一個面向信息抽取的中文跨文本指代語料庫
2015-04-25 09:57:27趙知緯錢龍華周國棟
中文信息學報 2015年1期
趙知緯,錢龍華,周國棟
(1.蘇州大學 自然語言處理實驗室,江蘇 蘇州 215006)(2.蘇州大學 計算機科學與技術學院,江蘇 蘇州 215006)
?
一個面向信息抽取的中文跨文本指代語料庫
趙知緯,錢龍華,周國棟
(1.蘇州大學 自然語言處理實驗室,江蘇 蘇州 215006)(2.蘇州大學 計算機科學與技術學院,江蘇 蘇州 215006)
跨文本指代(Cross Document Coreference, CDC)消解是信息集成和信息融合的重要環節,相應地,CDC語料庫是進行跨文本指代消解研究和評估所不可或缺的平臺。由于目前還沒有一個公開發布的面向信息抽取的中文CDC語料庫,因此該文在ACE 2005語料庫的基礎上,采用自動生成和人工標注相結合的方法,構建了一個面向信息抽取的涵蓋所有ACE實體類型的中文CDC語料庫,并將該語料庫公開發布,旨在促進中文跨文本指代消解研究的發展。同時,該文以該語料庫為基礎,分析了中文環境下跨文本指代現象的類型和特點,提出了用“多名困惑度”和“重名困惑度”兩個指標來衡量跨文本指代消解任務的難度,為今后的跨文本指代消解研究提供一些啟示。
跨文本指代;信息抽取;語料庫標注;困惑度
1 引言
指代是一種常見的語言現象,即在文章中多個指代詞指向同一個實體。指代消解的任務就是把所有指向相同實體的詞組合在一起形成一個指代鏈[1]。指代消解可以分為文本內的指代消解和跨文本的指代消解。以往大量的研究工作都集中于文本內的指代消解[2],取得了一定的成就。隨著信息抽取技術向信息融合和知識工程等方向發展,跨文本指代消解也獲得了廣泛的重視[3]。所謂跨文本指代消解是指將不同文章內指向同一實體的所有指代詞歸入同一個指代鏈。MUC-6[4]就提出把跨文本指代(Cross Document Co-reference,CDC)消解作為一個潛在的任務,之后在ACE2008[5]中引入的全局實體檢測和識別(Global Entity Detection and Recognition,GEDR)任務就包含了跨文本指代消解任務。跨文本指代消解不僅是信息抽取和信息融合中的關鍵任務,對信息檢索、文本摘要等其他應用也有重要作用。
跨文本指代通常包含兩種情況,“多名”現象和“重名”現象。前者指的是同一實體在不同文本中有不同的指代詞,例如,“藍色巨人”和“國際商業機器”均指代IBM公司;而后者則是指不同文檔中的相同指代詞指向不同的實體,例如,“比爾”可能指代“比爾·克林頓”,也有可能指代“比爾·蓋茨”。因此,跨文本指代消解系統既需要將指代一個實體的多個名稱歸入到同一個指代鏈中,稱為“多名聚合”,也需要將相同名稱的不同實體歸入到各自的指代鏈,稱為“重名消歧”。
無論是采用有監督的學習方法,還是采用無監督的方法,跨文本指代消解都需要一個標準的語料庫進行學習或評估。為此,近十年來,研究人員收集和標注了大量的跨文本指代語料庫,并在這些語料庫上利用各種方法進行跨文本指代消解的研究[3,5-8]。由于人工標注大規模的CDC語料庫是一個費時費力的工作,因而大部分的語料庫都是面向信息檢索、用于人名“重名”消歧的英文CDC語料庫[6-7,9-10]。而NIST組織的ACE2008任務GEDR則包含了面向信息抽取的、同時用于多名聚合和重名消歧的英文和阿拉伯文的CDC語料庫。同樣,JHU在ACE2005英文語料的基礎上標注了一個小規模的實驗性英文CDC語料庫。到目前為止,還沒有面向信息抽取的中文CDC語料庫。
本文的研究工作就是要彌補這一方面的缺陷,其出發點是利用ACE2005的中文語料庫,構建一個面向信息抽取、包含多名聚合和重名消歧兩個子任務以及具有多種實體類型的實驗性中文CDC語料庫,稱為ACE2005中文CDC語料庫,并且將該語料庫在蘇州大學自然語言處理實驗室網站上公開發布*http://nlp.suda.edu.cn/~qianlonghua/ACE2005-CDC.zip,以使同行可以使用該語料庫進行中文跨文本指代消解的研究工作。盡管受ACE2005中文語料的限制,語料庫規模較小,我們希望,本文的初步研究工作可以為面向信息抽取的跨文本指代消解提供一個開放的基準語料庫,從而促進中文跨文本指代消解研究的發展。
2 相關工作
為了更清楚地比較目前的跨文本指代消解研究中所用到的語料庫,我們按語料庫的不同口徑,例如,語料庫規模、語料來源、所用語言、實體類型、消解任務、面向應用、標注粒度和標注方式等,對其進行分類和比較,結果如表1所示。
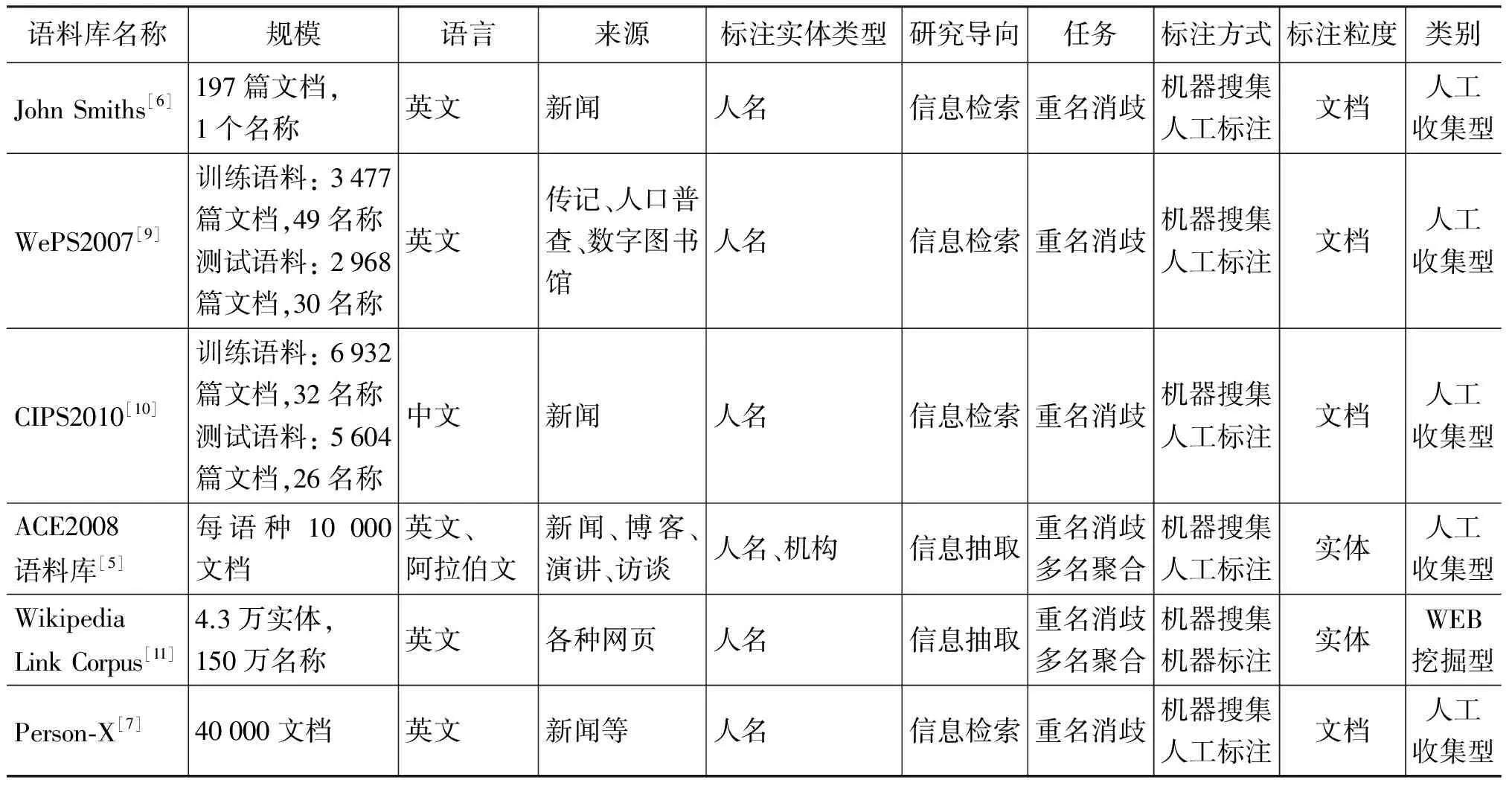
表1 各CDC語料庫的比較
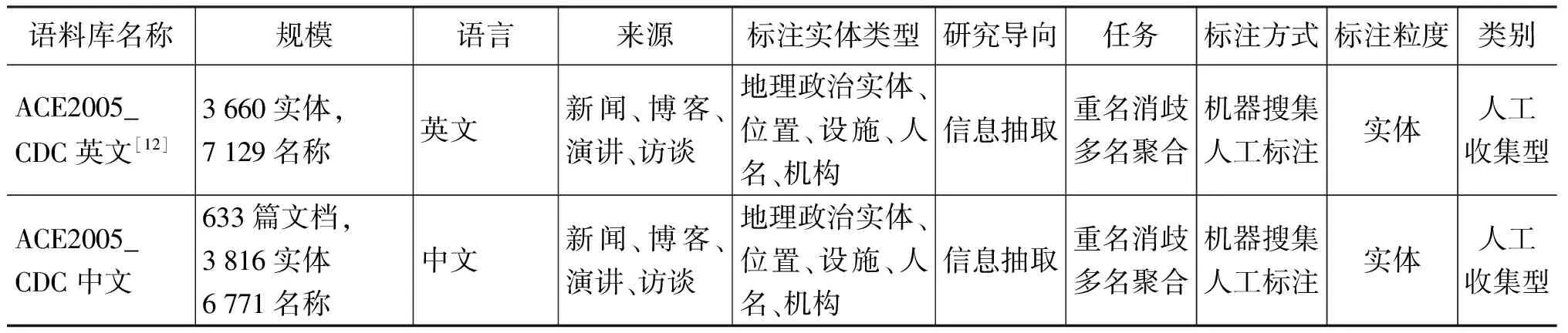
續表
總體上講,CDC語料庫可分為WEB挖掘型和人工收集型,下面分這兩種情況進行說明:
a) WEB挖掘型: 即按一定的查詢條件從WEB中檢索到語料,然后再進行手工或自動標注。這一類型語料庫以小規模的手工John Smiths語料庫[6]和大規模的自動Wiki Link語料庫[11]為典型代表。前者還包括用于評測任務的WePS[9]和CIPS[10]語料,其主要特點是:
? 語料庫的基本構建方法是挑選一個至數個人名作為查詢條件從搜索引擎里面搜集相關網頁,再用人工的方法將同一姓名而不同人物的網頁分別歸類,最后形成語料庫;
? 人力的有限,以及各研究者很難自行構建具有規模的語料庫,催生了Person-X[7]這樣的人工增加歧義的方法。具體做法是選擇幾個人名,然后在被選中的人名所在文檔中將該人名人工替換為Person-X以增加歧義;
? 面向信息檢索任務,因而標注的粒度限于篇章級。
為了克服小規模CDC語料庫中存在的實體分布單一和只有重名消歧的缺陷,Singh[11]提出了從海量的互聯網數據中自動挖掘出一個大規模的高可靠性的CDC語料庫。其具體做法是,針對不同網頁中指向同一個維基百科實體條目的超鏈接,抽取錨點文本作為該實體的一個名稱引用,將超鏈接附近的上下文作為該實體所在的文本,從而構造出一個CDC語料庫。
b) 人工收集型: 由于構建大規模的CDC基準語料庫需要相當大的精力和時間,這部分的工作主要由NIST通過相關的評測任務來完成。特別地,ACE2008引入了GEDR和GRDR(Global Relation Detection and Recognition)兩個跨文本的評測任務,即跨文本的實體識別和跨文本的關系識別。相比之前的CDC消解任務,ACE2008特點主要體現在:
? 將實體類型從單一的人名(PER)擴展為人名和機構名(ORG);
? 面向信息抽取任務,因而將標注粒度從文本級別細化到句子級別,即同一個文本內的同一名稱也可歸入到不同的指代鏈;
? 引入“多名聚合”任務,即除了考慮“重名消歧”外,也同時將同一實體的不同名稱歸入到同一個指代鏈中;
? 語料規模較大,包含10 000篇不同來源的文本,且根據文本所包含的實體進行精心挑選,因而保證了實體分布的多樣性。
在ACE2008之前,JHU 2007 CLSP暑期研討會[12]會議,以ACE2005英文語料庫為基礎,構建了一個實驗性的英文ACE2005 CDC語料庫。此語料庫雖然規模較小,但卻具備了多種特點,如面向信息抽取、多種來源和多種實體類型等。鑒于此,本文以ACE2005中文語料為基礎構建一個實驗性的中文CDC語料庫,選擇ACE2005中文語料的主要原因有以下幾點:
? 鮮有在中文方面信息抽取任務的CDC消解研究,相關語料庫的缺失是一個主要問題,而ACE2008語料庫很遺憾地沒有提供對中文的支持;
? 希望研究多種類型的實體出現CDC現象的語言特征,而不是僅限于PER和ORG,結果表明GPE實體也擁有相當豐富的CDC歧義現象: 該類型實體不僅占據了最多的實體引用數量,達到2 419個,而且其內部的具有跨文本指代的實體引用數量比例也高達85.4%;
? 進一步比較中文和英文在CDC現象上所呈現的語言特征的同異點,揭示CDC的跨語言共性;
? ACE2005語料庫已經完成了文本內的指代標注工作,因而有助于快速地進行跨文本指代的標注。
值得一提的是,與跨文本指代消解相關,TAC (Text Analysis Conference) 評測的KBP (Knowledge Base Population)[13]任務中就有一個稱為實體鏈接(Entity Linking)的子任務,其目的就是將在文本中出現的實體名稱映射到一個包含大量實體的知識庫中,從而為豐富知識庫中的實體信息打好基礎。由于同一名稱往往對應知識庫中的不同實體,因此同跨文本指代消解類似,實體鏈接也是解決實體消岐(Entity Disambiguation)[14]的兩條途徑之一。通常情況下,知識庫中的實體來源于維基百科中的條目,其信息從信息盒(Infobox)中提取。實體鏈接與跨文本指代消解相比,雖然都涉及到實體名稱的消岐,但前者是將文本中出現的實體名稱歸入到知識庫中已有的某一實體下,該實體往往具有豐富的信息,這些信息有助于實體的鏈接;而后者是將一個文檔集合中的同一實體歸并起來,其所依賴的信息只有實體名稱和上下文信息。另外,從語料的差異性上來看,實體鏈接大多使用維基百科中的網頁作為訓練和測試語料[15-16],也有一些使用了Web上的鏈接信息以及領域特定語料庫[14];而跨文本指代消解一般使用從Web上檢索到的網頁文本作為訓練和測試語料[9],維基百科的網頁比普通Web網頁更規范,結構性更好。
3 標注方法及過程
基于ACE2005中文語料庫的跨文本指代語料的標注過程分為語料庫預處理、初始指代鏈生成、指代鏈手工調整和指代鏈輸出等四個過程。
3.1 語料庫預處理
原始的ACE語料庫均使用XML標注方式,即所有的實體及實體對之間的語義關系等信息均以XML標記的形式嵌入到自由文本中,目的是提高標記的通用性、可讀性及標注效率。為了處理方便,我們首先把含有XML標記的文本轉換成不含標記的純文本。這樣,每個文檔就得到兩種形式: 一個是文本文件,其中每一個句子占據一行,并且所有單詞成分(包括標點符號等)之間都用空格分隔;另一個是標注文件,其中包含實體和關系的標注信息,并且實體之間通過相同的ID號來表明其指代關系。
3.2 初始指代鏈生成
首先,為每個文本的每個實體確定中心詞,挑選原則是文本中某個實體中字符長度最長的名稱引用。然后,就是按照字符串完全匹配的簡單規則,將不同文本之間的相同中心詞的實體鏈接在一起,形成初始的跨文本指代鏈。
3.3 指代鏈手工調整
這是真正的人工語料標注階段。安排兩位標注者A和B,要求他們逐一查看每一項實體,然后僅憑實體所在的文本信息來判斷初始指代鏈是否存在錯誤,并且對不當的指代鏈做出修改。該過程中,兩位標注者不得相互討論,也不能借助于外部資料。在標注者完成人工標注完成后,仲裁者C介入。仲裁者首先要找出兩標注者之間的差異,針對這些差異,仲裁者尋求外部知識來解決分歧,確定最終的指代鏈。
如圖1所示的語料標注工具是由我們專門為此任務開發的,它由三個部分組成。第一部分列出指代鏈的中心詞(headword);第二部分列出的是每個中心詞下面的指代鏈信息;第三部分是文本,即某一實體指代鏈中的某一引用所在的整個文本。根據預處理所得到的標注文件以及ACE定義的七大實體類型,將不同類型的實體以不同色彩來顯示以增加清晰度。

圖1 CDC標注界面
在標注過程中,經常會遇到指代鏈分解和合并等兩種情況:
a) 分解: 在初始指代鏈生成的時候,具有相同名稱的實體引用全部歸入到同一指代鏈中。當標注者發現其中部分引用名稱指向另一實體時,就需要將它們歸入已有的另一個指代鏈或者為其新建一個指代鏈。例如,“中國隊”,這個時候只有上下文賦予其特定的含義: 中國跳水隊或者中國游泳隊等,碰到這樣的例子是就需要進行分解的操作。
b) 合并: 當標注者發現兩個不同的名稱引用指向同一個實體時,就需要將其合并成一條指代鏈。如“重慶”和“渝”是同一個GPE實體的不同名稱,需要將它們進行合并。
在實際的標注過程中,由于指代現象的復雜性,兩種情況還會嵌套出現,特別是一些意義非常多樣化的實體引用上。例如,“中國”和“北京”,兩者可能指向不同的地理實體,也可能同時指向“中國政府”這一概念。
3.4 指代鏈輸出
標注完成后生成如圖2所示的標注文件。其中一級標記CDC中的ID屬性表示某個實體在整個語料庫中的編號,ENT_TYPE表示實體類型;次級標記ENTITY中的DOC屬性表示指代鏈實體所在的文本名稱,ID表示該實體在該文本中的實體編號,MENTION表示該實體在該文檔中的字符串長度最大的引用名稱。

圖2 CDC標注結果
4 語料庫統計與分析
本節首先對標注得到的CDC語料庫按不同口徑進行統計,然后對該語料庫上的跨文本指代消解任務的難度進行分析。
4.1 一致性檢驗
為了衡量跨文本指代標注結果的一致性,我們讓兩位標注者同時對整個語料庫進行標注。根據Passoneau[17]提出的語料庫指代標注的可靠性計算方法,采用Krippendorff[18]的alpha系數來表示兩位標注者之間的一致性。該系數通過計算指代鏈之間的相似度距離來表示不同標注者之間的一致性。Passoneau的相似度距離度量原則為:
? 當兩條指代鏈完全吻合時距離為0;
? 當一條指代鏈是另一條指代鏈的子集時則距離設為0.33;
? 當兩條指代鏈不互相包含且有公共的非空子集時,則距離設為0.67;
? 否則當兩條指代鏈交集為空集時,距離值設為1。
使用以上方法,我們計算得到兩位標注者的標注結果的alpha系數為96%。Krippendorff認為,低于67%的alpha系數表明標注結果不可靠,因此我們認為兩位標注者的標注結果是高度一致的。
4.2 語料庫統計
4.2.1 按實體類型分布情況
在最終的語料庫中,共有3 618個實體和6 771個實體引用(名稱)。在所有實體引用中,FAC類型占299個,GPE有2 419個,LOC有233個,ORG有1 939個,PER有1 860個,VEH和WEA分別為17個和4個。從實體引用是否具有跨文本指代的角度來看,有2 795個引用對應2 795個孤立實體,這些引用不存在“重名”,對應的這些實體也不存在“多名”,即名稱和實體是完全的一對一映射的關系。這部分孤立實體的引用占總數的41.3%,其余3 976個引用對應643個實體,即存在“多名”或者“重名”的跨文本指代現象。
圖3顯示了各個實體類型中,存在跨文本指代消解現象的引用所占的比例。從圖中可以看出,對于不同的實體類型,跨文本指代現象的分布不盡相同。GPE類型的實體引用存在指代的比例高達85%,占據了所有實體引用指代的55%;ORG和PER次之,而LOC和FAC則最小。可見,GPE類型的實體指代消解性能將會對整個系統的性能造成較大的影響。
4.2.2 “多名”指代的分類及分布
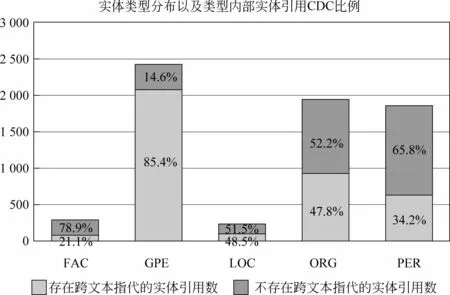
圖3 CDC按實體類型分布圖
在整個語料庫中, 具有跨文本指代的實體一共有643個,其中“多名”實體,即擁有多個名稱的實體數量為255個,占CDC實體總數的40%,占整個語料庫所有實體的7%。通過對這些實體名稱進行分析可以發現,具有“多名”指代的實體名稱可以分為以下四種類型:
? 名字省略,即兩個名稱之間具有包含關系,但指向同一個實體,例如,“山東省”和“山東”均指向同一個GPE實體;
? 翻譯差異,主要表現在兩個方面,一是外來詞音譯時的用詞差異,例如,“班達亞齊”和“班達雅奇”均指印尼的Banda Aceh;二是港澳臺地區和大陸地區的不同翻譯,比如“朝鮮”和“北韓”分別是大陸地區和臺灣地區對DPRK(Democratic People’s Republic of Korea)的不同稱呼;
? 錯別字,例如,“宏基”和“宏碁”,后者是臺灣宏碁公司的正式名稱,而前者是別字;
? 別稱或者轉喻,即字串間的交集為各字串的真子集,例如,“重慶”和“渝”,“北京”或指“中國”;
我們注意到,有些實體會出現一種以上的多名指代現象。
表2列出了四種多名指代類型在總數中所占的比例,從中可以看出,多名現象中“名稱省略”占了大多數,而“別稱”所占比例最小,因此解決名字的省略問題可以顯著提高該語料庫中的跨文本指代消解的性能。

表2 多名指代的分布
4.2.3 “重名”歧義中的分類及分布
整個語料庫中出現的所有實體引用可歸結為 3 795種不同的名稱。這3 795種名稱,在語料庫里面出現次數大于1的名稱為666個,這其中具有“重名”歧義的共有70個,這說明重名歧義的現象相當少。我們的分析表明,該語料庫中具有“重名”歧義的實體名稱可以分為三種類型:
? 名稱轉喻所引起的重名歧義,例如,“北京”既可以指北京這個城市,在外媒中往往又代表中國政府;
? 名稱省略而導致的重名歧義,這個類型比較復雜,在各ACE實體類型中表現不同: 在ORG實體中,省略定語等修飾詞的實體名稱,如“共產黨”可以是中國共產黨也可以是古巴共產黨;在GPE實體中,地名簡稱造成了重名歧義,例如,“蘇”可以指江蘇,或者指蘇州,也可以是指蘇聯;在PER實體中,用姓來稱呼人,例如,姓“布萊爾”的人,可以有不同的名,亦如“張某”,可能指向不同的張姓人士;
? 不當標注而造成的重名歧義,例如在語料庫中存在二個實體引用“利馬”,其中一處說的是秘魯首都,而另一處說的是馬來西亞的“利馬航展”,ACE在標注時把“利馬”和后面的被修飾成分分開不太合適。由于不同語言之間語言現象的復雜性和差異性,我們認為ACE的某些標注原則在中文環境下欠妥。
還有一種在人名中較為常見的,名稱完全相同造成的重名歧義,在本語料庫中并未出現。
表3統計了這三類“重名”歧義現象在總數中的分布情況,其中省略所占的比例最高,而轉喻則比例最低。有趣的是,名稱省略也是引起“多名”現象的主要原因,因此有效解決省略問題能顯著提高跨文本指代消解的整體性能。

表3 重名歧義的分布情況
4.3 語料庫的困惑度分析
Popescu[19]在研究人名的重名消歧問題時,將一種名稱所對應的實體數量稱為“困惑度”,并且認為人名的“困惑度”與進行消歧所需的特征數量成正比。為了更好地考察在本文所構造的語料庫上進行跨文本指代消解的難度,我們結合Popescu的觀點以及信息論中困惑度的概念,提出了衡量“多名聚合”和“重名消歧”復雜度的“多名困惑度”和“重名困惑度”以及“CDC語料庫等效模型”等概念。
4.3.1 多名困惑度
要衡量某一實體的不同引用的分布,不僅要考慮該實體有多少個不同名稱,還要考慮每種名稱所占的比例,這兩個因素都會對跨文本指代消解系統的性能產生影響。為了更好地描述問題,引用下列形式化表示:
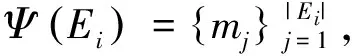
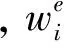
根據上述公式計算得到整個語料庫的“多名困惑度”為1.19。由于語料庫中存在2 795個既沒有“多名”也沒有“重名”的孤立實體,把這些孤立實體排除后語料庫的“多名困惑度”上升為1.36。語料庫的“多名困惑度”可以直觀的理解為每個實體平均擁有多少個等概率出現的名稱。由此可見,上述計算結果表明語料庫中一個實體平均擁有1.19個引用名稱,把孤立實體排除后,多名現象加重,一個實體平均擁有1.36個引用名稱。
4.3.2 重名困惑度
與“多名困惑度”不同的是,“重名困惑度”衡量一個名稱被不同實體所引用的不確定性,但其實只是將實體和引用的位置進行了互換,因此可以采用與“多名困惑度”相同的方法進行計算,即對于語料庫中的一個名稱Mi,計算其被不同實體引用的數量分布。由此,我們得到整個語料庫的“重名困惑度”(PPr)等于1.06,排除孤立實體后,語料庫的“重名困惑度”上升到1.10,它表明一個名稱分別對應于1.06或1.10個實體。
4.4 基準性能
為了評估在該語料庫上進行跨文本指代消解的難度,我們使用理論計算、字符串精確匹配以及向量空間模型等三種方法進行基準性能的評估。
首先從計算基準性能的理論值,根據上一節分析所得到的原始語料庫中的實體以及名稱引用的概率分布,本文用信息熵的辦法將原始語料轉換成與原始語料庫“等效”的虛擬語料庫。在這個語料庫中,|Ce|個實體等概率出現,而且每個實體的所有引用也是等概率分布的——即每個實體平均擁有PPv種等概率出現的名稱;從名稱的角度來說,|Cm|種名稱等概率出現,并且每種名稱平均對應PPr個等概率出現的實體。假設對該語料庫采用字符串精確匹配的方法進行跨文本指代消解,即將具有相同名稱的實體都歸入同一個指代鏈,遵循B3打分方法[20]的思想,那么其精度就是該指代鏈中所含實體的純度,即精度就是“重名困惑度”(PPr)的倒數,而其召回率參考指代鏈中名稱引用的純度,即為“多名困惑度”(PPv)的倒數。
需要注意的是,在計算性能的時候,我們通常使用去除了孤立實體后的重名困惑度和多名困惑度。原因是孤立實體在字符串匹配方法中必然100%匹配成功,因而不考慮在內。同樣,下面實驗中的性能評估也使用這一原則: 如果孤立實體匹配成功則不計算其帶來的性能收益,若匹配錯誤則計算其帶來的性能損失。
接著,我們使用字符串精確匹配的方法來進行跨文本指代消解,也就是認為具有完全相同名稱的實體為同一實體,實驗結果使用B3打分方法進行評估。
最后,在不考慮實體名稱的前提下,我們使用了廣泛采用的向量空間模型來進行跨文本指代消解,具體方法為: 首先在一個特定的窗口范圍內抽取待消解實體名稱的上下文特征詞;然后計算TF*IDF衡量每個特征的權值并由此構成每個實體的特征向量;最后使用層次聚類的辦法合并實體名稱。在此過程中通過調節窗口大小以及聚類閾值來獲得最佳性能。實驗結果同樣使用B3打分方法進行評估,三種方法的性能如表4所示。
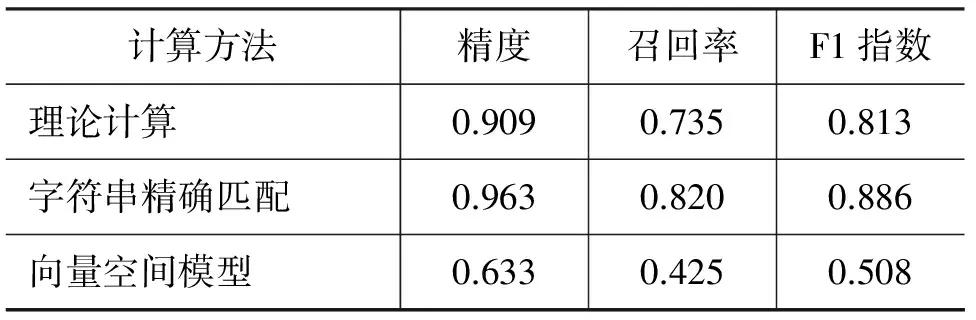
表4 跨文本指代消解的基準性能比較
從實驗結果可以看出:
? 字符串精確匹配方法的性能明顯高于理論分析的結果,這是由于CDC語料庫中實體和引用分布的“長尾效應”[3,21]所導致的,即每種名稱總是對應于某個占統治地位的實體,同時每個實體中總是對應于某個占統治地位的名稱,因此原始語料庫上的CDC消解要比虛擬語料庫上的CDC消解來得簡單。
? 無論是采用哪種方法計算基準性能,精度值都顯著大于召回率,這是由于語料庫中的“重名”歧義現象較少(“重名困惑度”較小),即使武斷地將相同的名稱都聚到同一實體鏈下,也能獲得較高的精度。而“多名”指代現象略微豐富一些(“多名困惑度”稍高),于是召回率明顯低于精度。
? 采用向量空間模型得到的性能明顯低于另二種方法得到的性能,其主要原因有二個,一是主題多樣性。同一實體,如“臺灣”,既可能出現在政治和經濟新聞,也可能出現在社會、娛樂和體育新聞中。不同主題的文檔語境不同,上下文迥異;二是上下文稀疏性。很多情況下,一個待消解的實體名稱在文檔中僅僅是順便提到,其上下文信息也就非常稀疏。
雖然簡單的字符串匹配就能取得較好的性能,而且就信息檢索的角度來看,能夠捕獲文本中的最主要實體及其引用在某些情況下已經足夠了,但是,本語料庫的出發點是面向信息抽取的跨文本指代消解,因而其最終目的是為信息集成和信息融合提供服務,即將分布在不同文本的實體及其相關信息通過跨文本指代消解構成一個內容更豐富的知識庫。為確保信息的可靠性和豐富性,信息融合對跨文本指代消解的性能特別是召回率有更高的要求,因此,我們下一步的工作是如何進一步提高面向信息抽取的跨文本指代消解的性能。
5 結論和下一步的工作
本文在ACE2005中文語料庫的基礎上,采用自動生成和人工標注相結合的方法,構建了一個面向信息抽取的中文CDC語料庫,并將該語料庫公開發布,旨在促進中文跨文本指代消解研究的發展。通過對該語料庫的進一步統計和分析發現,在所有的ACE實體類型中,跨文本指代現象較為嚴重的類型依次為GPE、ORG和PER等,且實體的多名現象和重名現象主要是由于名稱省略而引起的,因而有效地解決名稱省略問題能顯著提高跨文本指代消解的性能。另外,本文還提出了“多名困惑度”和“重名困惑度”兩個指標,以便從理論上衡量跨文本指代消解的難度,在此基礎上分析了理論分析和實驗方法所得到的性能之間的差異。
不足之處在于,由于本文所構建的CDC語料庫是基于現有的ACE 2005語料庫,因而其規模較小,因此今后的工作重點是一方面利用自動或手工的方法進一步擴充其規模,另一方面,在該語料庫上嘗試使用不同的方法來提高中文跨文本指代消解的性能。
[1] Dagan I, Itai A. Automatic Processing of Large Corpora for the Resolution of Anaphora References[C]//Proceedings of the 13th conference on Computational linguistics. Stroudsburg, PA, USA: Hans Karlgren, 1990: 330-332.
[2] 王厚峰.漢語指代消解與省略恢復研究[D]. 中國科學院聲學研究所2000屆博士后出站報告.
[3] Mayfield J, Alexander D, Dorr B, et al. Cross-Document Coreference Resolution: A Key Technology for Learning by Reading[C]//Proceedings of the AAAI 2009 Spring Symposium on Learning by Reading and Learning to Read. Stanford, California: March 23, 2009: 65-70.
[4] Grishman R, Beth S. Message Understanding Conference-6: a brief history[C]//Proceedings of the 16th Conference on Computational Linguistics (COLING'96). Copenhagen, Denmark: August, 1996: 05-09.
[5] NIST Speech Group. The ACE 2008 evaluation plan: Assessment of Detection and Recognition of Entities and Relations Within and Across Documents[EB/OL]. http://www.nist.gov/speech/tests/ace/2008/doc/ace08-evalplan.v1.2d.pdf, 2008.
[6] Bagga A, Baldwin B. Entity-Based Cross-Document Coreferencing Using the Vector Space Model[C]//Proceedings of the 36th Annual Meeting of the Association for Computational Linguistics and the 17th International Conference on Computational Linguistics (COLING-ACL'98). Montréal, Québec, Canada: 1998: 79-85.
[7] Gooi C H, Allan J. Cross-Document Coreference on a Large Scale Corpus[C]//Proceedings of HLT-NAACL 2004. USA,2004: 9-16.
[8] Batista-Navarro R T, Ananiadou S. Building a Coreference-Annotated Corpus from the Domain of Biochemistry[C]//Proceedings of the 2011 Workshop on Biomedical Natural Language Processing, ACL-HLT 2011. Portland, Oregon, USA: June 23-24, 2011: 83-91.
[9] Artiles J, Gonzalo J, Sekine S. Web People Search Task at SemEval-2007[EB/OL]. http://nlp.uned.es/weps/weps2007_data_readme_1.1.txt, 2007
[10] CIPS-SIGHAN Joint Conference on Chinese Language Processing (CLP2010)[EB/OL]. http://www.cipsc.org.cn/clp2010/task3_ch.htm, 2010.
[11] Singh S, Subramanya A, Pereira F, et al. Large-Scale Cross-Document Coreference Using Distributed Inference and Hierarchical Models[C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics. Portland, Oregon: 2011: 793-803.
[12] CLSP Summer Workshop. Exploiting Lexical & Encyclopedic Resources for Entity Disambiguation[EB/OL]. http://www.clsp.jhu.edu/ws2007/groups/elerfed/documents/ELERFED-CDC-Overview.v2.ppt, 2007.
[13] Task Description for Knowledge Base Population at TAC 2009[EB/OL]. http://apl.jhu.edu/~paulmac/kbp/090601-KBPTaskGuidelines.pdf, 2009
[14] 趙軍, 劉康, 周光有, 等. 開放式文本信息抽取[J]. 中文信息學報, 2011, 25(6): 98-110.
[15] Rao D, McNamee P, Dredze M. Entity Linking: Finding Extracted Entities in a Knowledge Base, Multi-source, Multi-lingual Information Extraction and Summarization[M]. Germany, Springer, 2011.
[16] Cucerzan S. Large-Scale Named Entity Disambiguation Based on Wikipedia Data[C]//Proceedings of Empirical Methods in Natural Language Processing. Prague: June 28-30, 2007: 708-716.
[17] Passoneau R J. Computing reliability for coreference annotation[C]//Proceedings of the International Conference on Language Resouces (LREC). Lisbon, Portugal: May 2004.
[18] Krippendorff K H. Content Analysis: An Introduction to Its Methodology[M]. Beverly Hills, CA: Sage Publications, 1980.
[19] Popescu O. Person Cross Document Coreference with Name Perplexity Estimates[C]//Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing. Singapore: 6-7 August 2009: 997-1006.
[20] Bagga A. Evaluation of Coreferences and Coreference Resolution Systems[C]//Proceedings of the First Language Resource and Evaluation Conference. Granada, Spain: May 1998.
[21] Baron A, Freedman M. Who is Who and What is What: Experiments in Cross-Document Co-Reference[C]//Proceedings of the 2008 Conference on Empirical Methods in Natural Language Processing. Honolulu: October 2008: 274-283.
Construction of Information Extraction-orientated Chinese Cross Document Coreference Corpus
ZHAO Zhiwei, QIAN Longhua, ZHOU Guodong
(1. Natural Language Processing Laboratory, Soochow University, Suzhou, Jiangsu 215006, China;2. School of Computer Science & Technology, Soochow University, Suzhou, Jiangsu 215006, China)
Cross Document Coreference(CDC) resolution is an important step in information integration and information fusion. As a consequence, a CDC corpus is indispensable for research and evaluation of CDC resolution. Given the fact that no Chinese CDC corpus is publicly available oriented for information extraction, this paper describes how to build a CDC corpus based on the ACE2005 Chinese corpus via automatic generation and manual annotation, which covers all the ACE entity types. The corpus is made publicly available to advance the research on Chinese CDC resolution. In addition, this paper analyses the types and characteristics of CDC in Chinese text as well as proposes the concept of two metrics, i.e., “variation perplexity” and “ambiguity perplexity”, to evaluate the difficulty of Chinese CDC resolution, providing some insights for further CDC research.
cross document coreference; information extraction; corpora annotation; perplexity

趙知緯(1987—),碩士研究生,主要研究領域為信息抽取。E?mail:none.zhao@gmail.com錢龍華(1966—),通訊作者,副教授,碩士生導師,主要研究領域為自然語言處理。E?mail:qianlonghua@suda.edu.cn周國棟(1967—),教授,博士生導師,主要研究領域為自然語言處理。E?mail:gdzhou@suda.edu.cn
1003-0077(2015)01-0057-10
2012-04-09 定稿日期: 2012-08-06
國家自然科學基金(60873150,90920004);江蘇省自然科學基金(BK2010219,11KJA520003)
TP391
A
猜你喜歡
甘肅教育(2020年8期)2020-06-11 06:10:02
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中華手工(2017年2期)2017-06-06 23:00:31
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
中外會展(2014年4期)2014-11-27 07:46:46
語文知識(2014年1期)2014-02-28 21:59:13
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
