采用子帶長時信號變化特征的VAD檢測
2014-09-18 00:16:26龍志軍
電視技術 2014年19期
蔡 鐵,唐 飛,龍志軍
(1.深圳市可視媒體處理與傳輸重點實驗室,廣東深圳518172;2.深圳信息職業技術學院,廣東深圳518172;3.中興通訊股份有限公司,廣東 深圳518057)
語音活動檢測(Voice Activity Detection,VAD)技術的目標是要確定語音開始和結束的位置,其應用十分廣泛,可作為前端處理,提高語音識別系統的識別率,改善語音增強的效果,提升語音編碼和傳輸的效率。傳統的語音活動檢測算法主要基于能量特征[1],在高信噪比條件下十分簡單有效,但在信噪比較低的情況下性能很差,有時甚至無法工作。因此,提高噪聲條件下語音活動檢測的穩健性是此領域研究工作關注的重點,如負熵[2]、長時譜散度[3]、自相關特征[4]等,雖然提高了 VAD算法在低信噪比環境下的穩健性,但在不同的噪聲條件下還不能取得一致的好效果。近年來,一些研究者提出了一些新的時長在150 ms以上的長時特征,例如長時信號變化(Long-term Signal Variability,LTSV)特征[5]以及(Long-term Spectral Flatness Measure,LSFM)特征[6],這些長時特征能在多種噪聲條件下取得不錯的效果,但大多采用傳統的門限比較法,在噪聲變化條件下表現不佳,檢測準確率大幅降低。
此外,為提高VAD算法在低信噪比下檢測的準確率,一些研究者對基于統計模型的VAD進行了深入研究[7-8],更關注數學統計模型的選取,其中,高斯混合模型(Gaussian Mixture Models,GMM)由于在噪聲環境下性能較好,近年來常用作VAD算法的統計模型[9-10]。
由于目前提出的長時特征都是從二維時頻窗口中提取信息,沒有引入語音的聽覺譜特性。對人耳聽覺功能的研究表明,人耳對語音信號的處理首先是將信號在不同頻率子帶進行分解,經各頻率子帶的處理后再綜合處理結果。由于各子帶的頻率分布不同,人的聽覺系統對不同頻段信號的感應也大不相同。此外,不同種類的噪聲也具有不同的頻率分布。因此,本文提出了一種采用子帶長時信號變化特征的穩健語音活動檢測算法,在頻域將語音信號分解為幾個不重復的子頻帶,分別提取這些子頻帶的長時信號變化特征,然后采用GMM在線建立語音和非語音模型進行VAD處理。實驗結果表明,本文算法可有效提高VAD在低信噪比環境及不同噪聲條件下的性能,且算法的計算復雜度不高,具有良好的實時性。
1 子帶長時信號變化特征的提取
根據文獻[5],語音信號的長時信號變化特征是由每個頻帶的長時譜熵取平均值計算獲得的,它能使VAD算法在低信噪比情況下具有良好的穩健性。但在脈沖噪聲的影響下,LTSV特征的性能將會明顯降低。為了使特征參數包含各個頻段的動態信息,獲取語音信號在不同頻帶的變化特性,本文采用子帶處理方法,提取子帶長時信號變化特征組成特征向量,進一步提高VAD算法的性能。
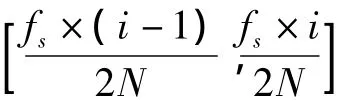
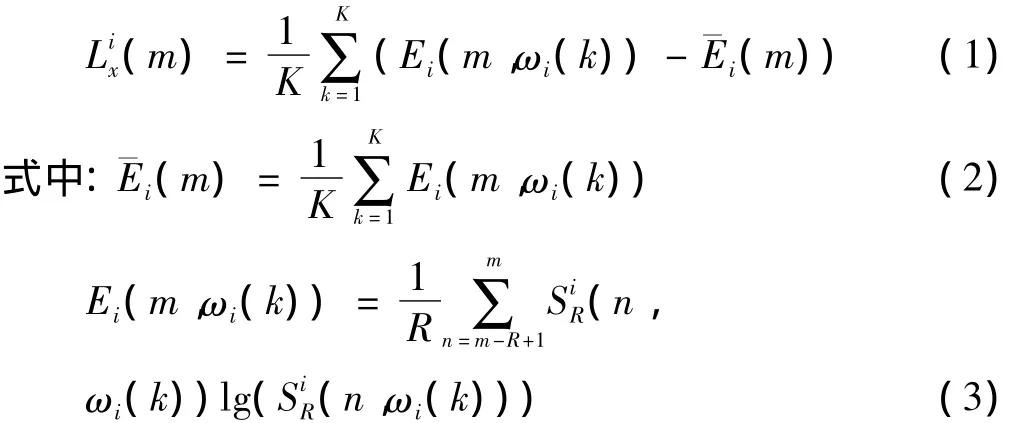
Ei(m,ωi(k))反映了R幀信號在子頻帶i中頻率ωi(k)處的長時譜熵,它由R幀長度時間分析窗的歸一化能量譜(n,ωi(k))計算得到,(n,ωi(k))的計算公式如式(4)和式(5)所示。
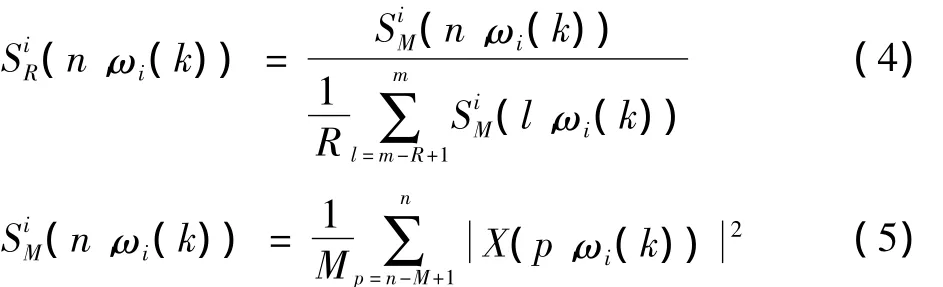
式中:(n,ωi(k))是子頻帶i最近M幀信號的平均能量譜;X(p,ωi(k))為第p幀信號在子頻帶i中頻率ωi(k)處的短時傅里葉變換系數。
計算出每個子頻帶的LTSV特征Lix(m)后,可以將這些特征參數組合為一個N維的特征向量Lm,用于第m幀語音信號的VAD處理。作為提取子帶LTSV特征的參數,子頻帶數量N與參數K,R,M都會影響所提特征的性能,從而獲得不同的VAD結果。根據文獻[5]的實驗研究,本文選取參數R=30,M=10,并設置子頻帶數量N=16(參數K可由N計算得到)。
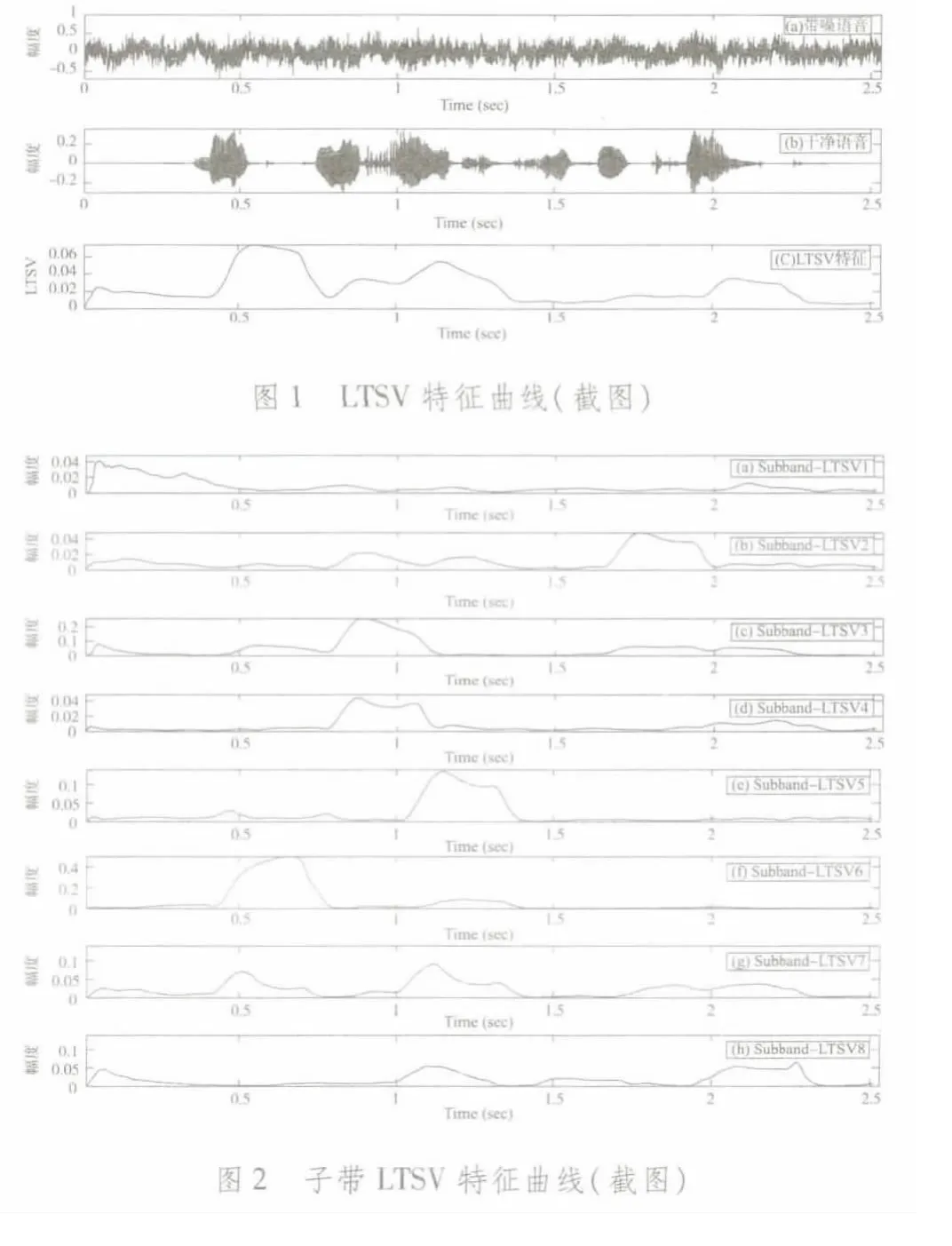
圖1為文獻[5]中LTSV特征曲線圖,圖1中a為帶噪語音信號(SNR=-10 dB),b為干凈語音信號。從圖1可以看出,LTSV特征具有較好的穩健性,但在信號的局部區域,LTSV特征值較小,難以區分出語音幀,可能導致VAD錯誤。圖2為相同帶噪語音信號的子帶LTSV特征曲線,圖2中(a)~(h)分別對應子帶1~8。從圖2可以看出,各子帶LTSV特征都在一定程度上反映了語音信號的活動情況,具有LTSV特征所缺乏的信息。例如圖1中c的LTSV特征在信號1.5~2 s區間中取值較小,難以檢測出語音活動情況,但圖2中(b),(c),(g),(h)中相同區間的子帶LTSV特征取值較大,區別明顯,可以檢測出語音活動情況。
2 語音活動檢測
基于子帶LTSV特征,可以建立語音模型和非語音模型(Non-speech Model),然后利用這兩個模型對提取的子帶LTSV特征向量進行判決,獲得VAD結果。本文算法采用了混合高斯模型(GMM)建立語音模型和非語音模型,利用兩個模型的概率比作VAD判決,算法的示意圖如圖3所示。其中,兩個GMM模型一般采用離線方式由已標注數據預先訓練得到,但本文算法采用了在線訓練方式,由每一句話(A Utterance)的部分數據在VAD判決前實時訓練獲得。
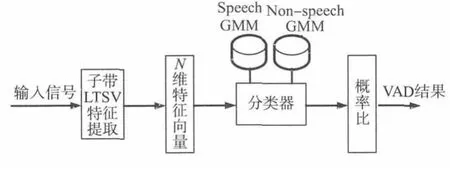
圖3 本文VAD算法示意圖
本文所提VAD算法的處理步驟如下:
1)從輸入的帶噪語音信號s(n)中提取所有幀的子帶LTSV特征向量,組成特征向量集合Lx,其中每一幀的子帶LTSV特征向量為xm(xm∈Lx)。
2)采用譜減算法[11]為輸入的語音信號s(n)降噪,獲得增強語音信號xclean。
3)利用增強語音信號xclean,計算每一幀的短時能量Em,并將部分最大短時能量對應的信號幀作為語音幀(固定百分比,本文取10%最大短時能量幀為語音幀),將輸入信號的初始20幀作為非語音幀,分別用于訓練語音GMM和非語音GMM兩個模型。
4)對于帶噪語音信號的每一信號幀,計算兩個
GMM模型的概率輸出,取概率比值用于VAD判決,即lg(p(xm|GMMspeech))≥lg(p(xm|GMMnon-speech))且Em≥θmin時,為語音幀,VAD 結果標注為1。其中,θmin為預先設置的最小能量約束。
5)考慮到相鄰幀之間的關聯性對于檢測語音的存在非常重要,對步驟4)的VAD結果加以修正,將兩語音段間的非語音段(VAD標注為0的相鄰幀)小于500 ms的轉化為語音幀。
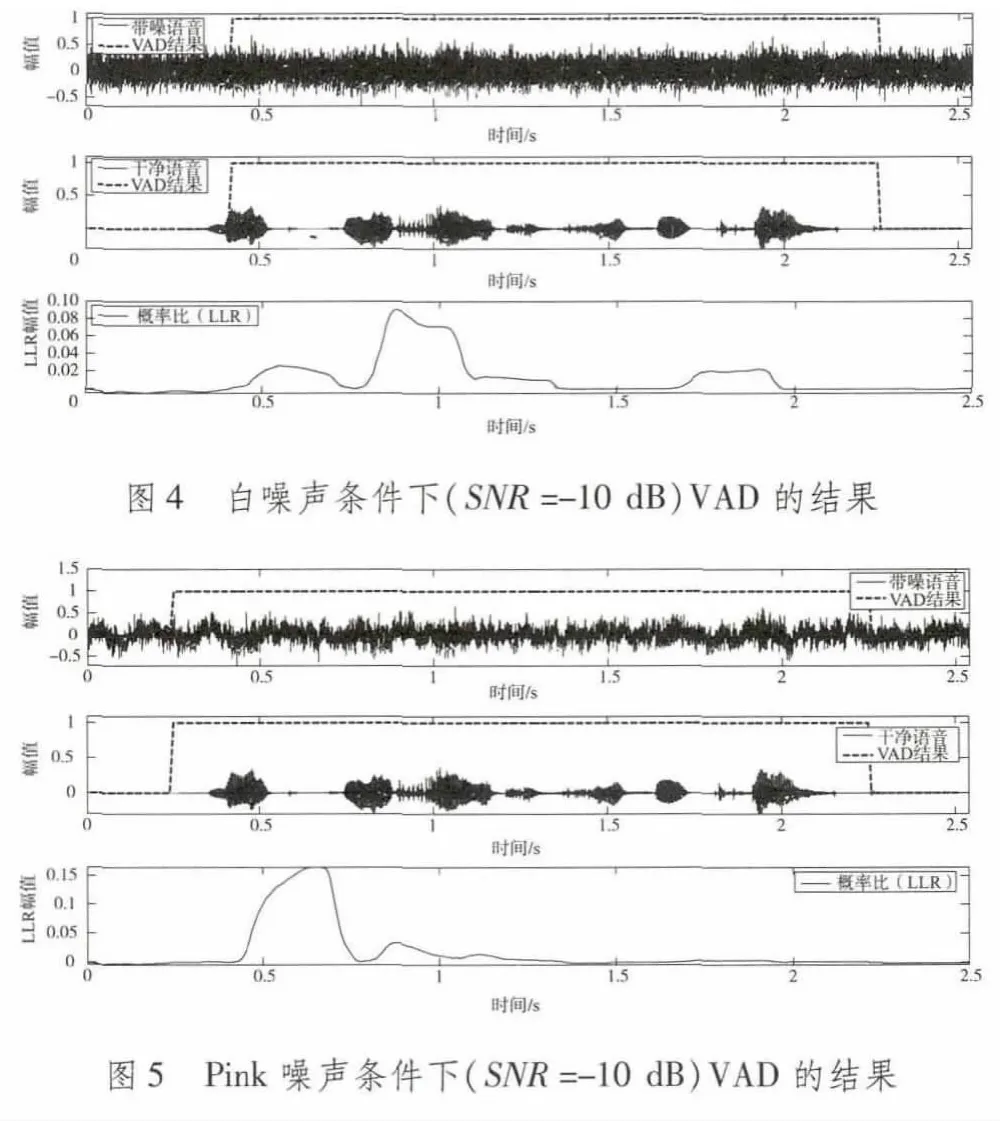
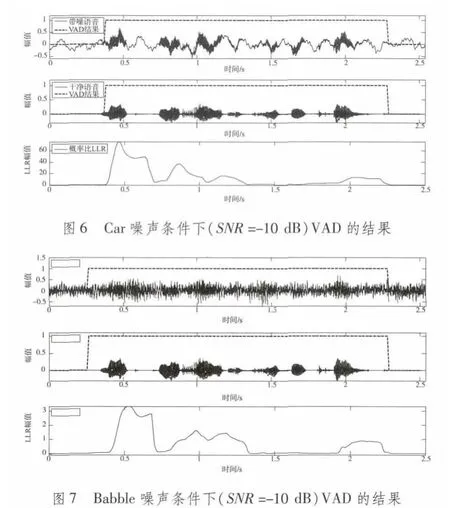
本文VAD算法在不同噪聲條件下的實驗結果如圖4~圖7所示,子帶LTSV特征具有較好的穩健性,算法在信噪比為-10 dB的嘈雜環境中仍能較準確地檢測出語音的活動情況,并不同信噪比條件下以及白噪聲、Pink噪聲、Car噪聲及Babble噪聲等多種噪聲條件下均能取得不錯的效果。與本文VAD算法相比,基于短時能量的VAD算法[1]在低信噪比情況下將完全失效。
3 實驗仿真與分析
3.1 VAD算法的性能評估
為驗證算法的有效性,在不同噪聲類型和信噪比的條件下,實驗采用本文算法(SBLTSV_VAD)與基于短時能量的VAD算法(Eng_VAD)[1]、基于MFCC特征參數的VAD算法(MFCC_VAD)[12]、基于 LTSV特征的 VAD算法(LTSV_VAD)[5]進行了比較。實驗所用的干凈語音數據為美國德克薩斯大學達拉斯分校的NOIZEUS數據庫[13]。該數據庫的clean數據集采集在安靜實驗室環境下,采樣頻率為8 kHz,由6名說話人(包括3名男性和3名女性)錄制的30句英文短語組成。這些數據集的語音信號起始點和終止點進行了人工標注,以作為VAD實驗的參考值。實驗中語音信號被分為30 ms的幀,相鄰幀有2/3重疊,即幀移為10 ms。實驗所用的帶噪語音是由人工加入噪聲到干凈語音中產生,信噪比范圍從-10~20 dB,噪聲類型包括有白噪聲、Pink噪聲、Car(汽車車廂內)噪聲、Babble噪聲等。實驗比較了不同信噪比(-10 dB,0 dB,10 dB)下,疊加各種噪聲后的帶噪語音信號采用VAD算法后,其VAD結果的誤檢率(即錯誤率),實驗結果如表1所示。
由于語音的起止點在連續語音情況下不能完全準確地檢測出,例如背景噪聲的誤檢以及語音中輔音的漏檢,因此不能依據一句語音或一個錯誤來判定VAD檢測性能,需要按如下評價參數進行了VAD算法的性能評比
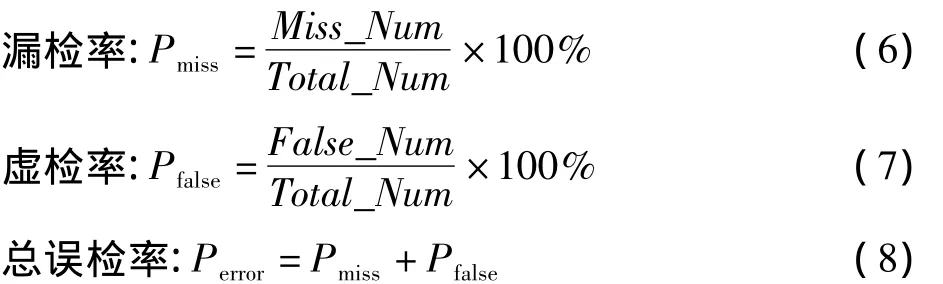
式中:Total_Num為總的語音幀數;Miss_Num表示語音幀被誤檢為非語音幀的幀數;False_Num表示非語音幀被誤檢為語音幀的幀數。本文將總誤檢率作為VAD算法性能比較的依據。
從表1中的實驗結果可以看到,本文提出的SB LTSV_VAD算法與文獻[5]的 LTSV_VAD在SNR=-10dB的環境下依然有效,其誤檢率明顯低于傳統的Eng_VAD算法以及采用MFCC特征的MFCC_VAD算法,說明LTSV特征對各種類型噪聲具有較好的穩健性。對比LTSV_VAD與本文SBLTSV_VAD算法的實驗數據可知,本文算法提取并綜合利用了各子頻帶的長時特征信息,可取得更優的檢測性能。
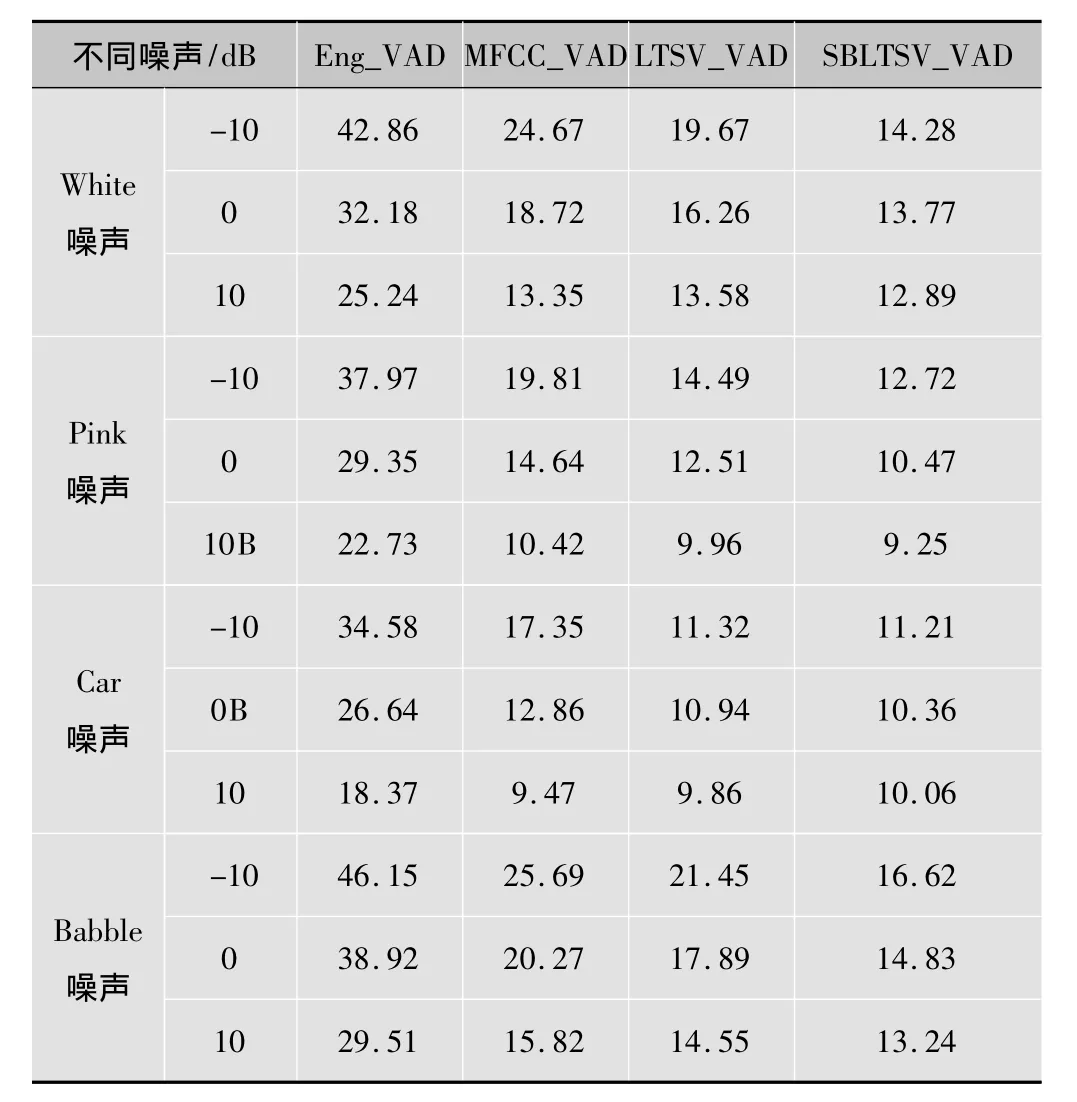
表1 不同噪聲環境下VAD算法性能比較
3.2 VAD算法對語音識別性能的影響
為進一步評估VAD算法的性能,本文將SBLTSV_VAD算法應用于語音識別系統。語音識別實驗的數據集采用的是英文數字串,這些數字串的長度從1~8不等,為連續語音。實驗數據集分為4類,采集自4種不同速度(空檔、30 m/h、55 m/h和變速)的汽車車廂內,采樣率為8 kHz(16 bit),分別標識為SET01~SET04,每類數據集包含有數字串約5 000個。語音識別系統采用了HMM模型,其特征維數為26維,特征包括MFCC參數和短時能量,HMM模型由大量真實環境下的語音數據訓練得到。本文實驗比較了無VAD、采用Eng_VAD算法[1]和本文SBLTSV_VAD算法情況下數字串集的識別性能,實驗結果如表2所示。
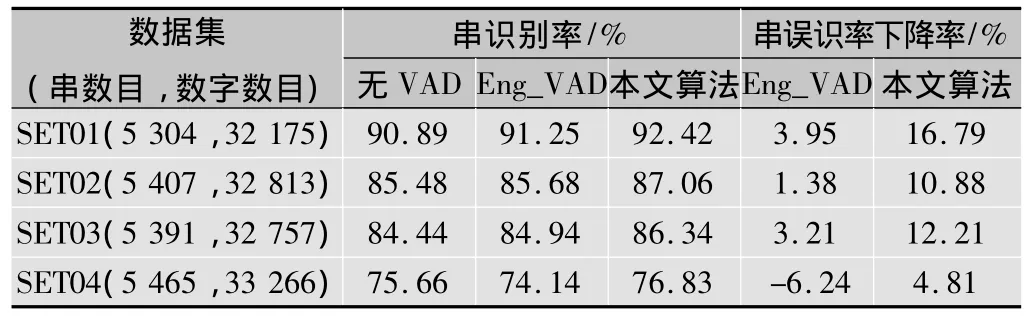
表2 數字串識別性能比較
從表2中的實驗結果可以看出,語音識別系統使用VAD算法后數字串的識別率都有一定程度的提高,但與采用短時能量的VAD算法相比,本文算法性能更優,使識別率的提高更為明顯。尤其對于SET04數據集,背景噪聲的影響使采用短時能量的VAD算法出現了嚴重的錯誤,反而導致識別率下降,而本文算法則在噪聲環境下具有更好的穩健性,在SET04數據集下的識別率仍有一定的提高。由于SET01,SET02與SET03的信噪比相對比較穩定,因此本文算法在前3種條件下效果更好,SET04的背景噪聲存在變化,本文算法僅取得了4.81%的誤識率下降。
4 結論
本文提出了一種采用子帶長時信號變化特征的穩健語音活動檢測算法,在頻域將語音信號分解為幾個不重復的子頻帶,分別提取這些子頻帶的長時信號變化特征,然后在線建立語音和非語音模型進行VAD處理。實驗結果表明,本文算法可有效提高低信噪比環境下語音活動檢測的性能,且對不同的噪聲均具有很好的魯棒性,適用性很強。在語音識別系統中的實驗表明,本文算法能有效提高噪聲環境下的語音識別率。在下一步的研究工作中,短時特征與長時特征的綜合應用,以及各類機器學習算法的引入將是研究的重點。
:
[1] GANAPATHIRAJU A,WEBSTER L,TRIMBLE J,et al.Comparison of energy-based endpoint detection for speech signal processing[C]∥Proc.IEEE Southeastcon'96 Bringing Together Education,Science and Technology.Tampa,FL:IEEE Press,1996:500-503.
[2] PRASAD R,SARUWATARI H,SHIKANO K.Noise estimation using negentropy based voice-activity detector[C]∥Proc.47th Midwest Symposium on Circuits System.[S.l.]:IEEE Press,2004(2):149-152.
[3] RAMIREZ J,SEGURA J C,BENITEZ C,et al.Efficient voice activity detection algorithms using long-term speech information[J].Speech Communication,2004,42(3):271-287.
[4] SHUYIN Z,YING G,BUHONG W.Auto-correlation property of speech and its application in voice activity detection[C]∥Proc.First International Workshop on Education Technology and Computer Science(ETCS’09).Wuhan:IEEE Press,2009(3):265-268.
[5] GHOSH P K,TSIARTAS A,NARAYANAN S.Robust voice activity detection using long-term signal variability[J].IEEE Tran.Audio,Speech,and Language,2011,19(3):600-613.
[6] YANNA M,AKINORI N.Efficient voice activity detection algorithm using long-term spectral flatness measure[J].EURASIP Journal on Audio,Speech,and Music Processing,2013(21):1-18.
[7] SOHN J,KIM N S,SUNG W.A statistical model-based voice activity detection[J].IEEE Signal Processing Letter,1999,6(1):1-3.
[8]蔡黎.一種基于本原多項式的LDPC碼構建新算法[J].電訊技術,2011(12):51-54.
[9] FUJIMOTO M,ISHIZUKA K,NAKATANI T.Study of integration of statistical model-based voice activity detection and noise suppression[C]∥Proc.9th Annual Conferene of the lnternational Speech Communication Asso ciatim.Brisbane,Australia:[s.n.],2008:2008-2011.
[10] FUKUDA T,ICHIKAWA O,NISHIMURA M.Long-term spectrotemporal and static harmonic features for voice activity detection [J].IEEE Journal of Selected Topics in Signal Processing,2010,4(5):834-844.
[11] GERKMANN T,HENDRIKS R C.Unbiased MMSE-based noise power estimation with low complexity and low tracking delay[J].IEEE Trans.Audio,Speech,Language Processing,2012(20):1383-1393.
[12]吳愚,方元.基于語音存在概率的語音活動檢測方法[J].電聲技術,2009,33(8):25-32.
[13] LOIZOU P C.Speech enhancement:theory and practice[M].Boca Raton,FL:CRC,2007.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年11期)2018-08-04 03:25:42
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
