語音技術在少數民族語言的應用研究?
2014-11-02 08:36:34達瓦伊德木草木合亞提尼亞孜別克吾守爾斯拉木
新疆大學學報(自然科學版)(中英文) 2014年1期
達瓦伊德木草,木合亞提尼亞孜別克,吾守爾斯拉木
(1.新疆維吾爾自治區多語種技術重點實驗室,新疆烏魯木齊830046;2.新疆大學信息科學與工程學院,新疆烏魯木齊830046)
0 引言
據科學家分析,人類說話的聲音能夠反映一個人的生理、情緒、感情、健康程度、受教育程度、居住以及所處的社會環境等諸多相關聯的特征,并且人類說話的聲音還跟遺傳因子(DNA)有關.因此,科學上不僅常常用有聲語言的聲學參數來觀察、辨別一個人的身份,而且還可以利用聲音或者話語方式操作計算機,實現高效率地通信.目前,利用聲音的應用系統開發很廣泛,比如:聲紋判別、口語翻譯手機、手寫或者印刷物自動發音的語音合成、利用聲源震動信息的醫療診斷、自然災害預測及公共安全電話-網絡語音監控等新技術[1~3].
新疆不僅是多語種地區,而且面向中亞、歐洲,還是重點開發的貿易口岸地區,由此基于多語言信息處理的通信應用研究顯得迫在眉睫,并貫穿到許多領域.本文在近年來語音工程技術研究成果基礎上進行擴展性應用研究.例如:在醫院門診室安置一個血壓計般大小的民-漢語言會話翻譯裝置可方便各民族百姓看病,省事、省時又省錢;在電話-網絡通話終端設置語音監控裝置保障地區的穩定安全;通過多語言語音查詢導向系統提高旅游業服務質量等.
自然言語交際及話語傳遞和接收過程中,存在巨大可變性,但是人類卻能非常魯棒性地理解言語交際.研究如何將言語聲學特性的可變性與言語知覺的不變性融合,是當前人機接口技術走向應用被關注的問題.這在語音接口技術研究中,如何高效地抽取有聲語言的聲學特征建模是一個高難度研究任務.先行相關研究靠海量級的語音語料探索建模規律,而且側重于英語、漢語等大語言[4,5].近年來,新疆維吾爾自治區多語種技術重點實驗室以維吾爾語、哈薩克語、柯爾克孜語及蒙古語等少數民族語言為研究對象,在語料缺乏、多復雜環境的情況下,更好的融合先行技術,挑戰語音技術的應用研究.
1 說話人識別
說話人識別實際上是模式匹配問題.其基本原理是將待識別目標說話人模型特征與預先訓練好的模板進行匹配,根據匹配距離或最大概率似然度判斷目標說話人是庫中哪一位或者判斷是否為被申明的說話人[6].
1.1 特定人開集說話人識別原理
本文構造的基于概率統計GMM模型文本無關(Open set)說話人識別系統如圖1所示,其工作原理如下:1.首先對錄制的n個連續聲源進行切分、端點檢測、分類、(Seg/ADC/VAD)等預處理,然后對有聲話語按發話人編碼,排序生成語音文件.wav(i=1,2···,U;k=1,2,···,M),作訓練數據[7,8].其中k為發話人數,i為第k個人話語U(Utterance).2.對話語Si.wav,每隔20~40ms(毫秒)間隔乘短時間Hamming幀系數,進行聲譜到頻譜分析,生成10~50維特征向量.然后,把分析幀左移8~20ms,繼續上述分析,直到全話語分析完畢.最后獲得每人話語時間序列特征向量X=(x1,x2,···,xT)(簡稱特征量).3.對于各目標人特征量,通過EM Training(Expectation maximization)學習,生成N個目標人GMMs模型(λ1,λ2,···,λk,···,λN),即說話人聲學樣本(稱為目標人聲紋登錄).建模方法除了高斯混合GMMs(Gaussian Mixture Model)方法之外,還有量化距離碼本(codebook)法、SVM(Support vector machine)方法、i?vector方法等[9].可以根據需求及規模選用.4.在識別階段,如圖1所示GMMs方法中,利用待測話語特征量與說話人樣本λk進行最大似然度(maximum likelihood rate ML)匹配,計算得分,選取最接近樣本λi作為識別結果.
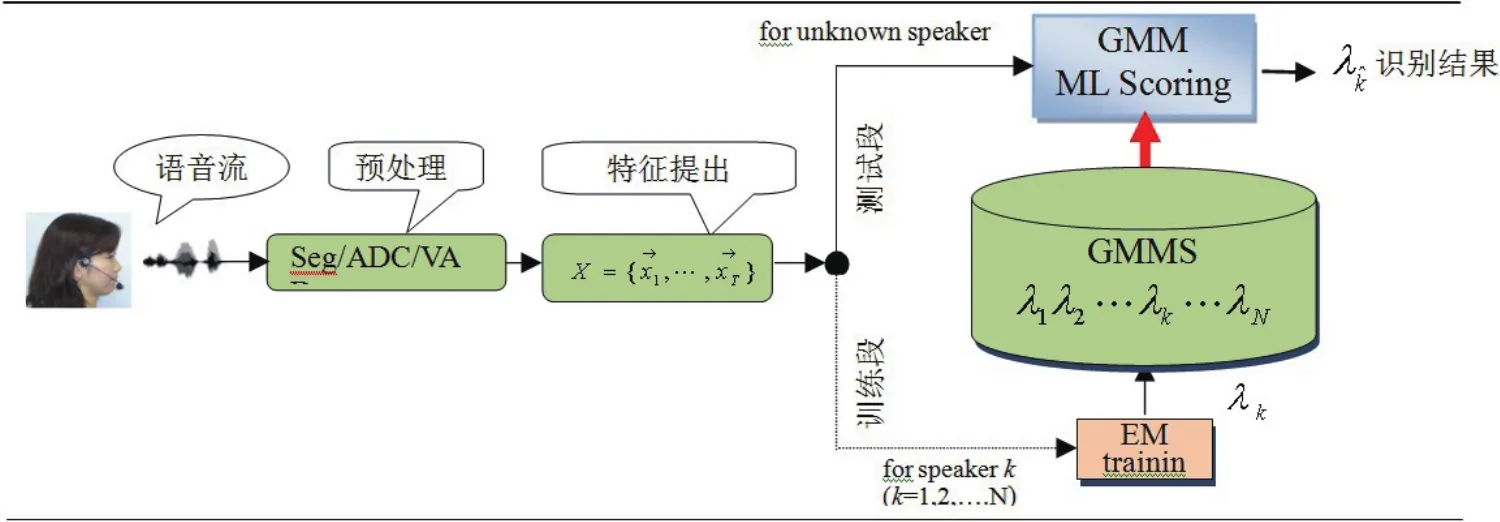
圖1 基于GMM說話人識別系統訓練和測試構造原理
1.2 GMM建模法
GMM模型利用多維概率密度函數對語音信號進行建模.由一個密度為M的高斯分量密度的和給出,即
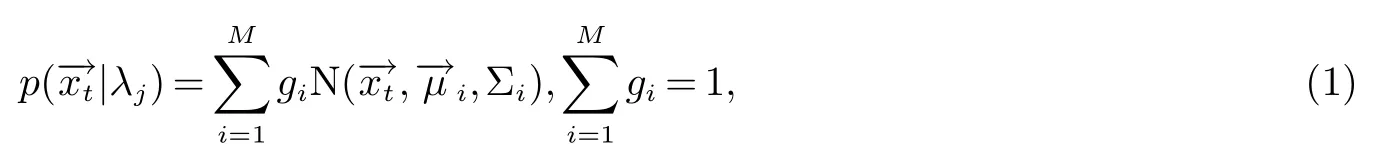
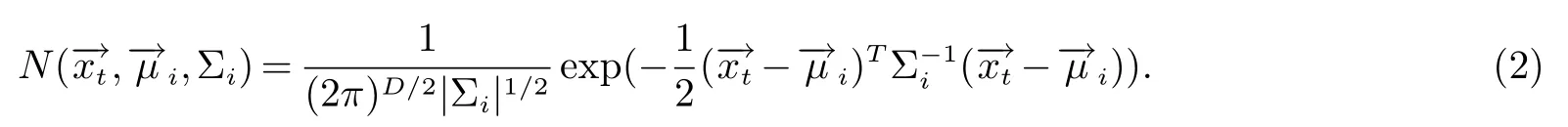
其中為第j個話者話語,在t幀抽取出的特征量,為高斯混合參數,即每個話者GMM模型,gi表示每個高斯分量的權重系數,為均值向量,而Σi是對角協方差矩陣.利用EM算法可以估計式(1)中高斯混合模型參數λj.由最大后驗概率給出的最終識別結果簡化為:

為便于計算,將上式(3)用對數似然度表示,即:

1.3 基于SVM的說話人識別
SVM(即支持向量機)算法用于解決二分類問題,然而對于有N個目標人的說話人識別系統,就要利用SVM方法解決多類分類問題.一般先對N個目標人話語進行訓練并分類,目標識別人數越多,在求解過程中的變量就越多,計算量就越大,而系統的實時實用性較低.目前,多數說話人識別的研究將一個多類分類問題轉換為多個二分類問題討論,通過組合多個二分類支持向量機實現多類分類[10].這種方法主要有兩種:一對一(one-against-one)組合算法和一對多OAA(one-against-all)組合算法,其中OAA SVM算法易于實現.下面用圖2和圖3介紹OAA SVM算法基本思路.
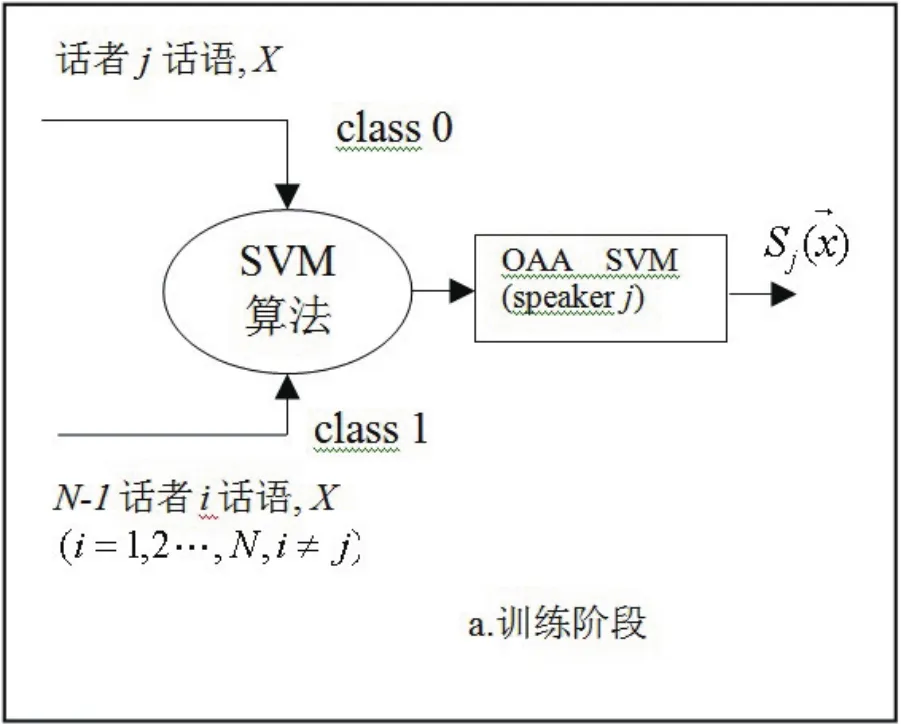
圖2 SVM法訓練OAA SVM模型
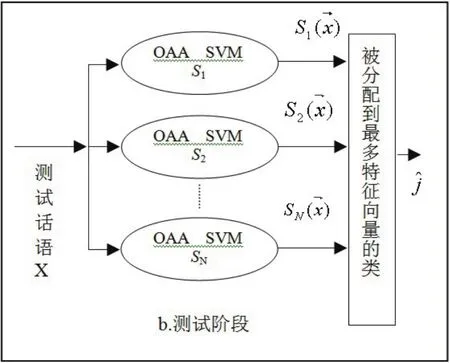
圖3 SVM法未知話者的識別過程
①訓練階段(見圖2):將訓練集中每個話者話語作為一類,例如:將話者j(j=1,2···,N)的語音信號特征量X作為class 0輸入,而剩余N-1話者話語全作為class 1輸入,經過SVM二分類器訓練生成說話者j的OAA SVM模型Sj().最終訓練出N個OAA SVM模型.
②測試階段(見圖3):對待測未知的話語,提取語音信號特征向量,依次輸入到N個OAA SVM模型中做二類分類.最后統計待測語音各幀特征量被分配到最多的類,則將此類作為最后識別結果.
2 語音識別技術
語音識別技術可以把話筒輸入的話語轉換為文本輸出(speech-to-text),如果具備高精度語音識別器,那么將來操作手機或計算機直接用話筒即可,不再用鍵盤不用文字知識.連續語音識別器CSR(Continuous speech recognition)由:上述第2章介紹的預處理階段,此外還包括聲學模型AM(Acoustic model),語言模型P(W)以及識別單元(Decoding)組成(見圖4).各單元的工作原理如下:
①訓練階段:
從N個話者錄制的語音數據中,提取話語特征量;再利用這些語音特征量參數,訓練音素或詞單元的聲學模型AM(Acoustic Model),保存到模板庫中.
針對識別語言收集整理大量的文本數據,利用統計學習訓練詞與詞的連接關系得到N-gram語言模型P(W),保存到模板庫中.
②識別階段:
對待識別語音信號進行聲學分析得到語音特征量生成測試數據,再與參考模板AM和P(W)匹配計算,利用Bayes判別準則,將匹配分數最高的參考模板,作為Decoding識別結果W?[11~13](見式5).其中,W=(w1,w2,···,wN)為長度為N的詞序列,F=(x1,x2,···,xT)為聲學特征量,而P(W|F)是后驗概率.
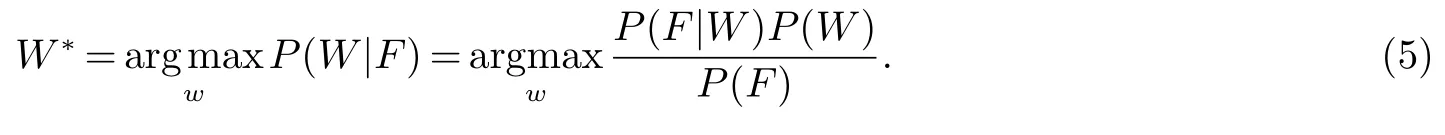
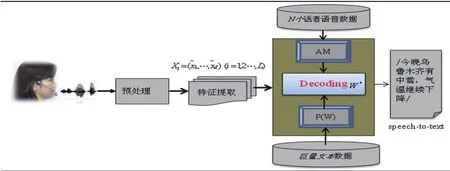
圖4 連續語音識別原
3 語音翻譯技術
3.1 語音翻譯技術及其應用
不同民族的人用自己的語言交談,不通過第三個人翻譯,而直接利用計算機翻譯的過程叫做語音翻譯S2S(speech to speech).目前不少研究機構研發了多語種-多功能語音翻譯應用軟件,并投入市場試用.如:日本國際電氣通信基礎技術研究所ATR(Advanced Technology Research)及NICT(National Institute of Information and Communication Technology)研發的手提式旅游-商務多語言(日-中,中-英或其他語言)雙向翻譯終端機;通過網絡交換方式,實現遠距離會話翻譯的手機;東芝中國研發中心開發的中-英雙向語音翻譯系統;Google開發的網上語音翻譯系統等[14].圖5及圖6分別顯示本文作者在日本NICT參與并研發的多語言雙向口語翻譯終端機及演示圖.本系統對旅游(特定任務)會話的實時翻譯正確率可達86%左右,已滿足一般應用需求.
3.2 語音翻譯原理
本文探討醫療衛生會話翻譯系統的基本原理如圖7所示.系統除了通過上述的語音信號的預處理,聲學分析特征提取之外,還包含連續語音識別CSR,機器翻譯(Machine Translation)及語音合成(Synthesize)等技術環節.該系統綜合應用了上述多領域相關技術.系統工作原理敘述如下:
(1)語音識別過程:假如,一名民族患者(一位維吾爾族大叔),對著翻譯器話筒說一段“/doctor,kozambir narsini yahxi kornayd/”,這段語音經過系統自動分析后,輸入到連續語音識別單元(Speech Recognition),經識別器識別輸出為維吾爾語文字串“doctor,kozam bir narsini yahxi kornayd”.
(2)機器翻譯過程:機器翻譯單元(Translation)對語音識別器的輸出結果進行維-漢文的自動翻譯,將輸出一段“醫生,我的眼睛看不見”的漢語文本.
(3)語音合成過程:對于機器翻譯輸出的文本“醫生,我的眼睛看不見”,語音合成單元將實施文本轉換語音的任務,使得醫生將聽到“/醫生我的眼睛看不見/”一段語音.由此系統實現了語音對語音的翻譯.由于本系統能夠實現雙向翻譯,即醫生說的話反過來患者也能用自己的語言收聽,從而完成醫-患者會話翻譯.

圖5 NICT開發的語音翻譯終端

圖6 漢-英語音翻譯終端演示(NICT)
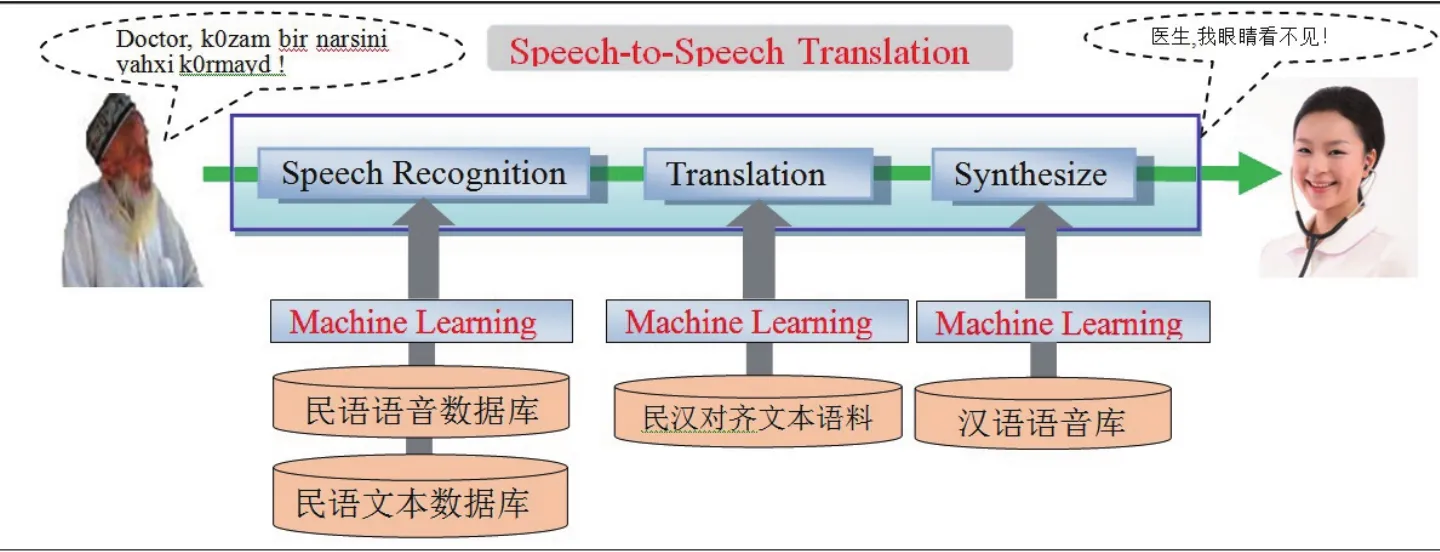
圖7 本研究提案醫院門診用語音翻譯系統結構圖
4 實驗測試
4.1 GMM-UBM-SVM混合開集說話人識別實驗
考慮到待識別人數多,系統實用環境噪音復雜等因素,本課題致力于提高開集說話人性能研究,提出(如圖8所示)一種新的開集說話人識別方法,即基于GMM-UBM-SVM混合模型識別方法.本系統充分發揮兩種分類方法GMM和SVM各自優勢,即GMM模型能較好地描述類別內部的相似性,而SVM模型有優秀的分類能力.系統工作原理如下:首先對待測話語進行確認測試,系統自動確認待測話語是否來自內集話者.系統預先計算待測話語特征向量與GMM-UBM分類模型相似度并計算得分.若相似度得分大于預先閾值δ,則接受待測話語為內集話語(否則作為外集話語拒絕判別),并進一步計算GMM模型λi的最大似然度?j,計算得分,若得分大于預先閾值η,則判斷待測話語就是內集話者中第j個話者.否則,若得分小于η,系統將實施SVM分類法,即選出小于η所對應GMM模型若干均值向量(一般選取1~3個),輸入到SVM進行OAA SVM模型訓練,并繼續對當前測試話語進行再次分類,選取待測話語特征向量中被分去最多向量的類作為最后判別結果輸出.
實驗數據:本文使用PC機,在普通實驗室錄制了100個說話人語音數據,每個話者任意說1~2 min話,話語的錄制頻率設置為44.1KHz.對于錄制的數據設置16KHz采樣頻率,16bit位進行量化處理.對長時間錄制語音流實施基于基頻F0的自動切分,端點檢測,提取有聲語音段,并通過人工編輯加工生成實驗語音數據.每個切分話語長設為10~30 s,并用waveform格式保存到語音訓練集中.本次說話人識別實驗中選用共60名話者,將其中50名話者話語作為訓練集,剩余的10名話者話語作為集外話者.
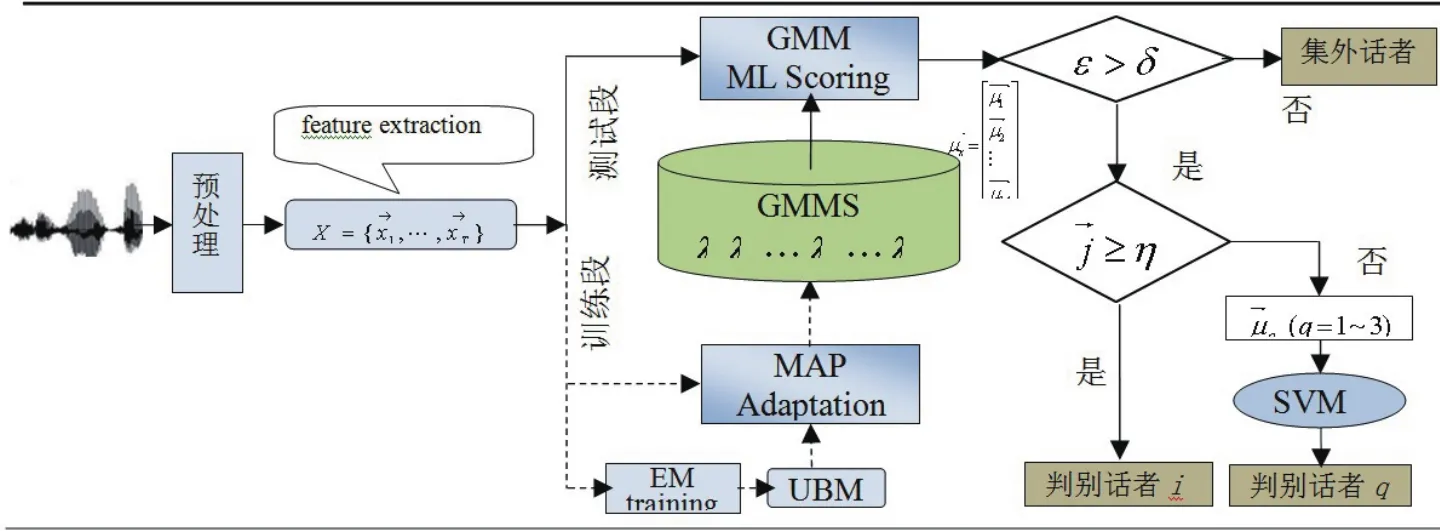
圖8 GMM-UBM-SVM混合模型說話人識別系統結構圖
本實驗提取的特征參數采用12維mel-到譜系數的MFCC和其一階差分和一維能量參數共25維特征向量.GMM混合數設定128,SVM內核參數為RBF.為了便于比較,本次試驗中也給出了GMM,GMMUBM常用測試結果.實驗結果如圖9和表1所示.
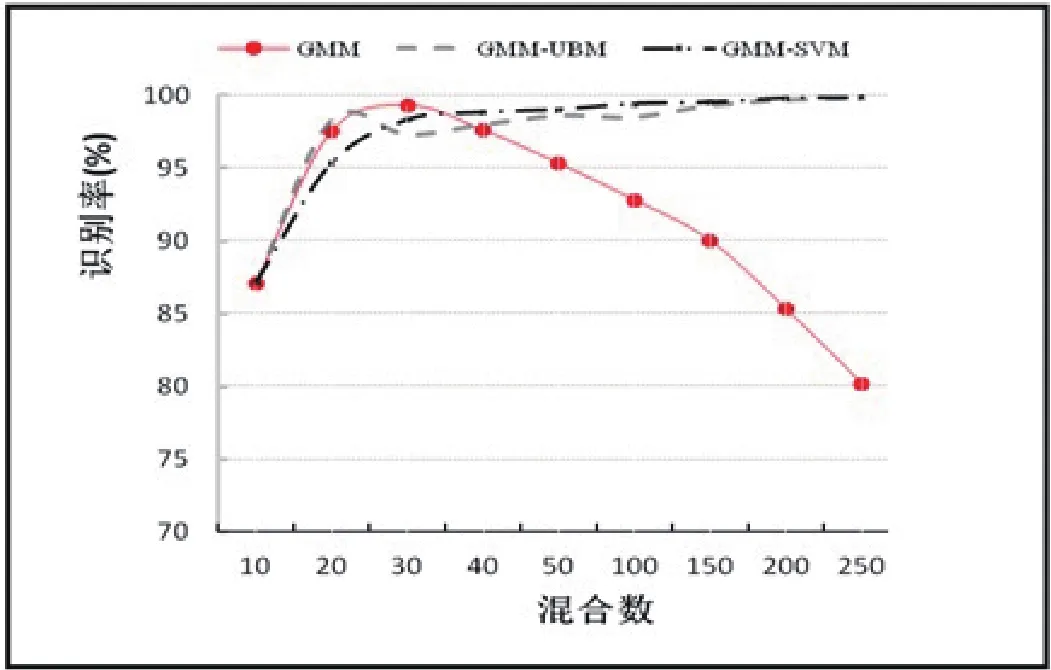
圖9 3個話語訓練數據在不同混合參數的說話人識別率

表1 5名話者說10個不同長度話語時的說話人識別結果
實驗結果分析:圖9顯示用不同混合參數訓練數據時獲得的識別結果,可以看出隨著混合參數的增加GMM方法識別率下降.GMM方法在混合參數為32時得到最好識別結果99.31%.這表明混合數的急劇增加會引起GMM識別結果大幅度衰退.GMM-UBM及GMM-SVM方法雖然在混合參數較小時識別率較低,但隨著混合參數增大識別率會快速上升.而GMM-SVM方法在混合參數趨于256時可達100%的識別率.表1給出了5名話者訓練模型的實驗結果,時長不同的10段話語,且話語長控制在約10 s.從表中顯示結果看到,GMM-UBM和GMM-SVM均用UBM方法適應學習建模,識別結果幾乎接近,但與GMM-UBM方法相比,GMM-SVM方法的識別結果高于GMM-UBM約3%左右.GMM-SVM方法顯示,即使語音信號時長較短,仍具備良好分類性能,明顯優于其它方法.
4.2 連續語音識別實驗
語音翻譯系統結構及工作原理在前面已介紹.下面以維-漢語音翻譯實驗介紹系統各單元實驗過程及測試結果.
實驗數據:本次試驗中使用由64名(男性32人,女性32人)維吾爾族說話人自由會話的短語作為語音語料.語料在PC機上采用單聲道錄制并保存為.wav文件,語料總時長約為4.0 h(小時).采樣率為16 kHz,16 bit,幀寬為10 ms.語音特征量為12維的Mel-倒譜系數(MFCC)及?MFCC加1維對數能量,共25維向量.話語文件.wav用表2所示33個聲學單元轉寫標注并生成拉丁字母.txt文本文件.其中sil為語音起止符.
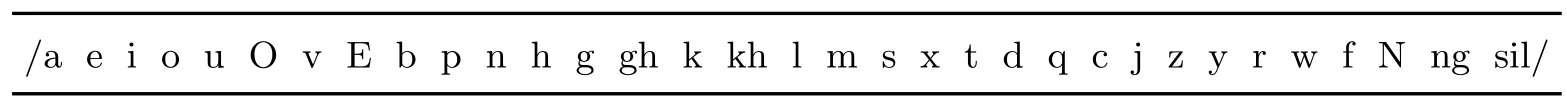
表2 維吾爾語語音標注聲學單元(共33)
建聲學模型:考慮到語料大小以及話語區間標注的精確度,本研究采用種子(seed)模型引導大語料,構建聲學模型方法.具體做法如下:
從語音語料中選擇10個話者500個話語(男性5人,女性5人),用表2中聲學單元進行人工準確地標注音素生成.lab文件;
利用HTK toolkit對以上語料(包括.wav文件和標注的.lab文件)進行聲學模型訓練,產生高精度的種子模型;
對剩余的語音語料(共54個話者語音.wav和.txt文本),利用viterbi alignment算法參照種子模型進行自動切分,并對每個切出音素,按前后2個音素的組合產生學習用數據,再利用學習用數據在HTK toolkit上訓練新的聲學模型.實現過程如下:學習數據的生成→topology學習→label學習→連接學習.如此,得到的聲學模型為三音子(triphone)HMMnet格式聲學模型;
用新的聲學模型替換第1次樣本seed模型,重復上述訓練過程,生成最終的33個HMMnet格式聲模(AM).
建語言模型:一般對容量為V的文本訓練集訓練N-gram語言模型時,要產生VN個N-gram參量,參量總數隨著N的增大急劇增大.為此,本文研討基于詞類(class N-gram)的語言模型.對于長度為V的詞串W=w1,w2,···,wi,具體做法如下:
將每個詞作為一個類初始化;
對每個詞或類指定能反映詞與詞之間連接關系的向量ν(x);
把向量ν(x)分別記作后行向量νt(x)和先行向量νf(x),如下所示:
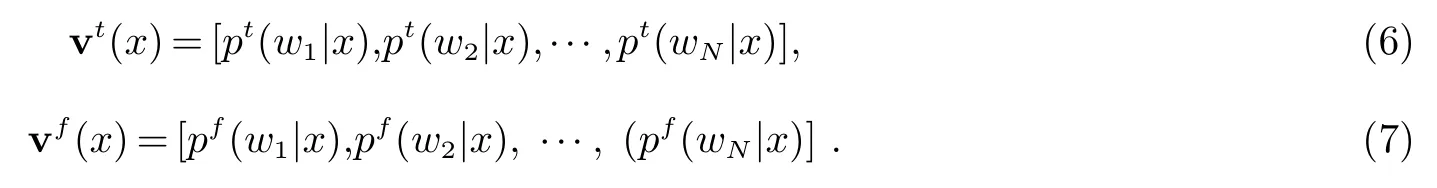
其中,pt(wi|x)和pf(wi|x)分別表示從某個詞或者類到后行一個詞和前行一個詞2-gram概率值.
通過式(8)把合并損失最小的2個類合并為一個:
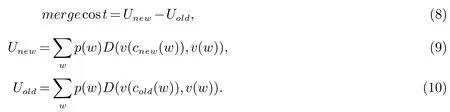
其中,cnew為合并后的類;cold為合并前的類;D(νc,νw)為向量νc和νw的歐氏距離平方.在本次試驗中利用表3數據,以及選用詞頻為200以上的詞構建6萬詞詞典,并用palmkit工具生成2-gram及3-gram統計語言模型.
4.3 實驗結果
利用上述方法生成的聲學模型和語言模型,引用Julius[15]識別器實現語音識別.為便于比較實驗結果,本文給出了語音數據在不經過人工標注切分和經過人工標注切分兩種情況下的實驗結果.對于200個上下文無關,一般話筒輸入話語和公用電話輸入話語通過3-gram語言模型進行識別的結果如圖10所示.
實驗結果表明,在同等數據的3-gram語言模型條件下,通過少量語料的人工切分標注來生成種子聲學模型再引導大語音建模方法的識別率為72.5%,明顯優于無人工標注(識別率為68.3%),識別率提高了4.2個百分點.同時也發現實時電話輸入語音識別的結果低于一般話筒輸入的識別結果.這可能因為電話語音噪音大,信號特性復雜難以獲得高精度特征參數而引起.
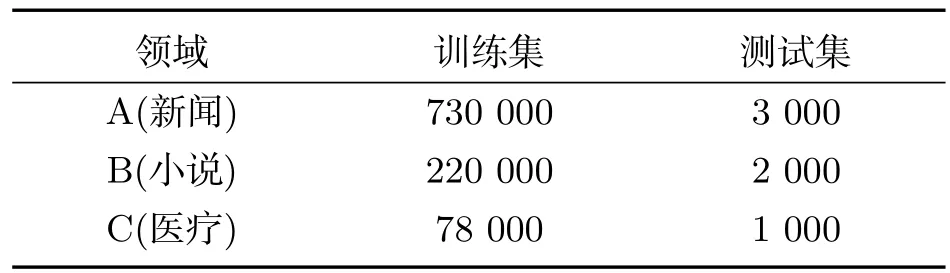
表3 用于統計模型的維吾爾語文文本集
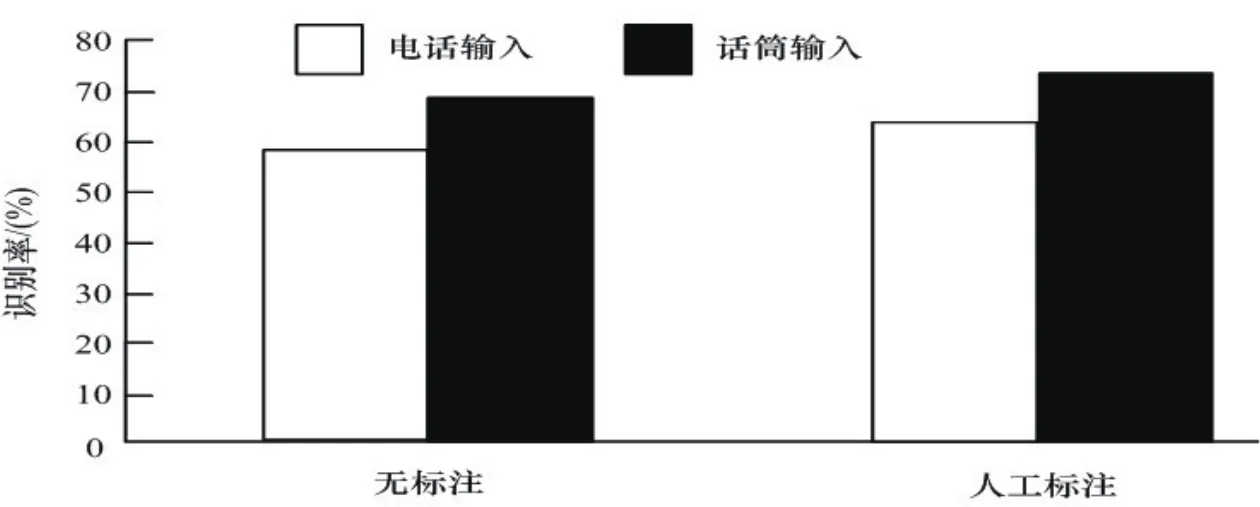
圖10 3-gram模型連續語音識別結果
4.4 統計機器翻譯實驗
本次實驗采用了統計機器翻譯SMT(Statistical machine translation)技術.從本研究設計制造的民-漢醫療衛生用語多文本對齊語料[16]中選用維-漢,蒙-漢各30K短語對齊文本語料,統計生成雙語翻譯模型,對目標語言(漢語),單獨訓練N-gram統計語言模型.本次實驗引用了Moses v 0.91版本翻譯軟件[17].表4中給出了用BLEU(Bilingual Evaluation Understudy)[18]值自動評測的翻譯實驗結果.在測試階段,另外生成510對測試文本,并對每個短語又設定14個參考翻譯短句.由于實驗數據處于初建階段,本文只報告維-漢和蒙-漢單向翻譯結果.

表4 機器翻譯自動測試實驗結果
4.5 語音合成實驗
本文討論基于隱馬爾可夫模型(HMMs)的語音合成方法.首先利用一名漢語普通話者朗讀時長約為1 h的醫療衛生用語短句文本.
其次,對于錄制話語采用16kHz采樣頻率,25-ms Hamming窗口進行預處理,每隔5-ms幀長,抽取出語音基音F0和到譜參數.抽出基音參數logF0值和變化率參數構成基音F0特征向量.由25維倒譜系數,過零系數,變化率參數組成倒譜特征向量.然后用自然語言處理工具對錄制話語進行聲學單元標注,確立話語中詞和句子的發音位置信息.聲學單元的訓練用5-狀態left-to-right HMMs進行,每個HMM對應話語中的各聲學單元.最后,合并標注文本,基音及到譜特征向量,訓練HMMs模型.
本次合成實驗引用HTS(HMM-based speech synthesis system)工具中的合成聲碼器,實現mel-對數譜近似(Mel Log Spectrum Approximation,MLSA)合成聲碼器.
通過人工聽力評估語音合成試驗結果.在本次試驗中系統對測試輸入話語,經機器翻譯及語音合成輸出其結果.通過觀察發現,合成實驗結果較接近原始錄音語音.但是對于不同話語的輸入,系統輸出語音的精確度有明顯差距.這主要可能是:連續語音識別單元識別精度不高,誤識別字符串得不到準確的翻譯,從而影響了語音合成效果;并且用于語音合成訓練的語料有限,使HMMs模型及合成參數特征提取精度不夠高,也可能是原因之一.
5 結論與展望
本文介紹了語音工程技術在民族語言文字處理方面的應用研究情況.對于說話人識別問題提出了GMMUBM-SVM混合技術的識別方案.試圖充分發揮GMM及SVM兩種算法各自強項提高系統魯棒性.從本次實驗可確認,GMM-SVM組合識別方法對于短暫語音信號有較好魯棒性,識別率好于常用GMM-UBM方法(約高3%).針對語音翻譯技術的工程應用,本文提出在醫療衛生領域使用民-漢語言會話翻譯系統.對于缺乏語料的民族語言,本文提取高精度聲學模型,采取了少語料人工標注生成語音環境精密的seed聲摸,再用之引導大語音語料訓練聲模.實驗結果得出結論,與無人工標注語音-文本對齊語料直接訓練聲摸情況相比,有人工標注的方式性能要好.該實驗證明語音環境的準確掌握對于缺乏語料的民語實現連續語音識別確有較大幫助.最后還嘗試了語音翻譯技術實用系統的構造及測試,并達到預期目的.
由于語音技術在少數民族地區的研究開發工作剛剛起步,收集準備的試驗數據及技術方法有限,本文僅僅討論了一些簡單的應用結果.今后將加大建立能夠全面覆蓋民語自然語音、語言知識網絡的語料庫系統,并結合具體語言結構建立多語言語音學知識系統,從而進一步提高應用系統的性能.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
文苑(2020年4期)2020-05-30 12:35:30
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
