基于SOM-DB-PAM混合聚類算法的電力客戶細分
2015-03-07 11:43:33胡曉雪趙嵩正
計算機工程 2015年10期
胡曉雪,趙嵩正,吳 楠
(西北工業大學管理學院,西安 710129)
基于SOM-DB-PAM混合聚類算法的電力客戶細分
胡曉雪,趙嵩正,吳 楠
(西北工業大學管理學院,西安 710129)
針對電力客戶具有客戶數量大、存在孤立點等特點,提出一種適用于對大量電力客戶進行快速聚類的SOM-DB-PAM混合聚類算法。該算法利用自組織映射神經網絡訓練輸入數據,以獲取代表輸入模式且數據量遠小于輸入數據量的原型向量,使用圍繞中心點的切分(PAM)對該原型向量聚類并用Davies-Bouldin指標判定最優聚類個數以保證聚類效果。實驗結果表明,與傳統聚類算法相比,該算法具有更高的分類正確率,當客戶數量較大時,能實現對客戶的快速、有效聚類,并減少人為指定聚類個數的盲目性和主觀性。
電力客戶細分;圍繞中心點的劃分;自組織映射;混合聚類算法;聚類分析
DO I:10.3969/j.issn.1000-3428.2015.10.056
1 概述
隨著電力工業改革的深入推進和智能電網建設的逐步開展,電力客戶在電力市場中的地位日益凸顯,這一趨勢促使供電企業將工作重點轉移到客戶服務上來,客戶服務質量成為制約電力公司發展的關鍵因素。客戶細分是產品差異化戰略的一個替代概念[1],其主要思路是找出具有相似人口統計學、行為、價值特征的客戶群[2]。 細分戰略基于以下邏輯:針對類似客戶組成的更小群體的獨特需求所采取的營銷方式,應當比針對不同客戶組成的大市場需求所采取的營銷方式更有效率[3]。對市場
條件下的電力客戶進行深度細分,有助于供電企業了解客戶用電行為,識別價值客戶,制定有針對性的服務措施和差異化營銷戰略,從而提升服務水平。
我國學者主要從供電企業的視角開展基于價值的電力客戶細分研究。在細分技術方面,層次聚類和K-means聚類,因為具有操作簡單和受大部分統計軟件支持的特性,被廣泛用于處理細分問題。文獻[4]建立了基于層次聚類的電力客戶細分模型;文獻[5]針對K-means初始條件隨機化、容易陷入局部最優解的缺陷提出了一種改進的Hopfield-K-means算法;文獻[6]在計算對象到聚類中心距離時考慮了指標權重的影響,提出結合AHP加權的K-means聚類模型;大部分研究采用如下思路:建立電力客戶價值評價指標體系;評估客戶價值;對價值評分進行分類,此時,研究重點由細分技術轉換為評價指標體系的構建和評價方法的選取[7-9]。其中,文獻[10-11]分別采用K-means和BP神經網絡對電力客戶價值評分聚類,后者嘗試使用遺傳算法優化BP以解決BP存在局部收斂和收斂速度慢的問題。
然而,上述研究均未考慮客戶數量大的情形,層次聚類只適用于少量數據,隨著客戶數的增加,對客戶逐個計算價值再聚類將非常耗時,“噪聲”和孤立點數據的增多直接影響聚類效果。圍繞中心點的劃分(Partitioning A round Medoids,PAM)聚類算法克服了K-means對孤立點數據的敏感性,但只適用于對少量客戶聚類且需預先確定聚類個數,以往研究大多依據專家經驗人為指定聚類數目,具有一定盲目性和主觀性。因此,本文針對電力客戶具有的客戶數多、數據量大、存在孤立數據等特點,提出一種基于SOM-DB-PAM的混合聚類算法,嘗試利用自組織映射(Self-Organizing Feature Maps,SOM)神經網絡的原型向量表征輸入模式的特性,結合PAM對孤立點的容忍能力,使用SOM對大量、多維電力客戶數據進行訓練,并用PAM對獲得的SOM原型向量聚類,用聚類效度指標Davies-Bouldin(DB)確定最優的聚類個數,從而克服上述研究的不足,實現對大量電力客戶的自動有效細分。
2 電力客戶細分基本思路
遵循細分研究的5個基本主題:問題定義,研究設計,數據收集,數據分析,實施和對結果的理解及每個主題涉及的關鍵問題[12],本文進行電力客戶細分的基本思路如圖1所示。

圖1 電力客戶細分基本思路
在問題定義和研究設計階段,由于從企業視角開展基于客戶終身價值(Customer Lifetime Value,CLV)的電力客戶細分研究對供電企業具有重要意義,本文的研究目標設定為:基于客戶終身價值、以識別高價值客戶為目標的電力客戶細分。客戶終身價值包含當前價值和潛在價值兩部分,篩選衡量電力客戶價值的指標構成初始細分變量,由于研究對象是大量客戶,用于分析的客戶數據主要來源于供電企業電力營銷數據庫和業務文檔中存儲的靜態電力客戶基本信息和動態業務數據,因此為盡量減少不確定因素對細分結果的干擾,在確定最終細分變量時,要基于簡明科學性、把握主導因素、變量獨立和可量可測的原則[13],還要綜合考慮數據的可獲取性和數據質量并盡量移除需要人為賦值的定性指標。在實施細分前,需對數據進行預處理。
3 SOM-DB-PAM混合聚類算法
3.1 SOM,PAM和DB算法介紹
自組織映射神經網絡SOM是一種同時具備矢量量化和矢量投影功能的無監督神經網絡。一個SOM由排列在低維空間(稱為輸出層)的m個神經元(結點)組成,每個神經元用一個d維權向量Wi=(Wi1,Wi2,…,Wid)表征(d代表輸入向量的維數),該權向量被稱為原型向量。SOM利用持續迭代的無指導學習對輸入數據進行訓練,目標是將輸入向量映射到與其相似度最高的原型向量表征的結點中并保持數據的拓撲結構不變。SOM可識別輸入數據具有自穩性的最顯著特征,適用于大樣本數據。其缺點表現在:處理小樣本數據時,算法的學習效率依賴于樣本對象的輸入順序且受到網絡連接權重和網絡拓撲結構選擇等的影響[14]。
K-medoid聚類算法的產生克服了K-means聚類用類中所有對象的均值表征各類中心,均值的計算受“噪聲”或孤立點干擾較重的問題。PAM試圖確定N個對象的K個劃分,是最基礎的K-medoid算法之一。PAM用被稱為中心點的一組對象代表簇中心以最小化非代表對象和最接近它們的中心點的平均相異度。算法包括2個階段:
(1)為每個類隨機選擇一個初始代表對象(中心點),將剩余對象按其與中心點的相異度或距離分配給離它最近的一個類,該過程稱為BUILD;
(2)反復用非代表對象替換中心點以提高聚類質量;聚類質量由一個代價函數評估,該函數度量一個非代表對象是否是當前中心點的好的代替,如果是就進行替換,否則不替換,直至聚類質量無法再提高,此過程稱為SWAP;詳細步驟參見文獻[15]。
相比K-means,PAM具有較強的健壯性,對“噪聲”和孤立點數據不敏感,由它發現的簇與測試數據的輸入順序無關,能夠處理不同類型的數據點。然而它和K-means一樣,需事先指定聚類個數,其主要缺點還在于:當數據量較大時算法的效率很低。
確定聚類個數的方法之一是分別使用不同的聚類個數運行聚類算法,使用效度指標度量聚類結果從而判斷出類內緊密性和類間分離度最佳的聚類數目[16],Davies-Bouldin(DB)指標是常用的聚類效度指標,描述為:
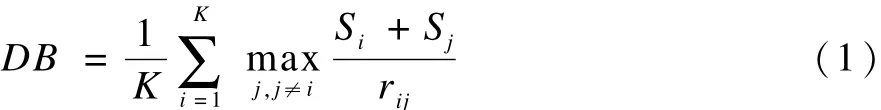
其中,K代表聚類個數;Si描述了一個類中所有點到類中心點的距離的均值;rij代表類i和類j的距離;向量mi表示類Ci的中心點;表示類Ci中包含的對象個數,如式(2)和式(3)所示。DB越小表明類內各對象與類中心距離越小(緊密性)而類間距離(分離度)越大,聚類質量越高。最小的 DB指標所對應的聚類個數即為最優聚類數目。
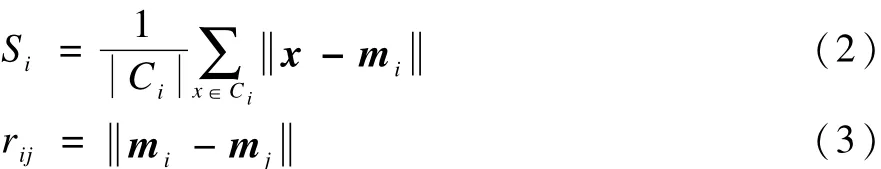
3.2 SOM-DB-PAM混合聚類算法
現有聚類技術有各自的優勢和局限,建立在不同技術有效組合或集成思路上的混合聚類技術能揚長避短,是細分技術未來的發展趨勢[17]。本文針對電力客戶數目大、存在孤立點數據的特點,提出SOM-DB-PAM混合聚類算法,算法包括2個階段:第1階段構建SOM對大量輸入數據進行訓練,得到反映輸入數據最主要特征的原型向量;第2階段使用PAM對所獲得的原型向量再度聚類,同時,使用DB指標自動判別最優聚類數目以保證聚類效度,算法流程如圖2所示。該算法在集成SOM處理大樣本的優勢和PAM健壯性的同時克服了人為指定聚類數目存在的困難和主觀性。
圖2 SOM-DB-PAM流程
在實際應用中,由于SOM輸出層的網絡拓撲結構、原型向量初始化方法和學習算法會影響網絡的學習效率,第1階段初期需指定網絡結點數即原型向量個數n,遵循在保留輸入數據主要信息基礎上盡可能減少第2階段工作量的原則,n應遠小于輸入樣本個數并盡量大于最終所需的類目數。早期研究表明:超環面和球面SOM拓撲結構能克服平面結構的邊緣效應且行列數不相等的輸入矩陣比方陣更能準確表達數據特征[18],因此,SOM應選擇超環面或球面拓撲結構且避免將輸入矩陣設計為方陣;批學習算法具有速度快,可產生更穩定的原型向量值和具備強的可再現能力的優點,采用批學習算法對設計好的SOM進行訓練,為提高訓練效率,使用線性初始化方法初始化原型向量。在第2階段中,以設定聚類數目的范圍[Kmin,Kmax]代替直接指定最終聚類數,為使細分結果有意義,原則上 Kmin>1且Kmax<n,綜合考慮制定營銷策略時的實際需要并參考領域專家的經驗適當縮小[Kmin,Kmax]區間可提高細分結果的可解釋性和PAM的聚類效率。
SOM-DB-PAM混合聚類算法的主要思想是:對N個待聚類對象使用SOM先進行“粗聚類”得到n個初步的類,再用PAM對這n個初步的類進行正式聚類。由于PAM算法的時間復雜度為O(T2× d×K(N-K)2),其中,T2為算法收斂所需的迭代次
數;K為中心點數目,即聚類個數,每計算一次用非中心點替換中心點的代價所需時間為d×K(NK)2,當樣本規模N和維數d都很大時,PAM的計算復雜度將非常高,而用電數據量大正是電力客戶細分面臨的主要問題,以某供電局管轄的居民客戶為例,平均每月產生的用電記錄數 N>26000,引入SOM進行“粗聚類”后,SOM-DB-PAM算法的復雜度為O(T1×n×d×N)+O(T2×d×K(n-K)2),其中,T1為SOM網絡訓練所需的迭代次數,由于使用SOM對數據進行“粗聚類”時,最終的聚類結果不依賴于神經元的拓撲位置,網絡不需要完全收斂,可設定一個較小的 T1以降低網絡的訓練時間[19],此時,算法的時間復雜度主要依賴于n,而n遠小于待聚類對象個數N,因此,采用SOM-DB-PAM對大量電力客戶數據進行聚類,在利用PAM健壯性的同時降低了其計算復雜度。
3.3 SOM-DB-PAM聚類性能測試
由于目前尚沒有針對電力客戶的可供實驗的公開聚類測試數據集,因此為測試SOM-DB-PAM的聚類性能,本文從某電力公司下屬供電局的營銷信息系統中抽取了120條電力客戶用電記錄組成仿真數據集進行聚類實驗,每條記錄由3個細分變量描述,分別為客戶當月用電量、當前欠費金額和歷史同期用電增長率,依據客戶在這3個變量上的不同表現,可將其劃分為卓越客戶、風險客戶和穩定客戶3類,每類各包含40條記錄,數據集中不含缺失值,但包含一條噪聲記錄。在實驗前,采用線性標準化方法分別對3個細分變量進行了預處理。在SOM-DB-PAM和SOM-DB-Kmeans聚類的第1階段,初始化 SOM網絡結點數為20,結點形狀為六邊形,按[7×3]矩陣排列,SOM圖形狀為超環面,初始鄰居距離為2;在第2階段,將最終類目數的區間范圍指定為[2,4]。在Matlab R2010a環境下編程實現SOM-DB-PAM并比較其與傳統K-means、SOM-DB-Kmeans聚類算法的性能差異。每種算法實驗10次,實驗結果如表1所示。表1中的DB指標值和程序運行時間均為10次實驗獲得的平均值。

表1 使用電力客戶仿真數據集的SOM-DB-PAM聚類測試結果
從表1可知:使用SOM-DB-PAM進行的10次實驗中,通過DB指標均能識別出正確的聚類數目3且樣本的分類正確率達到100%,高于傳統K-means和SOM-DB-Kmeans的分類正確率。而使用后2種聚類算法進行的實驗中,分別有2次和1次實驗DB指標無法準確判斷最優聚類數目(見括號),這主要是由于K-means采用隨機分配初始聚類中心的策略且聚類結果受數據輸入順序的影響,導致聚類結果不穩定。由于訓練SOM網絡需要時間,從表1可看出,K-means在本文實驗的運行時間上具有明顯優勢,為進一步驗證SOM-DB-PAM在大規模數據集上的時間有效性和聚類效果,考慮到為大樣本電力客戶預先設定合理的類編號存在困難,本文還使用UCI數據集中不同規模的其他行業測試數據集評估3種算法的聚類性能,測試結果如表2所示:在不同規模的測試數據集上,SOM-DB-PAM都具有更高的分類正確率且能準確判別最優聚類個數;在程序運行時間上,由于SOM-DB-PAM和SOM-DB-Kmeans需要構建SOM網絡并對其進行訓練,處理小樣本時,K-means具有更高的聚類效率;隨著樣本規模的增加,SOM-DB-Kmeans所需運行時間最少,但比SOM-DB-PAM并沒有顯著優勢,綜合分類正確率、最優聚類數目的判定和算法運行效率可知,在對大規模數據進行聚類分析時,SOM-DB-PAM優于傳統聚類算法。
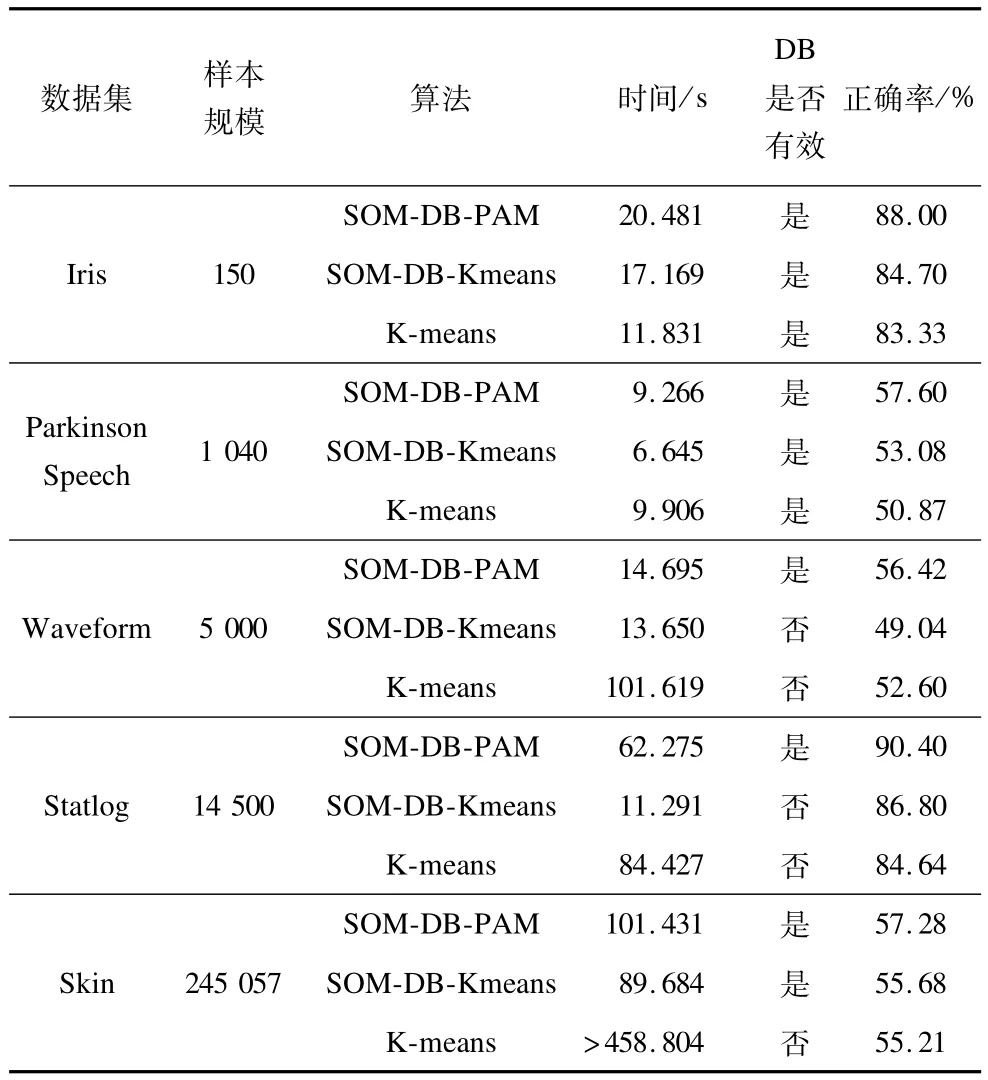
表2 使用UCI數據集的SOM-DB-PAM測試結果
4 實例分析
4.1 數據收集和數據預處理
本文從國家電網陜西省電力公司某下屬供電局的營銷信息系統中,抽取了16 818位居民客戶的基本信息和2011年、2012年12月的用電數據進行分析,驗證SOM-DB-PAM在真實電力客戶細分應用中的有效性。參照已有研究建立的電力客戶價值評價指標體系[8,13],在考察數據可獲取性和數據質量的基礎上選取11個指標構成細分變量,各變量的含義如表3所示。
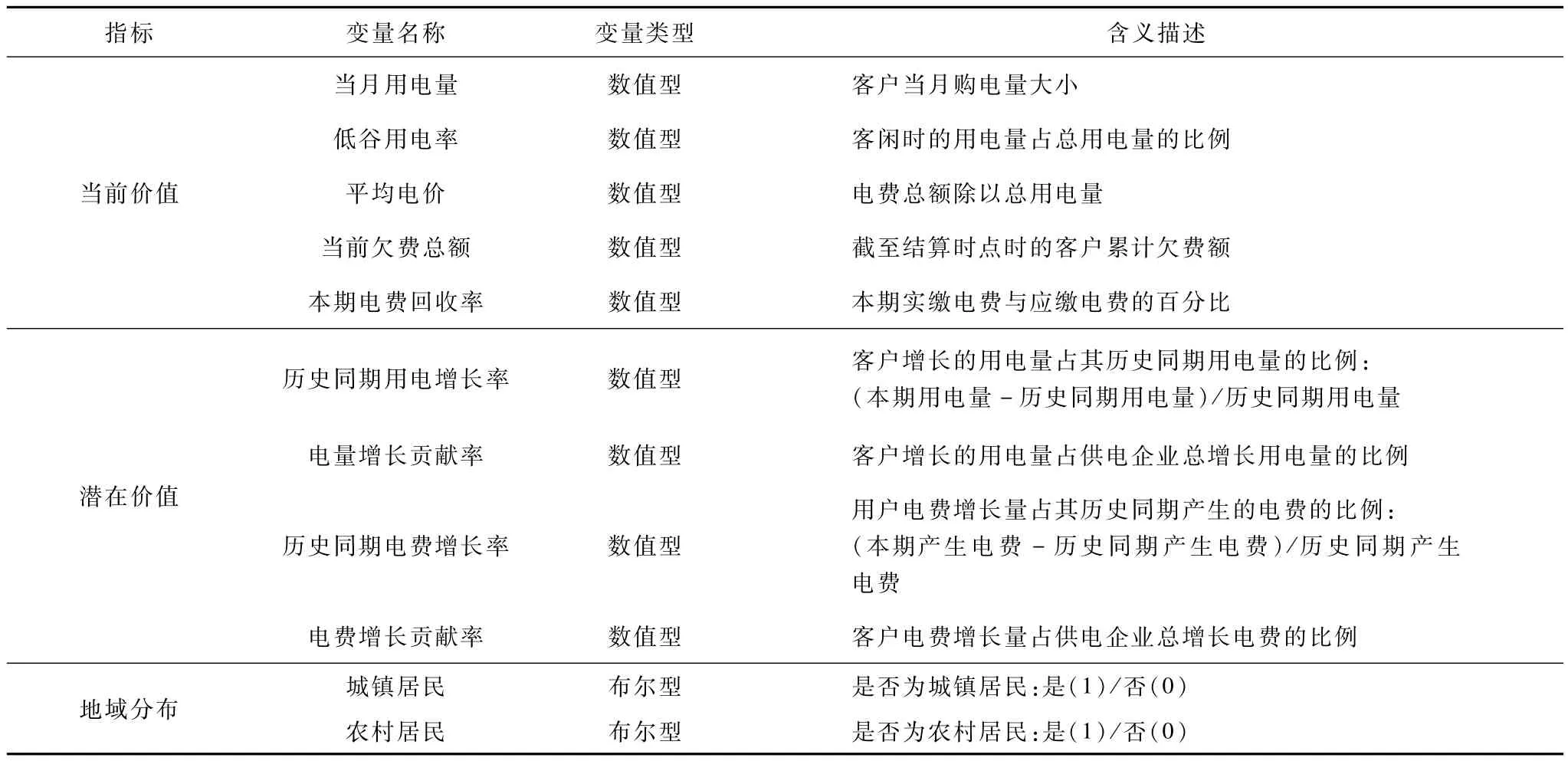
表3 電力客戶細分變量及其含義
為消除數據間由于量綱不同對聚類結果產生的影響,根據各變量數據的分布特點選取合適的標準化方法[20]對原始數據進行標準化處理,如表 4所示。

表4 細分變量的標準化方法
4.2 基于SOM-DB-PAM的電力客戶細分
使用SOM-DB-PAM混合聚類算法對經過預處理的電力客戶數據進行聚類,在第1階段,初始化SOM網絡結點數為 100,結點形狀為六邊形,按[13×8]矩陣排列,SOM圖形狀為超環面,初始鄰居距離為2。在第2階段,綜合考慮當前價值、潛在價值2個維度和細分結果的可解釋性將最終簇數目的區間范圍指定為[4,50],為克服PAM聚類時隨機選取初始中心點導致對于同一類目數,每次計算出的DB指標存在微小差異的缺點[21],對每個類目數,計算DB指標30次并用均值代表最終DB值。用DB指標獲得的最優聚類個數為33,此時的DB指標值為0.699 8,得到的每個類包含的客戶數和各類的中心點如表 5所示。其中,第 1列為各類的簇編號,第2列為每個類包含的客戶數,其他各列對應各類的中心點在各細分變量的取值程序運行時間為:175.122 s。
為更好地解釋聚類結果,33個客戶簇按照當月用電量大小(單位:kW/h)被分為4類:大型客戶,用電量大于 1 000;中型客戶,用電量區間 (500,1 000];一般客戶,用電量區間(100,500]以及用電量低于或等于100的小型客戶,圖3描述了各個類在當月用電量指標上的分布。其中,每個類包含的客戶數大小用圓圈大小表征。
綜合其他細分變量,客戶又可被分為卓越客戶、優質客戶、穩定客戶、存在潛在欠費風險的客戶、存在潛在流失風險的客戶以及同時具有以上2種風險的客戶,對各類型客戶的特征描述如表6所示。其中,卓越客戶和優質客戶在衡量客戶價值的各指標上表現優異,歷史同期用電量增長和電費增長幅度均超過10%,具有大的潛在價值,按時繳費,電費回收率超過95%,是本文要識別的高價值客戶,他們僅在用電規模上存在差異,卓越客戶的當月用電量更接近其所在用電量區間的上限。
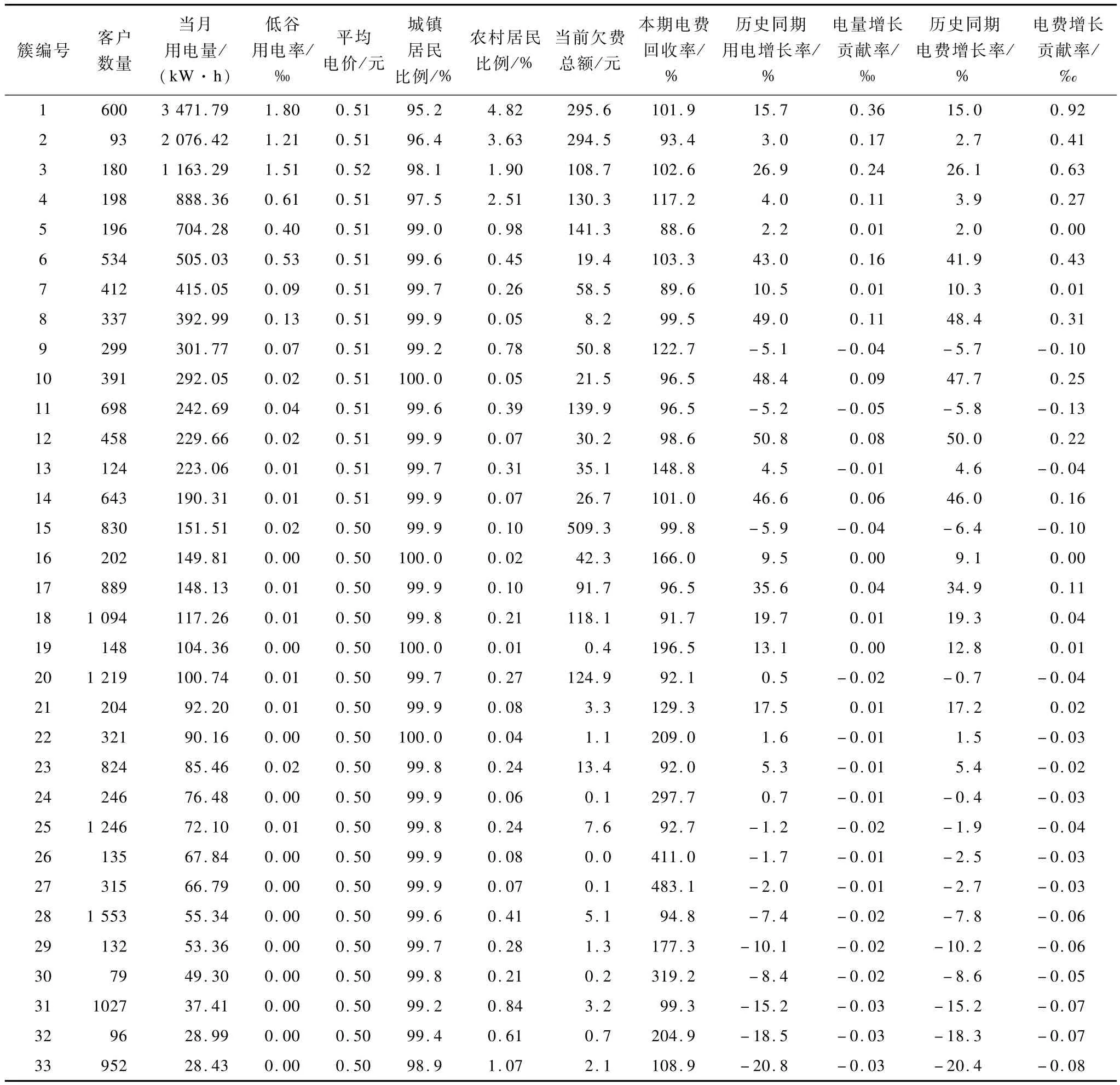
表5 各類包含的客戶數和類中心點分布
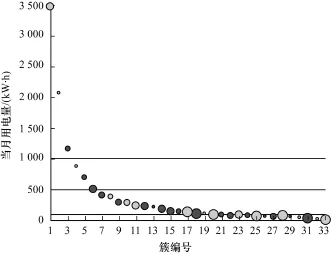
圖3 各類按當月用電量分布
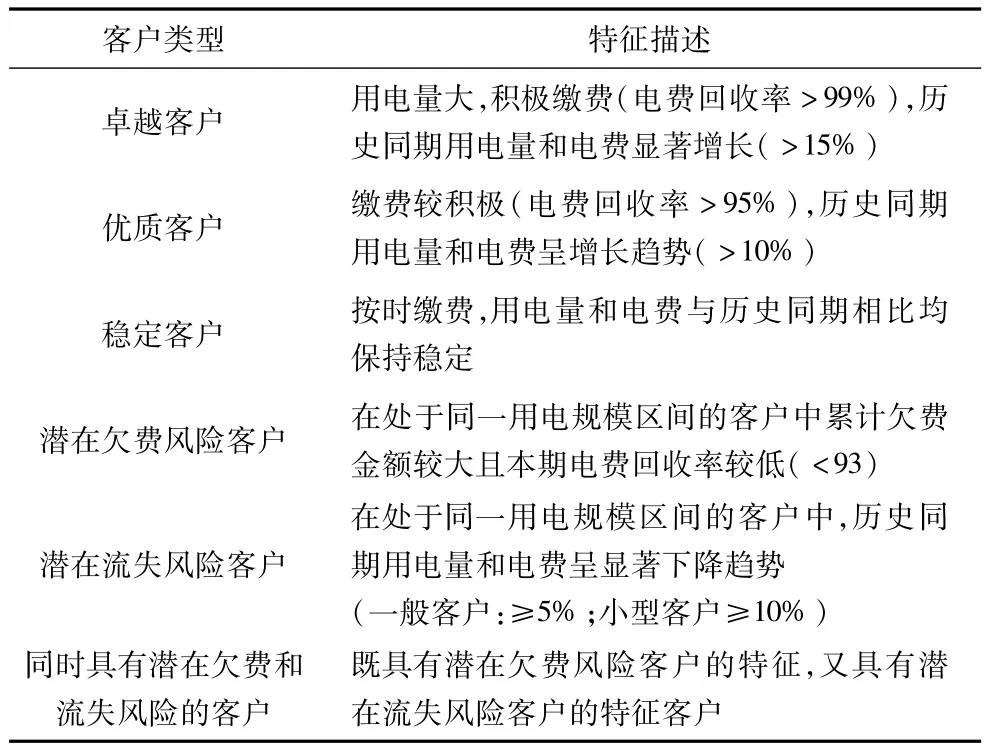
表6 各類型客戶的特征描述
圖4描述了各簇在用電量和客戶類型上的交叉細分結果,高價值客戶用六邊形表示,圖形中的數字為每個簇的簇編號。識別出的高價值客戶共4 384名,占客戶總量的26.07%。
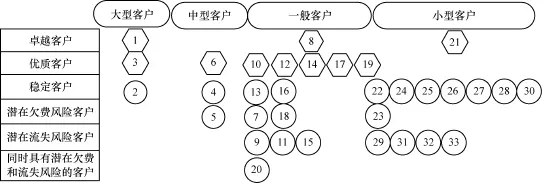
圖4 各簇在用電量和客戶類型上的交叉細分結果
供電企業可根據各類客戶的特征制定有針對性的服務措施。
從識別出的4 384名高價值客戶中隨機抽取50名客戶,由該供電公司組織營銷業務專家采用表3中指標和文獻[13]提供的客戶價值評價方法評價其價值,評價結果顯示:46名客戶的分類類型與使用SOM-DB-PAM得到的分類類型吻合。綜合業務專家的意見,認為該細分結果符合業務實際需要并具有良好的解釋性和一定的實用性。
5 結束語
隨著我國國家電網公司SG186信息化工程的深入推進和95598服務系統的投入運營,電力營銷數據庫中存儲的電力客戶數據呈數量級增長,如何有效利用這些信息對客戶進行快速、準確的細分和定位,是供電企業制定服務對策的前提。本文提出的SOM-DB-PAM混合聚類算法為解決這一問題提供了一種思路,針對電力客戶用電行為數據量龐大的特點,首先利用SOM對數據進行“粗聚類”得到表征數據主要特征的原型向量以壓縮數據量,再使用PAM對所獲得的原型向量正式聚類并用DB指標識別最優聚類數目,PAM的健壯性使其不易受到用電行為噪聲數據的影響,同時保證了DB指標的穩定性,而用遠小于初始樣本數的原型向量替代原始數據大大降低了PAM的計算量。分別采用仿真數據集和電力客戶真實用電數據對算法性能進行了測試,實驗結果表明,與傳統聚類算法相比,SOM-DB-PAM混合聚類算法在不同規模的測試數據集上,均能正確判別聚類個數并得到更好的分類結果,將其應用于電力客戶細分,能快速有效聚類并得到具有良好解釋性的細分結果,算法適用于針對大量電力客戶的深度細分。作為衡量聚類效度的指標,DB指標主要針對數值型細分變量,當細分變量為分類變量時,使用DB判別最優聚類數目的效果不理想,而電力客戶基本信息中包含了大量對細分有價值的分類變量,如客戶所在行業、用電類型、繳費方式等,研究適用于混合數據類型的聚類效度指標,擴展算法的適用范圍,是電力客戶細分研究有待進一步解決的問題。
[1] Smith W R.Product Differentiation and Market Segmentation as an Alternative Marketing Strategy[J]. Journal of Marketing,1956,21(1):3-8.
[2] Floh A,Zauner A,Koller M,et al.Customer Segmentation Using Unobserved Heterogeneity in the Perceived-value-loyalty-intentions Link[J].Journal of Business Research,2014,67(5):974-982.
[3] 威廉·G·齊克蒙德,小雷蒙德·邁克里奧德.客戶關系管理:營銷戰略與信息技術的整合[M].胡左浩,譯.北京:中國人民大學出版社,2005.
[4] 郭迎春.知識型電力客戶關系管理研究[D].保定:華北電力大學,2008.
[5] López J J,Aguado J A,Martín F,et al.Hopfield-K-Means Clustering Algorithm:A Proposal for the Segmentation of Electricity Customers[J].Electric Power System s Research,2011,81(1):716-724.
[6] 徐天池.基于數據挖掘的電網客戶細分系統設計與實現[D].廣州:中山大學,2013.
[7] 王軼華.電力客戶綜合價值分析[D].上海:上海交通大學,2007.
[8] 王松濤.市場條件下的電力客戶價值分析體系[J].電網技術,2010,34(2):155-158.
[9] 李泓澤,郭 森,王 寶.基于遺傳改進蟻群聚類算法的電力客戶價值評價[J].電網技術,2012,36(12):256-261.
[10] 曾 鳴,楊素萍,楊鵬舉,等.社會節能環境下電力客戶價值評估研究[J].華東電力,2008,36(6):15-18.
[11] 王春葉.基于數據挖掘的電力客戶細分研究[D].保定:華北電力大學,2009.
[12] Wind Y.Issues and Advances in Segmentation Research[J].Journal of Marketing Research,1978,15(1):317-337.
[13] 蔣維楊.電力客戶價值評價及信息系統開發研究[D].西安:西北工業大學,2010.[14] Zhou Kaile,Yang Shanlin,Shen Chao.A Review of Electric Load Classification in Smart Grid Environment[J].Renewable and Sustainable Energy Reviews,2013,(24):103-110.
[15] Laan V D,Pollard M J,Katherine S,Jennifer B.A New Partitioning Around Medoids Algorithm[J].Journal of Statistical Computation&Simulation,2003,78(8):575-675.
[17] Hiziroglu A.Soft Computing Applications in Customer Segmentation:State-of-art Review and Critique[J].Expert Systems with Applications,2013,40(1):6491-6507.
[18] 安 璐,張 進,李 綱.自組織映射用于數據分析的方法研究[J].情報學報,2009,28(5):720-726.
[19] Vesanto J,Alhoniemi E.Clustering of the Selforganizing Map[J].IEEE Transactions on Neural Networks,2000,11(3):586-600.
[20] Wang J.Encyclopedia of Data Warehousing and Mining[M].Hershey,USA:Information Science Press,2006.
[21] Rasanen T,Ruuskanen J,Kolehmainen M.Reducing Energy Consumption by Using Self-organizing Maps to Create More Personalized Electricity Use Information[J].Applied Energy,2008,85(1):830-840.
編輯 索書志
Power Customer Segmentation Based on SOM-DB-PAM Hybrid Clustering Algorithm
HU Xiaoxue,ZHAO Songzheng,WU Nan
(School of Management,Northwestern Polytechnical University,Xi’an 710129,China)
Based on power customers which reach a very large amount and the feature of presence of outlier,and limitations of Partitioning A round Medoid(PAM)algorithm in handling large amounts of data and predefining the number of clusters,a new hybrid clustering algorithm called SOM-DB-PAM that is suitable for fast clustering of large number of electricity customers,is proposed.In the proposed algorithm,the Self-Organizing Map(SOM)neural network is used to train input data to find prototype vectors that represents patterns of the input data set but far less than the number of it,and the prototype vectors are clustered by the PAM algorithm and to ensure the validity of clustering,the Davies-Bouldin(DB)indexis calculated for SOM prototype vectors to solve optimal number of clusters.Experimental results show that,com pared with traditional clustering algorithm s,the accuracy of classification is enhanced and when the amount of electricity customers is large,the proposed algorithm can achieve a fast and effective clustering.In addition,the blindness and subjectivity of predefining the number of clusters artificially is decreased.
power customer segmentation;Partitioning A round Medoid(PAM);Self-Organizing Map(SOM);hybrid clustering algorithm;clustering analysis
胡曉雪,趙嵩正,吳 楠.基于SOM-DB-PAM混合聚類算法的電力客戶細分[J].計算機工程,2015,41(10):295-301,307.
英文引用格式:Hu Xiaoxue,Zhao Songzheng,Wu Nan.Power Customer Segmentation Based on SOM-DB-PAM Hybrid Clustering Algorithm[J].Engineering Computer,2015,41(10):295-301,307.
1000-3428(2015)10-0295-07
A
TP391
國家教育部博士點基金資助項目(20116102110036)。
胡曉雪(1986-),女,博士研究生,主研方向:數據挖掘,電力企業市場營銷,客戶關系管理;趙嵩正,教授、博士生導師;吳 楠,博士研究生。
2014-08-28
2014-11-12E-mail:nolanspring@163.com
