基于特征序列的語義分類體系的自動構建
2015-04-21 08:33:27陳剛,劉揚
中文信息學報 2015年3期
陳 剛,劉 揚
(1. 北京大學 計算語言學研究所,北京 100871;2. 北京大學 計算語言學教育部重點實驗室,北京 100871)
?
基于特征序列的語義分類體系的自動構建
陳 剛1,2,劉 揚1,2
(1. 北京大學 計算語言學研究所,北京 100871;2. 北京大學 計算語言學教育部重點實驗室,北京 100871)
詞義知識表示主要依賴屬性描述或分類描述,這兩種方式各有所長,但不同表示之間相互轉換的可行性與現實狀況還未被關注。在屬性描述的基礎上,該文引入序關系的思想,提出基于特征序列的概念與方法,以此來模擬、分析概念涵義從一般到特殊的漸次生成過程,發掘尚未顯性化的中間概念,自動構建出一個語義分類體系。以HowNet(2000版)數據為例,實驗表明該方法可以生成一個性質優良、覆蓋完全的新的語義分類體系,并反映此前的屬性描述在語言知識工程實踐中不易察覺的一些問題。
詞義知識;屬性描述;分類描述;序關系;特征序列;語義分類體系
1 引言
本體(Ontology)是一種形式化的、可共享的概念模型,它能夠在知識層面上為一般或特定領域的概念及其關系提供明確的描述,實現對相關領域知識的共同理解和共享復用[1-2]。詞義知識庫作為一種特定本體,關注的是語言系統內部的詞匯語義以及它們之間的相互關系,其知識表示方式主要有兩種: 屬性描述和分類描述。
詞義知識的屬性描述一般采取構造方式,借助義素分析等方法預先定義出一組基本語義單位,然后按照一定的描寫規則將這些基本語義單位組合起來,形成針對特定詞義的相互獨立的概念描寫,使用這種方法的典型系統是HowNet[3]等;而分類描述則不同,它并不注重單一的概念描寫,而是意在對全體概念進行系統性的區分,以上下位關系為主干結構將概念組織成一個語義分類體系,在此基礎上再添加其他類型的語義關系,進一步構成一個復雜的語義網絡,使用這種方法的典型系統是WordNet[4]。屬性描述和分類描述在方法、手段上各有所長,前者強于對概念自身的精細描寫、在詞義計算中便于實現多樣的特征選取,后者強于對系統結構的整體把握、在詞義計算中便于在不同粒度上的意義歸約。我們認為,在一定程度上實現兩種描述方式的計算性轉換,可以結合兩方面的優勢,在語言知識工程上做迭代性的評估和構建,這也是在實際的語言知識工程中需要特別關注的一個方面。
此前,Wong等[5]曾對HowNet和WordNet進行了系統性的分析和比較,認為它們使用兩種截然不同的知識表示方法,表達了十分相似的概念與關系,但是并未進一步研究這兩種表示方式相互轉換的可能性。盧鵬等[6]嘗試將HowNet中六萬多詞的屬性描述分配到高層義原分類樹的1 500多個節點上去,并對同一節點內的詞聚類,期望得出一個語義分類體系。后者已經注意到了兩種描述方式之間轉換的可能性,但是,他們選取的聚類的技術路線依賴語料,算法復雜度高而精度也難以保障,最終得到的義原分類樹下的次級結構不甚清晰、可靠性也不高,具體表現在不同概念之間的“弱”分類依據上以及同一概念內的不同詞之間的“弱”同義依據上。此外,使用各種資源自動或半自動地構建本體也是語言知識工程近年來的一個研究熱點,Chen等[7]、Liu等[8]的實驗表明了此類做法的有效性。
基于以上觀點,本文希望在屬性描述的基礎上,依據更合理的語言學假設,自動地構建出一個性質優良、覆蓋完全的語義分類體系,實現從屬性描述到分類描述的計算性轉換,并評估現有工作在語言知識工程上的狀況,以促進高質量的、實用化的詞義知識庫的演化、生成。
2 基于特征序列的語義分類體系的自動構建方法
2.1 廣義特征、特征集合、特征序列的約定
一般而言,詞義知識的屬性描述不僅涉及當前概念的多種語義屬性,也描述它與其他概念之間的多種語義關系。例如,HowNet對“醫生”概念的描述為: “DEF=human|人,#occupation|職位,*cure|醫治,medical|醫”。其中,“醫生”不僅具有“human|人”、“medical|醫”這兩種屬性,還具有與“occupation|職位”之間的“相關”關系(以“#”來標識)以及與“cure|醫治”之間的“施事-動作”關系(以“*”來標識)這兩種關系。
不難發現,屬性的描述針對當前概念、相對單純,而關系與程序中的指針類似,以它為媒介,從當前概念指向了另外的概念,這也是其不便處理的地方。基于方便結構計算的特殊考慮,我們不妨把屬性和屬性值封裝起來,同時把關系標識和它所指向的目標概念也封裝起來,先不做形式上的二元區分,則關系在整體上也相當于普通的描述項,即“醫生”概念有“human|人”、“#occupation|職位”、“*cure|醫治”、“medical|醫”這樣的字符串值分別作其概念涵義。在此約定下,我們可以把屬性、關系統一視為用來定義當前概念的廣義特征,以下均簡稱特征。換句話說,用來描述一個概念涵義的信息就是若干項特征,無須再區分屬性、關系這樣的子類了。
從語言學、尤其是詞匯語義學的角度看,一個概念涵義的界定由多項特征來描述,它們構成了一個無序的特征集合W={F1, F2, …, Fn},其中的每個元素分別描述了詞W的詞義的不同方面。
為凸顯詞義的不同方面的重要程度,我們在此集合上追加關于多項特征之間的序關系的認定,則特征集合W={F1, F2, …, Fn}在給定序關系下的排列W′= < Fs1, Fs2, …, Fsn>即為特征序列,其中si∈[1, n], 對于任何i≠j,滿足si≠sj。在給定的序關系下,從Fs1,Fs2,…,到Fsn,它們對整體的概念涵義的約束從左到右依次減弱。如此一來,特征在特征序列中的位序尤其重要,它決定該特征對于整體的概念涵義貢獻的大小。易見,理論上詞W的一組特征可以構成n!種排列。
序關系的引入,擴展了屬性描述的表達能力。例如,“中南海”一詞的概念涵義可能采取的特征包括 “人群”、“地點”、“機構”等多個方面,在不同的語境下要做不同的設定、選擇。在知識庫中若采用多繼承方式或單一屬性的多取值方式,往往會破壞數據的層次性、帶來結構的復雜化,甚至造成語義理解上的沖突。而序關系的限定和要求自然回避了特征之間非此即彼的硬性選擇,轉為表征它們之間重要性的位序的認定和記錄,且無任何語義上的損失。對于上面的例子,如果語料實例關注的是人,那么就可以將“人群”這個特征提前,然后才考慮“機構”和“地點”的排列;同理,如果關注地點、機構,那么只要將“地點”、“機構”特征提前即可,而其它特征后移。
2.2 中間概念生成與語義分類層次的擴展
依據上述理解,同一特征序列的不同長度的子序列,或稱序列前綴,也因此負載了特殊的意義。一個特征序列的序列前綴可以按照其長度的增長逐步展開,形成不同的分類層次、構成不同的中間概念,并自然地模擬了概念涵義從一般到特殊的漸次生成過程。在此解釋下,我們將全體概念的所有中間概念按分類層次收集起來,就能獲得一個相對完整的語義分類體系。
實際上,序列前綴表達的概念與該特征序列表達的概念之間形成了一種寬泛的分類關系。從左往右觀察特征序列,也可以看到概念涵義的生成過程: 每施加一項新的特征,概念就被約束到一個更小的內涵上去,模擬、分析了現實分類中的父類、子類關系。這種約束不限于狹義的kind-of或is-a關系,是一種更為“廣義”的上下位關系,也為一般的語義分類實踐提供了新的契機。
舉例來說,假設在給定的序關系下,有且僅有如下五個詞的特征序列構成的一個概念空間。
W(1)=
W(2)=
W(3)=
W(4)=
W(5)=
易見W(2)和W(5)具有相同的特征序列,這是語言中的“一義多詞”現象(注意,“一詞多義”現象在知識庫構建中并無特殊性,僅涉及詞形問題,為描述簡潔起見沒有列入)。我們把具有相同特征序列的詞結合形成同義詞集,表示同一個概念,從而避免詞形帶來的對概念表示的干擾。然后,對于每個特征序列,提取其所有的序列前綴作為新的特征序列持續加入。將所產生的特征序列去重并按字典序排列,可得如下新的概念空間。
{ }=
{ }=
{W(1)}=
{W(2),W(5)}=
{W(4)}=
{W(3)}=
其中,
另外,Kahrl和 Roland-Host對中國整體的水—能關系進行了研究。他們根據中國國家統計局和水利部公布的用電和用水數據以及中國的投入產出表,計算出了我國非農業用水對應的單位能耗。該方法與前文所述的采用逐步分析方法的研究不同,是應用投入產出模型,計算水資源產品和供給的能耗。該研究指出目前中國非農業供水的能耗占中國總能耗的比例較小,但是,隨著中國水處理能力的提高和水利設施的增加(如南水北調等),該比例會不斷增大。
將這些特征序列按順序翻轉90度,縱向觀察,所有的特征序列在字典序下對應著一個樹結構的先序遍歷結果,而序列前綴恰好對應著樹結構中的概念節點,因此自動導出一個如圖1所示的小型的語義分類體系。
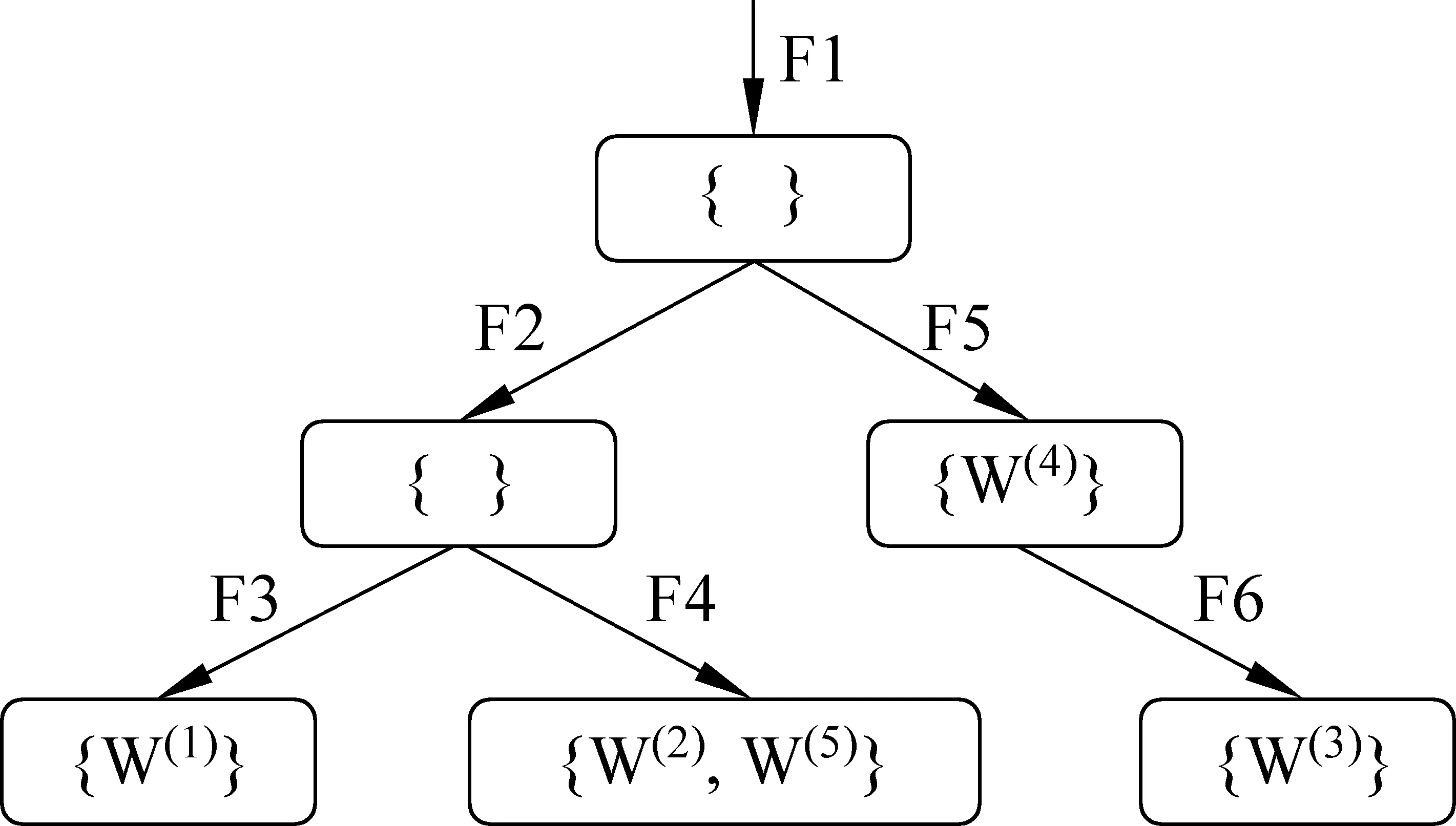
圖1 序列前綴擴展生成的樹結構
2.3 自動構建算法偽碼描述
上述方法的算法實現并不困難,我們僅以偽碼描述表示如下。易證,該算法的時間復雜度為O(M·N),其中,M為知識庫中的詞條數目,N為特征序列的平均長度。
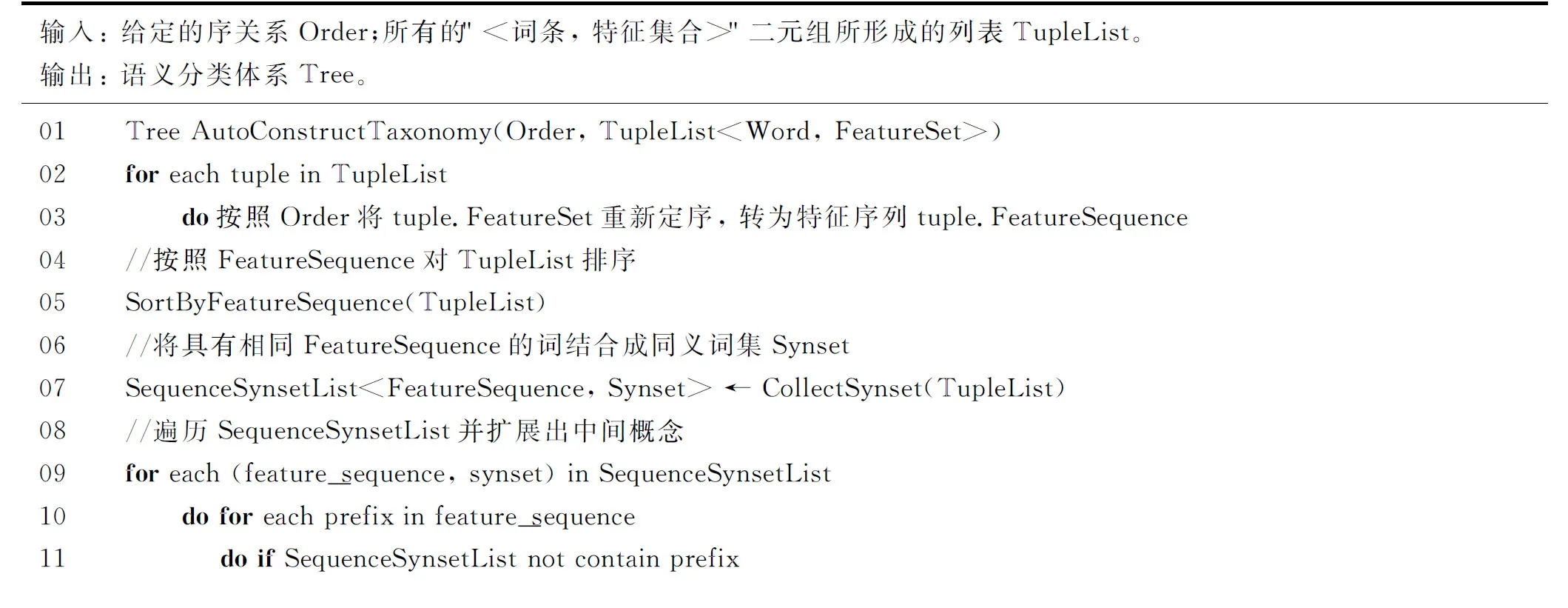
輸入:給定的序關系Order;所有的"<詞條,特征集合>"二元組所形成的列表TupleList。輸出:語義分類體系Tree。01 TreeAutoConstructTaxonomy(Order,TupleList

3 自動構建實驗與數據分析
3.1 實驗數據描述
HowNet(2000版)是采用屬性描述的一個典型的詞義知識庫,下面以其為例驗證本文方法的有效性。首先,HowNet定義了語義基本單位——義原,并依上下位關系把它們組織在幾個小型的樹結構中,包括“實體”、“事件”、“屬性”、“屬性值”、“動態角色與特征”等類。此外,HowNet進一步定義了上下位關系、整體-部分關系、施事-工具關系、受事-事件關系、相關關系等數十種關系。之后,通過義原和關系的組合來描述概念涵義,一些示例如表1所示。
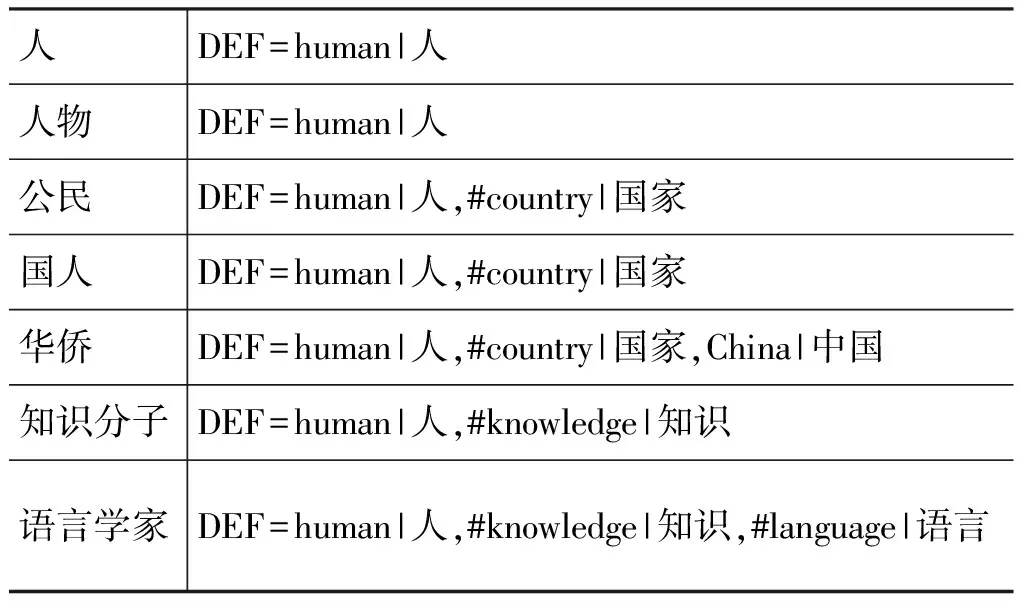
表1 HowNet基于屬性描述的釋義舉例
其中,“human|人”、“country|國家”、“China|中國”、“knowledge|知識”和“language|語言”是義原,“#”是“相關”關系標識。我們用特征定義來簡化概念表示。例如,在“公民: DEF=human|人,#country|國家”中,認定“公民”一詞具有兩項特征: “human|人”、“#country|國家”。HowNet已規定DEF項的第一項為概念的主要特征,其余為次要特征,我們也發現DEF定義項從左到右自然地反映了從主到次的序關系,因此,我們直接將這種序關系作為算法的輸入,不做任何調整。
3.2 分類體系的自動擴展及優化方案
使用本文方法,對上述用例自動擴展生成的一個語義分類如圖2右半部分示意。由于HowNet中的義原已經組織在如圖2左半部分示意的小型樹中,且同樣可轉寫為特征序列,這啟發我們在自動擴展的基礎上,依據DEF項對應的主要特征的取值,可將此前生成的語義分類直接“拼接”在義原樹上——或者,從另一個視角說,是將義原的特征序列直接追加在DEF項的主要特征上并重新做全局的自動擴展。這樣,利用已有結構,就把全部概念有機地結合在一個分類體系中了。考慮HowNet描述特性的優化方案生成的完整樹結構則如圖2所示。

圖2 HowNet分類體系的自動擴展及其優化方案示意
HowNet原始文件中不重復的DEF項(即概念定義)的總次數為17 216,在這些DEF項中義原出現的總次數為66 478,DEF項的平均長度為3.86。優化方案除覆蓋了原始的17 216個概念外,同時新生成了6 384個此前未加定義的中間概念,它們暫時還沒有詞的實例來承載。這些尚未顯性化的中間概念的數量占原有概念數量的37.08%,而全體概念數量增長到23 600個,其中的義原出現的總次數增長到182 686,DEF項的平均長度約7.74。從概念涵義的有意義擴展以及新的中間概念自動生成的角度看,這對語言知識庫建設是一個積極的現象。
在詞義知識表示上,屬性描述的詳細程度、均勻與否等關乎基于特征選取的詞義計算的穩定性。對比原始DEF項(含17 216個概念)的長度分布以及在優化方案下擴展出的特征序列(含23 600個概念)的長度分布,如圖3所示,其長度分布的右向漂移十分明顯。與盧鵬等工作相比,優化方案下構建的語義分類體系將義原的特征序列直接追加在DEF項的主要特征上, 增加了特征序列的長度,也增強了概念之間的區分性,而且,概念的特征序列長度的分布更均勻,這也有助于確保詞義計算的質量。此外,本文方法采用簡單、可靠的語言學假設,充分挖掘HowNet包括義原分類信息、DEF項定義信息在內的全部屬性描述信息,也避免了使用外部語料可能帶來的不確定性,同時,算法復雜度顯著降低,能很快完成分類體系的計算并輸出全局數據。

圖3 原始DEF項長度分布與優化方案下的特征序列長度分布的對比
基于特征序列的概念、方法并采取優化方案,我們在HowNet的全集規模(覆蓋全部原始概念,分類節點數在兩萬以上)上首次給出了一個分布均衡的語義分類體系,并保證同一概念節點內的詞享有完全相同的DEF項定義。表2列舉了自動構建的一些代表示例,它們本身即構成一棵子樹。其中,“@”、“#”分別標識“場所-事件”、“相關”關系,而null表示生成了新的有意義的中間概念,但在原知識庫中暫時還沒有詞的實例來承載,參考圖1,它們的語言學解釋不難理解。

表2 自動構建的一些代表示例
在自動構建的語義分類體系下,我們可以從整體結構上把握原始數據,反映此前的屬性描述在語言知識工程實踐中不易察覺的一些問題,表明了語言學假設和概念、方法的有效性。首先,本文提出的方法便于核查同一概念節點內不同詞的同義性狀況。例如,表2第一行為“亭子|碑亭|垛|構筑物|明溝|窨井”,雖然它們的特征序列(注意同時也是原始DEF項信息)相同,但是真實的詞義參差不齊,將這些詞分開做精細化描述可能是更好的選擇;其次,本文方法能進一步判斷概念涵義繼承鏈條的潛在缺失。對于那些新產生的中間概念,順應其作為“概念化”的自然成果,思考其概念涵義“詞匯化”的可能性,可以系統化地擴張知識庫中的詞量。例如,對于表2第二行,依據新產生的特征序列“facilities|設施,@exercise|鍛練”的概念涵義的指示,還可以添加“訓練場”、“健身中心”等詞;最后,本文方法也有助于發掘概念涵義繼承鏈條的潛在錯誤。依據現有的屬性描述,“DEF=facilities|設施,@exercise|鍛練,#ice|冰,sport|體育”的概念涵義明顯比“DEF=facilities|設施”更限定、更具體,則“冰場”在新分類體系下應認定為“亭子|碑亭|垛|構筑物|明溝|窨井”的子孫概念,而目前的這種狀況顯然是不合理的,需要修改部分詞的屬性描述的原始定義(即原始DEF項信息),這種情況在知識庫中也有較多出現。
總之,在詞義知識的屬性描述下,針對單個詞的屬性描述難以對不同的詞進行系統化的橫向、縱向比較,在語義分類體系下則可把相關問題清晰呈現出來。反過來,單純的分類描述缺乏對多種特征的有效認識和把握,在工程實踐中也會衍生出許多問題。兩種方式的結合有助于發揮綜合優勢,在語言知識工程上做迭代,以生成高質量的、實用化的詞義知識庫。
4 結語
在知識庫的構建中,詞義知識表示主要依賴屬性描述或分類描述,這兩種方式各有所長,但不同表示之間相互轉換的可行性與現實狀況還未被關注。
在屬性描述的基礎上,本文引入了序關系的思想,提出了特征序列的概念以及基于該概念的分類層次展開方法。該方法能夠模擬、分析概念涵義從一般到特殊的漸次生成過程,并發掘、記錄那些尚未顯性化的中間概念,自動地構建出一個語義分類體系,實現從屬性描述到分類描述的計算性轉換。以HowNet數據為例,實驗表明本方法可以生成一個性質優良、覆蓋完全的新的語義分類體系,并反映此前的屬性描述在語言知識工程實踐中不易察覺的一些問題。
值得注意的是,不同特征之間的序關系的認定至關重要。為方便起見,本文直接采用了原始DEF項的定義順序,以此生成了一個單一分類體系。進一步,序關系的變更和認定也可以不僅限于特征之間,而是先將全部特征按照某種相關性分組(例如,確定分別屬于領域、格框、情感、語域等不同方面的特征),然后依據“組間”順序和“組內”順序來形成有側重的、不同的序關系。這樣的研究有利于多分類體系的自動構建和調整,形成不同應用需求下的可定制知識庫系統。
此外,特征序列的概念、方法也具有通用性,在從分類描述向屬性描述的轉換中同樣適用。其做法為: 對于語義分類體系中的每個概念節點,持續界定、收集從根節點到該概念節點的路徑上的每一處分類的區分性憑證(即區分特征),若知識庫中存在多繼承現象和多種其它關系,則需要在序關系上做一些特殊的認定和處理。鑒于篇幅所限,這部分內容不再贅述。
目前,我們正將基于特征序列的概念、方法應用于北大“中文概念詞典”的迭代評價和結構重構等方面,希望在語言知識工程上不斷演化,生成出高質量的、實用化的詞義知識庫。
[1] T Gruber. Toward Principles for the Design of Ontologies Used for Knowledge Sharing[J]. International Journal of Human-Computer Studies, 1995, 43 (5-6): 907-928.
[2] 鄧志鴻, 唐世渭, 張銘,等. Ontology研究綜述[J]. 北京大學學報(自然科學報), 2002, 38(9): 728-730.
[3] 董振東. 知網(2000版)[DB/OL], http://www.keenage.com.
[4] G A Miller, B Richard, F Christiane, et al. Introduction to WordNet: An On-line Lexical Database[R]. Five Papers on WordNet, CSL Report 43, Cognitive Science Laboratory, Princeton University, 1993.
[5] P W Wong, P Fung. Nouns in Wordnet and HowNet: An Analysis and Comparison of Semantic Relations[C]//Proceedings of GWC′02, India, 2002: 319-322.
[6] 盧鵬, 孫明勇, 陸汝占. 基于知網的詞匯語義自動分類系統[J]. 計算機仿真, 2004, 21(2): 127-133.
[7] H P Chen, L He, B Chen. Research and Implementation of Ontology Automatic Construction Based on Relational Database[C]//Proceedings of International Conference on Computer Science and Software Engineering-CSSE, 2008: 1078-1081.
[8] N Liu, G Y Li, Y F Zhang. Research on Domain Ontology Semi-automatic Construction Model towards Chinese Text[C]//Proceedings of International Convention on Information and Communication Technology, Electronics and Microelectronics-MIPRO, 2010.
Automatic Construction of Semantic Taxonomy Based on Feature Sequences
CHEN Gang1,2, LIU Yang1,2
(1. Institute of Computational Linguistics, Peking University, Beijing 100871, China; 2. Key Laboratory of Computational Linguistics (Ministry of Education), Peking University, Beijing 100871, China)
Feature description and taxonomic description are two basic knowledge representations widely employed in lexical semantics. However, the the transformation between them remains an open issue with well discussion. In this paper, we applies the notion of ordering relationship into the feature description, and automatically derive a taxonomy from general to specific concepts, in which the previous undefined intermediate concepts are revealed. Experiments on HowNet (2000) show that a semantic taxonomy, with a fine-defined inheritance and a full coverage of all concepts, can be automatically generated by this approach. Further analysis of the output also indicates some underlined defects in the feature description for natural language knowledge engineering.
lexical semantics;feature description;taxonomic description;ordering relation;feature sequences;semantic taxonomy

陳剛(1988—),碩士研究生,主要研究領域為自然語言處理、語言知識工程。E?mail:gangchen@pku.edu.cn劉揚(1971-),男,副教授,主要研究領域為自然語言處理、語言知識工程。E?mail:liuyang@pku.edu.cn
1003-0077(2015)03-0052-06
2013-04-08 定稿日期: 2013-07-25
國家重點基礎研究發展計劃資助項目(2014CB340504);國家社科基金重大項目(12&ZD119)。
TP391
A
猜你喜歡
現代裝飾(2022年1期)2022-04-19 13:47:32
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
開放教育研究(2020年2期)2020-03-31 01:54:14
現代裝飾(2020年2期)2020-03-03 13:37:44
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·高一版(2018年9期)2018-10-09 06:46:48
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
中學生數理化·高一版(2017年9期)2017-12-19 12:15:14
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
現代語文(2016年21期)2016-05-25 13:13:44
