基于選擇度的分類規則學習算法
2014-12-02 01:11:50何田中周忠眉黃再祥
計算機工程 2014年8期
何田中,周忠眉,黃再祥
(閩南師范大學計算機科學與工程系,福建 漳州 363000)
1 概述
分類技術一直是數據挖掘技術中研究的熱點之一,近年來提出了各種不同的分類技術,如:將近似求導引入分類[1],使用最近鄰進行分類[2]等。為了提高不平衡數據集分類準確率,文獻[3]使用KNN技術,文獻[4]提出基于Boosting 技術。規則式分類一直是分類技術的重要方法之一,近年來也提出了許多規則式分類技術,如:基于DE/QDE 算法技術[5],具有多標準分類技術[6],分層模糊化規則分類技術[7],進化的規則式系統[8]等。規則式分類具有分類速度快特點,因此規則式分類技術也得到了較為廣泛的應用,如:肺癌評估[9],預測蛋白質相互作用類型[10]等。規則式分類技術抽取一條新規則時,使用某種度量獲取“最好”屬性值添加到當前規則中。如ID3、C4.5[11]算法分別使用信息熵及信息增益來選擇“最好”屬性,信息熵及信息增益都是單一度量,使用它們度量屬性時存在很多度量值相等的“最好”屬性,導致上述算法很難選擇出真正的“最好”屬性。FOIL[12]算法使用FOIL 增益來度量,FOIL增益是支持數與相關度的乘積。當支持數較大時,相關度幾乎不起任何作用,使用FOIL 增益也不能選擇出“最好”的屬性值。
規則式分類技術抽取一條新規則時,不斷選擇出“好”屬性值添加到規則中,直到該規則置信度100%為止,然后抽取下一條規則。這種學習方法容易導致過度學習,規則的支持度小、質量不高,并且使規則抽取更為耗時。如在ID3 算法中,當節點包含的實例為同一類時,分枝結束;此時的規則置信度為100%。FOIL 算法不斷地選擇“好”屬性值添加到當前規則中,直到該規則不包含負實例為止,規則的置信度也是100%。
為了解決上述問題,本文提出了基于選擇度的分類規則學習算法LRSM,該算法具有以下特點:
(1)使用一個新的屬性值度量方法——屬性值的選擇度,屬性值的選擇度是屬性值的信息熵、類的支持度及偏離度的綜合。由于選擇度是3 種度量的綜合,用它度量屬性值時,度量值相等“最好”屬性值的數量將大大減少。另外,選擇度包含偏離度,偏離度能夠衡量屬性值偏向某一類屬性值的程度。因此,選擇度不但能度量屬性值的好壞,而且還能夠反映出其偏向某一類屬性值的程度。
(2)LRSM 算法使用基于負實例數進行剪枝(NIP),即當規則覆蓋的負實例數小于特定值時,LRSM 算法結束該規則抽取,進行下一條規則抽取過程;這種方法克服了FOIL 等零負實例的學習方法帶來的過度擬合的問題,提高規則的支持度及質量,分類準確率得到較大的提高,同時也大大減少抽取規則時間。
2 屬性值的選擇度
設T 為元組集合,其屬性為A1,A2,…,Am及類屬性C={c1,c2,…,ck},每一元組{a1,a2,…,am,c}稱謂實例,其中,ai是屬性Ai;c 是類屬性C 的值。實例{a1,a2,…,am,cp}稱為正實例,而實例{a1,a2,…,am,cq},其中,q≠p 則稱謂負實例。
定義1 屬性值ai的信息熵:
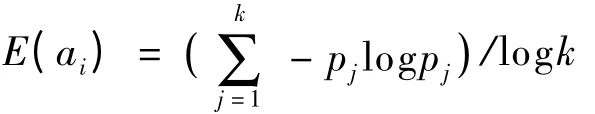
其中,pj=mj/mai,m為包含屬性值的實例數,mj為包含屬性值ai,且類值為cj的實例數。
屬性值的信息熵能夠度量出屬性值所包含信息量大小,但不能夠反映出該信息量更偏向哪個類屬性值。數據集D 如表1 所示。
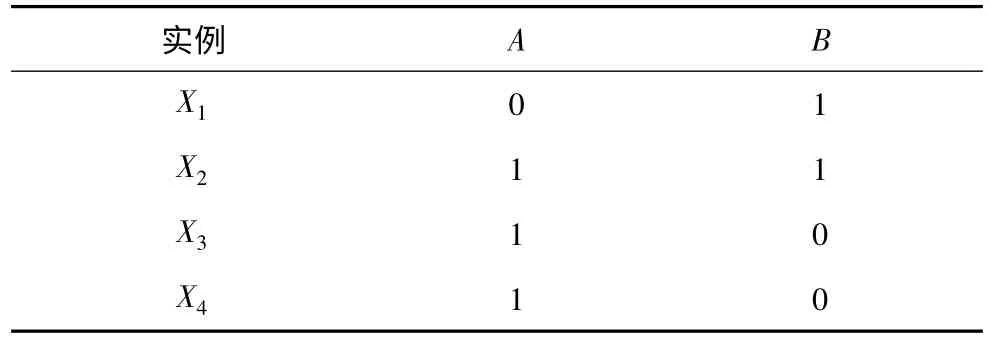
表1 數據集D
屬性值(A,1)的信息熵E((A,1))=0.918 3,其包含的實例如表2 所示。

表2 屬性值(A,1)包含的實例
從表2 可以看出,屬性值(A,1)包含的實例中,屬于類(C,1)的實例數比類(C,0)要少;但無法從信息熵看出屬性值(A,1)更偏向類(C,0)。為了克服信息熵的這種缺點,本文提出了屬性值的偏向熵。
定義2 屬性值ai對類cj的偏向熵:
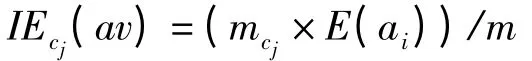
其中,m為包含屬性值ai的實例數;mcj為包含屬性值ai,且類值為cj的實例數。
按照定義2 屬性值(A,1)對類(C,0)及類(C,1)的偏向熵分別為:
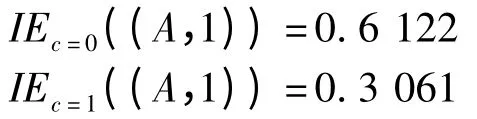
可以看出,屬性值(A,1)更偏向于類(C,0)與實際情況一致。
定義3 屬性值ai對類cj的偏離度:

其中,k 為類值個數;mc為包含屬性值ai,且類值為c的實例數;Mc為類值為c 的實例數。
定義4 屬性值ai對類cj的選擇度:
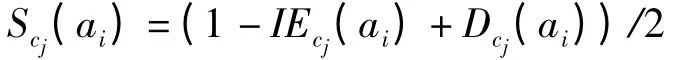
從定義4 可以看出,選擇度是偏向熵與偏離度的綜合,而偏向熵綜合了熵與類的支持度,即選擇度是熵、類支持度及偏離度3 種度量的綜合;屬性值度量值相同的機會較少,更易選擇出“好”屬性值,實驗結果表明,使用選擇度來度量屬性值具有更高的準確率。
3 基于選擇度的分類規則學習算法LRSM
LRSM 算法具有以下特點:(1)使用選擇度來度量屬性值,具有相同度量值的“最好”屬性值的數量大大減少,能更好地選擇出“好”屬性值;(2)LRSM算法使用基于負實例數進行剪枝,因此抽取的規則的置信度小于100%,從而避免了過度學習,提高規則的支持度。對于訓練集的每一個類屬性值,LRSM算法依次把屬于該類的所有實例作為正實例集,屬于其他類的實例作為負實例集,然后抽取屬于正實例集類的規則。抽取正實例集類規則時,LRSM 算法不斷使用選擇度來選擇“最好”屬性值添加到當前規則中,當該規則覆蓋的負實例數小于給域值時,規則抽取結束,刪除該規則覆蓋的正實例,再進行下一條規則抽取。因此,LRSM 算法具有較高準確率,且規則提取耗時更少的優點。
LRSM 算法具體描述如下:
輸入 數據集D
輸出 一組規則集RS
(1)對數據集D 中的每一類標c 值循環。
(2)將D 分成正實例集PS 及負實例集NS,其中,PS 為類標值為c 實例,其余的組成NS。
(3)抽取規則rs=mineRule(PS,NS),并添加到RS 中。
mineRule(PS,NS)過程描述如下:
1)規則集rs←Φ;
2)正實例數n←|PS|;
3)max_rule_length←屬性個數;
4)WHILE n >0
5) NS'←NS,PS'←PS;
6) 規則r←Φ;
7) 當前負實例數m←|NS'|;
8) 最小負實例數δ←m×α
9) WHILE(m >δ AND 規則r 長度<max_rule_length)
10) 根據PS' 及NS 計算所有屬性值的選擇度,并返回選擇度最大的屬性值av;
11) 將av 添加到規則r 中;
12) 從PS'、NS'移除不滿足規則r 的實例;
13)m←|NS'|
14) END
15) 規則r 添加到規則集rs 中;
16) 從PS'移除滿足規則r 的實例;
17) n←|PS'|
18)END
19)返回規則集rs
LRSM 使用選擇度選擇“好”的屬性值;由于選擇度是3 種度量綜合,因此屬性值具有相同度量值機會大大減少,更容易選擇“好”的屬性值;另外,當負實例數小于最小負實例數δ,規則提取提前結束,因此規則抽取耗時更少,支持度更高。
以下通過一個例子說明LRSM 主要思想:數據集如表3 所示,以正實例為類屬性值(C,1),負實例數域值為δ=2 為例進行說明。
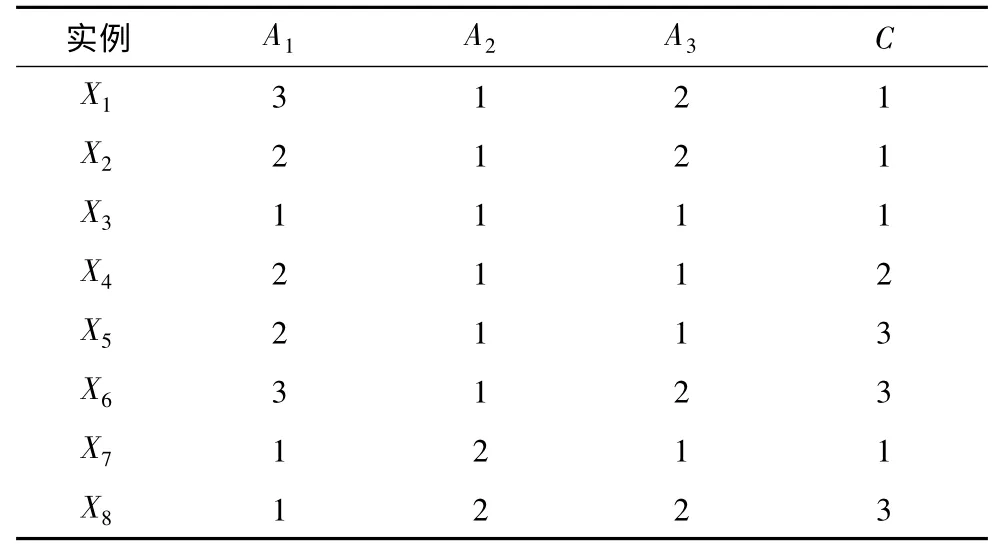
表3 數據集
此時,正實例集為:PS={X1,X2,X3,X7},負實例集為:NS={X4,X5,X6,X8}。
提取第一條規則,PS'=PS,NS'=NS;空規則為:null→(c,1)。
計算屬性值的偏向信息熵、偏離度及選擇度如表4 所示。

表4 屬性值的偏離度、偏向熵及選擇度
由表4 可知,屬性值(A1,1)選擇度最大,將(A1,1)添加到規則中得:(A1,1)→(C,1)。
從PS'、NS'中刪除滿足規則前件的正、負實例得:PS'={X3,X7},負實例集為:NS'={X8}。
從PS 中刪除滿足規則的實例,此時,正實例集為:PS={X1,X2},負實例集為:NS={X4,X5,X6,X8}。由于正實例數不為零,繼續下一條規則抽取,過程同上,正類(C,1)的規則集為:(A1,1)→(C,1),(A3,2)→(C,1)。
4 分類規則學習算法LRSM 的測試
在進行測試之前,先計算出所有規則強度RS。測試每一實例時,如果該實例匹配的規則集的類屬性值相同,且該實例的類屬性值與規則集類屬性值一致,測試正確;若匹配的規則集類屬性值不同,將這些規則集按類屬性值分組,計算規則集R 的平均強度ARS(R),如果該實例的類屬性值與最高平均強度的規則集類屬性值一致,測試正確。
計算規則強度定義如下:
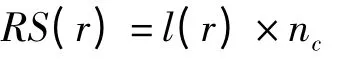
其中,nc為滿足規則實例數;l(r)為規則r 的拉普拉斯值[13]。
規則集R 的平均強度定義如下:
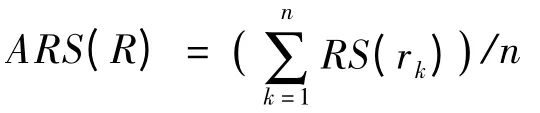
其中,n 為規則集R 中規則數。
5 實驗結果與分析
所有的實驗都是PC 機上進行,其中,CPU 為3.1 GHz、內存4 GB、操作系統為Windows XP;實驗數據來源于UCI 機器學習庫。為了驗證選擇度及LRSM 算法的準確性及耗時,分別設計以下3 組與FOIL 對照的實驗。
在第1 組實驗中,用實驗測試本文中屬性值的度量選擇度有效性。在FOIL 算法中,分別使用FOIL 增益及選擇度來選擇“好”屬性,表5 實驗結果表明,選擇度度量平均準確率比FOIL 增益高,尤其在數據集lymph、monks 和breast 有較大的提高。
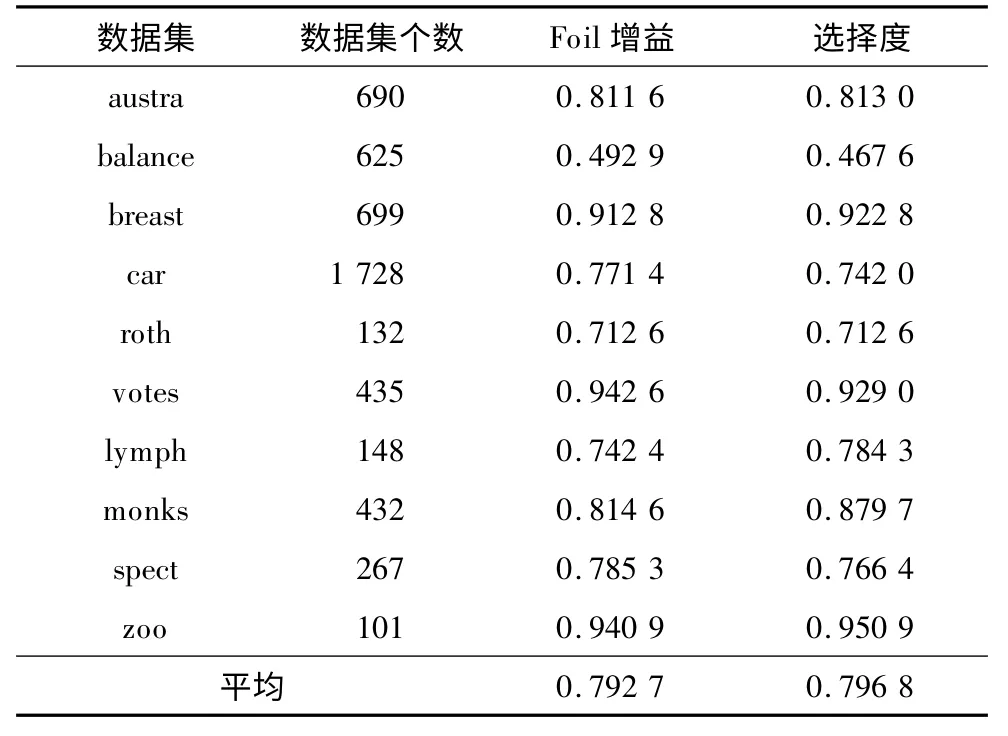
表5 FOIL 增益及選擇度的準確率對比
在第2 組實驗中,為驗證基于負實例數提前剪枝(NIP)的有效性,在FOIL 算法中使用基于NIP 剪枝與不使用NIP 剪枝,表6 結果表明,使用提前剪枝能使規則的支持度更高,規則質量更好。因此,基于負實例數提前剪枝能較大地提高分類準確率。
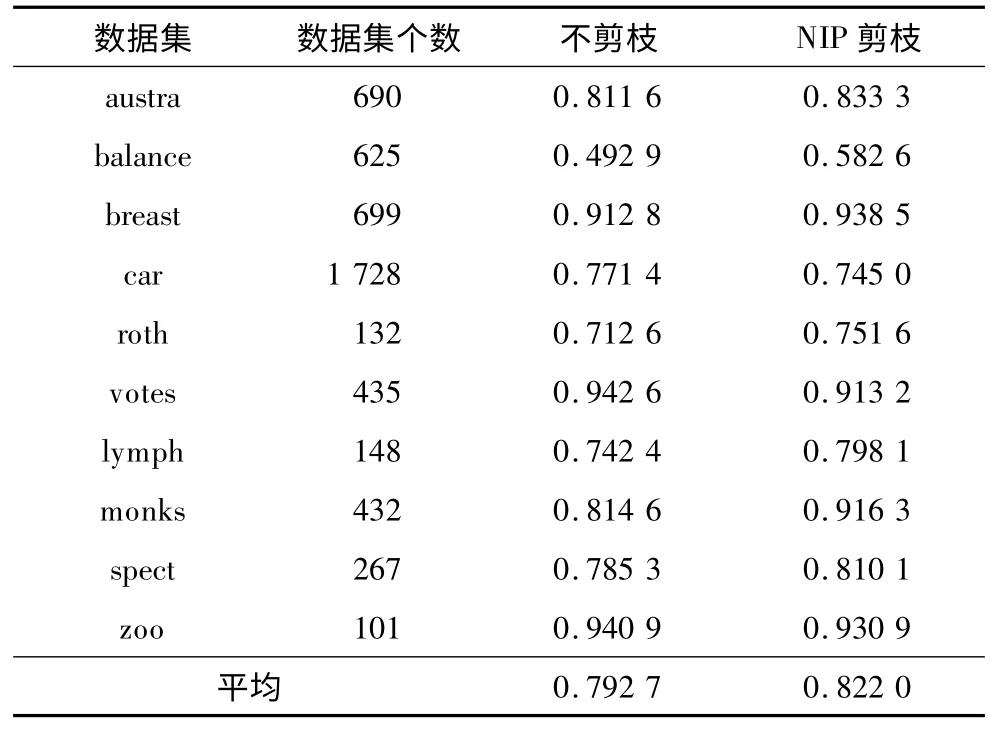
表6 使用NIP 剪枝與不剪枝的準確率對比
在第3 組實驗中,用實驗測試LRSM 算法的準確率及效率,使用LRSM 算法與FOIL 算法進行實驗,由于LRSM 算法使用提前剪枝且使用選擇度度量,表7 實驗結果表明,與FOIL 算法相比,LRSM 算法訓練耗時減少近一個數量級,而平均準確率提高了近3 個百分點。

表7 FOIL 算法與LRSM 算法的準確率及耗時對比
從上述3 組實驗可以得出如下結論:
(1)三度量結合的選擇度比兩度量結合FOIL增益,更易選擇出“好”屬性值,分類準確率更高;
(2)使用基于負實例數提前剪枝(NIP)不但能提高分類準確率,而且能大大縮短提取規則的時間。
6 結束語
通常屬性值的度量采用單度量如信息增益,或2 種度量結合如FOIL 增益。不管是單度量還是2 種度量結合,仍然會存在若干不同屬性值的度量值相同,從而較難選擇出“好”的屬性值。本文提出一種三度量結合的度量選擇度,使用選擇度度量屬性值時,不同屬性值具有相同的度量值大大減少,因此更容易地找出“好”屬性值。此外,本文提出基于選擇度的規則學習算法LRSM。在LRSM 算法中,使用選擇度,及基于負實例數提前剪枝。用基于負實例數提前剪枝方法能提取到的規則支持度更高、質量更好且耗時更少。實驗結果表明,LRSM 算法減少了訓練時間,且提高了分類準確率。
[1]劉建偉,李雙成,羅雄麟.基于非近似求導過程的加更新和乘更新分類算法[J].計算機學報,2013,36(2):327-340.
[2]鐘 智,朱曼龍,張 晨,等.最近鄰分類方法的研究[J].計算機科學與探索,2011,5(5):467-473.
[3]王超學,潘正茂,馬春森,等.改進型加權KNN 算法的不平衡數據集分類[J].計算機工程,2012,38(20):160-163.
[4]李秋潔,茅耀斌,王執銓.基于Boosting 的不平衡數據分類算法研究[J].計算機科學,2011,38 (12):224-228.
[5]Su Haijun,Yang Yupu,Zhao Liang.Classification Rule Discovery with DE/QDE Algorithm[J].Expert Systems with Applications,2010,37(2):1216-1222.
[6]Rezaei J,Dowlatshahi S.A Rule-based Multi-criteria Approach to Inventory Classification[J].International Journal of Production Research,2010,48 (23):7107-7126.
[7]Fernández A,del Jesus M J,Herrera F.Hierarchical Fuzzy Rule Based Classification Systems with Genetic Rule Selection for Imbalanced Data-sets[J].International Journal of Approximate Reasoning,2009,50 (3):561-577.
[8]Orriols-Puig A,Bernadó-Mansilla E.Evolutionary Rulebased Systems for Imbalanced Data Sets [J].Soft Computing,2009,13(3):213-225.
[9]Anthony N N,Michael J L.Symbolic Rule-based Classification of Lung Cancer Stages from Free-text Pathology Reports[J].Journal of the American Medical Informatics Association,2010,17(4):440-445.
[10]Sung H P,José A R.Prediction ofProtein-protein Interaction Types Using Association Rule Based Classification[J].BMC Bioinformatics,2009,10(1):36.
[11]Quinlan J R.C4.5:Programs for Machine Learning[M].Vol.1.San Francisco,USA:Morgan Kaufmann,1993.
[12]Quinlan J R,Cameron-Jones R M.FOIL:A Midterm Report[C]//Proc.of ECML'93.Vienna,Austria:Springer,1993:3-20.
[13]Yin Xiaoxin,Han Jiawei.CPAR:Classification Based on Predictive Association Rules[C]//Proc.of SDM'03.San Francisco,USA:Society for Industrial & Applied Mathematics,2003.
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
幸福(2018年33期)2018-12-05 05:22:42
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
Coco薇(2017年11期)2018-01-03 20:59:57
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
