改進蟻群算法在支持向量機參數中的應用
2015-01-13 08:09:00劉繼承隋殿雪
化工自動化及儀表 2015年4期
劉繼承 解 敬 隋殿雪
(東北石油大學電氣信息工程學院,黑龍江 大慶 163318)
1 SVM的基本思想與參數①
SVM是一種基于統計學習理論的模式識別方法[3],其基本思想是通過核函數將樣本空間映射到特征空間,在特征空間中尋求原樣本的最優分類面,得到輸入變量和輸出結果之間的一種線性或非線性關系[4],即尋找SVM進行模式分類[5]。
對線性可分的樣本集(xi,yi)(i=1,2,…,n,n為學習樣本數目),xi=Rd表示輸入變量,yi∈[-1,+1]為輸出變量。利用非線性映射φ(·),將輸入空間的數據映射到高維特征空間,并構造最優分類超平面:
f(x)=w·φ(x)+b=0
(1)
式中b——閾值;
w——權值矢量。
為了使結構風險最小化,分類應滿足以下約束:
yi[(w·xi)+b]-1≥0,i=1,2,…,n
(2)
對于線性不可分的問題,引入松弛變量ξi來構建最優超平面。允許在一定程度上違反間隔約束優化問題,則有:
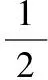
(3)
yi[(w·xi)+b]≥1-ξi,ξi≥0,i=0,1,…,n
(4)
此時根據核函數理論,應存在核函數K=(x,x′)=[Φ(x),Φ(x′)],從而使:
(5)
(6)
C≥αi≥0,i=1,2,…,l
(7)
其中,C為誤差的懲罰參數,αi>0對應的點是支持向量。進而構造出決策函數:
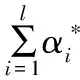
b*)
(8)
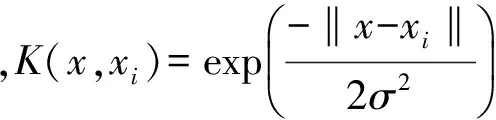
SVM參數的確定影響其學習和推廣能力[6]。對于RBF核函數的SVM來說,其參數包括懲罰參數C和核寬度σ。懲罰參數C是在結構風險和樣本誤差之間的折衷,其值越大,允許的誤差越小;核寬度σ與學習樣本的輸入空間范圍或寬度有關,樣本的輸入空間越大,σ取值越大。
2 改進蟻群算法優化SVM參數
由于蟻群算法全局優化參數的時間較長,為了減少優化參數的時間,筆者有效結合了交叉驗證法和蟻群算法來優化SVM參數,最終達到理想的識別效果。
2.1 交叉驗證法
首先將數據分成n個同樣大小的子集;然后選取n-1個子集作為訓練樣本,預測那個沒有參加訓練的子集,共進行n次,將全部數據中的每個樣本點都預測一遍,但準確率并不是很穩定;最后記錄每次預測的(σ,C),挑選準確率相對較高的幾組,運用蟻群算法再次尋優,得到最佳參數,進而得到滿意的識別結果。
2.2 蟻群算法
1992年意大利學者Dorigo M首先提出了一種源于蟻群覓食行為的智能仿生蟻群優化算法[7],該算法具有智能搜索、全局優化、較強的魯棒性、正反饋、分布式計算和易與其他算法結合的特點。筆者通過蟻群優化算法優化SVM參數σ、C的具體操作步驟包括:參數初始化;通過蟻群進行局部和全局搜索,不斷更新信息素,同時將每代全局最優解保存下來。
2.2.1參數初始化
首先,將利用交叉驗證法得到的幾組參數(σ,C)隨機分配給每只螞蟻,然后對訓練集通過SVM學習得到相應的誤差模型:
Δt(i)=α-Error(i)
(9)
用根據上述誤差模型預測得到的誤差值來確定螞蟻i的位置信息素:
T0(i)=α-Error(i)
(10)
其中,α=2。由式(10)可知:誤差值越小,螞蟻的信息素越大。
2.2.2局部和全局搜索
根據螞蟻留下來的信息素的大小確定每只螞蟻下一步的轉移概率:
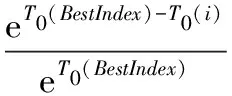
(11)
其中,BestIndex為得到信息素最大的螞蟻。
建立動態揮發因子。在最初階段信息素揮發因子相對較小,隨著不斷增加進化次數,信息素揮發因子逐漸增大。信息素的揮發因子定義為:
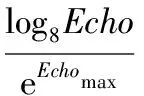
(12)
其中,k=0.1;Echo為當前的進化代數;Echomax為蟻群的最大進化代數。
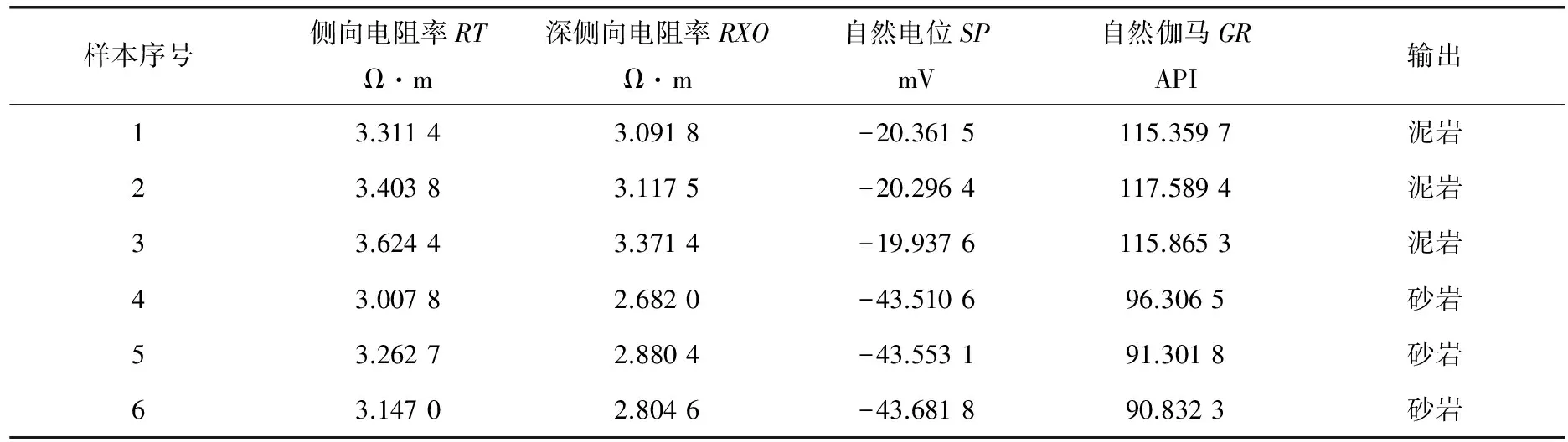
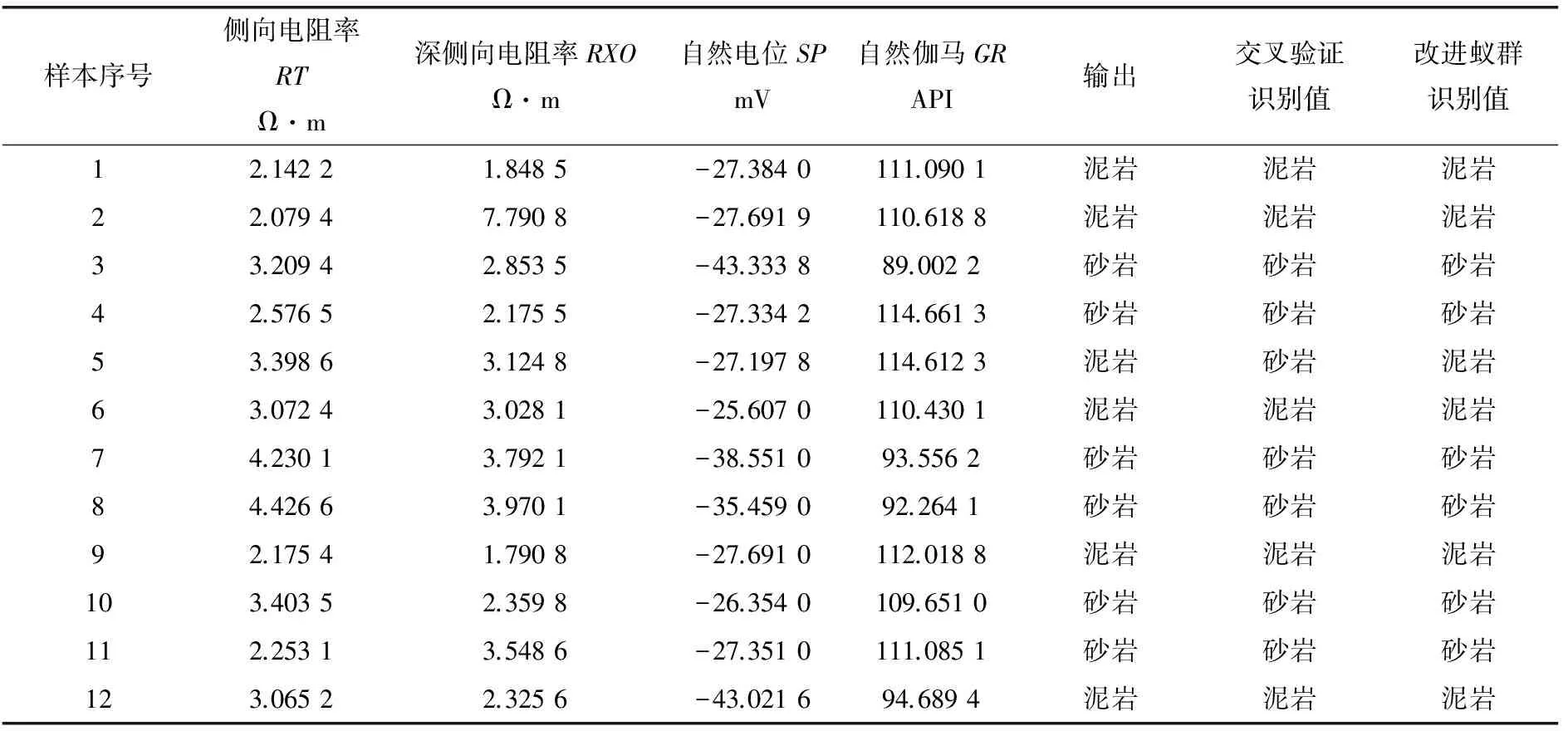
建立動態轉移因子。在每輪迭代過程中,根據螞蟻信息素的大小來確定全局轉移因子p0。設螞蟻數量為m,計算e-T0(i)(i=1,2,…,m),并對計算結果進行升序排列,得到序列T1(j)(j=1,2,…,m)。當Echo 如果螞蟻的轉移概率小于p0,則進行局部搜索,否則進行全局搜索。在開始搜索過程中,大部分螞蟻進行局部搜索,從而保證螞蟻能搜索到更好的解;在后期搜索中,大部分螞蟻進行全局搜索,避免陷入局部最優,得到全局最優解。 更新信息素。根據蟻群優化得到的SVM參數進行信息素更新,更新規則為: T0(i)=(1-ρ)T0(i)+Δt(i) (13) 在每次迭代的過程中,將信息素最大的螞蟻保存下來,然后根據誤差模型計算誤差值,返回2.2.1小節進行迭代循環。 如果迭代的次數滿足開始設置的要求,則搜索完成,從而得到最佳螞蟻,將最佳螞蟻轉換成SVM參數σ、C。 根據確定的SVM參數σ、C計算相應的目標函數值,最后進行誤差分析(圖1)[8]。 圖1 蟻群算法的SVM參數優化流程 選取大慶油田某井的測井數據中有代表性的屬性來構成樣本的維數。筆者選取具有代表性的某油井在不同深度中的側向電阻率RT、深側向電阻率RXO、自然電位SP和自然伽馬GR共4個參數進行巖性預測,輸出為泥巖和砂巖(表1)。 表1 學習樣本集 蟻群算法中參數的設置:螞蟻數m=25,揮發因子ρ=0.7,步長0.2,α=0.5,β=1。SVM參數C、σ采用二進制編碼,C∈[0,500],σ∈[0.01,100.00]。最大進化代數為100,最優解碼誤差為0.02,最終C=10,σ=0.19。 同時為證明基于改進蟻群算法優化SVM參數的優越性,采用交叉驗證法作為參比模型,其優化后的SVM參數C=1,σ=0.01。 預測樣本通過交叉驗證法和改進蟻群算法優化參數,兩種方法的識別結果見表2,識別準確率分別為91.666 7%和100%,說明采用改進蟻群算法優化SVM參數的識別準確率高于采用交叉驗證法的識別準確率,證實筆者提出的改進蟻群算法是分類準確率較高的參數優化方法。 表2 交叉驗證法和改進蟻群算法識別結果的比較 SVM參數的優化是當前模式識別研究的一項很有意義的課題,筆者通過采用改進的蟻群算法(即交叉驗證法與蟻群算法的有效結合)對SVM參數進行優化之后,不僅縮短了參數優化的時間,而且有效地改進了其學習性能,提高了學習精度和識別準確率。 [1] Ertekin S,Bottou L,Giles C L.Nonconvex Online Support Vector Machines[J]. IEEE Transactions on Pattern Aanlysis and Machine Intelligence,2010,33(2):368~381. [2] 莊嚴,白振林,許云峰.基于蟻群算法的支持向量機參數選擇方法研究[J].計算機仿真,2011,28(5):216~219. [3] 陳桂娟,賈春雨,鄒龍慶,等.基于腐蝕圖像與支持向量機的CO2腐蝕類型識別方法研究[J].化工機械,2014,41(6):742~745. [4] 文傳軍,詹永照,陳長軍.最大間隔最小體積球形支持向量機[J].控制與決策,2010,25(1):79~83. [5] 楊智明,彭宇,彭喜元.基于支持向量機的不平衡數據集分類方法研究[J].儀器儀表學報,2009,30(5):1094~1099. [6] 王凱,張永祥,姚曉山,等.支持向量機懲罰參數的自適應調整方法[J].計算機工程與應用,2008,44(26):45~47. [7] 韓虎,黨建武,任恩恩.基于自適應小波支持向量機的圖像去噪研究[C].第七屆全國信號與信息處理聯合會議暨首屆全國省(市)級圖象圖形學會聯合年會論文集.蘭州:蘭州交通大學,2008:349~352. [8] 劉瑜,馬良.基于元胞蟻群算法的臥式內壓容器優化設計[J].化工機械,2010,37(1):17~20,89.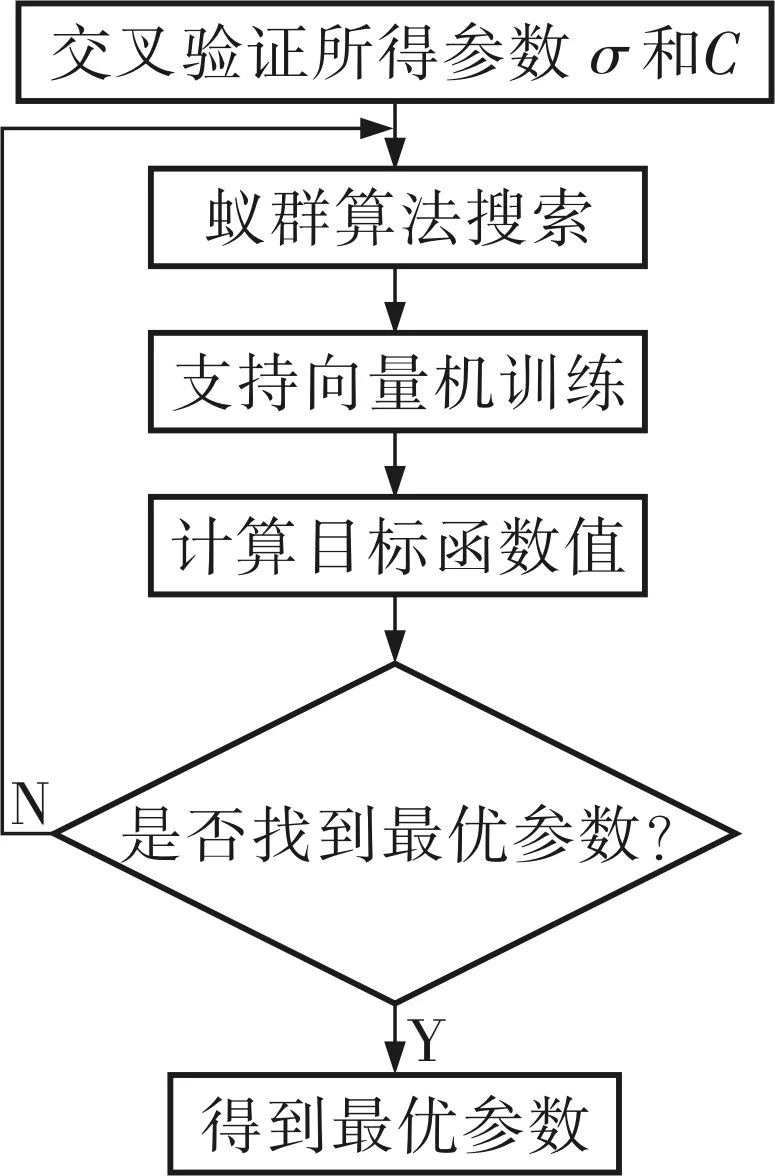
3 仿真實驗
3.1 數據源
3.2 算法的參數設置
3.3 結果與分析
4 結束語
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
中華手工(2017年2期)2017-06-06 23:00:31
現代企業(2015年2期)2015-02-28 18:45:09
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
