基于語義相似度計算的Deep Web數據庫查詢*
2014-11-10 07:10:04夏海峰陳軍華
網絡安全與數據管理 2014年8期
夏海峰,陳軍華
(上海師范大學 計算機系,上海200234)
在當今信息時代,萬維網成了主要的資源。隨著萬維網的飛速發展,使得其在全球網絡中所占的比重越來越大,其內部涵蓋的信息也越來越豐富。然而對于其內部所包含的Deep Web,卻沒有被很好地開發和利用。根據Bright Planet對 Deep Web統計而發布的白皮書[1],截止到2011年,共有600萬個中文萬維網數據庫,并且每天都以指數級的速度增長。傳統意義上的萬維網數據搜索只能通過查詢接口(即HTML表單)被用戶訪問,用戶得到的反饋內容也僅僅局限于查詢接口與后臺數據庫交互之后生成的查詢頁面內容。
基于當前中文Deep Web數據庫的研究現狀,本文提出了基于語義相似度計算的中文Deep Web數據查詢方法。該方法旨在通過基于計算關鍵詞和屬性詞典之間的語義相似度,將用戶查詢的關鍵詞映射到具體的領域,最大程度地縮減數據庫的查詢范圍,最終提高查詢的效率。對于Deep Web數據庫,本文采用數據集成技術[2],將同一領域的數據庫表結構采用標簽的形式,形成對應的屬性詞典,從而實現前后臺的無縫連接。
1 理論基礎
1.1 知網體系
知網(HowNet)是一個以漢語和英語的詞語所代表的概念為描述對象,以揭示概念與概念之間以及概念所具有的屬性之間的關系為基本內容的常識知識庫。其體系架構如圖1所示。知網體系包含豐富的語義知識和相關本體知識。在知網中,所有詞匯的概念都是基于以下兩個主要概念:
(1)概念。它是對詞匯語義的一種描述,每一個詞可以表達為幾個義項。義項是用一種知識表示語言來描述的,這種知識表示語言所用的詞匯叫做概念。
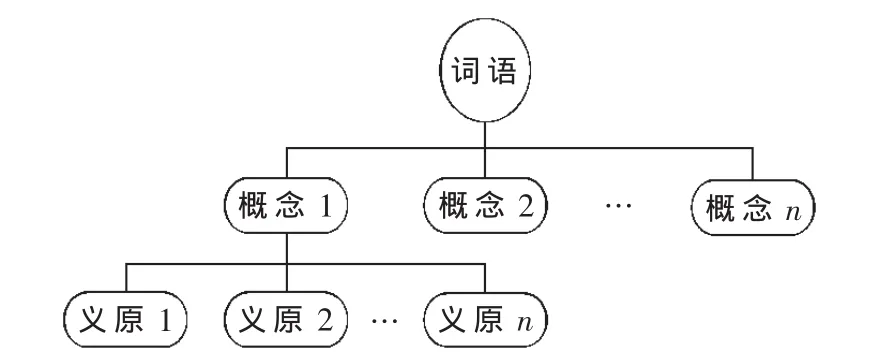
圖1 知網體系架構
(2)義原。它是用于描述一個概念的最小意義單位,從所有詞匯中提煉出的可以用來描述其他詞匯的不可再分的基本元素。
在知網體系中,每個詞匯都由一個四元組W_C=詞語;E_C=詞語例子;G_C=詞語詞性;DEF=概念定義)表示而成,并且在知網體系中,它并不像同義詞詞林那樣將所有的概念歸結到一個樹狀的概念層次體系中,而是每一個概念都是由義原采用四元組的形式加以表示。圖2顯示的是關鍵詞“北京”基于知網的語義表示形式。
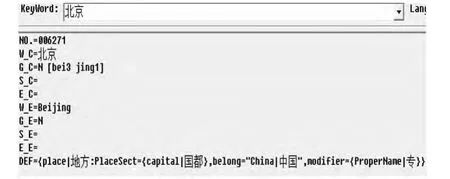
圖2 關鍵詞“北京”
1.2 屬性詞典
在Deep Web數據庫中,本文引入了屬性詞典的概念[3]。事先在數據庫中創建一個屬性詞典(稱之為Attr-Dict表),該表的作用在于保存數據庫中每一張表結構的字段和對于該字段的詳細解釋。該屬性詞典主要用于計算關鍵詞和后臺數據庫屬性列之間的語義相似度。
該AttrDict表的表結構如下:
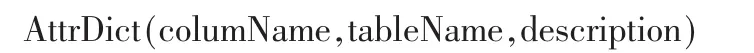
其中,字段columName為數據列名,字段tableName為對應的表名,字段description為屬性對應的描述。
在本文的數據源中,假定其中的兩張表如下:
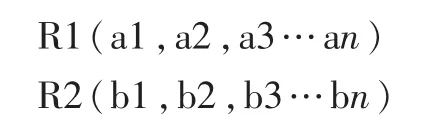
則對應的AttrDict表對應的字段如表1所示。
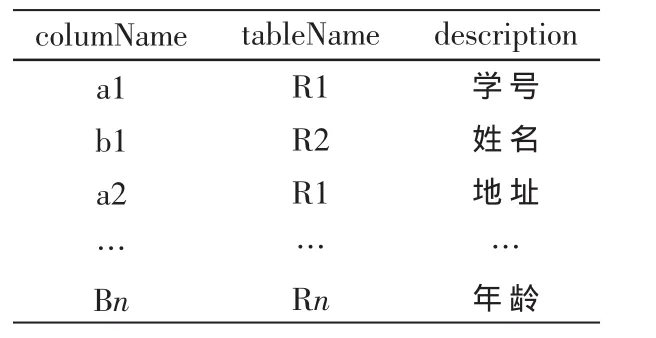
表1 屬性詞典表結構示例
2 語義相似度計算方法研究
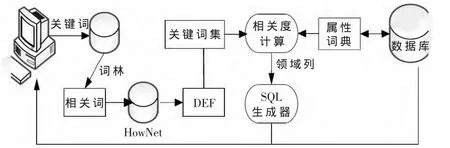
圖3 基于語義相似度計算Deep Web數據庫查詢
本文在計算關鍵詞[4-5]的語義相似度時,采用基于詞語相似度的計算方法,其流程如圖3所示。計算出當前關鍵詞和屬性詞典每個屬性列的相關聯程度,設定一個起初的閾值,當相似度計算所得結果大于該閾值時,認為當前屬性列對應的領域即是當前關鍵詞對應的領域R,這樣也就確定了關鍵詞K和屬性列之間的對應關系,從而確定對應的表結構的字段集合C,最終根據生成的一個完成的SQL查詢語句,將查詢的結構反饋給用戶。
基于HowNet的詞語相似度[6]充分利用了 HowNet對每個概念描述時的語義信息,但沒有考慮到在信息檢索過程中關鍵詞的相關詞的語義相似度,這樣可能減少實際上關鍵詞的相關詞的檢索范圍。基于以上觀點,本文提出了一種改進的詞語相似度計算方法[7],主要工作如下:
(1)首先利用詞林(哈工大版)[8]獲得當前關鍵詞的相關詞集合;
(2)基于HowNet獲得相關詞集合的每個相關詞的概念定義(DEF);
(3)利用知網計算相關概念詞集合詞語和屬性詞典的概念相似度。
2.1 預處理關鍵詞
定義1 利用詞林(哈工大版)尋找相關詞,形成相關詞集合,用下面一個4元組構成:
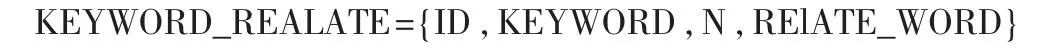
定義2 關鍵詞概念定義(DEF)用下面一個5元組構成:
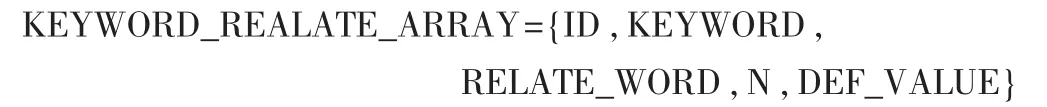
其中,ID表示單標識符,由系統自動賦予并唯一表示;KEYWORD表示當前檢索系統提交的關鍵詞;RELATE_WORD表示通過詞林獲得關鍵詞的相關詞;N為正整數,表示提交表單中概念定義屬性的個數;DEF_VALUE為概念定義屬性名/值對集合,用來表示當前關鍵詞的概念定義的詳細信息,其個數為N。
2.2 相似度計算方法
(1)詞語相似度:
假設現有兩個詞語A1和A2,A1由m個概念組成,A2由n個概念組成,如下表示:
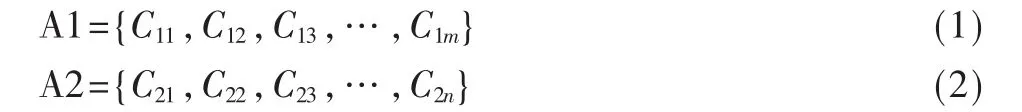
[6]認為兩個詞語的相似度,也就是兩個詞語的概念的任意組合的相似度的最大值。其計算采用的是最大值匹配法,公式如下:
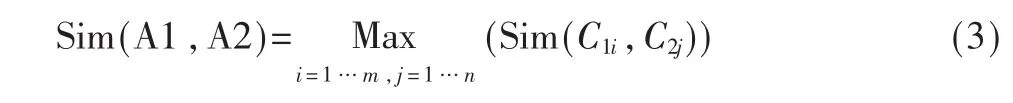
(2)概念相似度
參考文獻[6]把對義項的描述分為4類:第一基本義原描述、其他基本義原描述、關系義原描述和關系符號描述。假設義項C1有m個義原,C2有n個義原,如下式所示:
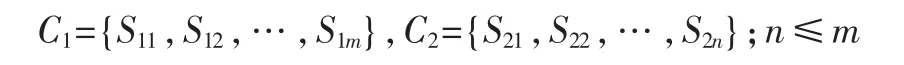
則對于義項C1、C2之間的相似度可以用義原的相似度加以描述:
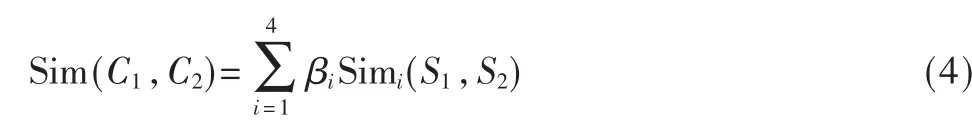
Sim1(S1,S2)表 示 第 一 義 原 的 相 似 度 ,Sim2(S1,S2)表 示其他基本義原的相似度,Sim3(S1,S2)表示關系義原描述的相似度,Sim4(S1,S2)表示符號義原的相似度,并且 β1+β2+β3+β4=1。
(3)義原相似度
HowNet是一個具有網狀結構的世界知識庫,義原相似度要利用義原間的上、下位關系來構造一種樹狀結構的義原層次體系,通過樹中各個義原節點之間的相互關系來計算。許多學者在這方面進行了大量的研究,其中被廣泛認可的是中科院劉群等人的公式:

2.3 基于相似度計算的匹配算法
定義 3 對于給定的閾值 E,如果 Sim(A,B)≥E(Sim為計算相似度的方法,詳見2.2節),則認為關鍵詞相關詞A和數據庫列屬性概念描述B相匹配,Match(A,B)=1;否則 Math(A,B)=0,兩者不匹配。
為了規則化處理,假設A和B都存放在單鏈表中,A的表頭指針為 HeadA,B的表頭指針為 HeadB,下面是關鍵詞相關詞A和數據庫列屬性概念描述B的匹配算法過程:
/*Threshold表示設定的閾值;r、s分別表示A、B兩個單鏈表中要比較的節點;Delete(node)表示將當前節點從鏈表中刪除*/

刪除B中不滿足條件的節點之后,剩下的都是和關鍵詞滿足一定相似度的列,基于此,下面給出了集成方法。

3 實驗分析與說明
Deep Web蘊含了海量的數據,受客觀條件限制不可能在整個深度萬維網上進行實驗,并且中文實驗數據樣本不多,為了簡化起見,選擇了上海師范大學某學院信息管理系統2012~2013年的數據進行測試,整個系統共包含20張表結構,數據量500 MB。實現的步驟主要分為以下3個部分:
(1)基于哈工大《同義詞詞林(擴展版)》計算關鍵詞的相關詞,獲取過程如圖4所示。
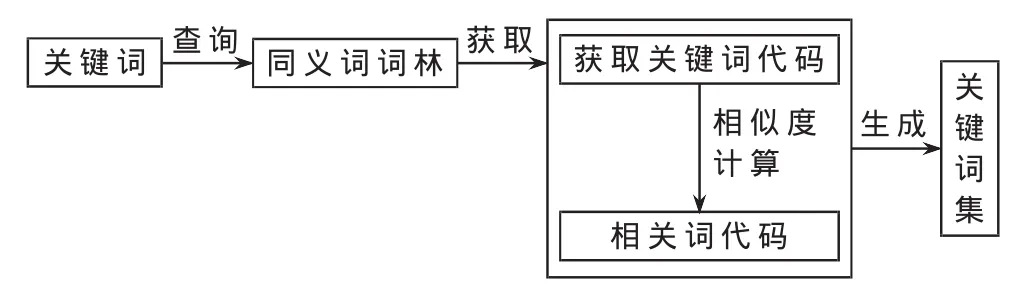
圖4 基于同義詞詞林的相關詞獲取過程
輸入關鍵詞"北京"進行查詢,獲取"北京"的代碼為"Di03A01=",根據參考文獻[8]中相似度計算公式,得到與當前關鍵詞處于同一層的關鍵詞分別是:"Di03A01=:北 京","Di03A02=:都 城","Di03A03@:陪 都"。在同義詞詞林的定義中,“=”代表“相等”、“同義”,“@”代表當前該詞語在同義詞詞典中既沒有同義詞也沒有相關詞,故本實驗中,省去"Di03A03@:陪都"這一個基于同義詞詞林獲得相鄰的近義詞。
(2)基于 HowNet獲得關鍵詞集合的概念定義(DEF)如表2所示,其中根據集合的原理,取其共同擁有的部分,則關鍵詞集對應的DEF={地方,國都}。

表2 關鍵詞集表
(3)基于本文提出的改進的相似度的計算方法,計算出關鍵詞DEF集和屬性詞典對應屬性列之間的語義相似度。
①創建后臺數據庫屬性詞典(AttrDict)
選取上海師范大學某學院信息管理系統后臺表2個月的數據進行試驗。根據要求,屬性詞典主要包含3個部分:表名、字段名和對應的描述文字,如表3所示。為了簡便起見,選取其中的一張表member作為展示部分。
②相似度計算方法
由 DEF={地方,國都},根據HowNet逐個計算DEF值和當前AttrDict中每條記錄的相似度,如圖 5、圖 6所示。
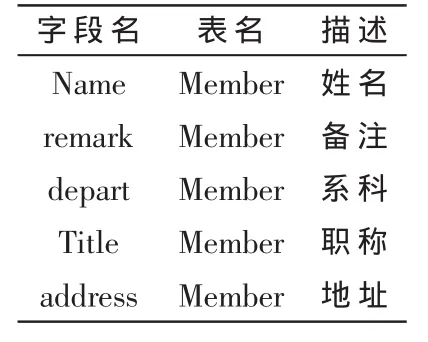
表3 屬性詞典表
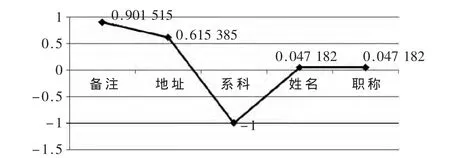
圖5 地方的相似度計算
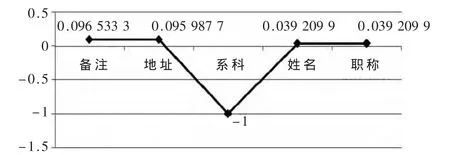
圖6 國都的相似度計算
根據事先設定的閾值E=0.5,當兩個詞語之間的相似度 表4 相似度計算結果表 ③限定對應的查詢領域 由表4中相似度計算所得結果,證實“北京”這一詞語可能與后臺數據庫對應的“備注”、“地址”的相關度很高,已無需查詢所有的表結構了,只需要查詢“備注”和“地址”列對應的數據,根據這一結果,動態生成相應的SQL查詢語句,并將查詢的結果返回給前臺頁面。 本文采用基于語義相似度的查詢方法進行Deep Web數據庫源的查詢,較早地探討了中文深網技術,宏觀上提出了整體解決方案,并且通過實驗過程驗證了當前方法的可用性。本文是對Deep Web數據庫相似度的一次初探,主要研究通過計算查詢關鍵詞和屬性詞典概念之間的相似度,從而降低全表掃描帶來的系統資源的損耗,提高數據庫整體查詢效率。但是本文方法依然存在一些問題,下一步不僅應該深入研究相似度的改進算法,還要研究對于系統未登錄詞的處理,并將致力于做出全自動的屬性匹配原型系統。另外,針對中文深網一整套解決方案實現原型系統也是未來工作的重點。 參考文獻 [1]NOOR U,RASHID Z,RAUL A.A survey of automatic Deep Web classification techniques[J].International Journal of Computer Application,2011,19(6):43-50. [2]劉偉,孟小峰,孟衛一.Deep Web數據集成研究綜述[J].計算機學報,2007,30(9):1475-1489. [3]馮磊,陳軍華.數據庫全文搜索方案的研究[J].上海師范大學學報(自然科學版),2010,39(2):153-155. [4]丁傳羽,陳軍華,夏海峰.基于關鍵詞的深度萬維網查詢[J].計算機與數字工程,2013,41(4):616-618. [5]范舉,周立柱.基于關鍵詞的深度萬維網數據庫選擇[J].計算機學報,2011,34(10):1797-1804. [6]劉群,李素建.基于知網的詞匯語義相似度的計算[C].第三屆漢語詞匯語義學研討會,臺北,2002:59-76. [7]王小林,王義.改進的基于知網的詞語相似度算法[J].吉林大學學報(信息科學版),2011,31(11):3076-3079. [8]田久樂,趙蔚.基于同義詞詞林的詞語相似度計算方法[J].計算機應用,2010,28(6):602-605.
猜你喜歡
現代裝飾(2022年1期)2022-04-19 13:47:32
開放教育研究(2020年2期)2020-03-31 01:54:14
現代裝飾(2020年2期)2020-03-03 13:37:44
中學生數理化·高一版(2018年9期)2018-10-09 06:46:48
中學生數理化·高一版(2017年9期)2017-12-19 12:15:14
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
現代語文(2016年21期)2016-05-25 13:13:44
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
