一種基于二叉樹的數學公式抄襲檢測算法
2015-04-14 12:28:34秦玉平唐亞偉倫淑嫻王秀坤
計算機工程與應用 2015年1期
秦玉平 ,唐亞偉 ,倫淑嫻 ,王秀坤
1.渤海大學 工學院,遼寧 錦州 121000
2.渤海大學 信息科學與技術學院,遼寧 錦州 121000
3.渤海大學 新能源學院,遼寧 錦州 121000
4.大連理工大學 計算機科學與技術學院,遼寧 大連 116024
1 引言
為保護知識產權,防止學術論文抄襲,論文查重檢測技術已成為信息檢索領域的一個研究熱點[1-2],并取得了一些研究成果。如數字指紋法[3-4]、詞頻統計法[5-6],篇章結構相似度法[7]、段落相似度法[8]、句子相似度法[9]和局部詞頻指紋法[10]等。但這些方法都針對純文本內容的檢測,對數學公式的抄襲檢測尚處于探索階段[11-13],現有的抄襲檢測系統都不能對數學公式進行檢測。但一篇學術論文,尤其是自然科學學術論文,其思想、觀點或創意等核心內容往往體現在公式中,因此,對數學公式的抄襲檢測的研究具有十分重要的意義。
LaTeX軟件已被廣泛地用于制作科技論文、書籍、檔案、學位論文、手稿、私人信件以及各種復雜的符號公式等。另外,其他格式的文檔可轉化為LaTeX格式[14]。為此,本文提出了一種基于二叉樹結構的LaTeX格式數學公式檢測算法,實現了對數學公式的抄襲檢測,并通過實驗結果驗證了算法的有效性。
2 數學公式的二叉樹表示
2.1 二叉樹構造
在LaTeX文檔中,根據標記提取用字符串形式表示的數學公式。由于LaTeX格式的數學公式具有較強的結構特征,因此,可將一個復雜的數學公式分解為多個子式,再將每個子式分解成多個更小的子式[15],如此反復,直到不能分解為止。分解后得到的最小子式稱為公式元素。
對于三目運算符,如求和運算“∑”,它與上、下、右都有聯系,通過增加一個“link”運算符,將其與右面的子式結合起來。
從左向右遍歷增加了“link”運算符后的字符串,生成公式元素的優先級列表。依據結構特征和優先級列表可生成數學公式的二叉樹表示。二叉樹中結點的數據結構如表1所示。
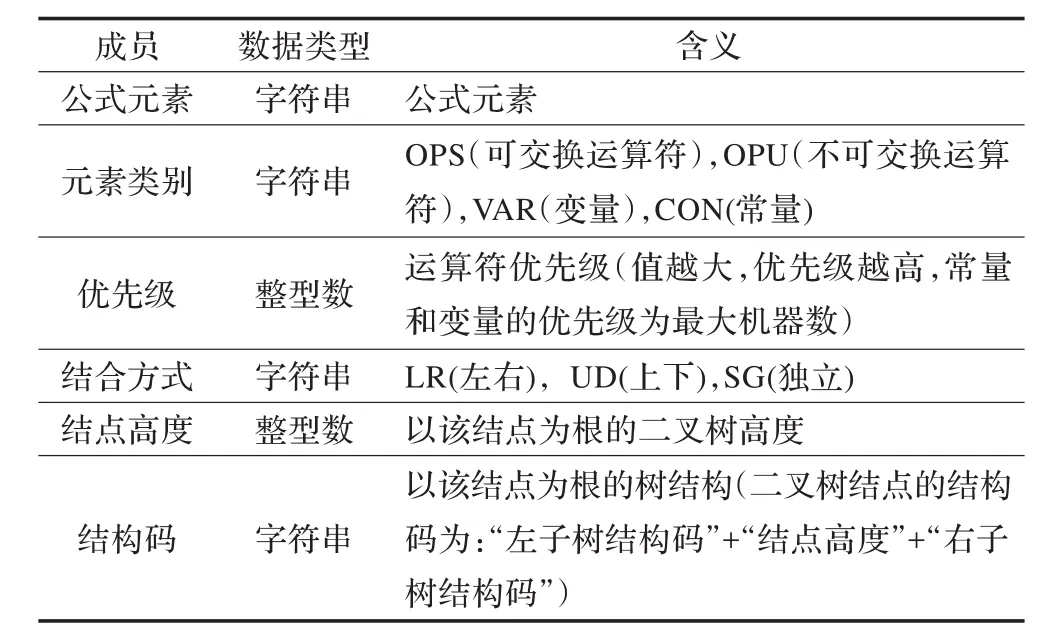
表1 二叉樹結點的數據結構
由數學公式的公式元素串表示生成其二叉樹表示的方法是先建立根結點,根結點的公式元素是公式元素串中優先級最低的公式元素,由于公式元素串中位于根結點公式元素之前的公式元素在根結點的左子樹,位于根結點公式元素之后的公式元素在根結點的右子樹,遞歸建立根結點的左右子樹。
每個結點的公式元素類別和結合方式根據公式元素確定。每個結點的高度根據公式(1)計算。每個結點的結構碼在對樹形結構作歸一化處理后生成。
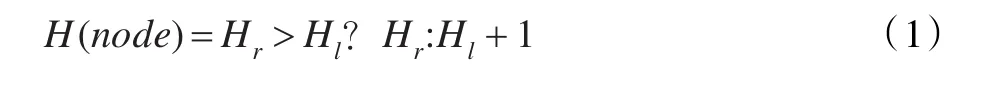
其中,H(node)是結點node的高度,Hl是結點node左子樹的高度,Hr是結點node右子樹的高度。
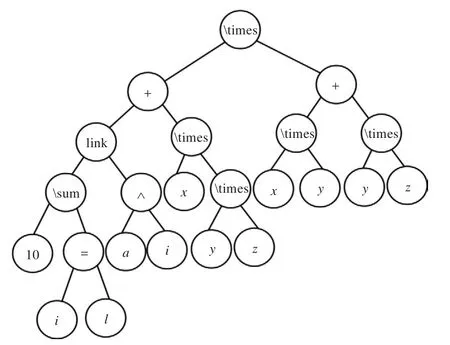
圖1 數學公式的二叉樹表示
2.2 歸一化處理
由于一些運算符的操作數具有可交換屬性,即交換前后數學公式的含義不變,但它們對應的二叉樹樹形結構可能不同,因此,必須對二叉樹樹形結構作歸一化處理。樹形結構歸一化處理的方法是先序遍歷二叉樹,若當前結點公式元素類別為OPS且其左子樹的高度大于右子樹的高度,則交換其左右子樹。例如,對圖1作歸一化處理后的二叉樹如圖2所示。
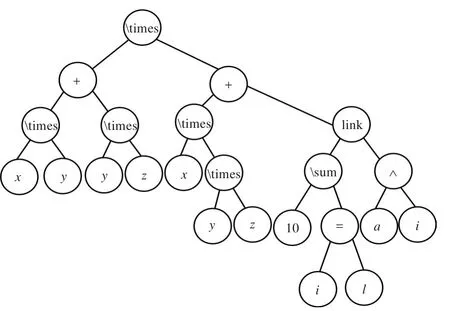
圖2 樹形結構歸一化后的二叉樹
對樹形結構作歸一化后處理后,后序遍歷二叉樹,根據式(2)生成各結點的結構碼,最終得到根結點的結構碼,即二叉樹的結構碼。

其中,C(node)是結點node的結構碼,Cl是結點node左子樹根結點的結構碼,Cr是結點node右子樹根結點的結構碼。
另外,數學公式中的變量名與公式含義無關。對于一個樹形結構確定的二叉樹,為使按給定的遍歷方式遍歷后得到的公式元素序列唯一,必須對序列中的變量名作歸一化處理。對變量名作歸一化處理的方法是按從左到右的順序,用固定的變量名序列依次替換遍歷序列中公式元素類別為VAR的公式元素。
3 公式檢測數據庫設計
公式檢測數據庫包含論文信息表和數學公式信息表兩種表。論文信息表的結構見表2,數學公式信息表結構見表3。數學公式信息表以結構碼命名,即結構碼相同的數學公式信息存儲在同一個表中。

表2 論文信息表結構

表3 數學公式信息表結構
4 數學公式檢測算法
步驟1對于待檢測文檔,提取所有數學公式,得到數學公式集Formula={f1,f2,…,fn}。
步驟2若數學公式集Formula非空,則從Formula中取出一個數學公式fi,生成fi的二叉樹表示并對二叉樹結構作歸一化處理,得到fi的二叉樹表示Ti及其結構碼fcode,轉步驟3;否則,轉步驟7。
步驟3查找文件名為fcode的數據表,若該文件存在,轉步驟4;否則,轉步驟2。
步驟4在數據表fcode中,查找與二叉樹Ti根結點的公式元素相等的記錄,若存在,轉步驟5;否則,轉步驟2。
步驟5對二叉樹Ti中的公式元素類別為OPS且左、右子樹高度相同的結點(設有k個),交換這類結點的左右子樹,得到2k-1棵樹形結構與Ti相同的二叉樹,分別先序遍歷這2k棵二叉樹,得到相應二叉樹的公式元素遍歷序列,對序列中的變量名作歸一化處理,公式元素序列相同的只保留一個,得到公式元素序列集L={L1,L2,…,Lm},轉步驟6。
步驟6在數據表fcode中,查找與L中的公式元素序列相同的記錄,若存在,輸出數學公式fi所在的論文名和發表信息,轉步驟2。
步驟7檢測結束。
5 實驗結果及分析
為了驗證算法的性能,從258篇公開發表的學術論文中選取1 000個含義和結構互不相同的數學公式,預處理后存入公式檢測數據庫。
實驗環境為CPU Pentium 2.0 GHz,內存2 GB,操作系統Windows XP SP3,數據庫ACCESS 2007。
實驗中采用準確率P、召回率R和F1值作為評價標準。

其中,A是檢測結果中語義相同且實際相同的表達式數,B是檢測結果中未出現但實際語義相同的表達式數,C是檢測結果中語義相同但實際不相同的表達式數。
數學公式抄襲的手段主要有原樣復制,修改變量名稱和交換可交換運算符兩邊子式的位置等。根據抄襲手段的不同,對公式檢測數據庫中的公式人工修改后進行檢測,具體的修改方式如表4所示。

表4 修改方式的種類
實驗中,根據數學公式抄襲的手段,對選取的258篇論文中的數學公式按表4中的修改方式作相應的修改后,分別對這些論文進行檢測。共進行2 000次數學公式檢測,檢測的準確率和召回率都為100%,檢測檢測時間為421 ms。
從實驗結果可以看出,該算法對公式未作修改,修改其變量名稱及交換其可交換運算符兩邊子表達式的情況都實現了精準檢測。其原因是對源公式和目標公式的樹形結構作歸一化處理后,源公式和目標公式的樹形結構相同,雖然與源公式樹形結構形同的目標公式二叉樹可能有多種,但在對所有的先序遍歷序列的變量名稱作歸一化處理后,目標公式的遍歷序列中至少存在一個與源公式遍歷序列完全相同的遍歷序列,使修改后的目標公式恢復原形。該算法檢測速度比較快。數學公式的檢測過程包括數學公式提取、轉換和查找。由于LaTeX格式文檔中的數學公式有開始和結束標記,所以根據標記能快速識別并提取數學公式。由LaTeX格式表示的數學公式轉換成其對應二叉樹表示時,其主要操作是遍歷公式元素串。遍歷串長為n的公式元素串的時間復雜度為nlbn。由于公式元素串的串長較小且操作簡單,所以用時較少。查找時,先檢查與結構碼同名的數據表是否存在,若不存在,檢測結束,否則,先在數據表中查找與根結點公式元素相等的記錄,若有滿足條件的記錄,再在滿足條件的記錄中查找與變量名歸一化后的先序遍歷公式元素序列相等的記錄。
6 結束語
基于數學公式的二叉樹表示,提出了一種LaTeX格式的數學公式檢測算法。本文方法對未作修改的公式檢測,對修改變量名稱的公式檢測和對交換可交換運算符兩邊子表達式的公式的檢測都十分精確,且具有較高的檢測速度,有效地解決了論文抄襲檢測中數學公式檢測問題,彌補了現有的檢測系統中不能對數學公式進行檢測的缺陷。
[1]史彥軍,滕弘飛,金博,等.抄襲論文識別研究與進展[J].大連理工大學學報,2005,45(1):50-57.
[2]Song Q B,Shen J Y.On illegal Coping and Distrib uting Detection Mechanism for Digital Goods[J].Journal of Computer Research and Development,2001,38(1):121-125.
[3]Hoad T,Zobel J.Methods for identifying versioned and plagiarism documents[J].Journal of the American Society for Information Science and Technology,2002,54(3):203-215.
[4]Chowdhury A,Frieder O.Collection Statistics for Fast Duplicate Document Detection[J].ACM Transactions on Information System,2002,20(2):171-191.
[5]Zobel J,Moffat A.Exploring the similarity space[J].ACM SIGIR Forum,1998,32(1):18-34.
[6]Antonio S,Leong H V.A document plagiarism detection system[C]//Proceedingsofthe1997 ACM Symposium for Applied Computing.San Jose:ACM Press,1997:70-77.
[7]金博,史彥軍.基于篇章結構相似度的復制檢測算法[J].大連理工大學學報,2007,47(1):125-130.
[8]趙俊杰,胡學鋼.一種基于段落詞頻統計的論文抄襲判定算法[J],計算機技術與發展,2009,19(4):231-233.
[9]秦新國.基于句子相似度的文檔復制檢測算法研究[J].現代圖書情報技術,2007(11):63-66.
[10]秦玉平,冷強奎,王秀坤,等.基于局部詞頻指紋的論文抄襲檢測算法[J].計算機工程,2011,37(6):193-194.
[11]Lee H,Wang J.Design of a mathematical expression recognition system[J].Pattern Recogniton Letters,1997,18(8):289-298.
[12]陳國俊,唐勇智.基于基準線的多候選數學公式識別[J].計算機工程與應用,2013,49(1):206-209.
[13]陳康,許婷.基于Web的全文搜索引擎的設計與實現[J].計算機工程,2005,31(10):51-53.
[14]靳簡明,江紅英,王慶人.數學公式識別系統:MatheReader[J].計算機學報,2006,29(11):2018-2026.
[15]郭育生,黃磊,劉昌平.基于多候選的數學公式識別系統[J].計算機研究與發展,2007,44(7):1144-1150.
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
哲學評論(2021年2期)2021-08-22 01:53:34
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中華詩詞(2019年7期)2019-11-25 01:43:04
模具制造(2019年3期)2019-06-06 02:10:54
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
海峽科技與產業(2016年3期)2016-05-17 04:32:12
