大數據領域演進路徑、研究熱點與前沿的可視化分析
2015-04-13 08:53:24何曉萍
現代情報 2015年4期
何曉萍 黃 龍
(南昌大學圖書館,江西南昌 330031)
?
大數據領域演進路徑、研究熱點與前沿的可視化分析
何曉萍 黃 龍
(南昌大學圖書館,江西南昌 330031)
本文以Web of Science為數據源,運用信息可視化軟件CiteSpace Ⅲ對所搜集的有關大數據研究的文獻進行聚類分析和共引分析。通過CiteSpace Ⅲ生成的知識圖譜并結合相關文獻的研究內容,從演進路徑、研究熱點以及研究前沿三方面對大數據研究進行量化分析和解讀。6篇關鍵節點文獻很好地展示了大數據研究的演進路徑,13個高頻關鍵詞和10個突現詞表征了大數據的研究熱點與研究前沿,得出結論:大數據的研究經歷了從大數據的計算模型、具體概念、復雜性科學的理論研究到有關大數據社會科學層面、應用型實踐層面研究的歷程;大數據處理技術、大數據挖掘及大數據應用是大數據研究的三大熱點;對大數據本身的研究、處理技術的研究、數據挖掘、系統、模型和網絡的研究以及其績效評估和數據管理的研究是大數據的研究前沿和發展趨勢,文章旨在為現階段大數據研究工作的深入開展提供參考。
大數據;CiteSpace Ⅲ;演進路徑;研究熱點;研究前沿;可視化
大數據是當下繼云計算之后的一大熱點詞匯。2011年5月,信息存儲資訊科技公司EMC在“云計算相遇大數據(Cloud Meets Big Data)”大會上正式提出了“大數據”的概念。幾近同時,麥肯錫全球研究院(MGI)發布了一份研究報告《大數據:創新、競爭和生產力的下一個前沿領域》(Big data,The next frontier for innovation,competition,and productivity)[1],它研究了文檔和數字數據的狀態以及處理這些數據所帶來的潛在價值。2012年1月,在瑞士達沃斯舉行的世界經濟論壇上,“大數據”是主要討論的主題之一,該論壇上發布了一份題為《大數據,大影響》(Big Data,Big Impact)的報告,提出“數據已成為一種新的經濟資產類別,就像貨幣或黃金一樣。”[2]2012年3月,美國奧巴馬政府在白宮網站上發布了《大數據研究和發展倡議》(Big Data Research and Development Initiative),該倡議涉及聯邦政府的6個部門,這些部門承諾將投資超過兩億美元,來大力推動和改善大數據的提取、存儲、分析、共享和可視化[3]。
無論是EMC、MGI的研究報告,世界經濟論壇的論題,還是美國政府的倡議,都向人們預示著大數據時代的來臨。國內外對大數據的研究不斷增加,該領域的研究文獻量也與日俱增,大量的研究文獻使得人們難以對大數據的知識進行深入地研究。信息可視化是常用的數據挖掘方法之一,它可以利用人類在可視化形勢下對模型和結構的獲取能力來解決科技文獻數量過大、無法快速進行有效交流的問題,可視化數據挖掘可以觀察、發現、篩選和理解信息,發現數據和信息背后所隱藏的含義[4]。本文將運用信息可視化工具CiteSpace Ⅲ,以Web of Science數據庫中收錄的有關大數據研究的文獻為樣本進行聚類分析和共引分析,對大數據的研究熱點、主題內容和發展趨勢三方面進行量化分析和解讀。
1 數據來源和研究方法
Web of Science是美國Thomson Scientific(湯姆森科技信息集團)基于WEB開發的產品,是大型綜合性、多學科、核心期刊引文索引數據庫,收錄了8 000多種世界范圍內最有影響力的、經過同行專家評審的高質量的期刊[5],以Web of Science為數據源進行研究,可以保證研究數據的全面性和權威性。本文選取了Web of Science數據庫中的4個子庫:Science Citation Index Expanded(SCI-EXPANDED)、Social Sciences Citation Index(SSCI)、Conference Proceedings Citation Index-Science(CPCI-S)和Conference Proceedings Citation Index-Social Science& Humanities(CPCI-SSH),檢索方式選擇高級檢索,檢索策略為:主題=(“big data”),時間跨度=所有年份,共檢索到有關大數據得研究文獻記錄1 849條(檢索日期:2014年10月12日)。
本文研究工具采用陳超美教授開發的信息可視化軟件CiteSpace Ⅲ,其獨到的創新之處在于繪制的一幅科學知識圖譜,能夠顯示一個學科或知識域在一定時期發展的趨勢與動向,形成若干研究前沿領域的演進歷程[6]。將檢索到的1 849篇文獻題錄信息(主要包括篇名、關鍵詞、摘要、作者、參考文獻等字段)導入到CiteSpace Ⅲ軟件中。有關大數據研究的第一篇文獻的發表于1993年,即所檢索到的文獻時間范圍是1993-2014年,共計22年,以每2年設為1個時間分區(Time slicing),總共分為11個時間段;主題詞來源(Term Source)選擇標題(Title)、摘要(Abstract)、關鍵詞(Author Keywords)和標識符(Keywords Plus);分析節點(Node Types)選擇共引文獻(Cited Reference);設置閥值(c,cc,ccv)為(2,2,15),(3,2,20),(4,3,20),c為最低被引次數,cc為本時間段內的共被引次數,ccv為規范化以后的共被引次數,每個時間段中選取被引次數最高的30篇文獻。運行CiteSpace Ⅲ軟件,得到大數據研究共引分析文獻網絡組圖和知識圖譜,就此分析關鍵節點文獻。主題詞類型(Term Type)有名詞短語(Noun Phrases)和突現詞(Burst Terms)兩種,名詞短語可以表達大數據的研究熱點,而突現詞則可表達大數據的研究前沿及發展趨勢。
2 結果與分析
2.1 大數據研究文獻的時間分布情況
對WOS數據庫中大數據研究文獻按年代變化進行時間分布分析,如圖1所示,從圖中可以看出,大數據的研究可以分為3個階段:第一階段從1993-2007年,為大數據的孕育階段,該階段大數據研究成果零散,發文量十分有限;第二階段從2008-2011年,為大數據研究的起步階段;第三階段從2012-2014年,為大數據研究的上升階段,研究文獻劇增,且年發文量大于200篇,呈現出快速增長的態勢,2014年的文獻數據不全,但已有600篇,由此可以預測未來大數據的研究將保持迅猛增長的勢頭。同時,通過Logistic曲線擬合文獻量的時間序列分布,發現大數據研究還處在快速上升時期,還沒出現成熟前的“拐點”。
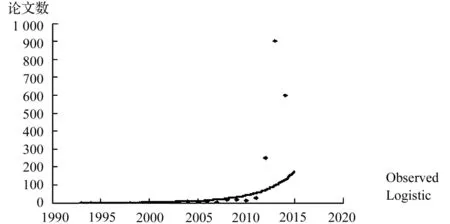
圖1 大數據研究文獻的年度時間分布
2.2 大數據研究的演進路徑分析
信息可視化軟件CiteSpace Ⅲ有兩種顯示共引網絡圖譜的視圖方式,分別為聚類視圖(cluster views)和時區視圖(time-zone views)。時區視圖的顯示方式突出共引網絡節點隨時間變化的結構關系[6]。運行CiteSpace Ⅲ軟件得到大數據研究文獻共引網絡節點的時區視圖,圖譜中共有182個節點,410條連線,如圖2所示。

圖2 大數據共引網絡節點的時區視圖
CiteSpace Ⅲ最突出的特點就是關鍵節點的計算測量,圖中每個圓形節點代表一篇引文,節點大小與被引用次數有關,節點越大,被引頻次越高,其文獻價值也越大,當設置“標簽字體大小依比例顯示選項”后,被引頻次高的引文在圖中的字體也越大,同時,節點間的連線代表引用關系與引用時間,連線越粗則引用次數越多,連線顏色則提示引用時間,依時間先后序列由冷色向暖色改變[7]。從知識理論的角度看,關鍵節點文獻通常是在該領域中提出重大理論或是創新概念的文獻,也是最容易引起新的研究前沿熱點的關鍵文獻[8]。按被引頻次的大小,表1列舉出了圖2中排名前六位的有關大數據研究關鍵節點文獻,這些文獻都是大數據研究的知識基礎,結合圖2,按時間順序對表1中的關鍵節點文獻進行分析,即可梳理出大數據研究發展的演進路徑。
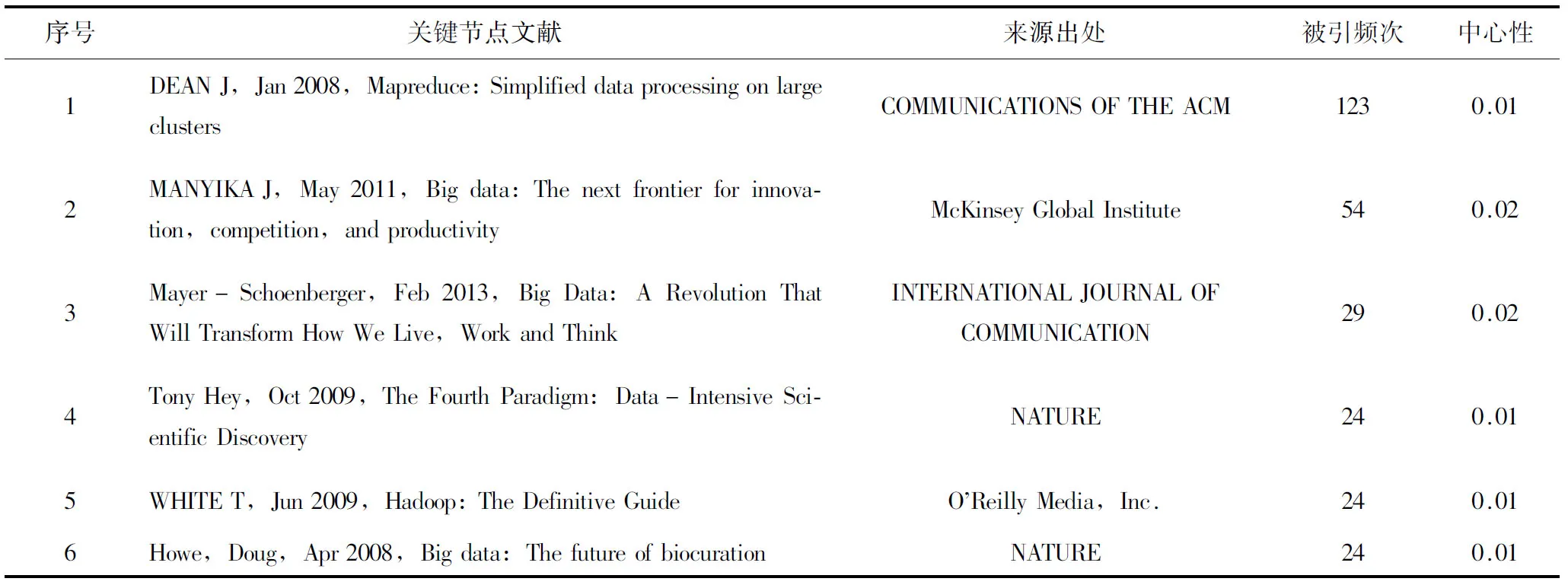
表1 大數據研究關鍵節點文獻
第一篇文獻是由MapReduce、BigTable 等系統的創造者Jeff Dean于2008年發表在《COMMUNICATIONS OF THE ACM》刊物上的《Mapreduce:Simplified data processing on large clusters》[9],文章借鑒函數式編程語言,強調了MapReduce的思想,將MapReduce模型用于大規模數據集的并行運算,包括“分布grep,分布排序,web連接圖反轉,每臺機器的詞矢量,web訪問日志分析,反向索引構建,文檔聚類等”。這說明借助關鍵技術對大規模數據進行深入的研究,最大限度地提升管理和使用大規模數據的能力開始成為研究的重點。
第二篇文獻是由Howe,Doug于2008年發表在《NATURE》雜志上的《Big data:The future of biocuration》[10],文章基于大數據環境,提出了“生物文獻數據結構化”這一概念,通過數據結構化來規范生物文獻信息,從而提高生物學信息的獲取率和利用率。這標志著大數據的研究在生物學學科得到廣泛關注。
第三篇文獻是由英國e-Science計劃前首席科學家Tony Hey于2009年發表在《NATURE》雜志上的《The Fourth Paradigm:Data-Intensive Scientific Discovery》[11],該文探索了數據密集型計算以及未來計算技術的發展,揭示出數據分析已經成為繼理論、實驗和計算之后的第四種科學發現基礎,是產生經濟價值的新源泉。數據分析有助于市場預測、社會學以及醫學等學科領域的知識規律發現和趨勢預測,達成“真理盡在數據中”的效果,“數據科學”逐漸成為業界學者研究的新興領域。
第四篇文獻是由WHITE T撰寫的《Hadoop:The Definitive Guide》[12]一書,于2009年由O’Reilly Media,Inc.出版社出版,書中展示了如何使用Hadoop構建可靠、可伸縮的分布式系統,程序員可從中探索如何分析海量數據集,管理員可以了解如何建立與運行Hadoop集群。作為處理海量數據集的理想工具,Apache Hadoop架構是MapReduce算法的一種開源應用,是Google(谷歌)開創其帝國的重要基石,更是打開“數據金礦”大門的金鑰匙。
第五篇文獻是由麥肯錫全球研究院(MGI)于2011年發布的研究報告《Big data,The next frontier for innovation,competition,and productivity》[1],該報告系統的闡述了大數據概念,麥肯錫認為,“大數據”是指其大小超出了典型數據庫軟件的采集、儲存、管理和分析等能力的數據集。該定義有兩方面內涵:一是符合大數據標準的數據集大小是變化的,會隨著時間推移、技術進步而增長;二是不同部門符合大數據標準的數據集大小會存在差別。同時,報告詳細列舉了大數據的核心技術,深入分析了大數據在美國醫療衛生、歐洲聯合公共部門管理、美國零售業、全球制造業和個人地理位置信息5個領域的應用,明確提出了政府和企業決策者應對大數據發展的策略。作為第一份從經濟和商業維度詮釋大數據發展潛力的研究成果,揭示出數據正在成為有形資本、人力資本這類產品的一個因素,如何讓商業適應大數據,如何讓大數據的更有利的管理和更有價值的分析,是一個全新的具有挑戰的話題。
最后一篇是由被譽為“大數據商業應用第一人”的Mayer-Schoenberger于2013年在《INTERNATIONAL JOURNAL OF COMMUNICATION》雜志上發表的《Big Data:A Revolution That Will Transform How We Live,Work and Think》[13],文中前瞻性地指出,大數據帶來的信息風暴正在變革我們的生活、工作和思維,大數據開啟了一次重大的時代轉型,其中最大的轉變就是,放棄對因果關系的渴求,而取而代之關注相關關系。也就是說只要知道“是什么”,而不需要知道“為什么”,這就顛覆了千百年來人類的思維慣例,對人類的認知和與世界交流的方式提出了全新的挑戰。該文還提出大數據的核心就是預測。大數據將為人類的生活創造前所未有的可量化的維度。大數據已經成為新發明和新服務的源泉,而更多的改變正蓄勢待發,例如谷歌、微軟、亞馬遜、IBM、蘋果、facebook、twitter、VISA等大數據先鋒們已經開啟了對大數據最具價值的應用歷程。因此,該關鍵節點論文是大數據應用在大數據時代的一個重要標志。
通過以上關鍵節點文獻的分析,可以得出,在2008年之前,由于大數據理論和基礎比較缺乏,有關大數據研究的論文發文量比較低,且沒有產生具有影響力的文獻。從2008年開始,隨著研究的不斷深入,進入大數據領域進行研究的機構、學者等不斷增加,有關大數據研究的論文發文量急劇增長,產生了許多重要的研究成果。大數據的研究經歷了從大數據的計算模型、具體概念、復雜性科學的理論研究,到伴隨大數據研究技術的全面拓展而進行的有關大數據社會科學層面、應用型實踐層面研究的歷程。
2.3 大數據研究熱點分析
由于關鍵詞是作者對文章核心內容的精煉與概括,體現文章研究價值與方向,因此在軟件分析結果中,頻次高的關鍵詞常被用來確定一個研究領域的熱點問題,另外,從文章中提取的名詞短語也可以在一定程度上代表某學科的研究熱點[14]。在CiteSpace Ⅲ軟件中,節點類型選擇關鍵詞(Keyword)、主題詞類型選擇名詞短語(Noun Phrases),并選擇Pathfinder算法,運行CiteSpace Ⅲ軟件得到由關鍵詞和名詞短語生成的大數據研究熱點知識圖譜,圖譜中有342個節點,1 076條連線,如圖3所示。

圖3 大數據研究熱點知識圖譜
圖3中的圓形節點和方形節點分別代表關鍵詞和名詞短語,節點的大小表示關鍵詞或名詞短語出現的頻次,圓形節點越大,越可以體現大數據的研究熱點,同樣,方形節點越大,也在一定程度上代表了大數據的研究熱點。選取出現頻次大于等于40的熱點名詞術語,得到大數據研究熱點詞匯統計表,見表2。
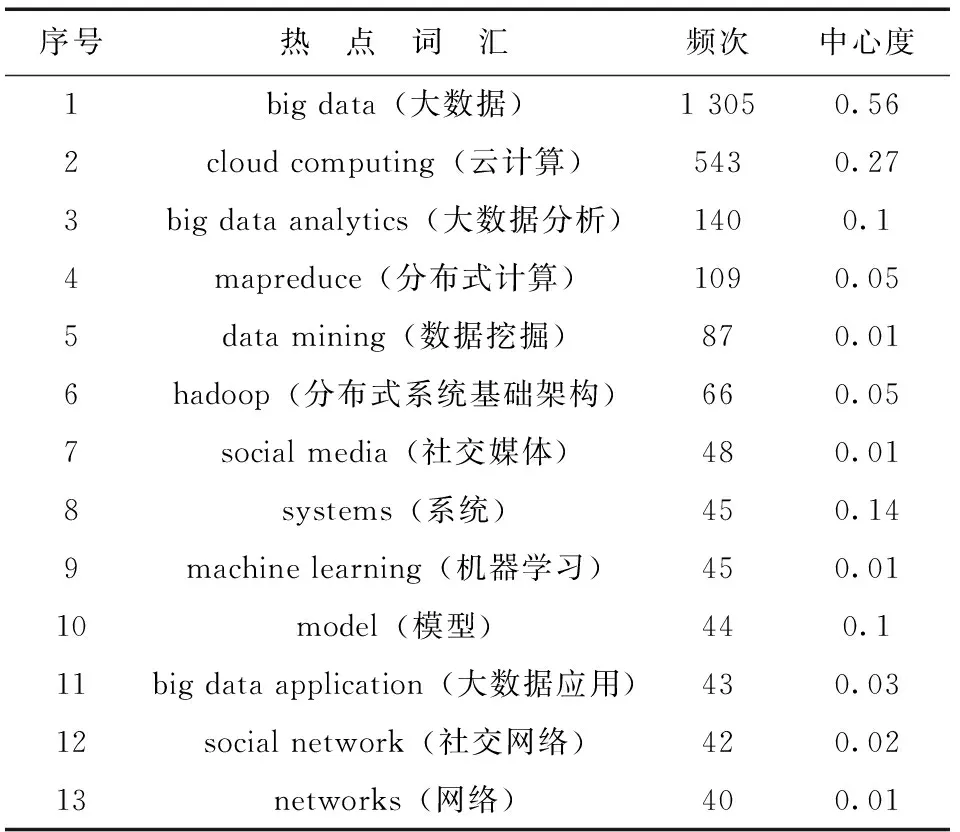
表2 頻次大于等于40的熱點詞匯統計表
從圖3和表2可以看出,出現頻次最高的熱點詞為big data(大數據),達1 305次,且其中心度值(0.56)也位居首位,一方面,表明了選擇“big data”為本文的研究主題具有一定的明確性;另一方面,也說明“big data”這一表述在學術界被普遍認可,且對大數據的研究也極其重視。其他高頻熱點詞匯按出現頻次高低分別為:cloud computing(云計算)、big data analytics(大數據分析)、mapreduce(分布式計算)、data mining(數據挖掘)、hadoop(分布式系統基礎架構)、social media(社交媒體)、machine learning(機器學習)、model(模型)、big data application(大數據應用)、social network(社交網絡)、networks(網絡),同時,這些熱點詞匯正是前文所述多數關鍵節點文獻研究的主要內容。
目前,大數據的研究熱點可以從以下3方面來分析:(1)大數據處理技術的研究。這一研究熱點主要涉及云計算、大數據分析、Hadoop、Mapreduce、模型等技術,尤其是Hadoop、Mapreduce帶來的并行式和分布式算法,為更高效率的管理和處理海量數據集帶來了可能。同時,云計算模式為大數據提供了存儲空間和計算能力,是大數據處理技術的基礎。(2)大數據挖掘的研究。這一研究熱點主要涉及云計算、社交網絡、社交媒體、數據分析、數據挖掘等。社交媒體、社交網絡的普及產生了大量的數據,而沉睡的數據只是一堆低價值密度的垃圾,只有通過數據挖掘,才能發現和創造其潛在的價值,同時,大數據挖掘的實現也需要云計算技術支持。在業界,IT巨頭們如:Google、微軟、EMC、IBM、惠普等互聯網公司都已經意識到大數據挖掘的重要意義,紛紛通過收購大數據分析公司,進行技術整合,希望從大數據中挖掘更多的商業價值[15]。(3)大數據應用的研究。這一研究熱點主要涉及大數據應用、數據分析、機器學習等。與傳統數據分析相比,大數據技術的核心目標之一即是從數據量大、數據結構類型多樣的數據中挖掘信息和獲取知識,而大數據技術這一目標的實現離不開機器學習的技術。通過機器學習高效智能地獲取新知識,為數據分析應用帶來價值是當今大數據應用研究的一大重點。
2.4 大數據研究前沿分析
陳超美認為,使用突現主題術語( surged topicalterms)要比使用出現頻次最高的主題詞(title words)更適合探測學科發展的新興趨勢和突然變化[16]。運用CiteSpace Ⅲ軟件的突現詞探測(Detect Bursts)技術,觀察詞頻的時間分布,將突現詞(Burst Terms)從大量的主題詞中探測出來,從而揭示出大數據的研究前沿。主題詞類型選擇突現詞(Burst Terms),運行CiteSpace Ⅲ軟件,得到大數據研究前沿的網絡圖譜,如圖4所示。探測得到10個突現詞,見表3。

圖4 大數據研究前沿的網絡圖譜
結合圖4和表3可以看出,突變率最高的主題詞為是“big data(大數據)”,達5.74,該主題詞代表了大數據領域對大數據本身的研究,而且,對大數據本身的研究依舊可能是未來大數據研究的熱點。除“big data(大數據)”以外,“mapreduce(分布式計算)”、“cloud computing(云計算)”、“hadoop(分布式系統基礎架構)”這3個主題詞的突變率也較高,說明mapreduce框架、云計算、hadoop框架的數據處理技術近年來備受研究者關注。同時,與數據處理技術有關的“data mining(數據挖掘)”、“systems(系統)”、“model(模型)”、“networks(網絡)”,這4個主題詞的突變率也比較高,分別是3.87、3.21、3.15和3.12,由此可以看出與大數據有關的數據挖掘、系統、模型及網絡的研究是近年來大數據領域研究的重要前沿與發展趨勢。此外,“performance(績效)”和“management(管理)”這2個高突變詞也說明了近年來大數據在績效評估和數據管理方向研究的重視,有關大數據的績效評估和數據管理也將成為未來幾年內大數據研究的重點。
3 結 論
CiteSpace Ⅲ信息可視化軟件具有較強的探測和分析某一學科演化路徑、研究熱點與研究前沿的功能,在上述大數據研究中得以完美體現,通過對Web of Science數據庫中收錄的有關大數據研究的文獻進行聚類分析和共引分析,得到以下結論:
(1)大數據研究的演進路徑:2008年,強調了MapReduce的思想,對大規模數據集進行并行運算,同時,大數據的研究開始向生物學學科滲透;2009年,探索了數據密集型計算以及未來計算技術的發展,揭示出數據分析已經成為繼理論、實驗和計算之后的第4種科學發現基礎,并且,數據處理技術Hadoop的應用,為更高效的處理海量數據集帶來了可能;2011年,系統地闡述了大數據概念,并介紹了大數據的核心技術,深入分析了大數據在不同領域的應用,明確提出了政府和企業決策者應對大數據發展的策略。2013年,前瞻性地指出了大數據帶來的信息風暴正在變革我們的生活、工作和思維,大數據開啟了一次重大的時代轉型。
(2)大數據的研究熱點概括為3個方面:一是大數據處理技術的研究;二是大數據挖掘的研究;三是大數據應用的研究。研究的內容逐漸從“概念化”走向“價值”。
(3)大數據的研究前沿有4個:一是對大數據本身的研究;二是有關大數據處理技術的研究;三是與大數據處理技術有關的數據挖掘、系統、模型和網絡的研究;四是大數據績效評估和數據管理的研究。海量數據的存儲、管理、轉換、績效評估等問題,以及大數據在社會科學層面和應用型實踐層面的研究將可能是大數據未來一段時間內的深度挖掘的方向和研究趨勢。
[1]Big data:The next frontier for innovation,competition,and productivity[EB/OL].http:∥www.Mckinsey.com/insights/business technology/big data the next frontier for innovation,2014-10-12.
[2]科技中國.大數據時代[EB/OL].http:∥www.techcn.com.cn/index.php?Edition-view-185281-2.html,2014-10-12.
[3]中國云計算.大數據大事業-白宮發布大數據研究和發展倡議[EB/OL].http:∥www.chinacloud.cn/show.aspx?id=9349&cid=17,2014-10-12.
[4]趙蓉英,徐燦.信息服務領域研究熱點與前沿的可視化分析[J].情報科學,2013,(12):9-14.
[5]百度百科.Web of Science[EB/OL].http:∥baike.baidu.com/view/3511061.htm?fr=aladdin,2014-10-12.
[6]Chaomei Chen.CiteSpace Ⅱ:Detecting and visualizing emerging trends and transient patterns in scientific literature[J].Journal of the American Society for Information Science and Technology,2006,57(3):359-377.
[7]趙智慧.文化遺產數字化研究演進路徑與熱點前沿的可視化分析[J].圖書館論壇,2013,(2):33-40.
[8]侯劍華,陳悅,王賢文.基于信息可視化的組織行為領域前沿演進分析[J].情報學報,2009,(3):422-430.
[9]DEAN J.Mapreduce:Simplified data processing on large clusters[J].COMMUNICATIONS OF THE ACM,2008,1(51):107-113.
[10]Howe D,Costanzo M,Fey P,et al.Big data:The future of biocuration[J].Nature,2008,455(7209):47-50.
[11]Tony Hey.The Fourth Paradigm:Data-Intensive Scientific Discovery[J].Nature,2009,462(7274):722-723.
[12]WHITE T.Hadoop:The Definitive Guide[M].USA:O’Reilly Media,Inc,2009:15-73.
[13]Mayer-Schoenberger.Big Data:A Revolution That Will Transform How We Live,Work and Think[J].INTERNATIONAL JOURNAL OF COMMUNICATION,2013,(7):2727-2729.
[14]趙蓉英,許麗敏.文獻計量學發展演進與研究前沿的知識圖譜探析[J].中國圖書館學報,2010,(5):60-68.
[15]何清.大數據與云計算[J].科技促進發展,2014,(1):35-40.
[16]陳超美.CiteSpace Ⅱ:科學文獻中新趨勢與新動態的識別與可視化[J].陳悅,等譯.情報學報,2009,28(5):401-421.
(本文責任編輯:馬 卓)
Visualization Analysis of Evolution Path,
Research Hotspots and Frontiers of Big Data
He Xiaoping Huang Long
(Library,Nanchang University,Nanchang 330031,China)
This paper used the literatures which were retrieved from the Web of Science with the capital of Big Data as data sources,and conducted the cluster analysis and co-citation by means of the information visualization software CiteSpace Ⅲ.Based on the knowledge mapping generated by Citespace Ⅲ and the relevant literature,it performed statistical analysis and data interpretation from three perspectives,namely,research hotspots,subject content and developing trends.6 critical node documents perfectly showed the evolution path of big data;13 high frequency keywords and 5 burst terms indicated the research hotspots and research fronts.Conclusion:the research of big data had experienced a process which from the big data calculation model,the specific concept,the theory research of complexity science to the research on big data of social science level and applied practice level,three research hotspots:big data processing,data mining and data application,the research frontier and developing trend of big data:the study of big data itself,the research of processing technology,the research of data mining and system,model and network,data management and performance evaluation,this paper aimed at providing the reference for carrying out the present research of big data.
big data;CiteSpace Ⅲ;evolution pathway;research hotspots;research frontiers;visualization
2014-12-15
何曉萍(1955-),女,教授,研究方向:情報學、圖書館學、教育技術學。
10.3969/j.issn.1008-0821.2015.04.010
G252
A
1008-0821(2015)04-0046-06
猜你喜歡
世界科學技術-中醫藥現代化(2022年3期)2022-08-22 00:32:50
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
云南化工(2021年8期)2021-12-21 06:37:54
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
大眾投資指南(2021年35期)2021-02-16 01:06:26
海洋信息技術與應用(2020年1期)2020-06-11 12:43:56
科技傳播(2019年22期)2020-01-14 03:06:54
傳媒評論(2019年4期)2019-07-13 05:49:14
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
電力與能源(2017年6期)2017-05-14 06:19:37
