基于密度與距離參數的CHMM聲學模型初值估計
2015-03-07 11:43:37鮮曉東呂建中樊宇星
計算機工程 2015年10期
關鍵詞:模型
鮮曉東,呂建中,樊宇星
(重慶大學 a.信息物理社會可信服務計算教育部重點實驗室;b.自動化學院,重慶400044)
基于密度與距離參數的CHMM聲學模型初值估計
鮮曉東a,b,呂建中b,樊宇星b
(重慶大學 a.信息物理社會可信服務計算教育部重點實驗室;b.自動化學院,重慶400044)
在語音識別中,連續型隱馬爾可夫模型(CHMM)在初始化時采用分段K-means算法,但該算法會導致模型參數收斂于局部最優。針對該問題,提出基于密度和距離參數的CHMM模型初始化算法。計算數據對象的距離和密度參數,選擇密度值較大而同時距離較遠的數據對象作為初始聚類中心,對其進行K-means聚類處理,得到最終的聚類中心,根據聚類中心初始化CHMM模型的參數。實驗結果表明,與隨機取值算法相比,該算法提高了語音的識別率。
語音識別;連續型隱馬爾可夫模型;K-means算法;局部最優;參數初始化
DO I:10.3969/j.issn.1000-3428.2015.10.060
1 概述
在語音識別中,關鍵的問題是建立每個語音識別基元的聲學模型。目前,應用較多的是隱馬爾可夫聲學模型。連續型隱馬爾可夫模型(Continuous Hidden Markov Model,CHMM)[1]由于其計算精度高的優點,在聲學模型中有較好的應用前景。對于連續型隱馬爾可夫聲學模型的研究主要有2個方面的內容:聲學模型的訓練和聲學模型的匹配。對于聲學模型的訓練采用的是Baum-Welch迭代算法。Baum-Welch算法不是一種解析算法,它是在給定初始模型的基礎上,不斷趨近于局部的最優解,不同的初始模型會得到不同的CHMM,因此,初始模型選取的準確程度影響語音識別的精度。目前,初始模型的選取主要采用分段K-means算法。
K-means算法[2]是一種基于劃分的聚類算法,應用比較廣泛,它的優點是計算簡單快速,但是也存在一些不足,不同的初始聚類中心會產生不同的聚類效果,同時會受到數據邊緣點和孤立點的干擾。很多學者對K-means的初始聚類中心的選取[3]以及
聚類過程[4]進行了研究。文獻[5]通過在聚類過程中進行變量的自動加權對傳統算法進行改進。文獻[6]將遺傳算法應用到了K-means聚類算法中,文獻[7]對遺傳算法的全局搜索和K均值算法的局部搜索進行了結合聚類,文獻[8]將粒子群優化與K-means進行混合聚類來提高全局搜索功能,但是這些算法計算量比較大。文獻[9]提出了一種基于空間劃分的初始聚類中心選取的方法。文獻[10-11]提出了基于密度的初始化聚類算法,文獻[12]提出了基于距離聚類的初始化算法,但是這2類算法中各有不足,基于密度的沒有考慮類間的相似度,而基于距離的沒有考慮類內的相似度。因此,本文采用結合距離與密度的方法進行初始聚類中心的選取,同時將該方法應用到語音的識別中。
2 連續型隱馬爾可夫模型
一個語音識別基元的隱馬爾可夫聲學模型可以由4個參數來描述,分別定義為:
(1)N,模型中的狀態總數;
(2)π={πi},初始的狀態概率分布,表示開始時處于第i個狀態的概率;
(3)A={aij},狀態的轉移概率分布矩陣,表示狀態由i轉移到j的概率;
(4)bi(Ot),概率密度函數,表示處于狀態i時,第t個輸入序列的輸出概率。
采用混合高斯函數作為概率密度函數,每個狀態下對應一個混合高斯函數來表示該狀態下的輸出概率。
混合高斯函數表示為:

2.1 傳統的初始化算法
在CHMM的初始模型選取中,對于狀態轉移概率,可以采用隨機取值和均值取值,對于狀態初始概率,一般是根據所選模型類型進行取值,初值選取的關鍵主要在于混合高斯密度函數各個參數的選擇上,一般采用分段K-means算法。
分段K-means算法是采用分段聚類的方法,將訓練數據分割成K類,將每類的均值向量和協方差矩陣作為高斯分量的初始均值向量和方差向量。
算法具體步驟如下:
(1)將語音訓練數據分成N段,N為訓練模型的狀態總數,每段為該狀態下對應的觀察值向量,這樣完成了分段。
(2)在每個狀態下的訓練數據中,隨機選擇K個特征矢量作為聚類的初始中心矢量。
(3)其余的點根據歐式距離計算與各個聚類中心的距離,選擇最小距離對應的聚類中心作為其類別。
(4)計算各類中數據的均值矢量,作為新的聚類中心,如果新的聚類中心與原聚類中心的距離滿足要求,說明聚類完成,否則轉第(3)步,繼續進行聚類處理。
(5)聚類完成后,得到K個聚類中心,即每一類的均值矢量,同時計算每一類的方差矢量,將其作為高斯密度函數的均值和方差的初始值。
傳統算法的優點是計算過程比較簡單,但是這種算法在聚類過程中有缺點。隱馬爾可夫模型的參數優化算法依賴于初始值的設置,在初始值的基礎上不斷趨近最優的一組參數,對于初始參數比較敏感,不同的初始參數會產生不同的訓練模型,而傳統的短算法對于初始值的計算比較粗略,是隨機選取了K個聚類中心點進行的計算,沒有結合訓練數據的特點,因此,最終的聚類結果的準確性受到影響。
2.2 基于密度和距離參數的初始化算法
根據分析,可以知道初始聚類中心應該遵循這樣的原則:
(1)聚類中心之間的距離盡量大,這樣類別之間的相似度較差;
(2)聚類中心應該處在數據密度大的地方,這樣類內的相似度較強,同時可以消除孤立點的影響。
基于數據密度和數據距離的聚類算法的基本思想是:首先計算每個訓練數據對象的密度值,以及任意2個對象的距離,通過這2個參數,選擇K個數據對象作為初始聚類中心,滿足密度值較大,同時任意2個中心的距離較遠,然后采用K-means的算法進行聚類。
定義密度:以數據對象χ為中心,半徑為R的空間區域內包含數據對象的數目稱為數據 χ的密度,用ρ表示。ρ越大,表示數據對象χ所處的區域數據對象比較集中,類內的相似度較高,反之,則類內相似度較低,可能是孤立點或噪聲干擾。
具體的算法描述如下:
(1)計算任意 2個對象之間的距離:dχy=組成距離集合D,同時求取平均距離。
(2)由平均距離設定半徑R,根據R計算訓練的數據對象的密度值,組成密度集合M。
(3)選擇M集合中密度值最大的數據對象作為第1個初始聚類中心,在集合M中剔除χ1,從M集合中選擇第2個初始聚類中心 χ2,滿足的條件是在
與χ1的距離不小于R的數據對象中χ2的密度值是最大的,然后選擇第3個聚類中心 χ3,同樣在與 χ1,χ2的距離均不小于2R的數據對象中χ3的密度值是最大的,進行選擇k次,得到k個初始聚類中心。
(4)將第(3)步計算選擇出的聚類中心作為初始中心,然后采用K-means算法對語音數據進行聚類處理,從而將語音的訓練數據分成K類,每類的均值矢量作為高斯概率密度函數的均值估計,方差矢量作為高斯概率密度函數的方差估計,由每類的數據對象的總數得到對應的高斯分量的權值。
以上算法完成了按照數據對象的密度和距離參數的初始化處理,克服了K-means的初值隨機選擇的缺陷,使選擇出的初始聚類中心能夠最大程度表征數據對象的分類。根據距離準則是類間數據對象的距離較大,相似性較弱,而同時結合密度參數,保證了所選的聚類中心不會是孤立點,這樣得到的高斯概率密度函數較準確,有利于進行模型參數的重估。
本文算法首先需要計算距離和密度,并通過計算得到初始聚類中心,較傳統算法復雜,單次迭代的復雜度較高,但是基于密度和距離選擇初始聚類中心的算法因為克服了傳統算法的初值隨機選擇的缺陷,初值聚類選擇得比較恰當,迭代次數會減少,使得本文算法的速度快于傳統算法。
3 實驗結果與分析
K-means算法是一種經典的聚類算法,應用比較廣泛,計算簡單快速;文獻[10]算法相比其他優化算法在考慮聚類效果的前提下,計算量較小,實現比較容易。為了驗證本文算法的有效性,對特征參數分別采用傳統K-means聚類算法、文獻[10]算法以及本文算法進行比較。進行仿真實驗,錄制了30段語音詞組,通過預處理和特征提取之后,得到語音的特征參數矩陣,對特征參數分別采用上述3種算法進行聚類,聚類的性能結果如表1所示。
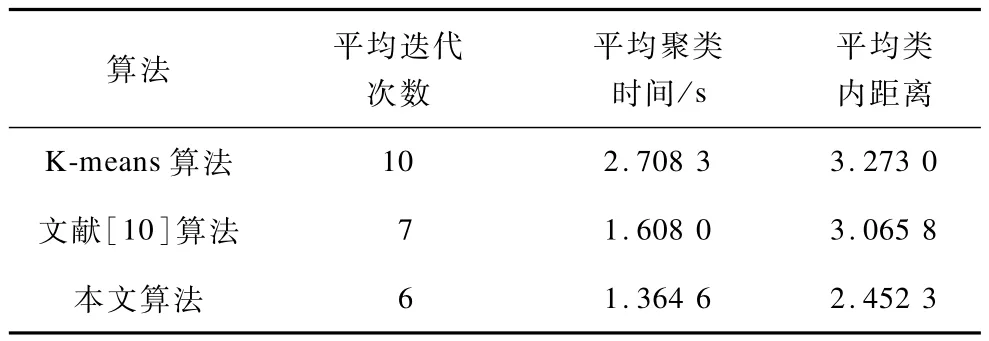
表1 3種算法性能比較
文獻[10]算法主要采用密度參數進行初始聚類中心的選取,相比于傳統的初始化算法和文獻[10]算法,基于密度和距離選擇初始聚類中心的算法迭代次數減少了很多,說明初值聚類選擇的比較恰當,而且平均的類內距離,即類內的矢量到該類中心的距離要小一些,說明聚類中心能夠較好地表征該類的特征矢量。在實時性方面,本文算法的聚類時間要少于傳統K-means聚類算法和文獻[10]算法。
30段語音數據的特征參數聚類后類內方差、類間方差如圖1、圖2所示。
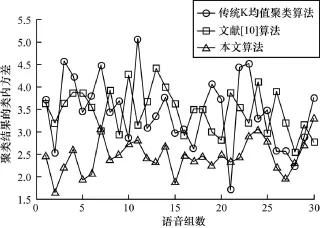
圖1 語音數據聚類結果類內方差
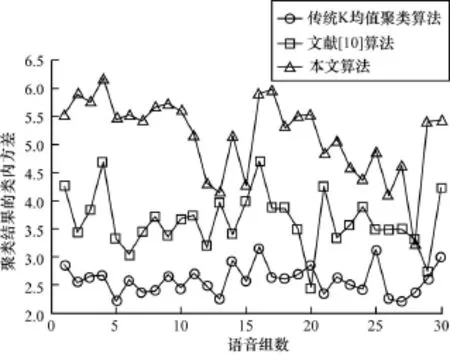
圖2 語音數據聚類結果類間方差
圖1表示語音數據聚類之后類內的方差,從圖中可以得出,采用本文算法進行聚類初始化的類內方差要小于隨機選擇初值的傳統K-means聚類和文獻[10]算法的類內方差。圖2表示語音數據聚類后類間的方差,從圖中可以得出,采用本文算法進行聚類初始化的類間方差要大于隨機選擇初值的傳統K-means聚類和文獻[10]算法的類內方差,說明基于本文的初始化算法的聚類算法得到的聚類中心之間不僅距離較遠,即聚類中心點分布較分散,同時各個聚類中心在語音數據的聚集點消除了孤立點的干擾,能夠表征該類之內的數據,因此,聚類的效果相比隨機初值的傳統K-means聚類的效果要好。
實驗中所用到的語音數據采集于實驗室的同學,錄制了8個人(5男3女)的語音,創建了18個詞的語音庫,每個詞匯每人錄制了 7次,采樣頻率為22 050 Hz,每個詞有56個語音數據,總共有1 008個語音數據,對于每個詞將其中的24個語音數據作為訓練語音,總共得到240個訓練數據,其余的作為測試樣
本,每個詞有32個測試樣本。
將實驗中采集的18個詞作為測試模板(即測試用例)進行識別。表2為采用傳統的初始化算法和本文的初始聚類中心算法進行聚類得到的結果;表2有18組測試樣本,其中每組32個,實驗結果表明,本文算法相對于傳統算法的正確識別個數明顯增加,誤識數減少;且傳統算法在左轉和右轉上誤識數多,這是因為讀音有相似的地方,導致提取出的參數有部分相似,而傳統算法訓練的模型不能較好地消除這種影響,導致讀音相近時誤識數較高,而本文算法減小了這種影響,誤識數明顯減少,能訓練較好的模型。
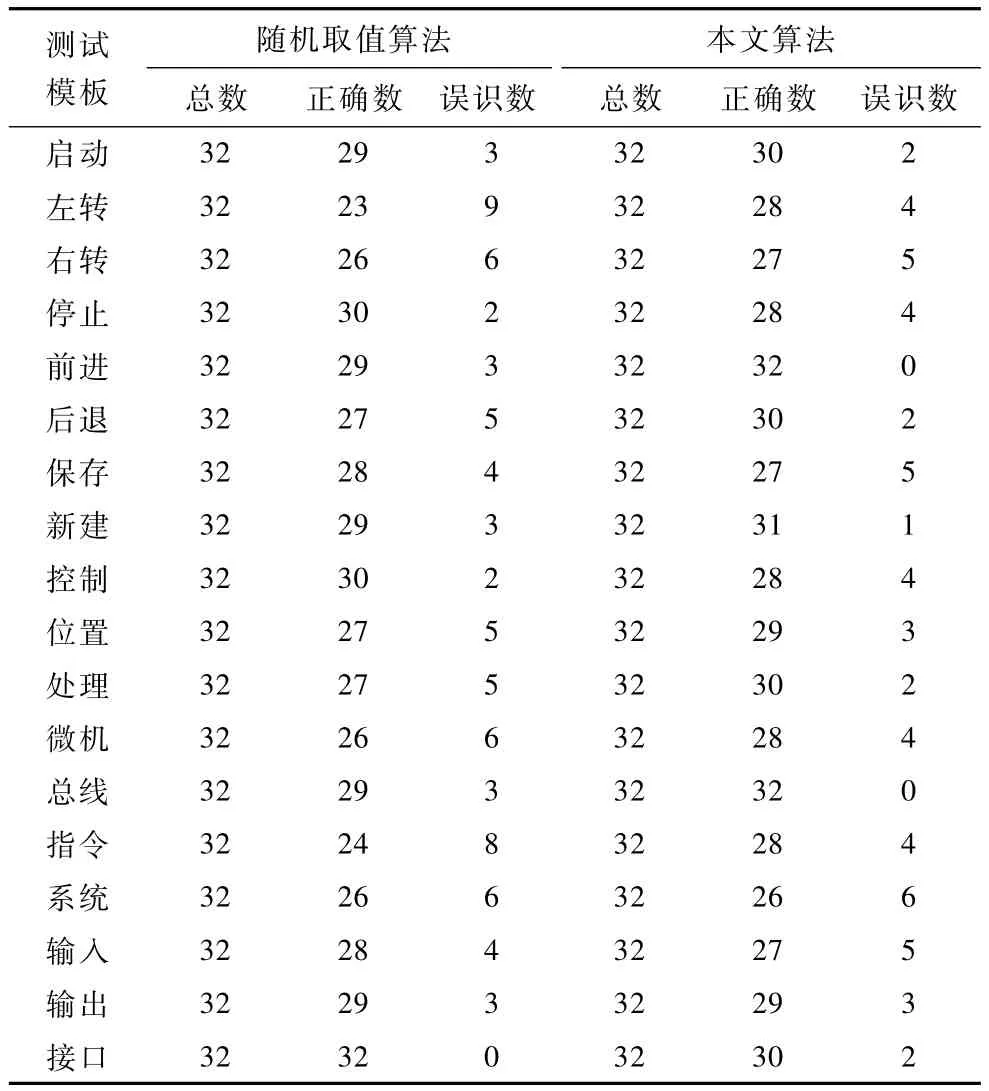
表2 2種算法識別結果
為了評價基于密度和距離的初始化算法的效果,選擇識別率作為評價標準,識別率 s定義如下:s=(r/n)×100%,其中,n為詞總數;r為識別正確詞數。表3為識別率的比較。可以看出,相比隨機選擇聚類中心的識別率86.7%,本文算法的識別率達到了90.3%,識別率較高,同時訓練得到的模型對于語音的描述較好,測試語音與其匹配值較高。這說明本文算法能在一定程度上提高語音識別率,達到較好的效果。

表3 2種初始化算法的識別率 %
4 結束語
針對語音識別中,利用連續型隱馬爾可夫模型對語音訓練時,初始化采用分段K-means算法會導致模型參數可能收斂于局部最優的問題,本文提出了一種基于密度和距離參數的CHMM模型初始化算法。將傳統K-means聚類算法、文獻[10]算法和本文算法在多段語音詞組下進行仿真實驗對比,結果表明,本文算法能滿足實時性要求,訓練得到的模型對于語音的描述較好,并在語音的識別率上有所提高。
[1] 趙 力.語音信號處理[M].北京:機械工業出版社,2008.
[2] 袁 芳,孟增輝,于 戈.對K-means聚類算法的改進[J].計算機工程與應用,2004,40(36):176-178.
[3] Deelers S,Auwatanamongkol S.Enhancing K-means Algorithm with Initial Cluster Centers Derived from Data Partitioning Along the Data Axis with the Highest Variance[C]//Proceedings of World Academy of Science,Engineering and Technology.Washington D.C.,USA:IEEE Press,2007:323-328.
[4] 劉 韜,蔡淑琴,曹豐文,等.基于距離濃度的 K-均值聚類算法[J].華中科技大學學報:自然科學版,2007,32(10):50-52.
[5] Huang Zhexue,Ng M K,Rong Hongqiang.Automated Variable Weighting in K-means Type Clustering[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2005,27(5):657-668.
[6] Sarafis I,Zalala A M S,Trinder PW.A Genetic Rulebased Data Clustering Toolkit[C]//Proceedings of Congress on Evolutionary Computation.Honolulu,USA:[s.n.],2002:1238-1243.
[7] 陸林華,王 波.一種改進的遺傳聚類算法[J].計算機工程與應用,2007,43(21):170-172.
[8] 陶新民,徐 晶,楊立標,等.一種改進的粒子群和 K均值混合聚類算法[J].電子與信息學報,2010,32(1):93-97.
[9] 蘇錦旗,薛惠鋒,詹海亮.基于劃分的K-均值初始聚類中心優化算法[J].微電子學與計算機,2009,26(1):8-11.
[10] 傅德勝,周 辰.基于密度的改進 K均值算法及實現[J].計算機應用,2011,31(2):432-434.
[11] 汪 中,劉貴全,陳恩紅.一種優化初始中心點的K-means算法[J].模式識別與人工智能,2009,2(4):299-304.
[12] 蘇 中,馬少平,楊 強.基于Web-Log Mining的Web文檔聚類[J].軟件學報,2002,13(1):99-104.
編輯 顧逸斐
Initial Estimation of CHMM Acoustic Model Based on Density and Distance Parameter
XIAN Xiaodonga,b,LV Jianzhongb,FAN Yuxingb
(a.Key Laboratory of Information Physical Society Credible Service Computing,Ministry of Education;b.College of Automation,Chongqing University,Chongqing 400044,China)
The method of Continuous Hidden Markov Model(CHMM)parameter initialization for speech recognition is segmented with K-means algorithm that can lead to convergence in local optimization of model parameters.A new approach of CHMM parameters initialization is proposed based on density and distance.Computing density and distance of data,the initial cluster center is selected according to the far distance and max density,then carries the K-means clustering process to get the final cluster centers,and initializes the CHMM parameters according to the cluster center. Experimental results show that the new approach has better recognition results compared with random selection algorithm.
speech recognition;Continuous Hidden Markov Model(CHMM);K-means algorithm;local optimization;parameter initialization
鮮曉東,呂建中,樊宇星,等.基于密度與距離參數的CHMM聲學模型初值估計[J].計算機工程,2015,41(10):318-321.
英文引用格式:Xian Xiaodong,Lv Jianzhong,Fan Yuxing.Initial Estimation of CHMM Acoustic Model Based on Density and Distance Parameter[J].Computer Engineering,2015,41(10):318-321.
1000-3428(2015)10-0318-04
A
TP301.6
重慶市教育委員會科學技術研究基金資助項目(KJ08A 01)。
鮮曉東(1966-),女,副教授、碩士,主研方向:無線傳感器網絡,移動機器人控制;呂建中、樊宇星,碩士研究生。
2014-08-18
2014-10-26E-mail:xxd@cqu.edu.cn
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
