農(nóng)村居民健康不平等及其分解分析
2015-02-18 04:55:26李艷麗譚樂祥閆菊娥高建民
統(tǒng)計(jì)與決策 2015年20期
李艷麗 ,譚樂祥,閆菊娥,高建民
(1.西安交通大學(xué) 公共政策與管理學(xué)院,西安 710061;2.臨沂大學(xué) 法學(xué)院,山東臨沂 276000;3.江蘇省興化市人民醫(yī)院,江蘇 興化 225700)
0 引言
當(dāng)前世界各國(guó)都開始加大對(duì)健康和醫(yī)療保健領(lǐng)域的投入力度,但是衛(wèi)生狀況和總體健康結(jié)果的改進(jìn)卻越來(lái)越緩慢,甚至出現(xiàn)了更大的健康結(jié)果不公平。健康結(jié)果不平等是指在一個(gè)國(guó)家或地區(qū)內(nèi)健康結(jié)果存在差異。中國(guó)居民的健康結(jié)果較之前有了很大的改善,但健康結(jié)果公平問題同樣不容樂觀[1]。
相較國(guó)際上對(duì)健康不平等問題的研究,我國(guó)對(duì)居民的健康不平等進(jìn)行的研究處于起步階段。劉寶和胡善聯(lián)(2001)利用上海市四區(qū)(縣)進(jìn)行的家庭衛(wèi)生服務(wù)調(diào)查數(shù)據(jù),采用Hopit模型獲得人群間可比性的傷殘得分考察了與收入相關(guān)的健康不平等問題。李湘君等(2013)利用2009年中國(guó)健康與營(yíng)養(yǎng)調(diào)查江蘇省數(shù)據(jù),以自評(píng)健康狀況為健康結(jié)果變量,研究結(jié)果表明江蘇省居民存在健康結(jié)果不平等[2]。與研究居民健康不平等問題的其它文獻(xiàn)相比,本文利用陜西省第四次國(guó)家衛(wèi)生服務(wù)調(diào)查數(shù)據(jù),對(duì)農(nóng)村居民的與收入相關(guān)的健康不平等問題進(jìn)行定量分析,以自評(píng)健康作為健康結(jié)果變量,采用Probit模型對(duì)其進(jìn)行賦值,并在此基礎(chǔ)上計(jì)算集中指數(shù),進(jìn)行不平等來(lái)源的分解。
1 數(shù)據(jù)、指標(biāo)選擇及變量設(shè)置
本研究使用2008年陜西省第四次國(guó)家衛(wèi)生服務(wù)調(diào)查數(shù)據(jù),以15歲及以上農(nóng)村居民為研究對(duì)象,共計(jì)3263戶、8558人。調(diào)查內(nèi)容包括家庭成員人口社會(huì)學(xué)特征、家庭成員經(jīng)濟(jì)狀況、家庭成員健康結(jié)果。擬合優(yōu)度檢驗(yàn)、瑪葉指數(shù)和DELTA不相似系數(shù)與GINI集中比顯示樣本的代表性較好,調(diào)查數(shù)據(jù)與總體的差別較小。
大量文獻(xiàn)表明,健康自評(píng)能夠反映健康狀態(tài)的主觀和客觀兩個(gè)方面,因此可以作為評(píng)價(jià)健康狀況的一個(gè)重要指標(biāo)。根據(jù)國(guó)際經(jīng)驗(yàn),第四次國(guó)家衛(wèi)生服務(wù)調(diào)查采用歐洲五維健康量表(EQ-5D)來(lái)反映居民的健康自我評(píng)價(jià)情況。本研究選用綜合健康評(píng)分指標(biāo)來(lái)反映自評(píng)健康狀況。綜合健康評(píng)分指標(biāo)是對(duì)百分制刻度尺進(jìn)行打分,“0”代表健康結(jié)果最差,“100”代表健康結(jié)果最好。根據(jù)研究目的以及擬合模型需要,本研究將百分制的自評(píng)健康得分轉(zhuǎn)換成二分類變量,即以中位數(shù)為界,80分及以上為良好,80分以下為不良,可以計(jì)算自評(píng)健康不良率。
引入模型的健康結(jié)果的影響因素包括:“人口統(tǒng)計(jì)學(xué)”變量如性別和年齡,“控制”變量包括經(jīng)濟(jì)水平、教育程度等。具體設(shè)置及描述見表1所示。
2 研究方法
2.1 健康結(jié)果不平等測(cè)量方法
采用集中指數(shù)和集中曲線測(cè)量健康結(jié)果不平等。集中曲線是以經(jīng)濟(jì)水平從最窮到最富排序后的人口累計(jì)百分比為x軸,以與之相對(duì)應(yīng)個(gè)體的健康結(jié)果變量為y軸進(jìn)行繪制的。如果健康結(jié)果與經(jīng)濟(jì)水平無(wú)關(guān),集中曲線應(yīng)該與45度對(duì)角線重合。45度的對(duì)角線也被稱之為公平線。集中曲線與公平線的距離越遠(yuǎn)說(shuō)明健康結(jié)果越不公平[3]。集中指數(shù)是集中曲線和公平線(45°線)間面積的兩倍,取值范圍為[-1,1]。集中指數(shù)的公式如下:

式中:cov為協(xié)方差;hi為健康結(jié)果變量;μh為hi均數(shù);ri=i/N是將個(gè)體按照經(jīng)濟(jì)水平排序后,第i個(gè)體在總?cè)藬?shù)中的比例,i=1為最窮個(gè)體,i=N為最富個(gè)體。

表1 Probit模型中控制變量的設(shè)置及描述
2.2 健康結(jié)果的水平公平性測(cè)量方法
本文采用集中指數(shù)分解法測(cè)量健康結(jié)果的水平公平性。集中指數(shù)分解法是將健康結(jié)果集中指數(shù)分解為各因素對(duì)健康結(jié)果不平等的貢獻(xiàn),將影響因素分為“人口學(xué)”變量和“控制”變量。利用集中指數(shù)分解法不但可以測(cè)量與經(jīng)濟(jì)水平相關(guān)的健康結(jié)果的水平公平性,而且能夠計(jì)算各因素對(duì)健康結(jié)果不平等性的貢獻(xiàn),通過(guò)Probit模型估計(jì)不同因素對(duì)健康結(jié)果變量的影響[4]。公式如下:
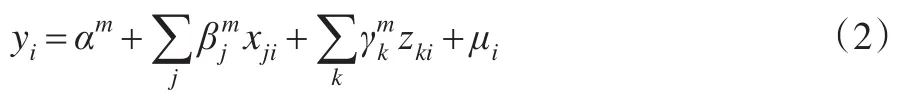
式中:yi為健康結(jié)果變量;xj為“人口統(tǒng)計(jì)學(xué)”變量;γk為“控制”變量;為邊際效應(yīng),即為dy/dxj和dy/dzk,它是每個(gè)變量通過(guò)計(jì)算樣本均數(shù)時(shí)得到并被視為固定參數(shù);μi為殘差項(xiàng),包括逼近誤差。
由于式(2)具有線性可加性,因變量y的集中指數(shù)分解結(jié)果如下所示:
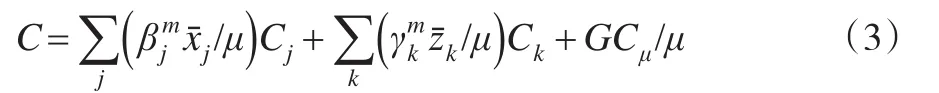
式中:C為y的非標(biāo)準(zhǔn)化集中指數(shù);Cj為xj的集中指數(shù);Ck為γk的集中指數(shù);GCε為殘差項(xiàng)的集中指數(shù);為xj的均數(shù);為zk的均數(shù)。
健康結(jié)果水平不公平指數(shù)等于非標(biāo)準(zhǔn)化集中指數(shù)減去“人口統(tǒng)計(jì)學(xué)”變量對(duì)不平等的貢獻(xiàn),公式如下:

數(shù)據(jù)采用Stata12.0軟件進(jìn)行統(tǒng)計(jì)學(xué)分析,圖表采用Excel2010軟件進(jìn)行繪制。
3 研究結(jié)果
3.1 基于經(jīng)濟(jì)水平的健康結(jié)果不平等
結(jié)果表明,自評(píng)健康不良率的集中指數(shù)為-0.0441,說(shuō)明陜西省農(nóng)村居民存在偏富人的健康結(jié)果不平等,即自評(píng)健康不良率集中于窮人,經(jīng)濟(jì)水平較差的農(nóng)村居民的健康結(jié)果較差。以經(jīng)濟(jì)水平(人均消費(fèi)性支出)的累計(jì)百分比為x軸,以其所對(duì)應(yīng)的健康結(jié)果變量為y軸,繪制集中曲線。自評(píng)健康不良率的集中曲線總體上位于公平線的上方,說(shuō)明健康結(jié)果的集中指數(shù)總體上為負(fù)值,存在偏富人的健康結(jié)果不平等,經(jīng)濟(jì)水平較差農(nóng)村居民的健康結(jié)果較差。
3.2 健康結(jié)果不平等的影響因素
以自評(píng)健康不良率為健康結(jié)果指標(biāo)為因變量,擬合模型,分析各因素對(duì)健康結(jié)果水平公平性的影響。回歸模型的自變量分為兩類:“人口統(tǒng)計(jì)學(xué)”變量和“控制”變量,其中性別和年齡為“人口統(tǒng)計(jì)學(xué)”變量,其它變量為“控制”變量。選用Probit回歸模型,采用線性逼近法計(jì)算自變量對(duì)健康結(jié)果的邊際效應(yīng)。
通過(guò)模型計(jì)算顯示,偽決定系數(shù)(Pseudo R2)=0.1812,似然比c2=1866.48,P<0.001,故該模型與最簡(jiǎn)模型相比有統(tǒng)計(jì)學(xué)意義,對(duì)其有顯著影響的變量有經(jīng)濟(jì)水平、性別、年齡和家庭規(guī)模。
比較其它變量對(duì)自評(píng)健康不良率的影響,可以發(fā)現(xiàn):(1)就業(yè)狀況對(duì)自評(píng)健康不良率的影響大體上顯著,在校學(xué)生呈負(fù)向顯著,而無(wú)業(yè)呈正向顯著,說(shuō)明相比較在業(yè)居民,在校學(xué)生的自評(píng)健康不良率較低,而無(wú)業(yè)居民的自評(píng)健康不良率較高。(2)廁所類型對(duì)自評(píng)健康不良率的影響呈正向顯著,說(shuō)明相比較無(wú)害化衛(wèi)生廁所,使用衛(wèi)生廁所和非衛(wèi)生廁所居民的自評(píng)健康不良率較高。(3)居住地區(qū)對(duì)自評(píng)健康不良率的影響呈負(fù)向顯著,說(shuō)明相比較陜南居民,陜北及關(guān)中居民的自評(píng)健康不良率較低。(4)離最近醫(yī)療點(diǎn)距離對(duì)自評(píng)健康不良率的影響呈正向顯著,說(shuō)明距離最近醫(yī)療點(diǎn)的分鐘數(shù)越大,自評(píng)健康不良率越高,具體見表2所示。
3.3 健康結(jié)果不平等的分解
利用Probit回歸模型估計(jì)出自變量對(duì)健康結(jié)果的邊際效應(yīng)后,便可利用式(3)將健康結(jié)果的集中指數(shù)分解為各自變量對(duì)其的貢獻(xiàn)。計(jì)算得出自評(píng)健康不良率的集中指數(shù)為-0.0441,即不良健康結(jié)果集中于低收入群體,存在偏富人的健康結(jié)果不平等。
從“人口統(tǒng)計(jì)學(xué)”變量的角度來(lái)看,男性和30~44歲、45~59歲兩個(gè)年齡組,貢獻(xiàn)均為正值,起到了擴(kuò)大偏窮人健康結(jié)果不平等的作用,對(duì)偏富人的健康結(jié)果集中指數(shù)的貢獻(xiàn)率為負(fù)值。60歲及以上年齡組的貢獻(xiàn)為負(fù)值,起到了縮小偏窮人健康結(jié)果不平等的作用,對(duì)偏富人健康結(jié)果的集中指數(shù)的貢獻(xiàn)率為105.41%。貢獻(xiàn)率作為一個(gè)相對(duì)指標(biāo),在自評(píng)健康不良率為健康結(jié)果指標(biāo)的集中指數(shù)的分解中,如年齡對(duì)偏富人健康結(jié)果不平等的貢獻(xiàn)為負(fù)值,說(shuō)明年齡起到了縮小偏窮人健康結(jié)果不平等的作用,因此相比較偏富人的自評(píng)健康不良率的集中指數(shù),貢獻(xiàn)率為正值。具體見表3所示。
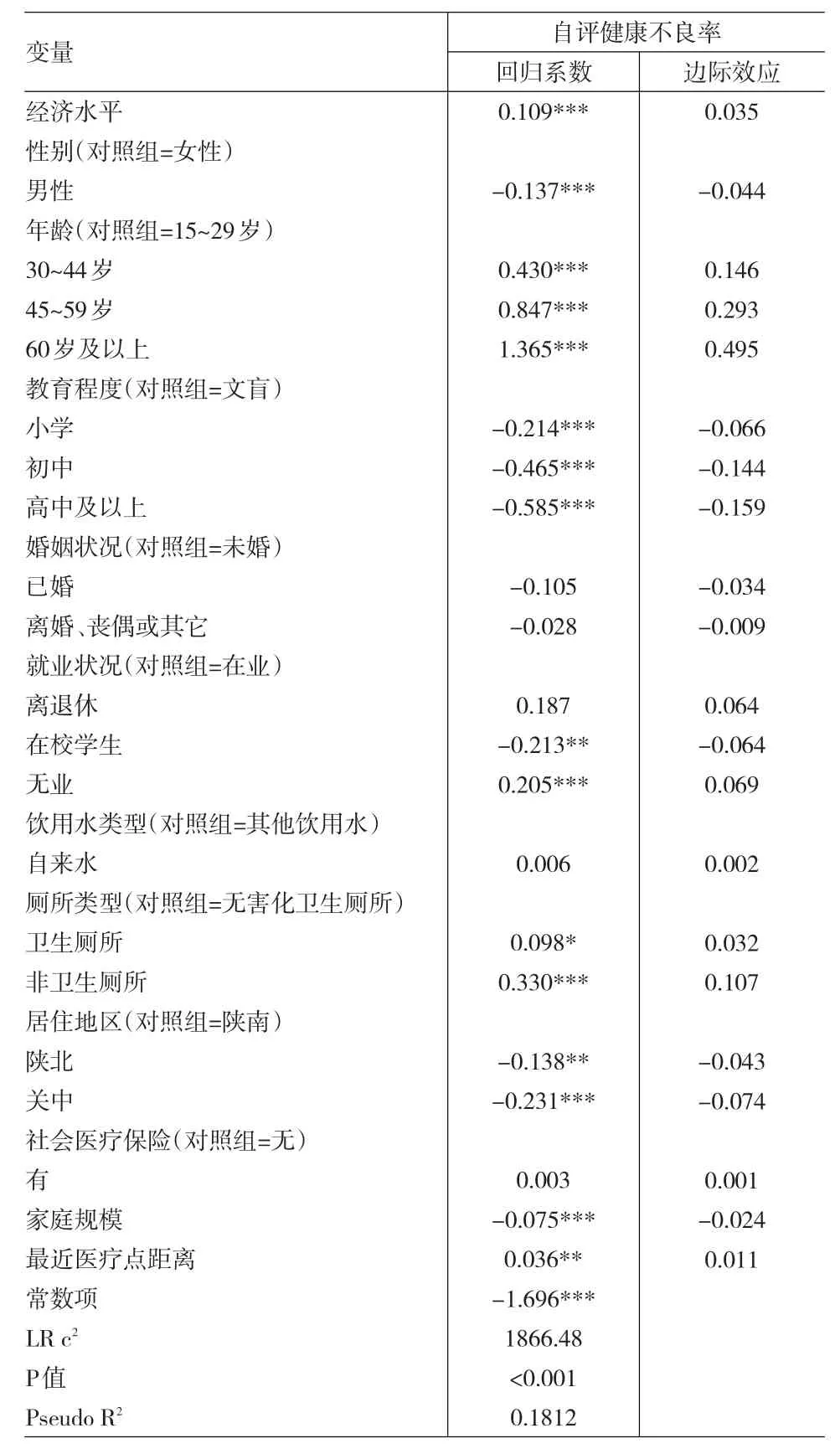
表2 以自評(píng)健康不良率為因變量的Probit模型估計(jì)結(jié)果
從“控制”變量的角度來(lái)看,經(jīng)濟(jì)水平對(duì)健康結(jié)果影響的彈性為正,由于其分布集中于富人,貢獻(xiàn)為正值,起到了擴(kuò)大偏窮人健康結(jié)果不平等的作用,而對(duì)偏富人的健康結(jié)果集中指數(shù)的貢獻(xiàn)率為-91.60%。教育程度的貢獻(xiàn)為負(fù)值,起到了縮小偏窮人的健康結(jié)果不平等作用,對(duì)偏富人的健康結(jié)果不平等的貢獻(xiàn)率為39.34%。同樣,就業(yè)狀況大體上起到了縮小偏窮人健康結(jié)果不平等的作用,對(duì)偏富人健康結(jié)果的集中指數(shù)的貢獻(xiàn)率為23.01%。除此之外,廁所類型為非衛(wèi)生廁所、居住地為關(guān)中地區(qū)、距最近醫(yī)療點(diǎn)距離的貢獻(xiàn)為負(fù)值,起到了縮小偏窮人的健康結(jié)果不平等的作用,對(duì)偏富人的健康結(jié)果集中指數(shù)的貢獻(xiàn)率為正值;而衛(wèi)生廁所和家庭規(guī)模貢獻(xiàn)為正值,起到了擴(kuò)大偏窮人的健康結(jié)果不平等的作用,對(duì)偏富人的健康結(jié)果集中指數(shù)的貢獻(xiàn)率為負(fù)值。其余變量由于Probit回歸系數(shù)差異無(wú)統(tǒng)計(jì)學(xué)意義,故對(duì)健康結(jié)果不平等所起的作用并不明朗。具體見表3所示。
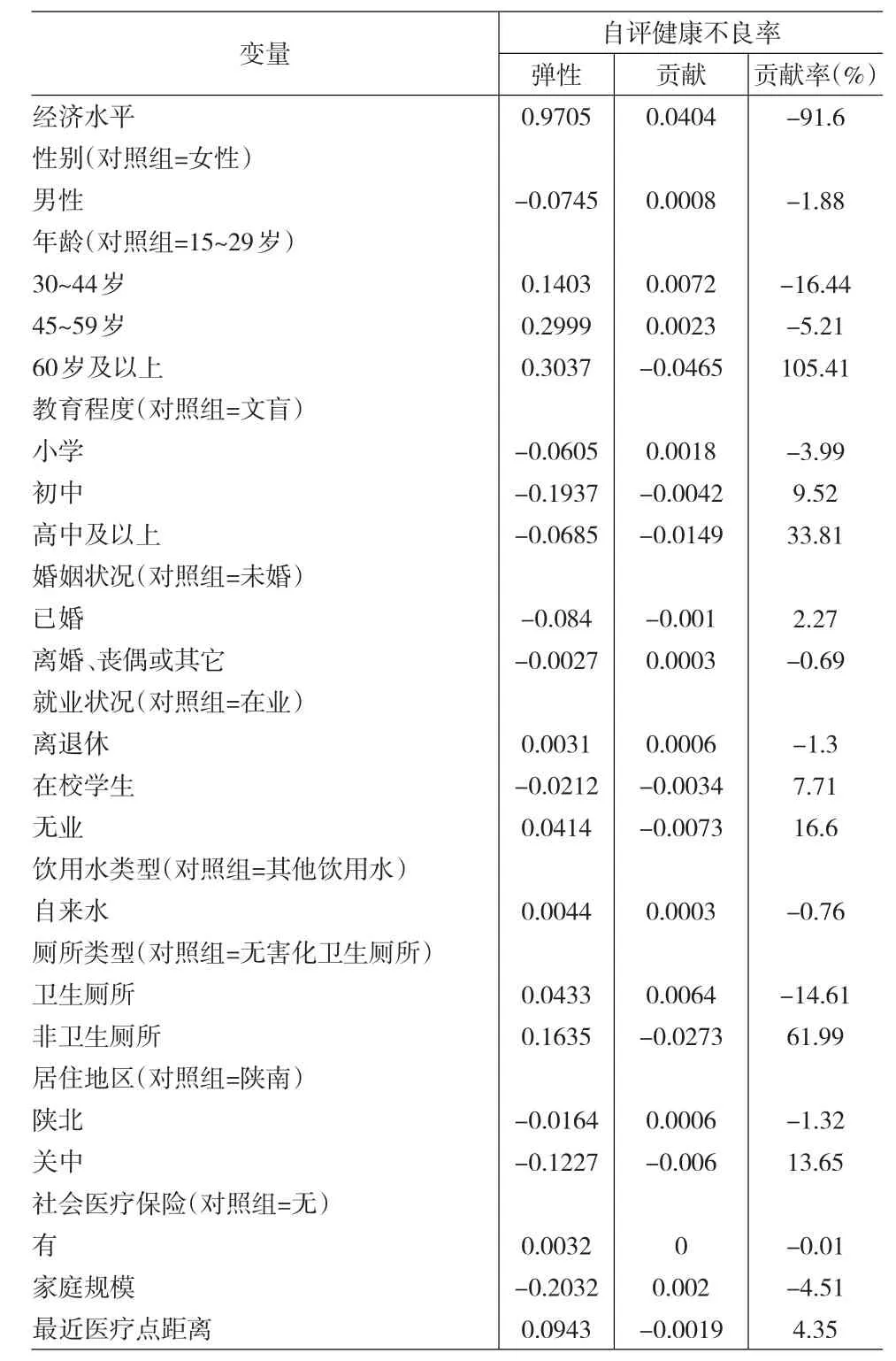
表3 以自評(píng)健康不良率為因變量的集中指數(shù)分解
3.4 健康結(jié)果水平不公平指數(shù)
根據(jù)Whitehead關(guān)于健康不平等和不公平的相關(guān)理論,利用式(4),計(jì)算出健康結(jié)果水平不公平指數(shù),自評(píng)健康不良率的水平不公平指數(shù)為-0.0080,說(shuō)明不良健康結(jié)果集中于低收入群體,存在偏富人的健康結(jié)果水平不公平,窮人的健康結(jié)果較差。
[1]中華人民共和國(guó)國(guó)務(wù)院新聞辦公室.中國(guó)的醫(yī)療衛(wèi)生事業(yè)[J].北京周報(bào)(英文版),2013,56(3).
[2]李湘君,王中華.江蘇居民健康不平等及其分解:基于CHNS數(shù)據(jù)的分析[J].醫(yī)學(xué)與哲學(xué)(A),2013,(5).
[3]Wagstaff A,Paci P,Van-Doorslaer E.On The Measurement of Inequalities in Health[J].Social Science&Medicine,1991,33(5).
[4]Scott E,Theodore K.Measuring and Explaining Health and Health Care Inequalities in Jamaica,2004 and 2007[J].Revista Panamericana De Salud Pública.2013,33(2).
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
美與時(shí)代·美術(shù)學(xué)刊(2022年3期)2022-04-27 01:18:15
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
火花(2019年12期)2019-12-26 01:00:28
人大建設(shè)(2019年12期)2019-05-21 02:55:32
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
學(xué)苑創(chuàng)造·A版(2015年11期)2016-01-14 09:03:27
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
中國(guó)火炬(2010年8期)2010-07-25 11:34:30

- 統(tǒng)計(jì)與決策的其它文章
- 小微企業(yè)創(chuàng)業(yè)者素質(zhì)評(píng)價(jià)指標(biāo)體系構(gòu)建
- 企業(yè)主支持感知對(duì)經(jīng)理人管家行為傾向影響的實(shí)證
- 所有制、社會(huì)責(zé)任與旅游企業(yè)財(cái)務(wù)績(jī)效
- 內(nèi)部控制對(duì)企業(yè)社會(huì)責(zé)任履行影響的實(shí)證檢驗(yàn)
- 金融集聚對(duì)區(qū)域經(jīng)濟(jì)增長(zhǎng)的路徑引導(dǎo)模型構(gòu)建與政策啟示
- 動(dòng)態(tài)空間視角下信貸轉(zhuǎn)移與區(qū)域性經(jīng)濟(jì)增長(zhǎng)研究