面向機器翻譯的句類依存樹庫構建及應用
2015-04-25 09:57:29王慧蘭張克亮
中文信息學報 2015年1期
王慧蘭, 張克亮
(1. 空軍指揮學院,北京 100097;2. 解放軍外國語學院,河南 洛陽 471003)
?
面向機器翻譯的句類依存樹庫構建及應用
王慧蘭1, 張克亮2
(1. 空軍指揮學院,北京 100097;2. 解放軍外國語學院,河南 洛陽 471003)
該文以漢英機器翻譯為應用目標,以概念層次網絡理論的語義網絡和句類分析方法為理論基礎,探討了句類依存樹庫構建的理論和標注實踐等問題,描述了構建樹庫所需的概念類別標注集和句類關系標注集。并通過與已有漢語樹庫進行對比,以漢語顯性輕動詞句的標注為例,分析了漢語句類依存樹庫的特點。該文在應用層面定義了面向漢英機器翻譯的融句法語義信息于一體的“句類依存子樹到串”雙語轉換模板,嘗試基于漢語句類依存樹庫提取漢英轉換模板。
機器翻譯;概念層次網絡理論;句類依存樹庫
1 引言
以句法樹為基本元素的樹庫是自然語言理解與處理的重要資源。目前國內外的樹庫基本上可以分為兩大類,一類是主要呈現句法信息的樹庫,例如,英國的Lancaster-Leeds樹庫、美國的賓州樹庫;還有一類主要呈現詞語之間的語義支配關系,例如,德國的Tiger樹庫、捷克的布拉格依存樹庫PDT,另外Fillmore主導建設的框架網絡FrameNet中每個框架都配有若干經過句法語義分析的例句,從廣義角度講FrameNet也可以看作某種樹庫。
2 現有漢語樹庫的標注信息對比
目前國內外比較有影響的漢語樹庫主要包括,賓州大學漢語樹庫PennCTB、“臺灣中央研究院”(以下簡稱“中研院”)漢語樹庫Sinica、清華大學樹庫TCT、北京大學漢語樹庫、哈爾濱工業大學漢語依存樹庫HIT-IR-CDT以及山西大學漢語框架語義知識庫Chinese FrameNet(CFN)。文獻[1]對現有漢語樹庫的規模、應用領域等進行了總結,現有漢語樹庫均有各自的標注體系以及標注特點,樹庫包含的標注信息決定了樹庫已開發的以及潛在的應用領域。本文綜述的重點則在于現有漢語樹庫所標注的句法和語義信息,如表1所示(√表示已標注,其后的數字表示標注集的大小;×表示未標注相關信息)。
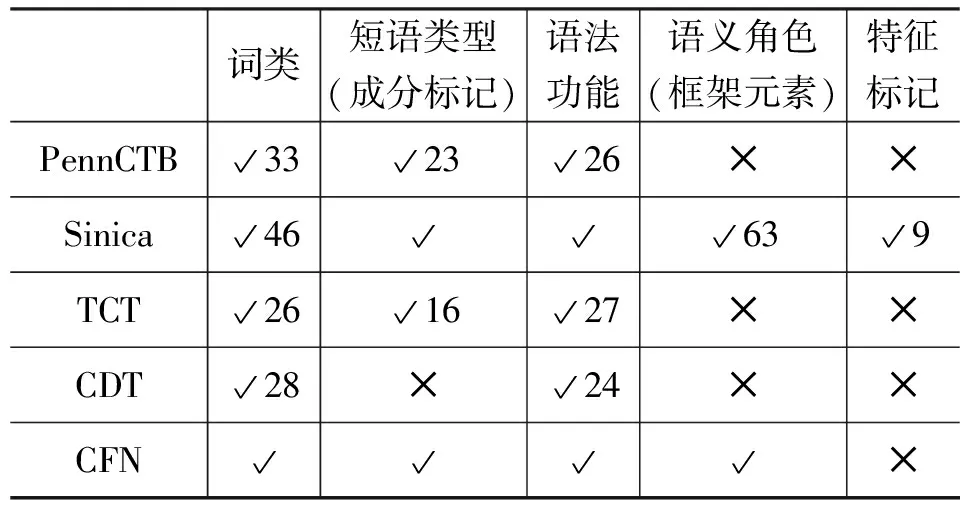
表1 現有漢語句法樹庫已標注信息
PennCTB[2]以喬姆斯基的短語結構語法為理論基礎,標注了句子的層次關系、短語的結構類型、功能類型以及詞語的詞類。臺灣中研院語言所和資訊所聯合建設的Sinica樹庫[3]以信息為本的格語法為理論基礎,兼顧了句法和語義信息,不僅標注了句子的層次關系、短語的結構類型以及詞類,還標注了名詞短語的語義角色,并開發了包含9個特征標記的標注集。北京大學計算語言學研究所的漢語句法樹庫[4]與清華大學TCT句法樹庫[5]二者一脈相承,均以漢語傳統的層次分析法為理論基礎來標注句子層次,采用了相對較小的詞類標注集,并在詞類標注的基礎上對于直接成分之間的句法關系進行了標注。國家語委的現代漢語語料庫也基本上采用了相似的構建思路[6]。哈工大漢語依存句法樹庫[7]以依存語法為理論基礎,采用了國家語委863項目開發的詞類標注集(由23個詞類標記符組成)[8],并開發了一個包含24種句法依存關系的關系標注集。山西大學CFN句子庫的標注信息包括詞類、短語類型、語法功能以及框架元素[9-10]。
現有的漢語樹庫在句法、語義的描寫方面各有側重,采用的句法分析方法也各不相同,但無論在句法標注還是語義標注層面,都存在一定局限。以往漢語樹庫的共同點在于,基于現有的詞類體系進行漢語句法分析,該詞類體系是從印歐語系中引進的舶來品,對于漢語而言,由于現代漢語語法體系中詞類和句法成分之間不存在一一對應的關系,導致兼類詞、詞類歧義偏多。而語義層面的標注目前主要還停留在語義表層,語義標注的類型主要分為語義角色(semantic role)標注和語義框架(semantic frame)標注,還沒有涉及到深層次的語義信息。“由于語義角色類型有限,忽略了語言表達中的細節,實用價值受到限制[9]。”
“既然我們的普遍共識是,漢語的詞性和句法功能是不像英語中那樣嚴格對應的,那么一個以詞性為基礎,以主謂賓等句法功能為架構的漢語樹庫,真的能夠全面而真實地反映漢語的語言現實嗎?[11]” 對于“詞無定類,離句無品”的現代漢語而言,我們嘗試尋找一種更適用于漢語的詞的分類方法,以及句子分析方法,并在此基礎上構建一個更為本土化的漢語樹庫。本文在概念層次網絡(Hierarchical Network of Concepts, HNC)理論框架下,以HNC語義網絡和句類理論為理論基礎,擬構建一個面向機器翻譯領域的漢語句類依存樹庫,重點標注詞語級的概念類別信息和句子級的語義依存信息,并嘗試探討該句類樹庫在漢英機器翻譯領域的應用。
3 漢語句類依存樹庫的構建研究
本小節擬在概念層次網絡(Hierarchical Network of Concepts, HNC)[12-14]理論框架下,研究漢語句類依存樹庫構建中的相關理論與操作實踐問題。
3.1 樹庫構建的理論背景
目前基于句法的機器翻譯研究仍然依賴于詞類體系,而詞形、詞類都具有較強的語言個性,但是與詞形詞類相比,概念則具有跨語言共性,可以成為翻譯過程中的中介體系。眾所周知,語義范疇具有相對性,概念體系的具象化亦非常難,我們僅從語義知識顆粒度相對較粗的概念類別出發,構建基于詞的語義類的句類依存樹庫,為基于句法的漢英機器翻譯定義一種新的雙語轉換模板。
HNC理論是關于人類語言認知機制的理論,也是面向計算機的自然語言理解理論體系,該理論以概念類別為基礎,而非詞類,根據句子核心動詞的語義類別對句子進行分類(即句類),更適合于意合的漢語。HNC對于概念之間層次性和關聯性的描述體現在三大語義網絡中: 基本概念、基元概念以及邏輯概念語義網絡。基本概念語義網絡包括時間、空間等基本概念;基元概念語義網絡的構建以作用效應鏈為基礎,包含作用、過程、轉移、效應、關系及狀態六個主體基元概念子網絡,是HNC句類分析的基礎;邏輯概念語義網絡包括語言邏輯概念(如語義塊標識符、句間邏輯說明符等)和基本邏輯概念(如比較、判斷等概念)。HNC語義網絡具有概念化、基元化、層次化和網絡化等四個基本特征,是概念聯想脈絡的線索[13]。
句類由語義塊構成,是句子的語義類型,HNC句類劃分的標準是“作用效應鏈+判斷”,他們表述事物的基本側面及句子的基本語義信息,一共有作用句、過程句、轉移句、效應句、關系句、狀態句和判斷句七大句類共57組基本句類,基本句類彼此之間又可以形成混合句類,依靠57組基本句類及其混合句類可以窮盡表達自然語言中的所有句子,且所有句類都可以利用句類表達式進行形式化表達[13]。
以 “中國今天公布了去年打擊走私的巨大成果。”為例,句子的特征語義塊(主要動詞)為“公布”,是整個句子的支配者,該句的句類為信息轉移(T3)與效應(Y30)的混合句,句類表達式如式(1)所示。
T3Y30*21J=TA+T3Y30+YC
(1)
該句類表達式可以預測句子的主要語義類別以及包含的主語義塊數目和類型等相關句類知識。“中國”為轉移者TA,“今天”為j1(時間概念),即時間輔語義塊,“了”為hv(特征語義塊的后附加成分,也稱為特征語義塊核心的下裝),小句“去年打擊走私的巨大成果”為效應內容YC。
3.2 樹庫標注集
標注樹庫需要完善的標注體系和規范的標注流程,從而保證標注語料的高質量和一致性。用于標注句類依存樹庫的共有兩個標注集,其一為概念類別標注集,其二為句類關系標注集。
3.2.1 概念類別標注集
概念類別標注集基于HNC語義概念體系而建立,用于表示詞語的主要概念類別意義,例如,“普京”標注為fp(人名)等。我們構建句類依存樹庫時主要利用了已建成的HNC詞語知識庫資源,該知識庫中一共標注了53 000多個詞形,每個詞形可能具有多個語義類別,例如,“后院”具有兩個概念類別: wj01(具體空間);pj01(社會空間)。
HNC詞語知識庫中每個詞形的各語義類別都分別標注了該詞語的概念類別、HNC符號、句類代碼、語句格式、句類知識等知識,目前在HNC句類自動分析系統中僅僅利用了詞語的概念類別知識,還無法對HNC符號進行自動解讀。我們在構建句類依存樹庫時主要利用了詞語知識庫中的概念類別、句類代碼等知識,并對其中的概念類別進行了規范統一處理。
概念類別標注集分為以下11大類: v類概念(動態概念)、g類概念(靜態概念)、u類概念(屬性概念)、z類概念(值概念)、r類概念(效應概念)、p類概念(人)、w類概念(物)、jw類概念(基本物)、j類概念(基本概念)、l類概念(語言邏輯概念)、f類概念(語習概念)。
例1 中國/pj2 今天/j1 公布/v 了/hv 去年/j1 打擊/v 走私/v 的/l41 巨大/u 成果/r 。/pun
例2 此外/lb ,/pun 委員會/pe 還/uv 相繼/uv 派/v 團/pe 赴/v 臺/pj2- 訪問/v ,/pun 與/l02 臺灣/pj2- 工商界/pj01 進行/vv 了/hv 廣泛/u 的/l41 接觸/v 和/l42 交流/v 。/pun
3.2.2 句類關系標注集
句類關系標注集用于標注詞語之間的語義依存關系,與以往樹庫關系類標注集的最大區別在于我們的句類關系標注集不是封閉集合,是以HNC句類分析理論為支撐的半開放集。仍以例1 “中國今天公布了去年打擊走私的巨大成果。”為例,來具體說明句類關系標注集的類別。
句類關系標注集分為以下兩大類6小類。
(1) 句類核心成分,其與支配者的句類關系利用句類表達式中的符號表示,包括以下a、b兩個小類:
a) v類概念自身的語義類別,包括充當全局特征語義塊的v概念以及充當局部特征語義塊(塊擴、句蛻的核心成分)的v概念,如圖1中全局特征語義塊“公布”,其語義類別為T3Y30(信息轉移與效應),局部特征語義塊“打擊”的語義類別為X(基本作用);
b) v與相關廣義對象語義塊之間的關系,如圖1中“中國” 與其支配者“公布”的關系類別為TA(轉移者),“成果”與其支配者“公布”的關系類別為YC(效應的內容),“走私”與其支配者“打擊”的關系類別為XB(作用的對象);
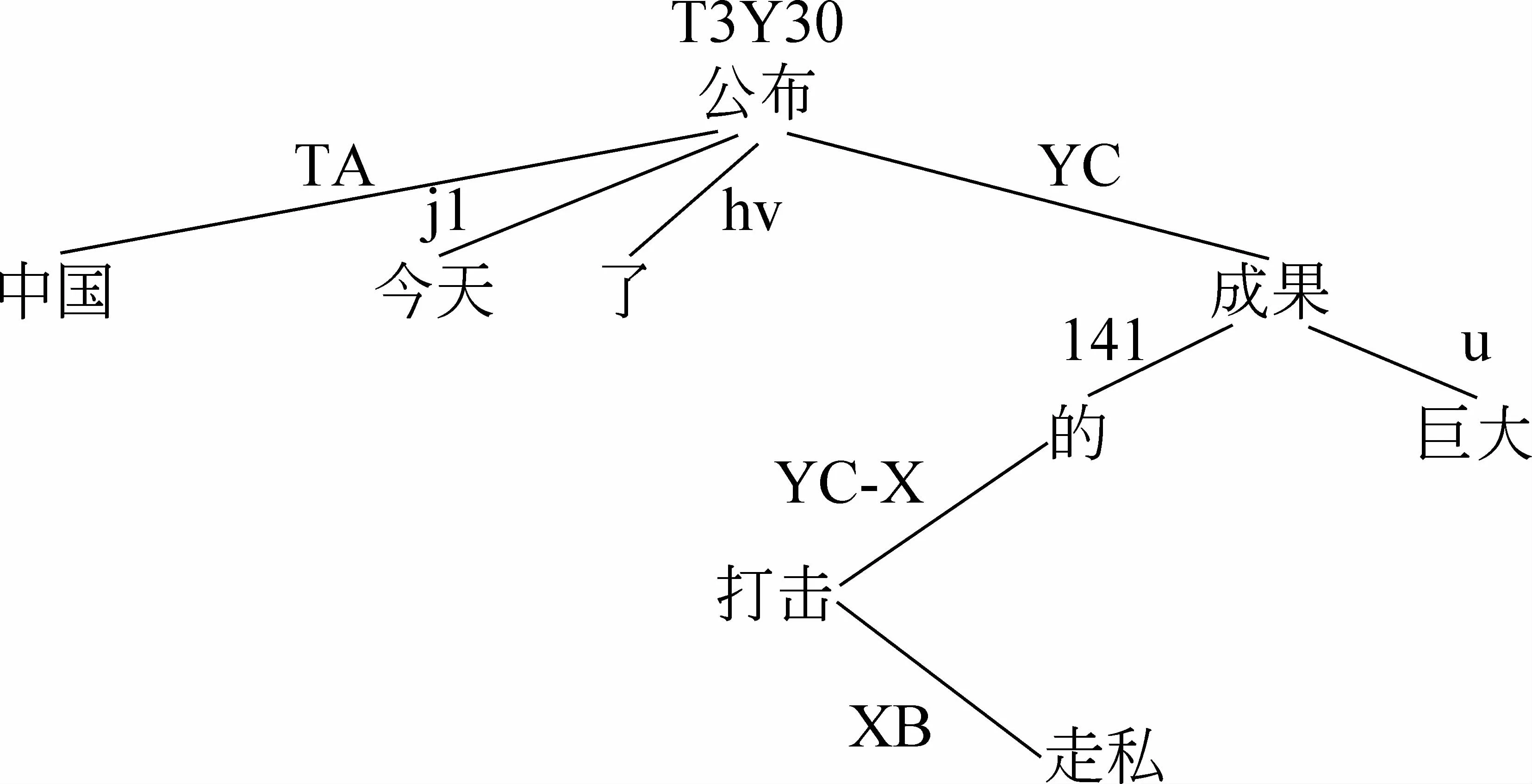
圖1 句類依存關系圖示
(2) 句類非核心成分,其與支配者的句類關系利用其本身的概念類別符號表示,一共有以下4個小類:
c) 特征語義塊Ek的復合構成,如圖1中結構助詞“了”為特征語義塊的后附加成分,也稱為Ek的下裝,關系類別用“了”本身的概念類別hv表示;
d) 時間、地點、方式、工具、參照等輔語義塊,如圖1中的“今天”、“去年”概念類別均為時間概念,其與支配者的關系類別用概念類別j1(時間)表示;
e) 語義塊核心成分的修飾性成分,包括傳統的定語及補語,如圖1中的屬性概念“巨大”,其與支配者“成果”的句類關系利用概念類別u(屬性)表示;
f) 句子的附加成分,主要包括連接詞、插入語等成分,如圖1中的結構助詞“的”,其與支配者“成果”的句類關系利用概念類別l41(語習概念l4中的一類,語義塊內部的偏正組合)表示。
3.2.3 兩個標注集的關系
正如句法分析以詞類為基礎,在句類依存樹庫的構建中,句類分析以詞的概念類別為基礎,概念類別標注集是詞語層面的標注集,句類關系標注集則為句法層面的標注集(此處的句法更偏向于語義層面)。
我們對于句子的句類依存分析基于以下假設: 漢語中詞語的概念類別決定了詞語在句類中能夠充當怎樣的句類角色(即廣義對象語義塊,如上例中的TA、XB、YC等),例如,TA類廣義對象語義塊往往是由人、物、組織機構等具有行為能力的概念來充當。因此,對于句類角色的標注必然要以概念類別為基礎;對于句子中的非句類角色成分而言,其概念類別與句類關系是一致的,因為概念類別本身就決定了其與相鄰成分間的句類關系,例如,l41類概念是指修飾關系,上例中“的”為l41類概念,“的”與“成果”之間的句類關系也正是修飾關系,因此直接用概念類別符號l41表示句類關系。
3.3 句類依存樹例釋及標注工具
在現有研究基礎上,本文利用xml語言構建了基于HNC句類理論和HNC詞語知識庫的漢語句類依存樹庫,樣例如圖2所示*本文依存樹的可視化方式基本上沿用了哈工大依存樹庫的可視化方法。。

圖2 可視化句類依存樹
句類依存樹上標注的句法和語義信息包括: 句子的句類(句子的主要語義類別)與語句格式(語義塊排列的表層順序),句子中每個詞語的概念類別,每一個詞語的父節點(支配者),詞語之間的有向弧表示了相關詞語之間的語義支配關系,有向弧上的標記表示詞語之間的句類關系。在可視化句類依存樹上僅顯示了語義支配關系及句類關系。
本研究開發了基于HNC詞語知識庫和同義詞詞林的句類依存樹輔助標注工具(圖3),在構建樹庫過程中主要采用半自動化標注方法從HNC詞語知識庫中自動查找詞語的概念類別,當有多個語義類別時人工選擇其中一個語義類別,并由標注者人工標注詞語之間的語義支配關系和句類關系。目前,HNC詞語知識庫的規模為53 000個左右詞形。為了擴展詞語知識庫,我們利用同義詞詞林進行輔助,即當在HNC詞語知識庫中無法查詢到目標詞時,自動轉入同義詞詞林中查詢,并在同義詞詞林中選擇與該詞最接近的一個同義詞重新進入HNC詞語知識庫中進行查詢,直到在HNC詞語知識庫中找到該詞為止。如果以上兩個步驟都未能查詢到目標詞,則由標注者人工判斷并手動輸入該詞的概念類別。本樹庫目前的標注規模為試驗性的2 000個漢語復雜句子,語料均為政論語體。
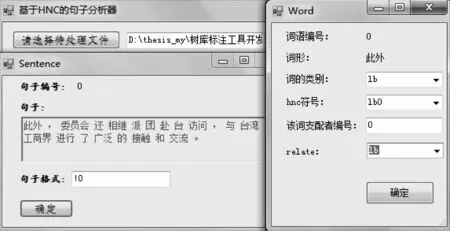
圖3 句類依存樹庫輔助標注工具
4 句類依存樹庫的特點
構建句類依存樹庫,并不是為了標新立異,本文希望這種新的樹庫模式能夠為中文信息處理提供另一種的視野和思路,在現有研究的基礎上進一步深化現代漢語句法語義的形式化分析。
4.1 特點之一: 以概念為核心來理解詞與句
漢語句類依存樹庫最大的特點是以概念為核心。首先根據概念類別對詞進行分類。郭銳指出,“詞類本質上說是詞在內在表述功能上的類別。”漢語中,詞的表述功能往往是由詞的意義決定的,意義在認知層面則體現為概念。因此我們嘗試在HNC語義網絡框架下為漢語詞匯進行概念分類,我們將詞分為11大類(共93個小類),例如,
“調查”為動態概念,記作v類概念;
“中國”為行政區劃概念,記作fpj2;
“主席”為人類概念,記作p。
其次,根據句子核心動詞的概念類別對句子進行句類分析。漢語的句子構造并不依賴于詞的功能類別體系。探求漢語句子的本質,需要以漢語詞匯的概念類別體系為基礎,對漢語的詞,特別是句子的中心動詞進行概念層面的分門別類。HNC句類分析正是基于句子核心動詞的概念類別,并綜合句子語義塊的切分對句子進行分類。
4.2 特點之二: 擅長處理漢語多動詞句
漢語多動詞句是自然語言理解與處理的難點之一,漢語動詞不帶形態標記導致計算機難以準確判斷各動詞之間的主從關系,而以往樹庫對于多動詞句的分析并沒有突出其特點,以多動詞結構“顯性輕動詞+V”為例,以往樹庫對于顯性輕動詞(如“進行”)的詞性標注或該結構的句法語義分析,都與語言事實存在較大差距,國家語委制定的“信息處理用現代漢語詞類標記集規范”[8]將“進行”類動詞處理為“形式動詞”,區別于一般動詞,符合語言學家們的判斷,但該標記集并沒有在中文信息處理領域獲得廣泛應用,而賓州樹庫將“進行”標注為VV(一般動詞),Sinica樹庫標為VC(動作及物動詞),北大樹庫標為V(一般動詞),均沒有將這類在句法和語義上有別于一般動詞的顯性輕動詞做特別標注,這必然導致該類結構的句法語義分析不夠準確。句類依存樹庫在構建過程中將重點關注漢語多動詞句的標注規范與技巧,以使之體現和保持漢語本色。
以賓州漢語樹庫為例,調查發現,賓州樹庫在“進行”句的句法分析中將“進行+V”處理為一般性的動賓結構,例如,
例3 兩岸可先就正式結束敵對狀態進行談判。
例4 該處現正就6宗較嚴重的山泥傾瀉事件進行詳細調查。(本例選自賓州漢語樹庫3.0)
在賓州漢語樹庫中,“進行談判”與“進行詳細調查”的句法分析如圖4所示。

圖4 賓州漢語樹庫對漢語顯性輕動詞結構的句法分析
這樣的分析至少存在以下兩個弊端: 首先,未將“進行”與一般動詞進行區別,無法表現出“進行”的特殊性,無法體現該類句式在語義表達上的獨特之處,即無法突出動詞性賓語的語義中心地位,這在句子的深層理解中將導致句子語義角色確認不當,并影響整個句子的語義理解;其次,“進行”后的賓語均處理為一般名詞,這顯然與語言學家們對“進行”后接謂詞性賓語這一共識相沖突。由此可見,賓州樹庫對“進行”句的處理并不完全符合語言學家們的認識,對該類句式的句法以及語義分析方法仍有待深入。
文獻[12]將“進行”類形式動詞定義為高層v概念,在詞語知識庫中利用5元組符號vv表示,“vv類概念是HNC引入的v類概念之一,它要求補充另一個v類概念,才能形成意義完備的E塊主體。[12]”HNC理論在概念表達的層面就給形式動詞賦予了特殊的地位,這一處理方式突出了“進行”類動詞在句法語義表達上的特殊性,使之區別于一般v類概念。
在句類分析層面,仍以例3“兩岸可先就正式結束敵對狀態進行談判。”為例, “vv+v”類特征語義塊,如“進行談判”,黃先生稱之為“高低搭配”,是特征語義塊核心構成的其中一種形式。這類高低搭配的語義中心在“進行”后的低位動詞v,即“談判”,句子的核心動詞由低位動詞“談判”充當而非高層概念詞“進行”,句中名詞性成分“兩岸”與低位動詞“談判”之間的語義關聯構成了整個句子的語義結構,這與語言學家們對“進行”句的認識是一致的。圖5顯示了漢語句類依存樹庫對例3的分析。

圖5 句類依存樹庫對漢語顯性輕動詞結構的句法分析
對于這類結構的分析,我們在FrameNet中找到了類似的分析思路,如例5(摘選自文獻[15])是一個英語的顯性輕動詞句。
例5 The senator paid me a compliment on my work.
Fillmore的分析思路是將動詞“pay”分析為支持動詞(support verb),整個句子的源框架來自于框架“Compliment”,而非“pay”,句中的名詞性成分“senator”、“me”及“work”分別源于框架“Compliment”的框架元素“speaker”、“addressee”及“reason”[15]。這一闡述亦可作為漢語句類依存樹庫對漢語顯性輕動詞句的分析佐證。
5 漢語句類依存樹庫的應用
句類依存樹在自然語言表征方面與以往樹庫相比,其創新之處在于加入了詞語的語義類別知識以及句子主要成分之間的句類關系知識,本節通過實例說明句類依存樹庫在漢英機器翻譯領域的應用前景。
現有機器翻譯系統采用的雙語表征方式各不相同,由此得到的翻譯模板也各有千秋,以往基于語料庫的機器翻譯方法(無論基于實例的還是基于統計的),主要使用的翻譯模板可以分為以下幾類: 基于非結構化句法的、基于短語結構樹的、基于句法依存樹的及基于語義框架或語義特征的翻譯模板幾大類。基于語言學句法的機器翻譯方法表現出了一定優勢[16],而且目前漢外機器翻譯研究方法中,“樹到串”的方法應用也較為廣泛[17],因此,本文定義的漢英翻譯模板為基于漢語句類依存樹庫的“句類依存樹到串”的語義轉換模板。
心理語言學的研究表明,人在翻譯過程中的翻譯單元(translation unit)往往并不是一個句子,而是比句子低一級的單位。在機器翻譯領域,隨著雙語對齊技術的發展深化,短語級對齊和詞語級對齊技術不斷發展完善,語塊(chunk)級的匹配單位以及語塊級的雙語轉換模板逐步成為主流。本節嘗試從經標注的漢英雙語平行語料(漢語語料標注為句類依存樹)中提取基于“句類依存子樹”[18]的雙語語義轉換模板庫,期望為漢英機器翻譯提供一種包含更多語義信息的模板。
仍以例1 “中國今天公布了去年打擊走私的巨大成果。”為例,下圖為該例在模板抽取過程中的子樹劃分圖示(圖6)。

圖6 “句類依存子樹到串”模板抽取子樹
“句類依存子樹到串”的模板抽取結果:
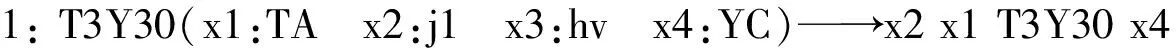
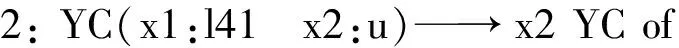
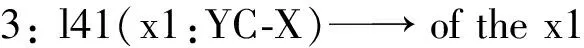

模板5~13為包含終結點的底層模板,均源于雙語串的詞級對齊信息,模板2~4為中層模板,模板1為包含根節點的高層模板。現以高層模板1為例,對其抽取過程解釋如下: 以T3Y30為支配者的子節點與T3Y30一起構成源語子樹T3Y30(x1:TA x2:j1 x3:hv x4:YC),該子樹包含一個支配節點與四個子節點x1-4,其與支配節點之間的句類關系分別為TA、j1、hv、YC。通過語料庫中的詞級對齊信息我們得到以下知識,T3Y30(公布)對齊于目標語串announced,其對應節點表示為T3Y30: announced,x1:TA(中國)節點對齊于目標語語串的單詞China,x2:j1(今天)節點對齊于目標語語串today,x3:hv(了)節點無對齊單詞,x4:YC(成果)節點對齊于目標語語串results,圖7展示了從漢英詞對齊“句類依存樹到串”詞級對齊語料中人工抽取“句類依存子樹到串”漢英轉換模板的過程。

圖7 “句類依存子樹到串”漢英轉換模板抽取
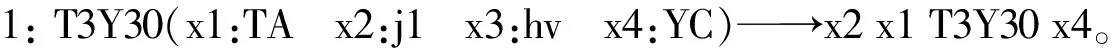
6 結語
樹庫的構建是一項非常復雜的工程,樹庫標注一方面需要標注者具備專業的理論知識以及對于現代漢語的分析能力;另一方面,標注的準確性、一致性等問題都需要重點關注。在標注的過程中,發現的問題主要集中在兩個標注集的規范上: 概念標注集中部分小的類別出現頻率太低,可以合并,其中以l類語言邏輯概念為主;部分小類如hv類概念則可以繼續細分;概念關系的標注則表現出了一定主觀性,需要進一步細化標注規范,保持整個語料庫的前后一致。另外,在模板抽取過程中,可嘗試自動抽取的方法以提高效率。
[1] 王躍龍, 姬東鴻. 漢語樹庫綜述[J]. 當代語言學, 2009,11(1): 47-55.
[2] Xue N, Xia F, Chiou F D, et al. The Penn Chinese Treebank: phrase structure annotation of a large corpus[J]. Natural Language Engineering, 2004, 10 (4): 1-30.
[3] 陳鳳儀, 蔡碧芳, 陳克健, 等. 中文句結構樹資料庫(Sinica Treebank)的構建[J]. Computational Linguistics and Chinese Language Processing, 1999, 4 (2): 87-104.
[4] 周強, 張偉, 俞士汶. 漢語樹庫的構建[J]. 中文信息學報, 1997,11(4): 42-51.
[5] 周強. 漢語句法樹庫標注體系[J]. 中文信息學報, 2004,18(4): 1-8.
[6] 靳光瑾, 肖航, 富麗,等. 現代漢語語料庫建設及深加工[J]. 語言文字應用, 2005,2:111-120.
[7] Liu T, Ma J, Li S. Building a dependency treebank for improving Chinese parser[J]. Journal of Chinese Language and Computing, 2006, 16(4): 207-224.
[8] 國家語委語言文字應用研究所計算語言學研究室. 信息處理用現代漢語詞類標記集規范[J]. 語言文字應用, 2001,3:16-20.
[9] 劉開瑛, 由麗萍. 漢語框架語義知識庫構建工程. 中文信息處理前沿進展[C]//中國中文信息學會二十五周年學術會議論文集.北京, 2006:64-71.
[10] 劉開瑛. 漢語框架語義網構建及其應用技術研究[J]. 中文信息學報, 2011,25(6):46-52.
[11] 董振東.下一站在哪里[J].中文信息學報, 2011,25(6):4-12.
[12] 黃曾陽. HNC(概念層次網絡)理論: 計算機理解自然語言的新思路[M].北京: 清華大學出版社, 1998.
[13] 苗傳江. HNC理論導論[M]. 北京: 清華大學出版社, 2005: 300-315.
[14] 張克亮, 黃曾陽. HNC作用效應句的漢英句類轉換[J]. 中文信息學報, 2003,17(5):19-26.
[15] Fillmore, C J. FrameNet and the Linking Between Semantic and Syntactic Relations[C]//Proceedings of COLING 2002, 2002.
[16] 劉群. 機器翻譯研究新進展[J]. 當代語言學, 2009(2):147-158.
[17] Liu Y, Liu Q, Lin S. Tree-to-string alignment template for statistical machine translation[C]//Proceedings of COLING/ACL 2006:609-616.
[18] Xie J, Mi H, Liu Q. A novel dependency-to-string model for statistical machine translation[C]//Proceedings of EMNLP 20112011:216-226.
Construction of Chinese Sentence-Category Dependency Treebank and Its Application
WANG Huilan1, ZHANG Keliang2
(1. Air Force Command College, Beijing 100097, China; 2. PLA University of Foreign Languages, Luoyang, Henan 471003, China)
Aimed at the application in Machine translation, this paper conducts a research on the construction of Chinese Sentence-Category Dependency Treebank (CSCDT) based on the theory of Hierarchical Network of Concepts (HNC). The conceptual category tagset and the Sentence-Category relation tagset for the treebank are presented together with the example tree of CSCDT. Compared with other Chinese treebanks, this paper discusses two advantages of CSCDT. In addition, the translation template of Sentence-Category dependency subtree to string are defined to construct translation template library for Chinese-English machine translation.
machine translation; hierarchical network of concepts; sentence-category dependency treebank

王慧蘭(1982—),博士,講師,主要研究領域為計算語言學,現代漢語語法。E?mail:hlwang9@sina.com張克亮(1964—),博士,教授,主要研究領域為計算語言學,機器翻譯,知識工程。E?mail:kliang99@sina.com
1003-0077(2015)01-0075-07
2012-04-15 定稿日期: 2012-11-19
國家社科基金(10BYY009);河南省哲學社會科學規劃一般項目(2012BYY004)
TP391
A
猜你喜歡
現代裝飾(2022年1期)2022-04-19 13:47:32
中華詩詞(2021年3期)2021-12-31 08:07:22
大連民族大學學報(2021年2期)2021-07-16 05:41:42
開放教育研究(2020年2期)2020-03-31 01:54:14
現代裝飾(2020年2期)2020-03-03 13:37:44
中學生數理化·高一版(2018年9期)2018-10-09 06:46:48
中華詩詞(2018年3期)2018-08-01 06:40:40
中華詩詞(2018年11期)2018-03-26 06:41:32
中學生數理化·高一版(2017年9期)2017-12-19 12:15:14
現代語文(2016年21期)2016-05-25 13:13:44
