圖書借閱量預測建模方法比較研究
2014-12-25 06:37:58陳英
科技視界 2014年23期
關鍵詞:模型
陳 英
(河南農業大學 馬克思主義學院,河南 鄭州450002)
0 前言
在信息社會, 紙質圖書的流通頻率對構建學習型社會非常重要,一定周期內的不同類型的圖書借閱量反映了該社會公民的整體素養。借閱趨勢分析是圖書管理員的日常工作之一, 通過對借閱規律分析,管理員能夠掌握師生的借閱興趣和研究狀況,各類圖書和期刊的采購數量和質量,達到更好的為師生服務的目的。 建立恰當的數學模型能夠預測未來一定時間段內圖書的借閱規律,常見的借閱規律預測模型建模方法有以下幾種:多變量回歸分析法、神經網絡、灰色系統理論和遺傳算法等[1]。 在上述方法中,多變量回歸分析方法是基礎,其它幾種方法都是基于該方法演變而來,是最通用的方法[2]。神經網絡算法也是數學建模中常用算法,該算法有很強的非線性擬合能力,可映射任意復雜的非線性關系,學習規則簡單,魯棒性、記憶能力、能力和自學習能力強大,但該算法沒能力來解釋自己的推理過程和推理依據,訓練模型的數據量龐大,計算過程容易造成信息的丟失;與神經網絡建模方法相比,灰色系統理論建模過程清晰簡單,模型穩定性比較好,但預測精度有待提高。 遺傳算法屬于全局搜索算法,采用仿生學原理模擬自然進化過程擇優搜索,該方法適用范圍廣,在一定域內總能找到目標解,但模型容易“早熟”,難以到達最優解,屬于隨機算法[3-4]。 本文對上述四種建模方法的建模過程進行分析,對數學模型的優缺點進行評價,為圖書管理員和圖書管理科研工作者提供一定的參考。
1 多變量回歸建模預測圖書借閱量
1.1 建模原理
回歸分析是一種分析變量之間關系的數理統計方法。對于待分析的數據和變量,雖然變量之間沒有確定的數學關系,但可以找出最能代表它們之間關系的數學表達式:數學模型。 在圖書借閱規律研究方面,有兩方面的應用,一是根據師生以往和現在的借閱狀況,預測圖書將來的借閱狀況; 二是對影響借閱狀況的原因進行分析, 找出哪些是重要因素, 哪些是次要因素, 這些因素之間又有什么關系等等。
1.2 建模過程
使用多變量回歸分析方法得到的圖書預測模型通常表示為時間變量的多項式,并利用最小二乘原理求得多項式的系數,主要求解步驟如下:
(1)根據待借閱預測的圖書數量,預測模型通常可表示為下列多項式:

其中:
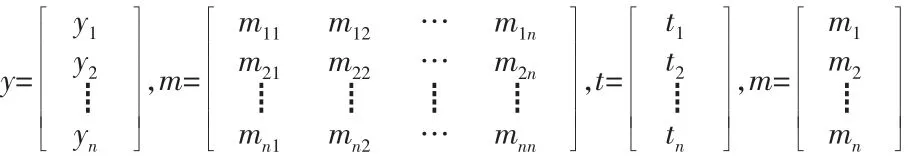
式中:y 為各種圖書的預測借閱量;m 為n×n 維模型系數矩陣;x為模型計算參數;c 為n 維待求常數向量。
(2)將各種圖書歷年的借閱數據代入方程式(1)中,計算出系數矩陣和常數項。
(3)將系數帶入方程(1),計算借閱預測值。
(4)計算擬合殘差,評估預測結果的可靠性。
2 神經網絡建模預測圖書借閱量
2.1 神經網絡建模原理
神經網絡建模的基本原理是:各種圖書歷年的借閱樣本數據通過模型的中間層作用于輸出層,經過非線形變換,產生輸出的模擬值,模型訓練的數據包括輸入矩陣和期望矩陣。模型輸出值和期望值之間的偏差量,通過調整輸入層與隱層之間的加權值、隱層與輸出層之間的加權值及閾值,使誤差沿梯度方向下降,經過反復學習訓練,確定與最小誤差相對應的網絡參數(加權值和閾值),訓練即告停止。 此時經過訓練的神經網絡即能對類似樣本的輸入數據,自行處理輸出誤差最小的經過非線形轉換的信息。 神經網絡模型結果如圖1 所示。
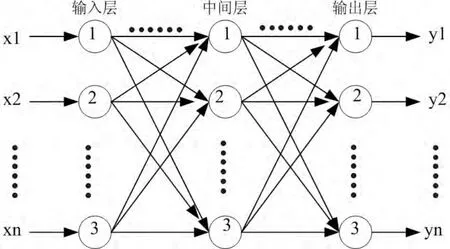
圖1 神經網絡模型結構Fig.1 The structure of a neural network model
2.2 神經網絡建模過程
(1)模型初始化。給各節點間賦予一個初始權值,一般可以設為(-1,1),設定節點間誤差函數e 和計算精度ε,規定最大學習次數M。
(2)輸入樣本數據,計算各隱層神經節點的輸入和輸出數據值。
(3)利用模型的輸出期望和實際輸出,計算誤差函數對模型節點的偏導數δm(k);計算隱層和輸出層對神經節點的偏導數δn(k)。
(4)利用神經節點的計算值修正節點間的連接權值。
(5)計算綜合精度,并判斷預測值是否符合要求。
3 灰色系統理論模型預測圖書借閱量
3.1 灰色系統建模原理
灰色系統模型預測, 是指對系統行為特征的發展變化進行預測,對既含有白信息又含有灰色信息的系統進行預測。 很多情況下,樣本數據中所顯示的信息具有隨機性,但隨機的信息中也包含了時序的特征,灰色模型預測就是利用這種規律來進行預測。 當前使用比較多的灰色預測模型是一階微分的GM(1,1)模型。它是基于隨機的原始時序,經累加后所形成的新的時序,該時序的規律用一階線性微分方程的解來逼近。
3.2 預測模型建模過程
(1)樣本數據處理和GM(1,1)方程的構建


式中:C 為中間值矩陣,Z 為原始樣本矩陣。
(3)預測方程精度評估。 精度評估主要是對模型方程的預測值和樣本數據進行比較,計算預測殘差和數據間的相對誤差。
(4)預測實現。
4 遺傳算法預測圖書借閱量
4.1 遺傳算法建模原理
遺傳算法是本質上是一種尋優方法,該方法借鑒生命學上的生物優勝劣汰原則,不斷的擇優搜索系統解。 該方法直接對待優化的系統進行求解,不需要對系統進行連續性限定和對系統求偏導數,因此在應用上更加靈活,并且有較強的全局搜索能力。 能對所有的樣本數據進行優化處理,并且自適應的調整搜索的方向,在樣本數據的漸次迭代中找到最優預測解, 而且得到的這個解象生物界的生命體進化那樣,有更強的適應性。
4.2 遺傳算法用于圖書預測建模過程
建模的過程參看流程圖2。
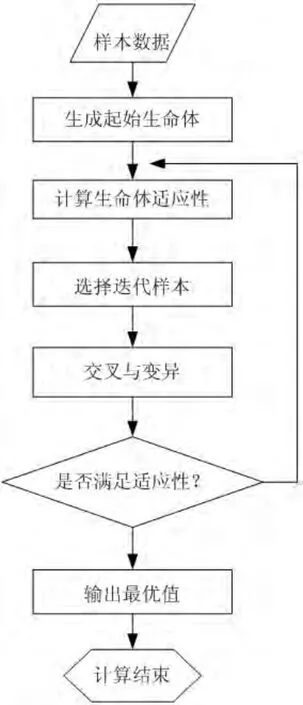
圖2 遺傳算法預測模型基本建模過程Fig.2 Prediction model of genetic algorithm
5 實例分析和預測結果比較
5.1 借閱樣本數據
表1 顯示的是河南農業大學文法學院圖書室2005~2012 年間兩種圖書的借閱量。

表1 2005~2012 年 兩種圖書借閱量Tab.1 Lending condition among 2005-2012 years
5.2 不同建模方法預測結果比較
(1)表2 顯示的是2013 年的兩種圖書預測結果
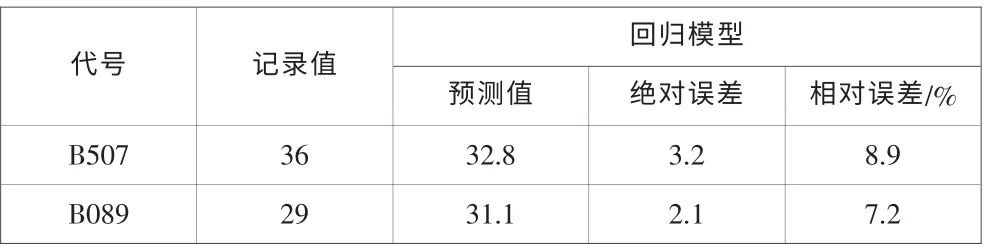
表2 回歸分析法年借閱趨勢預測結果Tab.2 Forecast results of year of variable regression
(2)表3 顯示的兩種圖書的灰色模型預測結果
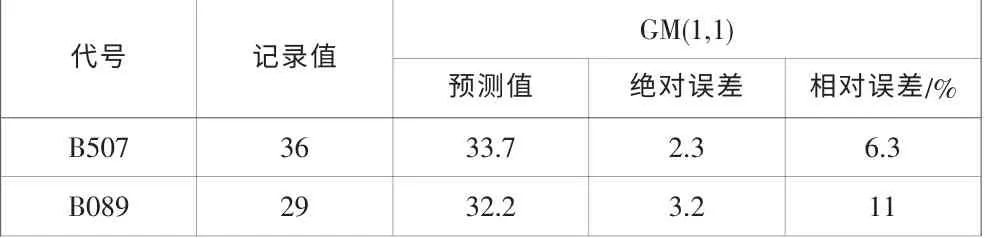
表3 灰色模型借閱趨勢預測結果Tab.3 Forecast results of year of grey system theory
(3)表4 顯示的兩種圖書的神經網絡模型預測結果
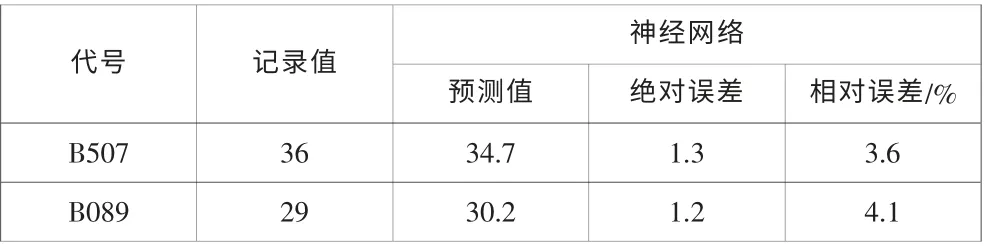
表4 神經網絡借閱趨勢預測結果Tab.4 Forecast results of year of neural network
(4)表5 顯示的兩種圖書的遺傳模型預測結果
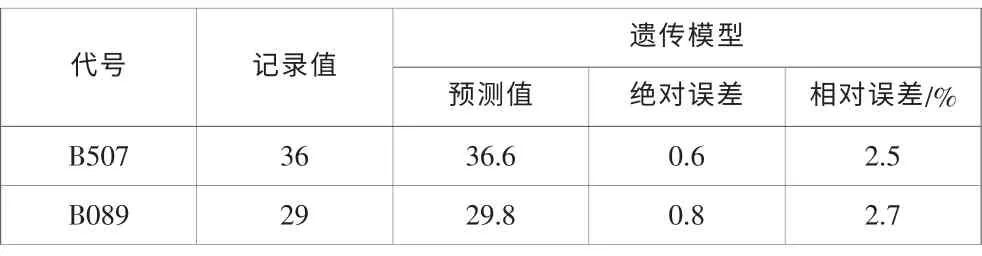
表5 遺傳模型借閱趨勢預測結果Tab.5 Forecast results of year of genetic algorithm
5.3 預測結果分析比較
從預測結果可以看出,遺傳算法模型的預測結果比較精確,絕對誤差和相對誤差都比較小, 灰色系統理論模型的預測結果相對比較弱,神經網絡模型和回歸模型的預測結果介于二者之間。 灰色系統理論是對數據進行逐次累加,找到數據間的線性規律,當原始數據間跳躍比較大時,這種疊加出的規律線性度并不明顯,所以預測結果比較弱。遺傳算法在每一步計算時,都要進行智能擇優搜索,而且對數據間的跳躍不敏感,所以在對這類數據進行處理和預測時,結果相對精確。神經網絡模型的精度和中間層的數量有很大的關系,對原始樣本數據量的要求也比較大,在不滿足上述條件時,預測精度比較弱,而回歸分析對數據的間的線性度要求比較高。
6 結語
本文分析了多變量回歸、灰色系統理論、神經網絡和遺傳算法在河南農業大學文法學院圖書室圖書借閱量預測模型構建方面的問題,對四種建模方法的建模過程和建模結果進行了分析。用部分圖書的年借閱量作為樣本數據,預測了2013 年這兩種圖書的借閱量,并與記錄值進行了比較。比較得出了遺傳算法更適合于圖書室借閱量預測的重要結論。
[1]劉思峰,等.灰色系統理論及其應用[M].3 版.科學出版社,2007.
[2]陳英,王秀山.基于灰色系統理論的農業院校院系紙質圖書借閱管理研究[J].科技視界,2003(3):114-116.
[3]陳英.小型圖書室用的智能型多功能入侵報警系統設計[J].科技信息,2013(25):376-377.
[4]趙海濤.數控機床熱誤差實時補償關鍵技術研究[D].上海交通大學圖書館,2006.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
