)化 AdaBoost算法的訓練過程(PSO-AdaBoost),采用提取最佳閾值和最佳特征的方式,避免了窮舉搜索,有效地提高了訓練速度。但是該算法的初始化過程是隨機的,不能夠保證粒子個體質(zhì)量,并且粒子運行會出現(xiàn)“惰性”,容易陷入局部最優(yōu)解。
本文在PSO-AdaBoost算法基礎上,結(jié)合混沌運動的優(yōu)點,提出使用混沌粒子群算法結(jié)合AdaBoost人臉檢測算法(CPSO-AdaBoost),來訓練人臉檢測分類器,改善了PSO-AdaBoost算法搜索最佳特征的能力,算法的收斂速度和精度也得到了提高。
1 基于AdaBoost的人臉檢測算法
AdaBoost算法的核心思想是將訓練出來的分類器,通過篩選、確定一系列分類性能較好的弱分類器,然后通過線性疊加的方式將它們提升為強分類器。訓練流程如圖1所示。
從流程圖中可以看出,訓練的關鍵任務在于尋找到若干個性能較好的弱分類器ht。若這些分類器選擇得當,后續(xù)所獲得的強分類器性能則會更好。式中:x為子窗口圖像;f為特征;p為偏置;θ為閾值。
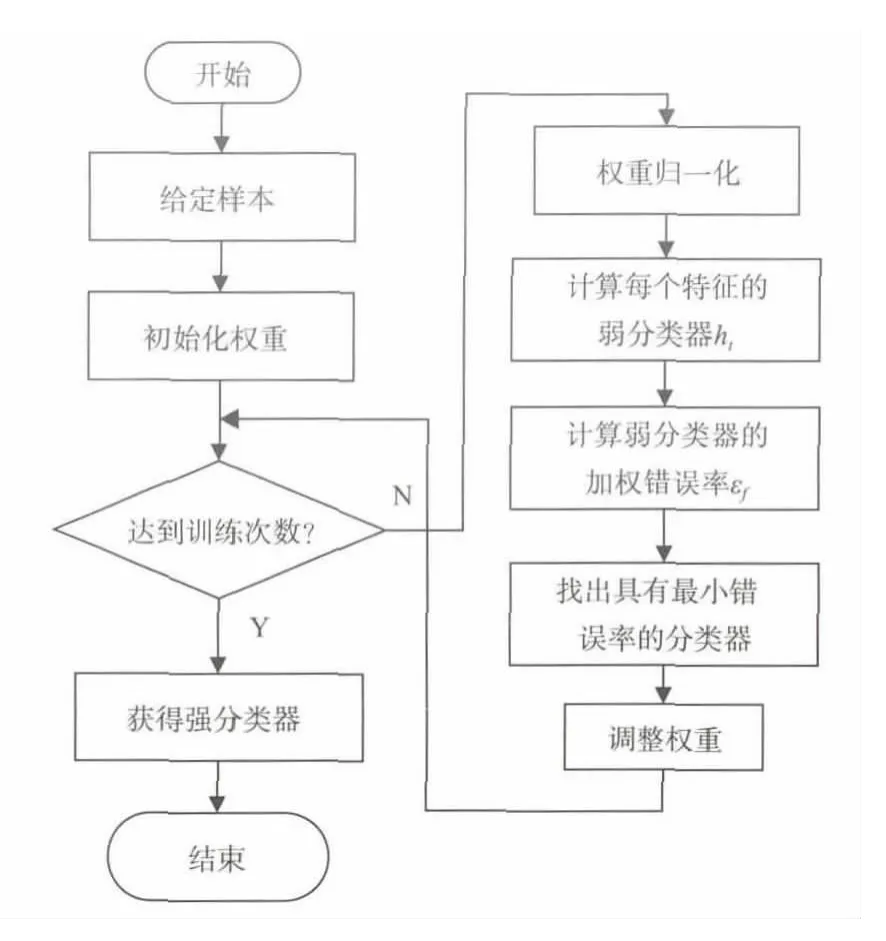
圖1 AdaBoost算法訓練流程圖
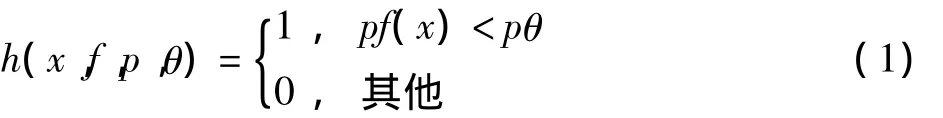
對于每一個特征f,訓練對應的弱分類器,即尋找并確定閾值 θ和偏置p,使其分類錯誤率函數(shù) εt=|h(xi,f,p,θ)- yi|的值最小(qi為歸一化后的權
弱分類器的數(shù)學結(jié)構為重),然后再從所有的弱分類器中尋找出最優(yōu)弱分類器。
AdaBoost算法訓練弱分類器時,是對每個特征進行窮舉搜索。然而一個檢測窗口的特征數(shù)量是巨大的,一幅24×24的圖像中就含有162 336個特征,訓練過程中,每循環(huán)一次都要計算一次目標函數(shù)來尋找最優(yōu)弱分類器,這將導致時間和內(nèi)存上的巨大開銷。
2 粒子群優(yōu)化算法
PSO算法是通過對鳥群某些行為的觀察研究而提出的一種進化算法[5]。算法中,每個粒子是由相應的目標適應度函數(shù)值決定其適應值,并由其速度調(diào)整粒子的移動方向和距離,通過迭代尋找全局最優(yōu)解。迭代中,粒子根據(jù)下面的公式更新自己的速度和位置
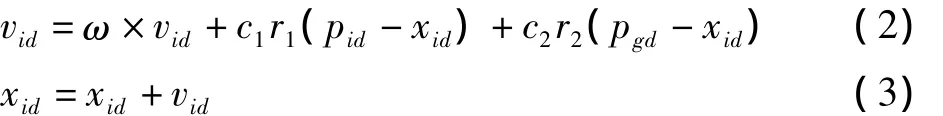
式中:ω為慣性權重;c1和c2為加速常數(shù);r1和r2為[0,1]范圍內(nèi)的隨機數(shù)。
由此可見,PSO-AdaBoost算法在訓練過程中能夠自動衍變出一組良好的特征和弱分類器,從而改善Ada-Boost算法的性能。然而,若待優(yōu)化函數(shù)較為復雜,包含多個局部極值點,或算法中的參數(shù)選擇不當,容易導致粒子的“早熟”現(xiàn)象,從而不能達到全局極值點。另外,由于算法迭代過程中僅僅依賴于pid和gid這兩個參數(shù)信息,沒有淘汰機制,而影響了算法的收斂速度。
3 混沌粒子群優(yōu)化算法
3.1 算法的基本思想
混沌是在確定系統(tǒng)中出現(xiàn)的一種看似混亂無規(guī)則,實則存在精細規(guī)律的類似隨機的現(xiàn)象[6]。混沌變量具有隨機性、遍歷性和對初始條件高度敏感性等特點。混沌優(yōu)化不要求目標函數(shù)具有連續(xù)性和可微性的性質(zhì)。
Logistic映射函數(shù)就是一個經(jīng)典的混沌系統(tǒng),在式(4)中,當μ=4,0<z0<1時,系統(tǒng)完全處于混沌狀態(tài)。
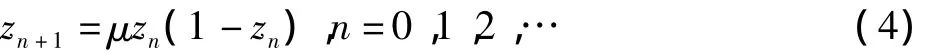
由于粒子群算法的隨機初始化過程僅能保證解群的均勻分布,但不能保證個體的質(zhì)量(如果離最優(yōu)解較遠),初始化的效果將影響到搜索的效率和解的質(zhì)量。另外通過分析式(3)可發(fā)現(xiàn),當粒子的當前位置xid及局部最優(yōu)值pid靠近全局最優(yōu)值gid時,vid的迭代僅依靠ω進行,當ω<1時,它的速度會越來越慢,而出現(xiàn)“惰性”,在接下來的迭代中,其他粒子會逐漸靠近此粒子完成進化,而無法達到全局最優(yōu)。
因此CPSO算法提出以下改進措施:
1)利用混沌序列對粒子進行初始化,保證了粒子的個體質(zhì)量和種群多樣性。具體作法為:隨機產(chǎn)生一個n維每個分量數(shù)值在[0,1]之間的向量,z1=(z11,z12,…,z1n),n為目標函數(shù)中的變量個數(shù),根據(jù)式(4)得到N個向量z1,z2,…,zN。并將zi的各個分量加載到對應變量的取值區(qū)間。
2)用當前最優(yōu)位置產(chǎn)生混沌序列,將該粒子與其他任意位置的某粒子互換位置,以幫助惰性粒子擺脫局部極值點。具體做法為:當粒子陷入局部最優(yōu)解Pg時,將pgi(i=1,2,…,D)映射到 Logistic方程的定義域[0,1],并通過式(5)把其變換到優(yōu)化變量的取值區(qū)間
式中:ai,bi為第i維變量的取值范圍,用Logistic方程迭代產(chǎn)生混沌變量序列(m=1,2,…),再把通過逆映射到原解空間,得到
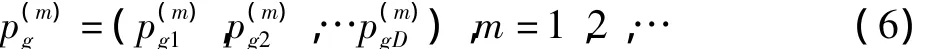
對每個混沌變量p(m)g經(jīng)歷的可行解計算適應值,并保存性能最好的可行解p*。最后用p*隨機取代群體中任意粒子的位置。
3.2 算法的測試及分析
為了測試CPSO的性能,本文使用測試函數(shù)GriewankFunction來進行試驗,并與PSO算法的試驗結(jié)果進行比較。試驗中各情況運行了50次,維數(shù)n取30,求得平均最優(yōu)適應值和最優(yōu)適應值作為比較的依據(jù)。
GriewankFunction函數(shù)為
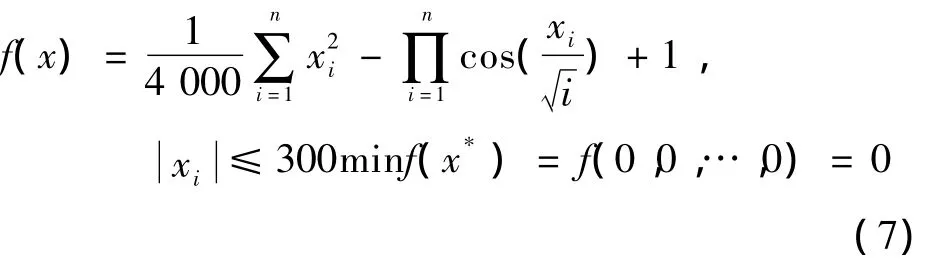
式中:當xi=0時,達到全局極小點;當xi=±kπ,i=1,2,…,n,k=1,2,…,n時,達到局部極小點。
2種算法計算結(jié)果見表1。

表1 GriewankFunction的2種算法測試值
GriewankFunction函數(shù)平均適應值隨迭代次數(shù)變化曲線如圖2所示。
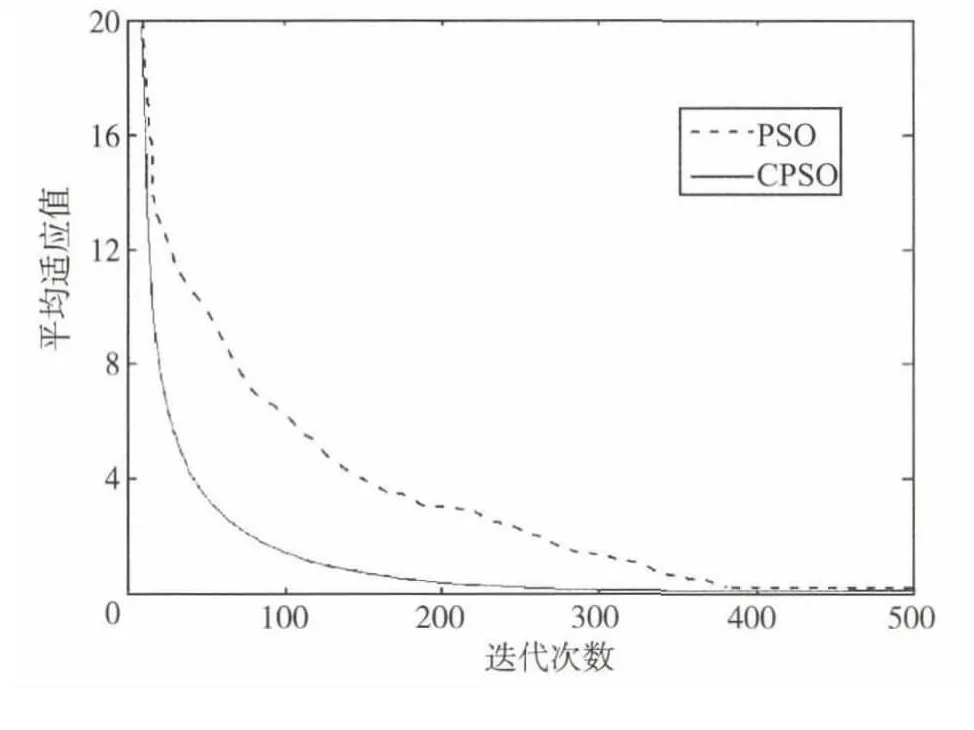
圖2 GriewankFunction平均值/迭代次數(shù)曲線
從試驗結(jié)果和圖2可以看出,CPSO算法性能優(yōu)于PSO算法,不但擁有較快的收斂速度,而且也有很強的全局搜索能力,CPSO的最優(yōu)適應值和適應值都比PSO的小,因此它的精度更高、更穩(wěn)定。從上述結(jié)果來看,CPSO方法適應于復雜函數(shù)的優(yōu)化問題,能夠獲得一定精度的全局最優(yōu)解。
4 CPSO-AdaBoost算法
4.1 粒子編碼及目標函數(shù)
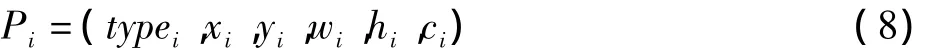
將弱分類器中的一組參數(shù)看成是搜索空間中的一個粒子,第i個粒子Pi可表示為式中:typei為矩形特征類型(取值范圍是[0,4]的整數(shù)),xi,yi為矩形特征左上角的坐標值,wi,hi為矩形特征的寬和高,ci為矩形特征值對正、負樣本的均值的均值[7]。
粒子的目標函數(shù)為
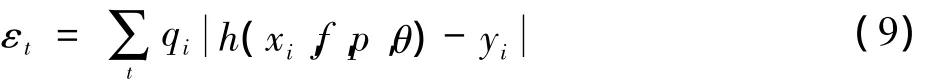
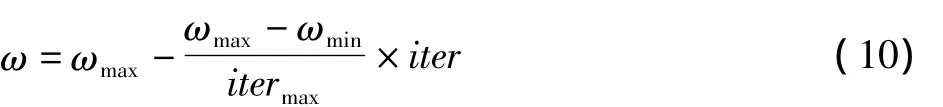
式中:iter表示當前迭代次數(shù);itermax表示最大迭代次數(shù);ωmax表示慣性權重初值;ωmin為終值[8]。
4.2 CPSO-AdaBoost算法流程
用CPSO優(yōu)化AdaBoost訓練算法的流程如下:
1)準備n個樣本集合,(x1,y2),(x2,y2),…,(xn,yn),并標示yi=0時為非人臉樣本,標示yi=1時為其為人臉樣本。
2)樣本權重初始化。
對于m個正樣本Dt(i)=1/2m,對于q個負樣本Dt(i)=1/2q。
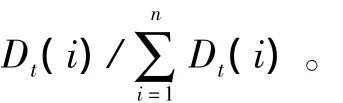
粒子的初始速度和位置均由混沌迭代出的序列初始化。ω取線性遞減慣性權重
While:
(1)混沌初始化粒子位置和速度。
(2)計算矩形特征與ci的大小,矩形特征大于ci,表示屬于正樣本,否則屬于負樣本,再計算各粒子的適應值。
(3)任意粒子,如果其fitness<pid,則將其設置為局部最優(yōu)值。
(4)任意粒子,如果其fitness<gid,則將其設置為全局最優(yōu)值。
(5)根據(jù)式(3)調(diào)整粒子的速度和位置。
(6)對最優(yōu)位置Pg進行混沌優(yōu)化。
(7)若達到搜索的停止條件,則輸出全局最優(yōu)位置及其fitness值(即最佳弱分類器),否則返回步驟(2)繼續(xù)搜索。
4)更新每個樣本對應的權重。
5)形成強分類器。
5 試驗結(jié)果及分析
為了對比效果,筆者使用傳統(tǒng)AdaBoost算法、PSO-AdaBoost算法和CPSO-AdaBoost算法,從分類器的訓練和人臉檢測兩個方面進行比較。所用樣本來自MIT CBCL樣本庫和網(wǎng)上下載的圖片,其中訓練集樣本包括2 305個人臉樣本和3 216個非人臉樣本,測試集包括2 138個人臉樣本和3 623個非人臉樣本,并對樣本進行尺寸調(diào)整和灰度歸一化的預處理操作。部分樣本如圖3所示。

圖3 部分人臉和非人臉樣本圖
5.1 分類器訓練結(jié)果比較
首先進行參數(shù)設置,CPSO的粒子個數(shù)設定為20個,終止迭代代數(shù)為100代,當特征的適應值在50代以內(nèi)沒有明顯改變的情況下,迭代提前終止,c1,c2均為2.05。訓練指標為檢測率≥0.99,誤檢率≤0.01。
本次試驗訓練了一個強分類器,訓練數(shù)據(jù)包括訓練指定性能的分類器所需要的平均特征數(shù)量和訓練耗時。表2中列出了3種算法的訓練結(jié)果。AdaBoost算法訓練時,由于最后一層的錯誤率下降速度過慢,且時間超過了4天,因此選擇了手動終止。
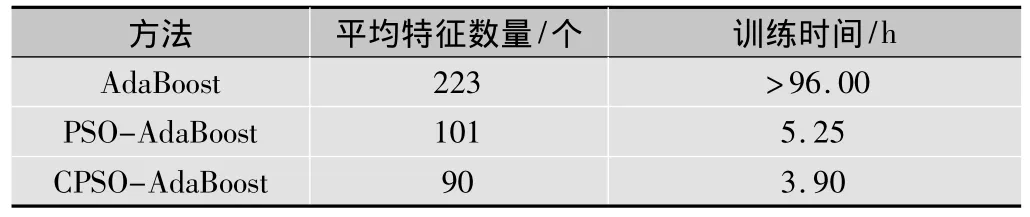
表2 平均特征數(shù)量和訓練時間的對比
從表2中可以看出,本文算法較其他算法在訓練的過程中所需要的平均特征數(shù)要少很多,訓練的時間復雜度也得到了降低。
5.2 檢測算法性能比較
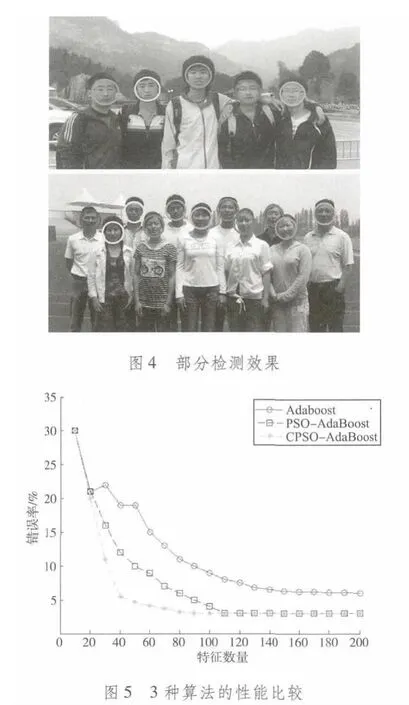
檢測過程采用訓練出來的強分類器對測試集中的樣本進行檢測,并統(tǒng)計檢測結(jié)果,表3中列出了檢測結(jié)果,部分檢測效果如圖4所示。測試性能曲線如圖5所示。
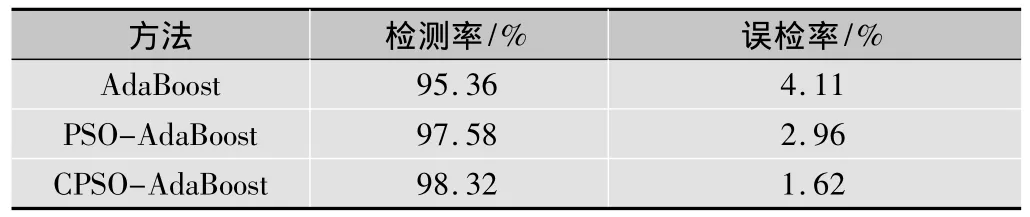
表3 檢測結(jié)果的對比
從檢測結(jié)果來看,本文算法相對另外兩種算法的檢測性能是最好的,只需要少量的弱分類器就能達到與其他算法相同的檢測率。究其原因,是因為CPSO-Ada-Boost算法在構造弱分類器具有比其他兩種算法更強的最佳特征搜索能力,這些最佳特征包括人臉的眼睛,鼻子和嘴巴周圍的特征,具有明顯的區(qū)分人臉和非人臉的特性,CPSO-AdaBoost算法有效地將這些特征挑選出來訓練分類器,從而獲得較高的檢測性能。
6 結(jié)論
本文提出使用混沌粒子群算法優(yōu)化AdaBoost算法的分類器訓練過程,解決了僅使用粒子群優(yōu)化算法中存在的容易陷入局部最優(yōu)解的困擾,增強了系統(tǒng)的穩(wěn)定性,總體性能優(yōu)于PSO-AdaBoost算法。針對同一訓練及測試樣本集,訓練時間減少了23%,檢測率提高了0.94%。下一步需要研究的問題是如何通過對訓練樣本集的選擇,或?qū)μ卣餍D(zhuǎn)特性的擴展,來解決對側(cè)面和傾斜的人臉檢測難題。
:
[1] VIOLA P,JONES M.Robust real-time face detection[J].International Journal of Computer Vision,2004,57(2):137-154.
[2] ZHANG L,CHU R,XIANG S,et al.Face detection based on multiblock LBP representation[EB/OL].[2014-01-16].http://link.springer.com/chapter/10.1007%2F978-3-540-74549-5_2.
[3] LI S Z,ZHANG Z Q.Floatboost learning and statistical face detection[J].IEEE Trans.Pattern Analysis and Machine Intelligence,2004,26(9):1112-1123.
[4] MOHEMMED A W,ZHANG Mengjie,JOHNSTON M.Particle swarm optimization based AdaBoost for face detection[C]//Proc.IEEE Congress on Evolutionary Computation.Piscataway,NJ:IEEE Press,2009:2494-2501.
[5] MOHEMMED A W,ZHANG M J,JOHNSTON M.Particle swarm optimization based AdaBoost for face detection[EB/OL].[2014-01-16].http://www.researchgate.net/publication/221008163_Particle_Swarm_Optimization_based_Adaboost_for_face_detection.
[6]孫子文,王鑫雨,白勇.基于信度和早熟檢驗的混沌粒子群優(yōu)化定位算法[J].傳感器與微系統(tǒng),2013,33(9):43-46.
[7] 李睿,張九蕊,毛莉.基于EREF的PSO-AdaBoost訓練算法[J].計算機應用研究,2012,29(1):127-129.
[8] SHI Y,EBERHART R.A modified particle swarm optimizer[C]//Proc.the IEEE World Congress on Computational Intelligence.Piscataway:IEEE Service Center,1998:69-73.
猜你喜歡
房地產(chǎn)導刊(2022年5期)2022-06-01 06:20:14
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
建材發(fā)展導向(2021年12期)2021-07-22 08:06:48
建材發(fā)展導向(2021年7期)2021-07-16 07:07:52
中學生數(shù)理化(高中版.高二數(shù)學)(2021年12期)2021-04-26 07:43:48
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
