基于五元組的詞語搭配自動抽取
2015-01-28 08:14:32孫婷婷
電子設計工程 2015年19期
孫婷婷
(江蘇科技大學 計算機科學與工程學院,江蘇 鎮江 212003)
計算語言學的發展為語言研究開辟了一個嶄新的領域,詞語搭配以其在機器翻譯,信息檢索,語義自動糾錯,問答系統及語言產生、理解、學習中的重要作用,成為了自然語言處理研究領域的重點研究方向之一。
在國外,最早開展搭配研究的是Choueka,他利用《紐約時代周刊》約1100萬詞的語料庫,通過計算重復出現的相鄰詞串的共現頻率來抽取詞語搭配[1]。之后,Church和Smadja等人都利用統計量,分別做過搭配抽取試驗,準確率可達80%左右[2-3]。在國內,較早開始研究的是清華大學的孫茂松教授,他借鑒國外語言學和語料庫學相關知識,提出了計算跨距[-5,+5]的詞語之間搭配強度、離散度及尖峰三個指標,但是利用該方法進行詞語搭配抽取的準確率不高[4]。之后,曲維光等提出了一種基于框架的詞語搭配抽取方法,孫宏林提出了“統計+規則”的方法[5-6]。還有一些研究者開始嘗試利用機器學習算法來進行中文詞語搭配抽取[7]。如山西大學的白妙青利用支持向量機來對“V+V”形式的詞語搭配進行研究,王素格和楊軍玲提出利用最大熵模型和投票法來獲取漢語中“V+V”詞性構成形式的詞語搭配[8]。這些方法都取得了不錯的效果。
本文首先介紹了搭配的定義,并給出了語義搭配和句式搭配兩類搭配的定義。然后提出了五元組模型,并依此為基礎,利用統計量做了實驗分析。
1 搭配的定義
對于搭配的定義,從不同的理論角度與應用背景出發,語言學研究學者和自然語言處理研究人員都有著各自不同的見解。本文采用的是由曲維光給出的有關搭配的定義:搭配是具有一定語法關系的詞語組成的一種具有任意性、并重復出現的詞語組合[5]。從定義中可以看出,搭配具有重復性、任意性、領域相關性、符合一定的句法結構等性質。在上述定義的基礎上,本文給出了兩類搭配的定義,這也是本文的提取目標。
1.1 語義搭配
定義 S=(x,w,y,w′,z) 為漢語中語意表達明確的一條文本信息,從該段文本信息中提取出的語義搭配記為c。其中:
1)w,w′是文本信息中的單個漢語分詞項,在語料庫中的詞性標注為/n(名詞)、/a(形容詞)、/ad(副形詞)或/v(動詞);
2)x,y,z是文本信息中的單個分詞項,或是由多個分詞項構成的短語、短句。 其中,x,y,z可以為空;
3)c是w與w′的結構性組合,并且能描述w與w′之間的某種語義關系;
簡單來說,w,w′就是語料庫某句話中兩個獨立的分詞項,它們的詞性可以是名詞、形容詞、副形詞或動詞中的任意兩種(可重復)。當不考慮句子中的其他成分,把這兩個詞組合在一起構成一個新詞時,這個新詞符合人們的日常語言習慣并且能描述w,w′這兩個詞之間的某種語義關系。
例如,w 為“金屬”,w′為“制品”,則我們可以得到 c 為“金屬制品”,其中,w 為 w′的材質;再如,w 為“仔細”,w′為“詢問”,則我們可以得到c為“仔細詢問”,其中w描述了w′動作的程度;再如,w 為“團結”,w′為“一致”,則我們可以得到 c為“團結一致”,其中w和w′為意思相近的形容詞,或者稱為并列形容詞。
1.2 句式搭配
定義 S=(x,w,y,w′,z) 為漢語中語意表達明確的一條文本信息,從該段文本信息中提取出的句式搭配記為c。其中:
1)w,w′是文本信息中的單個漢語分詞項,它們在語料庫中的詞性標注可以為/n(名詞)、/v(動詞)、a/(形容詞)、/p(介詞)、/c(連詞)、/f(方位詞)、/s(處所詞)或/Ng(名語素);
2)x,y,z是文本信息中的單個分詞項或是由多個分詞項構成的短語、短句;
3)c是w與w′的結構性組合,并且w與w′存在一定的句式結構關系;
簡單來說,w,w′就是語料庫某句話中兩個獨立的分詞項,它們的詞性可以是名詞、形容詞、動詞、介詞、連詞、方位詞、處所詞或者名語素中的任意兩種(可重復)。當不考慮句子中的其它成分,把這兩個詞組合在一起時能構成一個短語,并且該短語符合人們的日常語言習慣。
例如,w 為“按”,w′為“處理”,則我們可以得到 c為“按…處理”;w 為“在”,w′為“中”,則 c 為“在…中”;w 為“從”,w′為“到”,則 c 為“從…到”;
2 搭配抽取相關技術
本節對搭配抽取的相關技術進行介紹。首先介紹了實驗中用到的3種統計量,然后介紹了搭配抽取的評價指標。
2.1 搭配抽取統計量
目前,基于各種統計量來衡量搭配顯著程度的方法已得到了廣泛的研究應用,主要的統計量有互信息(MI)、t值、χ2檢驗、對數似然比等等。以下將對實驗中用到的三種統計量進行詳細介紹。
1)互信息
互信息 (Mutual Information)是信息論中重要的信息度量,一般用來對兩個信號的關聯強度進行衡量。在詞語搭配抽取中,互信息則用于衡量兩個詞語的搭配強度,互信息值越大,表明詞語搭配的強度越強[8]。對于兩個詞語w1,w2,它們之間的互信息計算公式如下:

其中 P(w1,w2)表示詞語 w1和 w2共同出現的概率,P(w1)表示詞語w1在語料庫中出現的概率,P(w2)表示詞語w2在語料庫中出現的概率。
2)t值
在統計學中,t值一般用來處理對數據的檢驗問題。首先提出一個假設,然后計算數據集中的相應參數,據此來確定能否拒絕該假設[10]。這種思路在搭配自動抽取中也得到了廣泛使用,原理如下:
假設兩個詞語w1和w2相互獨立,不構成搭配,則:
H:

假設從語料庫中抽取的樣本分布呈正態分布,計算統計量t,考察其實際均值x與期望均值μ的差異,得到的t值越大,說明差異越大,越能拒絕原來的假設。則這兩個詞能組合成搭配的可能性很大。t值計算公式如下:

其中,N為語料庫中的總詞頻數,C12為w1和 w2的共現頻數,C1為 w1的頻數,C2為 w2的頻數。
3)χ2檢驗
卡平方(χ2)檢驗是一種有效的假設檢驗方法,常被用于檢驗多個正態隨機變量是否具有獨立性[7]。在詞語搭配獲取研究過程中,卡平方(χ2)檢驗的應用思路是:先假設待確認搭配中的兩個分詞項分布獨立,然后計算這兩個分詞項的實際觀測值與期望值的差異之和。其中,實際觀測值是指這兩個分詞在語料中實際單獨出現的概率以及它們的共現概率,期望值是指當滿足假設即這兩個分詞分布獨立時,它們在語料中出現的概率及共現概率。卡平方檢驗是利用觀測值與期望值之間的差異來判斷假設是否成立的[3]。卡平方檢驗計算公式如下:
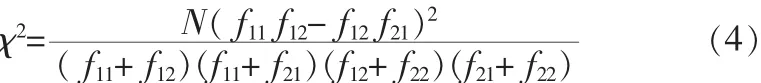
其中,f11,f12,f21,f22分別是 w1和 w2在各種情況下的頻率,即 f(w,w′),f(┐w,w′),f(w,┐w′),f(┐w,┐w′)。
2.2 評價指標
目前,搭配抽取性能評估方法主要有兩種,即內部評估和外部評估。內部評估是指將計算機自動獲取到的詞語搭配集通過人工校對或是將其與現有搭配詞典匹配進行比較,從而得到該搭配集中正確搭配的個數,再獲得該詞語搭配自動獲取算法的準確率、召回率等評價指標;外部評估是指根據詞語搭配的不同應用領域,考察抽取到的詞語搭配集在該領域某些實際應用系統如信息檢索、機器翻譯等中的應用效果來評估該搭配抽取算法的性能。本文采用的是內部評估方法,涉及到準確率,召回率,F值三項指標,具體闡述如下:
1)準確率(Accuracy)
準確率指的是抽取的搭配中標準搭配所占搭配總量的比例,其計算公式如下:

其中E(c′)指的是提取出的搭配中標準搭配的數量,E(c)指的是提取出的搭配的總數量。
2)召回率(Recall)
召回率指的是抽取的搭配中標準搭配所占語料庫中標準搭配的比例,其計算公式如下:
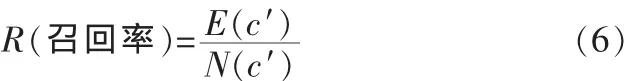
其中 E(c′)指的是提取的搭配中標準搭配的數量,N(c′)指的是語料庫中標準搭配的總數量。
3)F1-Measure
雖然準確率和召回率都體現了該搭配自動獲取算法的性能,但是這兩個指標之間卻是互相制約的。在這里,引入信息論中的F1-Measure概念來尋求搭配自動獲取的準確率與召回率之間的平衡點。公式如下:

其中,A為準確率,R為召回率,β為參數,一般情況下,β的取值為1,則F1-measure公式為:

3 搭配提取模型
本文借鑒前人的研究方法,給出了一種基于五元組的搭配提取模型。
定義:定義 G=(w1,f,w2,g,w3)為從語料庫中提取出的五元組。其中w1,w2和w3為單個分詞項,f和g為分詞的間距,取值 0,1或者 2。 從中可以提取出候選搭配 w1w2、w1w3和w2w3。例如,下面這句話中可以提取出的部分五元組如表1所示。
“在/p 這/r一/m 年/q 中/f,/w 中國/ns的/u 改革/vn 開放/vn 和/c現代化/vn 建設/vn 繼續/v向前/v邁進/v。/w”

表1 五元組實例Tab.1 Examp le of quintuple
有了五元組的定義,利用由北京大學計算語言學研究所和富士通研究開發中心有限公司共同制作的1998年 《人民日報》標注語料庫(一月份),提取第二節中給出的兩類搭配的具體步驟如下:
2)獲取五元組。利用語段序列集生成五元組候選集并對其進行初步數據統計。
3)初步篩選。在五元組候選集中,將分詞項中漢語個數少于2的五元組剔除。
4)再次篩選。分別抽取符合語義搭配和句式搭配定義的五元組集,用于語義搭配和句式搭配的提取。
5)獲取候選搭配集。利用4)中的五元組集合,獲取候選搭配集。
6)提取搭配。利用統計量,從候選搭配集中提取搭配。具體流程圖如圖1所示。
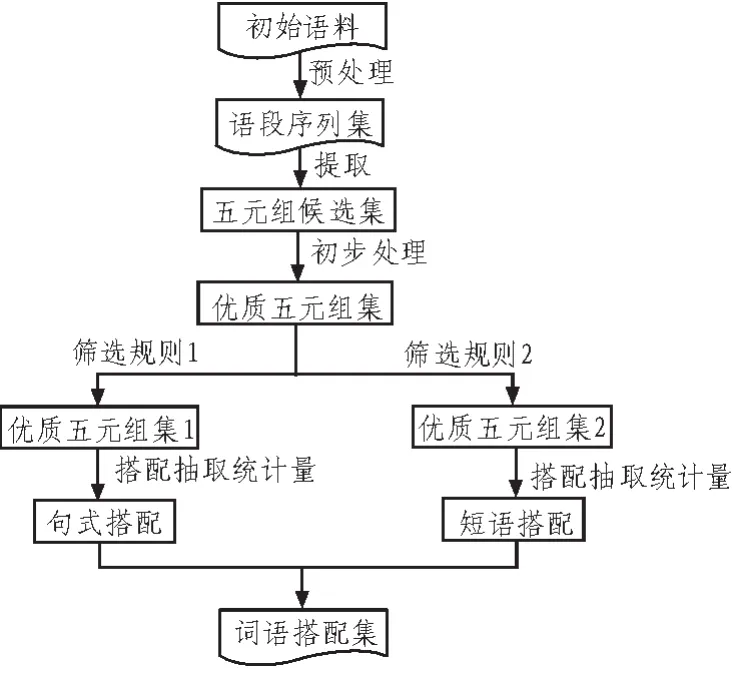
圖1 搭配抽取流程Fig.1 Collocation extraction process
4 實驗分析
搭配獲取實驗的第一步是要進行語料庫的選取,本文所采用的語料庫是由北京大學計算語言學研究所和富士通研究開發中心有限公司共同制作的1998年《人民日報》標注語料庫(一月份),網絡下載地址:http://download.csdn.net/detail/xmujay/1259040。該語料庫是嚴格按照人民日報的日期、版序、文章順序編排的,該語料庫實現了對110多萬字的中文文章進行分詞及詞性標注。經統計,本語料庫共含有50 178個詞,總的詞頻數為22 708 665,共22 720行。
利用C#編程語言,根據上述搭配提取流程,共獲得五元組70 63 130個,其中符合語義搭配定義的五元組1 460 033個,符合句式搭配定義的五元組866 308個。抽取結果如表2和表3所示。

表2 語義搭配抽取結果Tab.2 Results of sem antic collocation extraction
從上面兩個表格中可以看出,不管是語義搭配還是句式搭配,效果最好的統計量為互信息統計量,準確率可達80%,召回率達到64%。相對于各統計量,句式搭配結果要優于語義搭配結果。
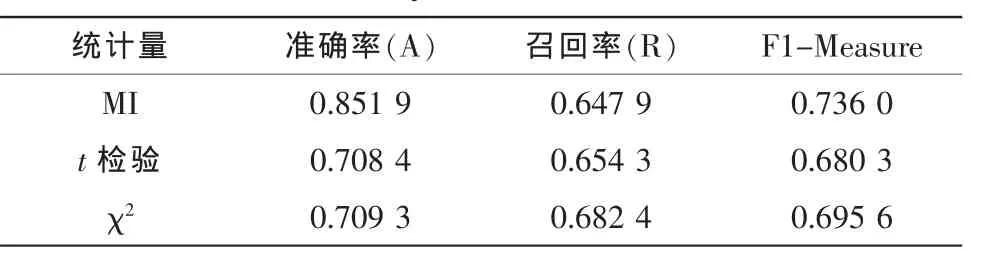
表3 句式搭配抽取結果Tab.3 Results of syntactic collocation extraction
5 結 論
本文以北京大學計算語言學研究所和富士通研究開發中心有限公司共同制作的1998年 《人民日報》標注語料庫(一月份)為語料庫,給出了基于五元組的詞語搭配抽取模型,并針對語義搭配和句式搭配做了實驗分析,指出基于互信息統計量的提取結果最好,準確率可達80%。
[1]Y Choueka,T Klein,E Neuwitz.Automatic retrieval of rrequent idiomatic and collocational expressions in Alarge corpus[J].Literary and Linguistic Computing,1983,4(1):34-38.
[2]Kenneth Ward Church,Patrick Hanks.Word association norms,mutual information,and lexicography[J].Computational Linguistics,1990,16(1):22-29.
[3]郎需超.基于R值的漢語搭配抽取[D].北京郵電大學,2012.
[4]林建方.詞搭配抽取及在信息檢索中的應用研究[D].哈爾濱工業大學,2010.
[5]曲維光,陳小荷,吉根林.基于框架的詞語搭配自動抽取方法[J].計算機工程,2004,30(23):22-24.QU Wei-guang,CHEN Xiao-he,JI Gen-lin.Aframe-based approach to chinese collocation automatic extracting[J].Computer Engineering,2014,30(30):22-24.
[6]王璐,張仰森.基于典型句型的詞語搭配定量分析及提取算法[J].計算機科學,2012(6):232-234.WANG Lu,ZHANG Yang-sen.Quantitative analysis and extracting arithmetic of collocations basic on typical patterns[J].Computer Engineering,2012(6):232-234.
[7]程月,陳小荷.基于條件隨機場的漢語動賓搭配自動識別[J].中文信息學報,2009,23(1):9-15.CHENG Yue,CHEN Xiao-he.CRFs based recognition of Chinese verb-object collocation[J].Chinese Information Technology,2009,23(1):9-15
[8]王素格,楊軍玲,張武.自動獲取漢語詞語搭配[J].中文信息學報,2006,20(6):31-37.WANG Su-ge,YANG Jun-ling,ZHANG Wu.Automatic acquisition of Chinese collocation[J].Chinese Information Technology,2006,20(6):31-37.
[9]王大亮,涂序彥,鄭雪峰.多策略融合的搭配抽取方法[J].清華大學學報:自然科學版,2008,48 (4):608-612.WANG Da-liang,TU Xu-yan,ZHENG Xue-feng.Collocation extraction withmultiple hybrid strategies[J].J-Tsinghua Univ:Sci&Tech,2008,48(4):608-612.
[10]王大亮,張德政,涂序彥,等.基于相對條件熵的搭配抽取方法[J].北京郵電大學學報,2007,30(6):40-45.WANG Da-liang,ZHANG De-zheng,TU Xu-yan,et al.Collocation extraction based on relative conditional entropy[J].Beijing University of Possts and Telecommunications,2007,30(6):40-45.
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
現代語文(2016年21期)2016-05-25 13:13:44
山東青年(2016年1期)2016-02-28 14:25:25
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
語文知識(2014年1期)2014-02-28 21:59:13
當代修辭學(2014年3期)2014-01-21 02:30:44
公務員文萃(2013年5期)2013-03-11 16:08:37
