計算機程序抄襲檢測系統的設計方案研究
2014-09-30 06:59:04張淑娟
吉林廣播電視大學學報 2014年4期
張淑娟
(云南經濟管理職業學院,云南 昆明 650106)
一、計算機程序抄襲檢測系統相關技術理論概述
計算機程序抄襲檢測系統的研發是為了進一步遏制越來越猖狂的抄襲現象,為良好的學術氛圍構建一個檢測平臺。當前已經有諸多的計算機程序抄襲檢測系統不斷被研發出來,各種各樣反抄襲手段也隨之而出,因此在對計算機程序抄襲檢測系統進一步研發的過程中,我們追求的不僅僅是能夠檢測相應的抄襲文檔,還應該從性能、準確度以及檢測效率等各個方面提升反抄襲檢測系統的實用性。衡量一個反抄襲檢測系統優劣的標準諸多,但是關鍵還在于程序的算法設計方面。我國現有的諸多計算機程序抄襲檢測系統都是針對中文字符來設計相應算法的,而國外較為先進的計算機程序抄襲檢測系統卻是在英文環境之下進行開發的,難以為我國學術檢測環境所應用。針對中英文在我國學術界的通用性,我國需要在此環境基礎之上研發出相應的計算機程序抄襲檢測系統。當前計算機程序抄襲檢測系統相關核心技術主要有如下幾種:
一是模擬匹配技術,模擬匹配技術在信息技術安全、信息檢索以及數據挖掘等方面已經得到了廣泛的運用,同時當前我國計算機程序抄襲檢測系統也是在模擬匹配技術支持基礎之上實現的,一個良好的計算機程序抄襲檢測系統需要有一個精確的算法作為支撐,與此同時模擬匹配技術可以分為單模式和多模式匹配算法,其中單模式匹配算法指的是從在長度為N的字符串Y中找到與長度為M的字符串X有一定相似度的子串,如果有相符的字串就會相應的位置,如果沒有找到相似的字串就會返回到零;其中多模式匹配算法指的是將字串集合P=(P1,P2,……P3),分別于字符串Z經過相匹配分析得到相似的字符串并回到相應的位置,如果沒有找到相似的字串就會返回到零,多模式匹配算法與單模式匹配算法有所不同,多模式匹配算法可以同時計算多個字符串并進行匹配計算,可以大大提升計算機程序抄襲檢測系統的檢測效率和使用性能[1]。
二是相似度算法,隨著當前我國計算機程序抄襲檢測系統的日益完善,抄襲者開始不斷變換抄襲手段,使用同義詞替換、添加刪除相應的字段、調換字符串之間的順序等方式來逃避反抄襲檢測系統,對此可以使用相似度算法原理來對計算機程序抄襲檢測系統進行進一步的優化升級。相似度算法從一定程度上來說也是模式匹配算法中的一種算法模式,是對不同字符串中相似程度的計算方法,文本相似度計算方法主要有字符匹配相似度法、集合模型的相似度計算法、空間向量模型相似度計算方法等。
三是中文分詞技術,在對文本抄襲進行反抄襲檢測時,如果利用整句的方式對相關關鍵信息進行匹配相似度計算等,可能會使檢測過程極為復雜且有檢測信息片面等問題,從而大大降低了計算機程序抄襲檢測系統的檢測效率,對此,可以使用中文分詞技術在對檢測文本進行合理化分割的前提之下提升計算機程序抄襲檢測系統的準確度和性能。中文分詞技術主要包括了字符串匹配分詞技術、統計方法的分詞技術以及知識理解的分詞技術等方法[2]。
二、計算機程序抄襲檢測系統需求及功能分析
1.計算機程序抄襲檢測系統中的核心技術
綜合前人的研究以及本文對反抄襲程序的研究可以知道計算機程序抄襲檢測系統設計的核心技術在于程序抄襲檢測技術,從上述分析可以知道程序抄襲檢測技術的重點在于相似度計算技術的選擇與應用,相似度計算技術在計算機程序設計中的應用指的是運用計算機實現對不同兩個程度文檔、代碼等各個方面的相似度匹配計算,這種方法已經被廣泛地應用到數字技術、學術領域、軟件工程代碼管理以及知識產權保護等各個領域中,可見相似度計算技術在計算機程序抄襲檢測系統的運用是至關重要的。但是在進行計算機程序抄襲檢測系統設計開發時首先需要明確系統的需求分析和相應的功能分析[3]。
2.計算機程序抄襲檢測系統需求及功能分析
(1)計算機程序抄襲檢測系統使用需求分析
比如在學生提交所創作的電子文檔類型的程序設計作業時,在沒有對此實行反抄襲軟件檢測之前,教師難以從中了解到提交的這些電子文檔類型程序設計作業哪些地方可能存在抄襲現象,因此在進行計算機程序抄襲檢測系統設計開發之前需要將已有的所有文檔進行相互對比匹配檢測,最終可以給出不同程序文檔之間的相似度匹配計算結果,一般都會以百分比的形式給出相應的似度匹配計算結果。與此同時需要考慮到計算機程序抄襲檢測系統使用者的使用習慣和邏輯性思維,這就需要在完成不同程序文檔之間的相似度匹配計算結果之后,對這些相似度計算結果進行一個方向性的排序,通過上述的計算分析處理就可以得到相似度最大的程度文檔,以此可以綜合性地高效、準確地確定存在抄襲現象的電子程序文檔。
(2)計算機程序抄襲檢測系統使用功能分析
從上述分析可以知道,在進行計算機程序抄襲檢測系統開發設計時需要保障有如下幾個方面的功能,以滿足反抄襲檢測系統的應用需求:
一是,選取并按照一定的順序羅列出將要被計算機程序抄襲檢測系統進行檢測的程序文檔文件名以及對應的文檔路徑等,對于這些羅列的程序文檔可以進行后續的添加和刪除,后續可以根據分析需求將指定的程序文檔進行部分刪除或者全部清空處理等[4]。
二是,開發設計具備對程序文檔進行相似度計算的功能。首先需要對這些將要被計算機程序抄襲檢測系統進行檢測的程序文檔進行相互匹配計算,即將所有文檔進行相互的配對分析,然后在此基礎之上對這些程序文檔之間的相似度進行有效計算,最后將上述程序文檔之間的相似度計算結果按照從高至低的順序進行一一排列。在此將相似度匹配計算方法運用到計算機程序抄襲檢測系統之中,可見這是該系統的核心功能所在。
三是,對上述程序文檔相似度較高的對象進行進一步的細化對此處理分析。由于相似度較高的程序文檔則說明這些程度文檔具備較高抄襲度,因此在上述相似度匹配計算結果基礎之上需要對其進行進一步的細化分析,從而準確地確認這些程序文檔是否存在抄襲現象,可以將兩個相似度最高的程序文檔進行深入對比分析,并顯示出相同部分來確定。對于相似度匹配計算結果較低的程序文檔可以直接確定這些程序文檔不存在相互抄襲的現象。
三、計算機程序抄襲檢測系統設計方案
從上述分析可以知道我國計算機程序抄襲檢測系統存在一定的可挖掘空間,面臨中英文環境的沖擊以及反抄襲檢測系統的功能需求,本文將在此基礎之上提出適用于中英文背景之下的計算機程序抄襲檢測系統研發技術工具,該反抄襲檢測系統設計的目的在于可以有效對程度文檔中的中英文字符進行合理分割,進而實現相似度匹配的計算,最終設計出相似度匹配過程中的模糊匹配、分割匹配等計算模式,從而高效準確地對中英文字符文檔進行檢測,并進而根據所檢測的各個層次的字符串按照規定的方式進行相似度計算,為抄襲現象的判斷提供可靠依據。與此同時,計算機程序抄襲檢測系統還需要為數據庫提供中英文庫存文檔的存儲、添加刪除、信息資源庫的文化更新以及用戶信息資源的維護更新、文檔篩選檢測等方面的功能。據此可以對計算機程序抄襲檢測系統的功能模塊進行對應的開發設計[5]。
計算機程序抄襲檢測系統的功能模塊設計所需要服務的對象主要包括幾個層面:
一是,計算機程序抄襲檢測系統面向系統用戶的功能設計,需要根據用戶的需求提供用戶注冊功能、用戶個人信息資源維護、信息更新以及修改完善、用戶會員登錄、信息資源程序文檔的提交、檢測結果的查詢、操作處理等方面的功能。
二是,計算機程序抄襲檢測系統面向系統管理員的功能設計,需要根據系統管理員的需求提供信息資源庫中英文程序文檔的添加刪除、信息資源維護、信息資源信息表的及時更新等多個方面的操作處理功能,除此之外,還可以為系統管理員提供相關數據庫的構建管理和系統用戶操作處理等方面的服務功能。
三是,計算機程序抄襲檢測系統檢測運行實現的過程如下:首先系統管理員通過輸入相應的口令登錄到檢測系統管理平臺,然后將所要被檢測的中英文文檔添加進入相應的信息資源庫,以此方便系統用戶能夠便捷地進行程序文檔的檢測。系統用戶在完成系統平臺注冊登錄之后便可以提供將要被檢測的程序文檔,計算機程序抄襲檢測系統將用戶的程序文檔與信息資源庫中的程序文檔進行相似度匹配計算之后,可以得出相似度較高的程序文檔。最后將這些相似度較高的程序文檔進行進一步的兩兩對比深入分析,將最終結果通過計算機程序抄襲檢測系統顯示反饋給系統用戶。
綜上所述,可以將計算機程序抄襲檢測系統開發設計為文檔注冊模塊、篩選、抄襲檢測以及后臺信息資源維護模塊等幾個重要的模塊,如圖1所示,同時每一個模塊相對獨立地承擔相應的功能,共同為反抄襲檢測系統服務,從而為學術領域等提供最佳的反抄襲系統檢測服務。
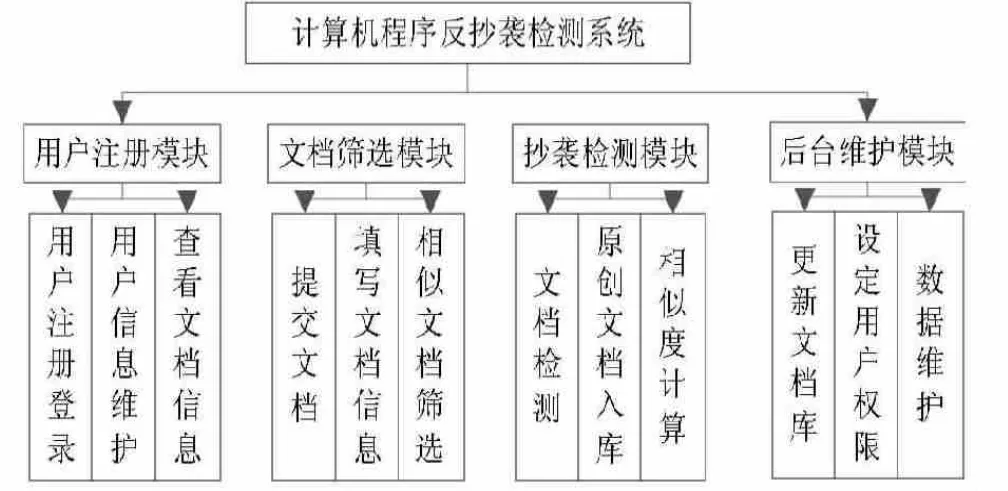
圖1 :計算機程序抄襲檢測系統模塊方案
[1]房德安.計算機程序抄襲檢測系統的設計方案分析[J].黑龍江科技信息,2013,(2):53-54.
[2]李雅慧,郭婷,孫麗穎.一種基于高頻詞和段落匹配的論文抄襲檢測系統設計[J].現代經濟信息,2009,(11):158-159.
[3]胡正軍.程序代碼相似度檢測方法研究及應用[D].長沙:中南大學,2012.
[4]李旭東.程序相似度計算技術及其在教學中的應用[J].軟件導刊(教育技術),2010,(4):111-113.
[5]祁俊,王曉英.抄襲檢測系統對計算機類電子作業的影響分析[J].價值工程,2012,(8):76-79.
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
人大建設(2019年12期)2019-05-21 02:55:44
瞭望東方周刊(2017年42期)2017-12-05 18:49:38
中華手工(2017年2期)2017-06-06 23:00:31
環球時報(2017-03-30)2017-03-30 06:44:45
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中國衛生(2015年3期)2015-11-19 02:53:32
中外會展(2014年4期)2014-11-27 07:46:46
