基于向量自回歸模型的GDP數據質量評估
2015-02-18 04:55:58廖傳勤
統計與決策 2015年22期
黨 瑋,廖傳勤
(石河子大學 商學院,新疆 五家渠 831300)
0 引言
我國通常用GDP來衡量國民經濟的運行情況,由于各種因素的存在,GDP數據質量或多或少存在一定的問題。現任中國國務院總理李克強在2007年任遼寧省委書記時,通過運用工業耗電量、鐵路貨運量和貸款發放量這三個指標來分析當年遼寧省的經濟運行狀況,此衡量方法得到了花旗銀行等眾多國際機構的認可,英國《經濟學人》2010年正式將其命名為李克強指數,以此作為評估中國經濟增長量的指標。相對于GDP的統計,“克強指數”三個指標不僅數據易于核實,而且更符合我國的經濟特征,與地方的GDP崇拜無關,更能擠出一般統計中的水分。三個指標從工業生產、能源消耗和經濟運行狀態三個方面更能真實、精確地反映我國經濟運行現狀。
對GDP數據質量的研究無論是從定性和定量的角度,還是從理論研究和實踐操作方面,國內外學者都提出了許多有參考價值的見解。目前,對我國GDP數據質量評估的研究相對較少,孟連和王小魯(2000)從我國地區GDP的匯總結果和國家統計局公布的GDP數據存在差異、通貨膨脹和經濟增長的關系出現偏差等方面進行分析,結果表明,1992~1997年中國的GDP高估了2.5個百分點[1]。Klein和Ozmucur(2002)采用了15個對中國經濟具有廣泛代表性的經濟指標,利用主成分分析的方法進行分析后認為,各項指標的變動和中國官方估計的實際GDP的變動具有一致性[2]。劉洪、黃燕(2009)通過利用經典的最小二乘法估計得到生產函數,對我國某地區歷年的地區生產總值,采用學生化殘差、DIFFITS統計量、Cook的D統計量等經典的診斷統計量對數據中的異常點進行了診斷[3]。盧二坡、黃炳藝(2010)通過運用穩健的MM估計異常值的診斷方法,并在使用生產函數模型框架的前提下,用兩種不一樣的勞動投入數據,對1978~2008年我國GDP的數據質量進行了評估。研究表明,相對于傳統方法容易掩蓋異常點的現象,穩健MM估計異常值診斷的方法能有效地解決這種情況,研究表明,1978~2008年間我國GDP數據是比較可靠的[4]。李庭輝(2011)在對數據質量的評估現狀進行整理的基礎上,構建了由空間、時間和結構三個維度形成的GDP數據質量評估體系,并提出了完善GDP數據質量評估的方法[5]。陳黎明、傅珊(2013)選取1985~2010年我國的GDP數據作為研究樣本,對我國GDP數據用誤差絕對值和最小的組合預測模型進行預測,預測所得的值代表“真值”,再利用異常值對我國GDP數據的準確性進行分析,研究表明組合預測模型對統計數據準確性的檢驗具有較高的實用價值,值得進行深層次的研究[6]。李庭輝(2013)選取與各產業相應的指標,根據數據之間的關系選擇VAR模型,結果表明全國產業的結構化數據和地區產業匯總后的結構化數據匹配性程度很高,我國GDP數據質量在總體上是較好的[7]。與已有文獻不同的是,本文試圖在運用“克強指數”來分析我國GDP數據質量的基礎上,用VAR模型來判斷兩者之間是否匹配以及使用相對誤差系數來判斷我國GDP數據質量的可靠性。
1 我國GDP數據質量匹配因素的理論分析
GDP即國內生產總值是國民經濟核算的核心指標,是以貨幣形式表現的一定時期內(一個季度或一年)一個國家(或地區)的經濟中所生產出來的全部最終成果(產品和勞務)的價值總和。從“克強指數”與我國GDP的關聯性即匹配性角度評估我國GDP的數據質量,主要應尋找與其具有關聯性的統計指標作為匹配因素。與國內生產總值相關聯的指標有很多,相對于其它指標而言,組成“克強指數”的三個指標更能真實、精確地反映我國GDP現狀。因為,現代的工業生產與能源消耗密切相關,所以,工業耗電量的多少,既可以準確反映我國工業生產的活躍度,又可以反映工廠的開工率;鐵路作為我國貨運的最大載體,其“鐵路貨運量”的多少,可以反映經濟運行現狀以及經濟運行效率;而對于間接融資占社會融資總量的比重高達84%的我國而言(銀行貸款占了我國間接融資的大部分),既可以反映市場對當前經濟的信心,又可以判斷未來經濟的風險度。由此可見,選取“克強指數”三個指標作為國內生產總值的核心關聯性指標較為合適。
據此提出以下基本假設:國內生產總值GDP與工業用電量、鐵路運輸量和銀行中長期貸款具有系統匹配性,且在時間上具有動態可變性,所以,從匹配性角度出發,需要選取反映動態系統結構的模型對我國GDP進行數據質量評估,而向量自回歸模型(Vector Autoregression Model,簡稱VAR模型)恰好符合該特征,故可以采用VAR模型對我國GDP數據質量進行評估。
2 基于VAR的我國GDP數據質量評估模型的構建
2.1 指標選取及數據來源
根據前述理論分析及其基本假設,對我國GDP的數據質量進行評估主要涉及工業用電量(P)、鐵路貨運量(S)和銀行中長期貸款(L)三個與之相匹配的指標。確定好指標以后,需要確定研究指標的數據頻率和時間。因為國內生產總值沒有月度數據,有的指標沒有收集到季度數據,所以,本文選取GDP的年度數據來進行數據質量評估,數據來源于《中國統計年鑒》。數據的時間范圍為1985~2012年(共28個數據),數據的空間范圍是全國。本文采用EViews6.0軟件進行分析。
2.2 基本理論模型的設定
根據GDP與“克強經濟”三個指標的匹配關系和基于匹配性的GDP數據質量評估的假設,GDP與工業用電量、鐵路貨運量和銀行中長期貸款四者之間存在較為穩定的相關關系、相互依賴的內在匹配性,利用VAR模型既可以判斷四者之間是否匹配,還可以對它們之間的動態關系進行研究,進而對GDP數據質量進行評估,評估的基本思路是借助VAR模型來尋找GDP與工業用電量、鐵路運輸量和銀行中長期貸款在一定經濟條件下不相符的樣本點。
根據向量自回歸分析理論,得到基于匹配性的GDP的數據質量評估理論模型如下:
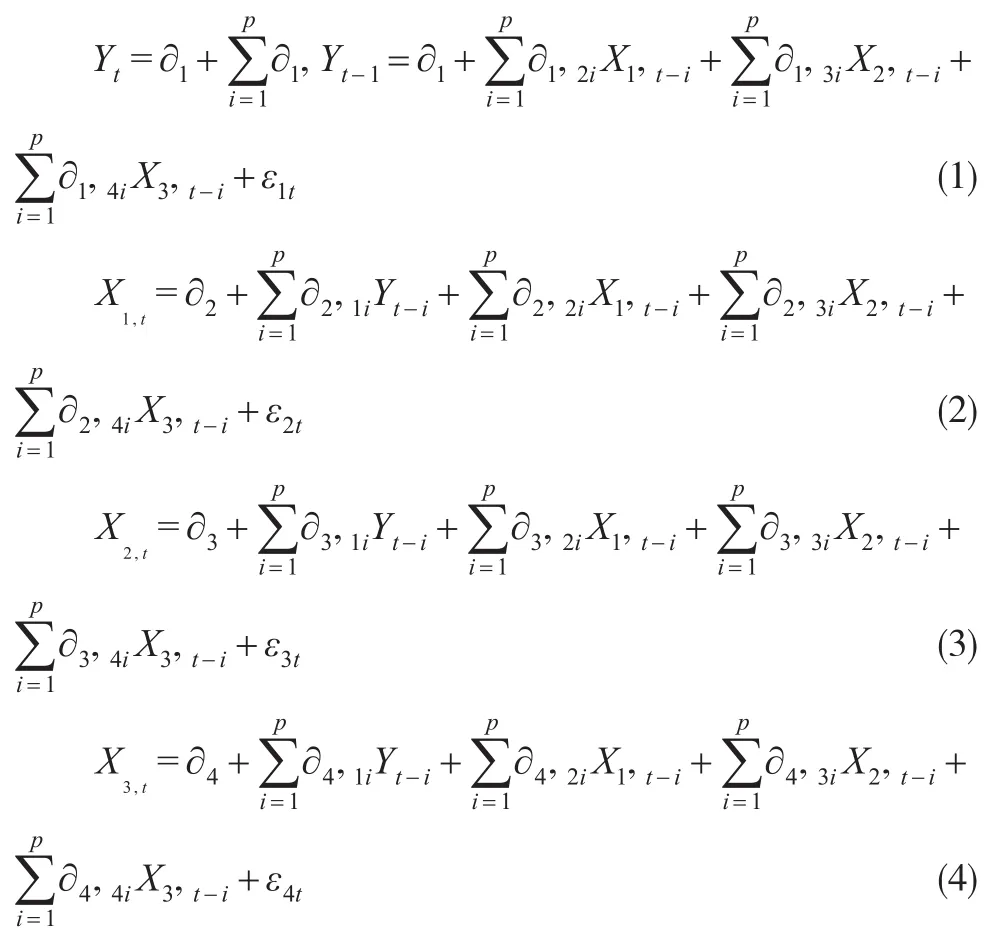
上式中,t為時間下標,Yt為第t期的GDP,X1,t為第t期的工業用電量,X2,t為第t期鐵路貨運量,X3,t為第t期銀行中長期貸款。
3 基于VAR的GDP數據質量的評估實證
3.1 VAR模型的估計及檢驗
使用VAR模型,首先需要考察相關變量的平穩性,同時,為了消除異方差和指數化趨勢,對納入模型的相關變量均進行了取對數處理,取對數后的我國GDP、工業用電量、鐵路貨運量和銀行中長期貸款分別記為lnGDP、lnP、lnS和lnL。本文采用單位根(ADF)方法對各變量進行單位根檢驗,結果如表1所示。
從表1可以看出,各變量原始序列的對數值均在10%的顯著性水平上沒有拒絕“存在單位根”的零假設,各序列都不平穩,但經過二階差分之后P值都小于0.05,且ADF的值均小于10%水平下的臨界值,拒絕“存在單位根”的零假設,所以原始序列對數的二階差分是平穩序列。
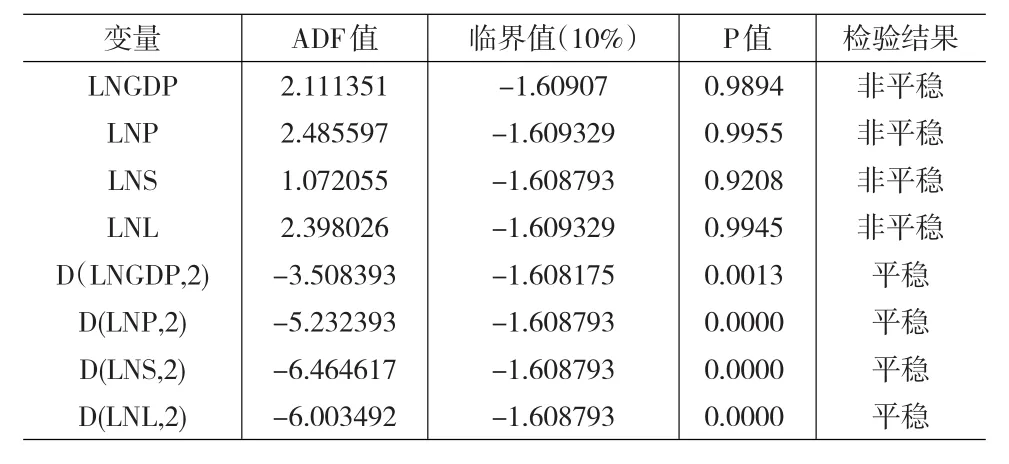
表1 單位根檢驗
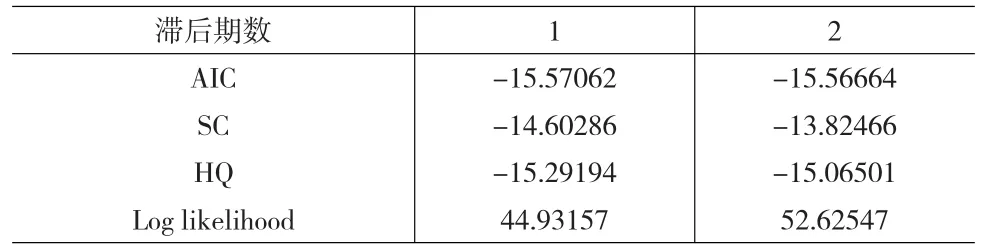
表2 滯后期的選擇
由表1和表2可知,我國GDP與工業用電量、鐵路貨運量和銀行中長期貸款之間存在動態的依賴關系,因此可以建立無約束的VAR模型。根據赤池消息準則(AIC)和施瓦茨準則(SC),滯后期為1時的AIC(-15.57062)和SC(-14.60286)均小于滯后期為2時的AIC(-15.56664)和SC(-13.82466)所以確定最優滯后期為1,對模型進行參數估計,模型的整體擬合效果較好,進而得到GDP與工業用電量、鐵路貨運量和銀行中長期貸款四個指標之間的回歸方程:

模型的AIC和SC值分別為-15.57062和-14.60286都較低,通過檢驗模型是穩定的,即所有根的模的倒數都小于1,位于單位圓內。從模型的整體檢驗和參數的顯著性檢驗結果可以看出,模型較好地刻畫了我國GDP與工業用電量、鐵路貨運量和銀行中長期貸款之間的動態結構與匹配關系,可以利用該模型對我國GDP的數據質量進行評估。
3.2 數據質量的判斷標準
對GDP數據質量是否可疑,還需要給定判斷標準,可以構造GDP相對誤差系數指標作為判斷標準。相對誤差系數δt用來測量第t期實際的GDP與GDP估計數據的相對誤差,如果相對誤差超過某一標準時,則可認為該期GDP的數據質量可疑。其中,相對誤差系數δt的計算公式為如果第t期的GDP統計數據相對誤差系數的絕對值滿足則認為該期GDP估計的相對誤差較大,說明該期的GDP統計數據質量可疑。
3.3 評估結果及其分析
對GDP進行數據質量評估,表3中的GDP是取對數處理后實際的GDP的值,是取對數處理后估計的GDP的值,根據相對誤差系數δt的計算公式得到δt的值。得到的結果如表3所示。
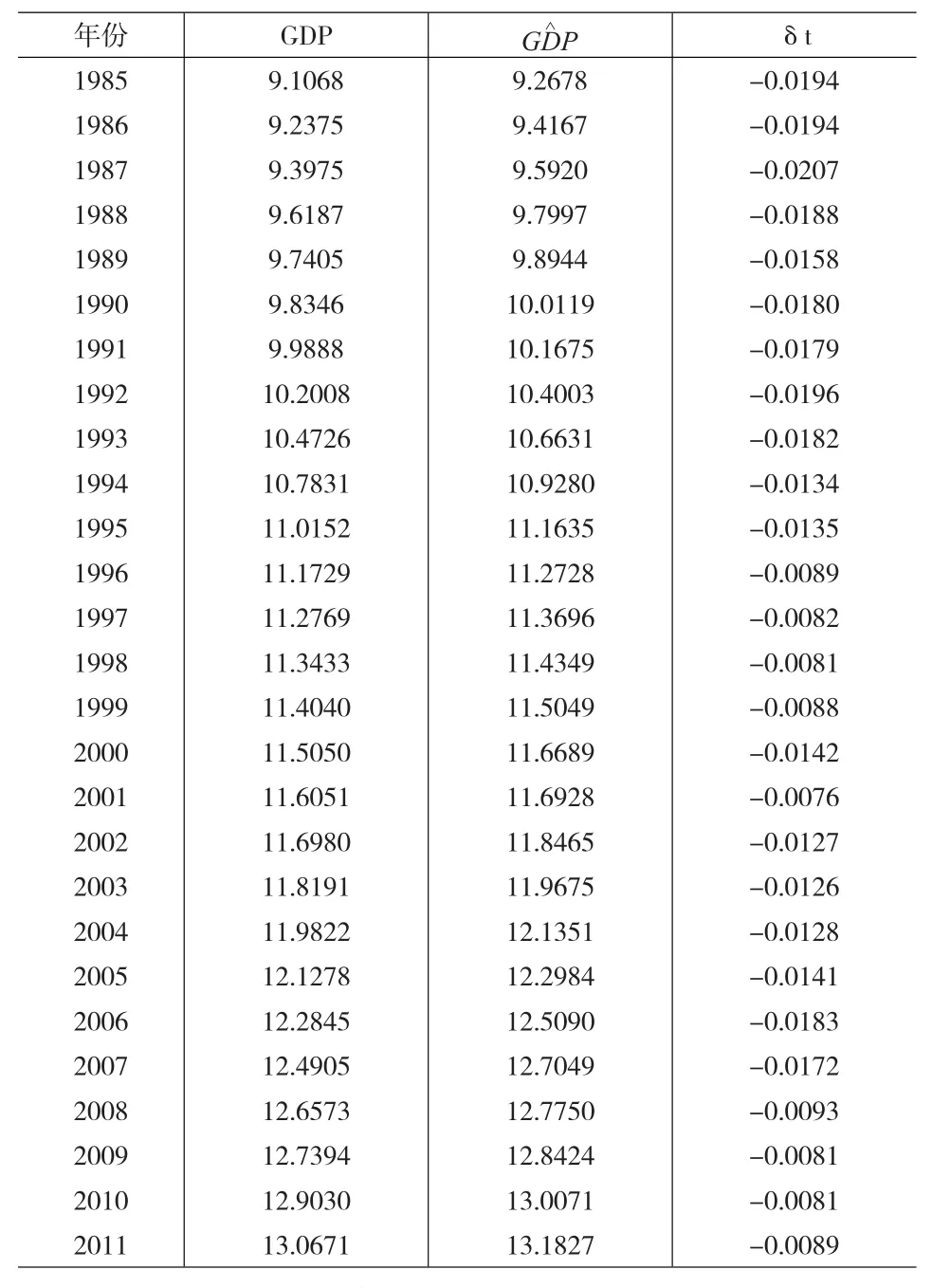
表3 GDP相對誤差系數
GDP相對誤差系數如表3所示,1985~2012年這28個年份中,GDP整體的數據質量整體較好,變動幅度相對較小,所有年份的GDP相對誤差系數的絕對值都小于0.05,由表3可知,從“克強指數”與我國GDP匹配的角度來看我國的GDP數據質量在逐步改善。
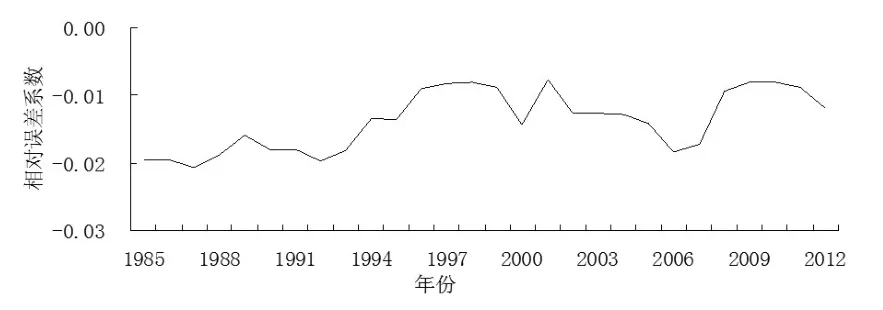
圖1 基于匹配性的GDP數據質量評估結果
從圖1可以看出,我國GDP的數據在允許誤差范圍之內,根據數據特征,可以將這28個年份分成3個階段,1985~1992年、1993~1999年、2000~2012年,從圖1可以明顯看出,1985~1992年的相對誤差系數變動較為平穩,但數據質量是這3個階段中最差的,這是因為1985~1992年之間,我國處在MPS和SNA兩種核算體系共存階段,到1985年國家統計局才第一次計算國內生產總值,GDP核算制度在不斷完善與發展之中。國家統計局在1992年才開始實施《中國國民經濟核算體系(試行方案)》,從而使得1992年以前的GDP數據質量相對較差。1993~1999年的數據質量逐步改善是因為在1993年的十四屆三中全會中全面的提出了建立社會主義市場經濟體制,且我國使用SNA1993(聯合國),使得1993~1999年的GDP數據質量逐步得到改善;在2000~2012年這十三年間,我國的社會主義市場經濟已經相對的完善。2000年國家統計局制定了《中國國民經濟核算體系(修改本)》(征求意見稿),廣泛地征求理論和實際部門的意見。經過多年的實踐,在總結經驗的基礎上,我國國家統計局頒布了《中國國民經濟核算體系(2002)》。至此,我國國民核算模式實現了向SNA的全面轉型,所以,該階段內的GDP數據質量相對更好一些,變動幅度也較適中。我國GDP數據質量在總體上是不斷提高的,近年來相對誤差有逐漸減少的趨勢,說明GDP數據質量整體上可靠,數據質量在不斷地提升,其誤差基本上控制在5%的范圍之內。
4 結論
通過對我國GDP與“克強指數”相關指標數據匹配性的實證分析,發現我國1985年至2012年的GDP年度數據基本上在誤差控制范圍之內,且近幾年數據質量有逐步提高之趨勢,說明我國GDP統計數據質量整體上是比較可靠的。基于“克強指數”和GDP數據質量評估的基本理論,結合實證分析的結果,得到如下結論:
(1)基于我國的宏觀經濟數據,構建“克強指數”各指標與我國GDP匹配關系的VAR模型,模型顯示“克強指數”各指標與我國GDP的具有較強的匹配性。
(2)從“克強指數”角度來分析的我國GDP數據質量整體上是較好的,“克強指數”為我們提供了一個全新的、真實的、客觀的視角來衡量我國的GDP的運行與發展。研究表明,“克強指數”不僅與我國GDP之間存在密切地聯系,且能在一定程度上更真實地反映我國GDP的運行和發展的現狀。
(3)從相對誤差系數的結果來看,我國GDP的數據質量存在階段性的特征,我們可以將這些年份分成三個階段。第一階段為1985~1992年,數據質量相對較差;第二階段為1993~1999年,數據質量有逐步改善的趨勢;第三階段為2000~2012年,數據質量整體較好[8]。這與我國的國民經濟核算的改革有密切的關系。
[1]孟連,王小魯.對中國經濟增長統計數據可信度的估計[J].經濟研究,2000,(10).
[2]Thomas G R.What's Happening to China's GDP Statistics[J].China Economics Review,2001,(12).
[3]劉洪,黃燕.基于經典計量模型的統計數據質量評估方法[J].統計研究,2009,(3).
[4]盧二坡,黃炳藝.基于穩健MM估計得統計數據質量評估方法[J].統計研究,2010,(12).
[5]李庭輝.基于匹配性的GDP數據質量評估體系構建[J].調研世界,2011,(11).
[6]陳黎明,傅珊.基于組合預測模型的GDP統計數據質量評估研究[J].統計與決策,2013,(8).
[7]李庭輝.基于地區產業結構匹配的GDP數據質量評估[J].統計與決策,2013,(19).
[8]薛麗娜,李正輝,李庭輝.基于地區投入結構的GDP數據質量評估[J].統計與決策,2012,(20).
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·八年級物理人教版(2021年12期)2021-12-31 03:23:08
中學生數理化·中考版(2020年10期)2020-11-27 01:59:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中國生殖健康(2019年2期)2019-08-23 08:12:08
產品可靠性報告(2017年7期)2017-09-05 09:49:12
光學精密工程(2016年6期)2016-11-07 09:07:19
汽車觀察(2016年3期)2016-02-28 13:16:26
核科學與工程(2015年4期)2015-09-26 11:59:03
