Bootstrap法在機電引信解除保險距離試驗中的應用
2015-01-13 01:53:04劉剛,王俠,陳眾,趙新
探測與控制學報 2015年3期
關鍵詞:方法
劉 剛,王 俠,陳 眾,趙 新
(中國華陰兵器試驗中心,陜西 華陰 714200)
正系數。
將N 個W1 樣本w11,w12,w13,…,w1 N 及W2 樣本w21,w22,w23,…,w2 N 分別 按照從小到大的 順 序進行排序,得到整理后的樣本。對于W1,變為w1(1),w1(2),w1(3),…,w1(N),對 于W2,變 為w2(1),w2(2),w2(3),…,w2(N),據此我們可構造出引信解除保險距離上下限分位數的單側置信區間,引入置信度γ,則:
對于p1 分位數,定義:
0 引言
引信解除保險距離試驗涉及引信安全性,歷來受到靶場的高度重視。近些年來,引信解除保險后立即起爆的試驗方法在實踐中應用較多,具體實施程序是對引信進行改裝后對空射擊,一旦解除保險,立即起爆。采用光學經緯儀測量炸點坐標,結合炮位坐標,可直接解算出引信解除保險距離。該方法在諸多引信定型試驗中得到成功應用,其優點在于試驗簡便,可控性強。
假設引信解除保險距離總體為正態分布N(μ,σ2),記xp1為總體p1分位數,稱為下限分位數,xp2為總體p2分位數,稱為上限分位數,實際中一般取p1=0.05,p2=0.95。在引信解除保險后立即起爆試驗中,若干發引信可視為從總體中隨機抽取的樣本,我們的任務是利用樣本數據估計總體的上下限分位數。現行數據處理方法為計算樣本均值和標準差,以樣本均值和標準差代替總體均值和標準差,從而直接計算得到總體上下限分位數。這種方法簡單易行,但顯而易見,樣本均值和標準差可能無法準確反映總體均值和標準差,從而在計算上下限分位數時出現較大散布,造成試驗誤判。
Bootstrap法在武器系統試驗數據處理方面已得到大量應用,但在引信解除保險距離試驗領域尚未見報道。為解決現行方法存在的問題,本文提出了基于Bootstrap法的機電引信解除保險距離試驗數據處理方法。
1 現行方法原理及仿真計算
1.1 現行方法原理
引信解除保險距離X 可視為一隨機變量,服從正態分布(根據以往經驗,引信解除保險后立即起爆試驗數據均能通過正態性分布檢驗),即X~N(μ,σ2),根據統計原理[1]有:

因此,N(μ,σ2)的ρ分位數xρ是以下方程的解
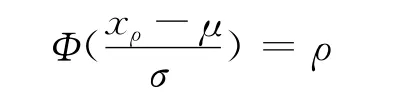
式中Φ(·)為標準正態分布函數,進一步得:
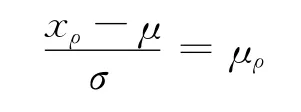
式中μρ為標準正態分布的ρ 分位數,進一步得:

設引信解除保險即起爆試驗中獲得的樣本序列為x1,x2,x3,…,xn,那么μ 的估計為:
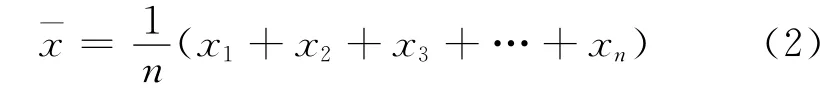
σ的估計為:
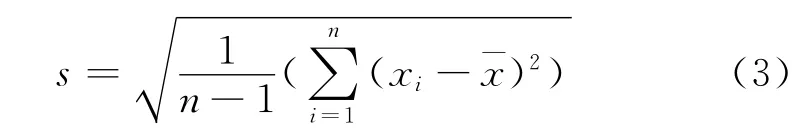
將式(2)、式(3)代入式(1),可得:

式(4)即為n個樣本條件下正態分布總體的p分位數估計公式。
1.2 現行方法仿真計算
仿真計算的一般流程為:
1)假設總體分布已知,即正態分布N(μ,σ2)的兩個參數μ、σ已知;
2)在N(μ,σ2)下生成3 000組隨機樣本,樣本量為n;
3)計算每組樣本的樣本均值和標準差;
4)按式(4)計算每組樣本的總體上下限分位數。
令μ=120,σ=10,n=10,下限分位數取x0.05,下限分位數取x0.95。編制仿真程序,計算結果如表1。同時給出其中一次仿真計算結果,見表2。
從表1中可看出,平均來說,現行方法對于總體參數μ、σ、x0.05、x0.95的估計結果是較理想的,然而,這一結論只在“平均意義”成立,由于抽樣的隨機性,造成^x0.05、^x0.95有較大的散布,單次樣本下^x0.05與x0.05真值之間的差值在(-18.37,15.38)間變化;^x0.95與x0.95真值之間的差值在(-15.55,17.67)間變化,而試驗只對單次抽樣負責,這意味著單次試驗散布較大,可能存在比較嚴重的估計偏差。
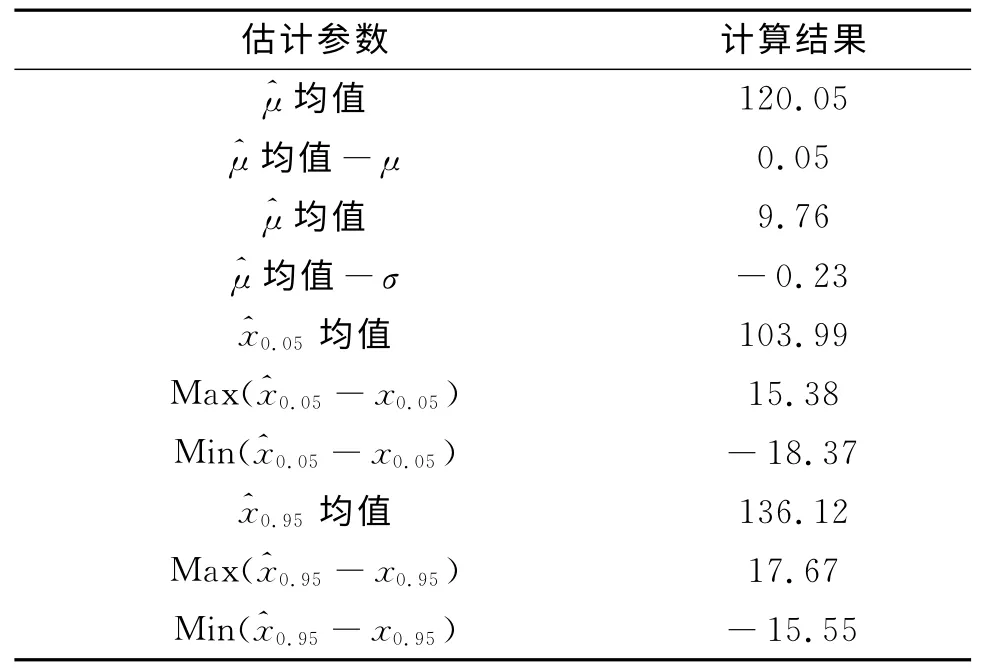
表1 現行方法仿真結果

表2 現行方法單次仿真結果Tab.2 Single Simulation recsult
對于x0.05,術語可表達為引信在距炮口103.55m以內解除保險的概率為0.05,但在單次試驗中,計算結果可能表達為引信在距炮口103.55+15.38=118.93m 以內解除保險的概率為0.05,人為地把引信保險距離擴大了15.38 m;對于x0.95,可表達為引信在距炮口136.44m 以外解除保險的概率為0.95,同樣在單次試驗中,計算結果可能表達為引信在距炮口136.44-15.55=120.89m以外解除保險的概率為0.95,人為地把引信可靠解除保險距離減小了15.55m。
1.3 對判定引信解除保險距離上下限的討論
對于引信解除保險距離下限,意味著在此距離以內,引信解除保險的可能性較低,估計值應盡量避免冒進,我們關心的是估計值的置信下限,這樣才能有把握為部隊使用提供更多的安全余量;對于引信解除保險距離上限,意味著在此距離以外,引信解除保險的可能性較高,我們關心的是估計值的置信上限,這樣才能有把握保證引信完全解除保險,進而不影響戰術使用。
以上述討論內容為出發點,根據所謂新單側容限系數法[2],將總體p1、p2分位數分別視為一隨機變量,表達式分別為:
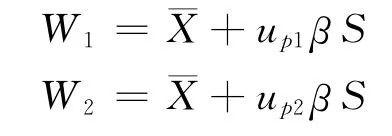
正系數。
將N 個W1樣本w11,w12,w13,…,w1N及W2樣本w21,w22,w23,…,w2N分別 按照從小到大的 順 序進行排序,得到整理后的樣本。對于W1,變為w1(1),w1(2),w1(3),…,w1(N),對 于W2,變 為w2(1),w2(2),w2(3),…,w2(N),據此我們可構造出引信解除保險距離上下限分位數的單側置信區間,引入置信度γ,則:
對于p1分位數,定義:

式(5)稱為在置信度γ下,引信解除保險距離p1分位數的置信下限。
對于p2分位數,定義:
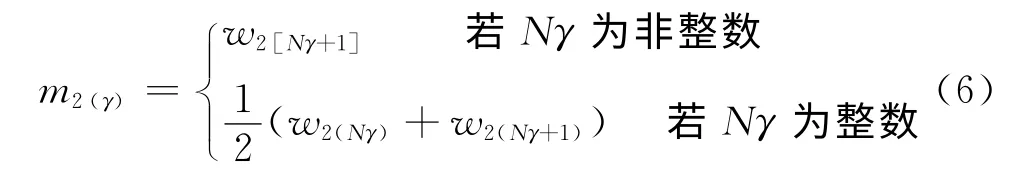
式(6)稱為在置信度γ下,引信解除保險距離p2分位數的置信上限。
2 Bootstrap法在引信解除保險距離上下限估計中的應用
2.1 Bootstrap法簡介
Bootstrap法是斯坦福大學Efron教授提出的一種逼近復雜統計量估計值分布的通用方法,該方法擺脫了傳統統計方法對分布假定的限制,只依賴于給定的觀測樣本,適合于任何分布和任何感興趣的參數估計。
Bootstrap法的核心工作流程是利用經驗分布函數代替總體分布函數[3],從經驗分布函數中隨機抽取樣本以估計統計量的抽樣分布。相當于從樣本x1,x2,x3,…,xn中進行有放回再抽樣,其中x1,x2,x3,…,xn中每一個xi以等概率出現。其基本步驟為:
1)由樣本x1,x2,x3,…,xn構造經驗分布Fn。
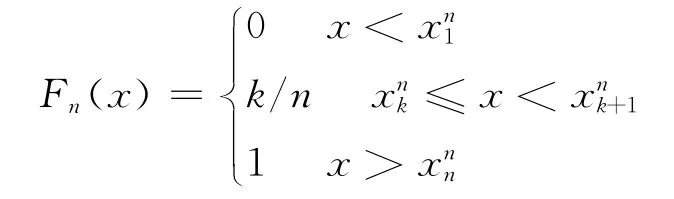
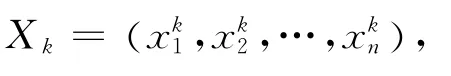
3)用θ*=θ*(X*,Fn)的分布去逼近θ=θ(X,F)的分布(θ*的分布稱為Bootstrap分布)。
從以上關于Bootstrap 法原理的介紹可看出,Bootstrap法解決的恰恰就是前文中N 個W1樣本w11,w12,w13,…,w1N及W2樣本w21,w22,w23,…,w2N的構造問題,因此Bootstrap法可用于計算引信解除保險距離p1分位數的置信下限及引信解除保險距離p2分位數的置信上限。
由于以上置信上下限估計方法在概率收斂性方面還存在一些不足,Efron提出了改進,即糾偏百分位法,其思路簡述為若出現大部分Bootstrap 估計量^θt=θ(X*t),t=1,2,3,…,T 小于實際樣本統計量,則意味著Bootstrap 模擬低估了實際樣本統計量,為糾正這一偏差,置信上下限必須向大值調整;相反,如果大部分Bootstrap 估計量大于實際樣本統計量,則意味著Bootstrap 模擬高估了實際樣本統計量,為糾正這一偏差,置信上下限必須向小值調整。該糾偏過程由糾偏量d0實現[4-6]。
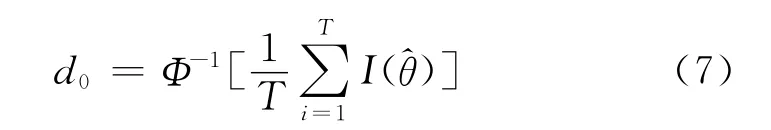
式(7)中,Φ-1[·]為標準正態分布函數的反函數,I(·)為示性函數,其定義為:
當需計算引信解除保險距離的這p1分位數置信下限時,
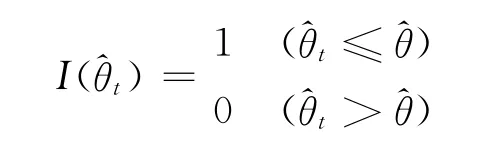
這樣,上文提到的引信解除保險距離p1分位數的置信下限修正為m1(1-γ+2d0)。
當需計算引信解除保險距離的p2分位數置信上限時,
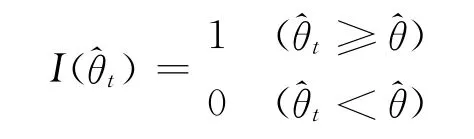
這樣,上文提到的引信解除保險距離p2分位數的置信上限修正為m2(1-γ+2d0)。
2.2 具體實施步驟及仿真計算
Bootstrap法的簡要計算流程為:
1)假設正態分布N(μ,σ2)的兩個參數μ、σ已知,從總體中隨機生成n個樣本x1,x2,x3,…,xn,方便起見,與前文例子保持一致,取μ=120,σ=10,n=10;
2)計算以上n個樣本的p1分位數估計=+以及p2分位數估計=+,取p1=0.05,p2=0.95;
3)以樣本x1,x2,x3,…,xn為基礎,進行T(T=1 000)次Bootstrap抽樣,獲得T 個樣本,,,…,,計算每個Bootstrap樣本的p1分位數估計=ˉx*+μp1βs*以及p2分位數估計=+μp2βs*;
4)按照式(7)分別計算兩個糾偏量;
6)考慮到隨機性因素,重復1)-4)k 次(本文取k=3 000)。
編制相應仿真程序,計算結果如表3。
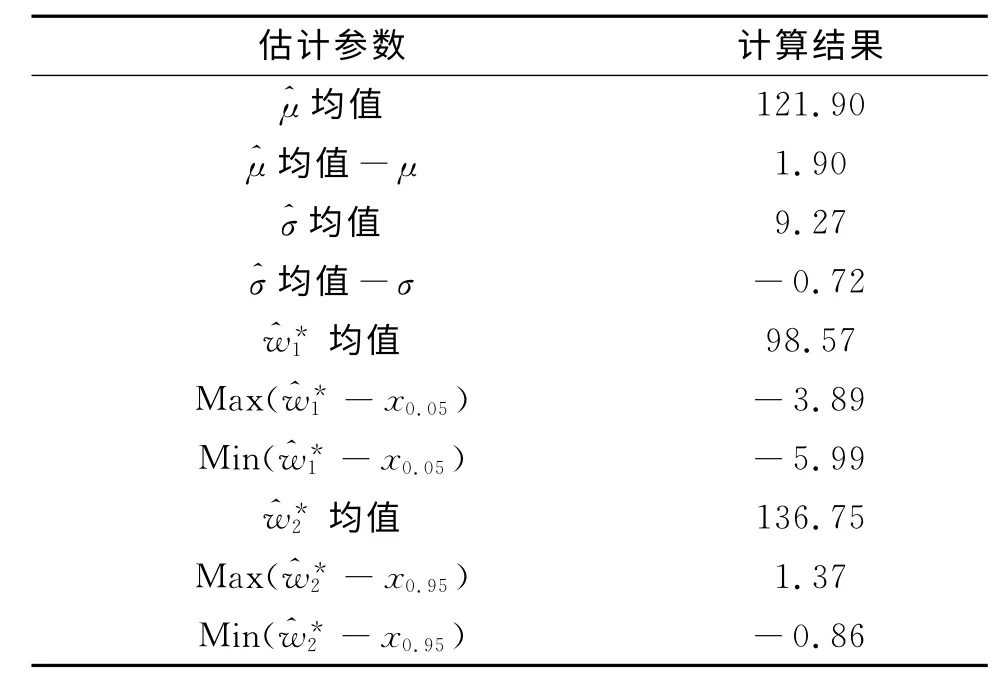
表3 Bootstrap法仿真結果
同時給出其中一次仿真計算結果,見表4。
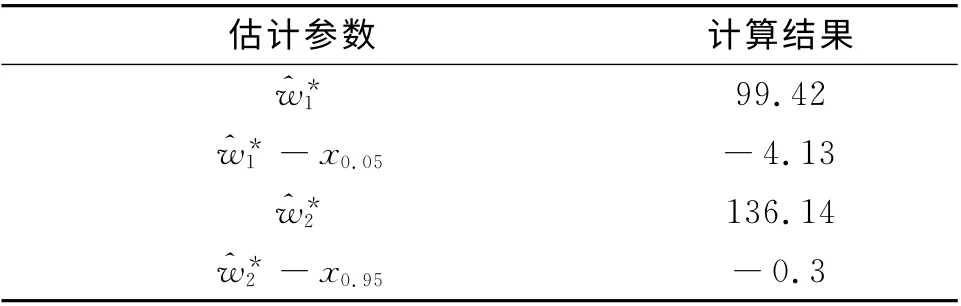
表4 Bootstrap法單次仿真結果Tab.4 Single simulation result of Bootstrap
從表3中可看出,相對于現行方法,Bootstrap法對于總體參數μ、σ、x0.05、x0.95的估計結果均值基本一致,但對于x0.05、x0.95的估計,單次樣本下^w*1與x0.05真值之間的差值在(-5.99,-3.89)間變化;^w*2與x0.95真值之間的差值在(-0.86,1.37)間變化,最大偏差率由17.7%降低為5.8%,估計結果的單次散布較現行方法大為減小,從而降低了試驗誤判的可能性。
3 結論
本文提出了基于Bootstrap法的機電引信解除保險距離試驗數據處理方法,該方法可有效克服現行方法中單次試驗估計偏差大的缺陷。仿真計算結果表明Bootstrap 法上下限分位數單次散布較小,大大降低了試驗誤判的可能性。
[1]峁詩松.統計手冊[M].北京:科學出版社,2003.
[2]李洪雙,呂震宙.小子樣場合下估算母體百分位值置信下限和可靠度置信下限的Bootstrap 方法[J].航空學報,2006,27(5):789-794.
[3]Wendy L.Martinez.Computational Statistics Handbook with MATLAB[M].London:Chapman & Hall,2002.
[4]Efron B.The jack knife,the bootstrap,and other resampling plans[M].Philadelphia:The Society for Industrial and Applied Mathematics,1982.
[5]Efron B.Tibshirani R J.Bootstrap methods for standard errors,confidence intervals,and other measures of statistical accuracy[J].Statistical Science,1986(1):54-77.
[6]Efron B.Tibshirani R J.An introduction to the bootstrap[M].London:Chapman and Hall,1993.
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
