高正確率的雙語語塊對齊算法研究
2015-04-25 09:56:30俞敬松王惠臨吳勝蘭
中文信息學報 2015年1期
俞敬松王惠臨,吳勝蘭
(1. 北京大學 信息管理系,北京 100871;2. 中國科學技術信息研究所,北京 100038;3. 北京大學 軟件與微電子學院,北京 100871)
?
高正確率的雙語語塊對齊算法研究
俞敬松1,3王惠臨2,吳勝蘭3
(1. 北京大學 信息管理系,北京 100871;2. 中國科學技術信息研究所,北京 100038;3. 北京大學 軟件與微電子學院,北京 100871)
高質(zhì)量的自動對齊雙語語塊,對于機器翻譯系統(tǒng),特別是計算機輔助翻譯系統(tǒng)的性能提高有重要作用,而且對于人工翻譯以及辭典編纂也都有巨大的應用價值。該文提出基于單詞間粘合度與松弛度的語塊劃分評分方法以及雙語語塊劃分的雙向約束算法,使得源語言和目標語言的語塊的劃分與對齊能相互促進。與傳統(tǒng)方法相比,因為無需事先進行雙語語塊劃分,而是在搜索最佳對齊時動態(tài)地考察劃分效果,故可以減少邊界劃分錯誤對對齊結果的影響。該算法獲得了遠超過傳統(tǒng)算法的高正確率。
語塊對齊;機器翻譯;平行文本;雙語對齊
1 概述
英語語塊(chunk)的概念最早由Abney[1]提出,代表句子的非遞歸核心成分,具有句法相關性和不可嵌套性。周強等[2]提出的漢語句子組塊分析體系可能是最早的關于漢語語塊的研究。對齊的雙語語塊是在機器翻譯研究工作中發(fā)展起來的語塊擴展形式,程葳等[3]認為雙語語塊有同樣的語義,在翻譯上可以互相轉(zhuǎn)換。
雙語語塊對齊任務可以描述為: 給定輸入雙語句子,自動進行語塊劃分并按語義對齊。目前多數(shù)算法都是基于統(tǒng)計方法的,輸出的對齊概率結果面向機器翻譯,人工無法解讀。
語塊對齊工作缺乏標準規(guī)范[4],也沒有公開的大規(guī)模的標準訓練和評測數(shù)據(jù)。單語語塊都很難嚴謹定義,雙語環(huán)境中更難。我們認為語塊劃分要兼顧對齊。從根本來說,語言現(xiàn)象的復雜性是最大的困擾。翻譯過程中存在的大量省譯、增譯、語序調(diào)整、意譯、兼類、指代等現(xiàn)象加大了雙語對齊難度。
我們提出的高質(zhì)量語塊互譯對齊,要求系統(tǒng)輸出的是人可辨識的有意義結果。譯員們獲得的是來自計算機的準確的有意義的提示,降低專業(yè)譯員們的認知負擔。在本篇論文中判定是否是語塊,除了形式化規(guī)則外,主要以人的主觀判定為依據(jù):首先語塊必須有明確的意義;其次在其他語句中可以重復使用。符合這兩條就認為語塊劃分且對齊正確,沒有遵從任何預定義的語法體系。這一點上,本文與其他論文有較大的不同。
本文工作服務于交互式機器翻譯等場合[5]: 當人類譯員在輸入完成一個句子的時候,系統(tǒng)依據(jù)原文、機器翻譯的假設及概率、目標語言模型等進行可能的提示,譯員可判斷接受從而加速正確譯文的產(chǎn)出速度。這里的譯文是人的工作成果,與機器翻譯沒有可比性。高質(zhì)量雙語語塊庫作為語言資源之一加入模型體系中,提高譯員接受猜測的概率。側(cè)重高正確率的算法將依賴更大規(guī)模的語料來保證召回。
高質(zhì)量語塊對齊結果對于機器翻譯系統(tǒng)來說也是高價值資源。基于短語的機器翻譯系統(tǒng)中,過長的句子由于訓練時間太耗時而常常被丟棄,利用高質(zhì)量對齊語塊將長句子“拆解”為較短的互譯片段可減少訓練時間并充分利用語料。本文的語塊對齊工作具有語言中立性。
關于語塊的研究早期多使用規(guī)則方法。呂學強等[6-7]總結了鏈語法的連接因子和E-Chunk的對應關系;劉冬明等[8]在實詞對齊的基礎上劃分語塊;屈剛[9]嘗試了基于句法深層結構翻譯不變性的翻譯等價對抽取;Macken[10]的工作則利用了短語構成的語言學知識。近期則是統(tǒng)計方法占主流。姜柄圭等[11]是統(tǒng)計方法為基礎,綜合運用規(guī)則方法抽取語塊;劉海霞等[12]將既有的語義資源引入計算過程中;諾明花等[13-14]針對漢藏翻譯中藏語語料庫規(guī)模小,giza++對齊結果不可靠的情況進行了探索;Deng[15]提出了語塊對齊的生成模型,本文的工作與之公布的MTTK開源系統(tǒng)進行了對比;Liu等[16]使用PLSI技術計算雙語語塊相似度;Zhao[17]嘗試了基于譜聚類的雙語詞聚類,并基于隱概念流的思想提出了翻譯等價對同步生成的圖模型;Ma[18]使用了將若干連續(xù)的詞打包成一個詞后反復迭代的方法;Kim[19]將對數(shù)線性模型框架應用到了語塊對齊任務。
本文在分析和總結前人工作的基礎上,創(chuàng)新提出了粘合度與松弛度的概念,分別衡量語塊劃分時單詞間連接緊密程度和松散程度,針對語塊劃分及對齊提出了多種平行的計算模型及融合算法,并進一步提出了語塊對齊時的搜索及擴展算法。
2 語塊切分的數(shù)學模型的建立
2.1 語塊評分方法
給定一個由N個詞組成的句子S=w1w2…wi…wN-1wN,將相鄰詞對wiwi+1之間的間隙記作切分點gi,其取值1、0分別代表劃分語塊時在該處是否切開。于是,我們可以使用切分點的取值序列G=g1g2…gi…gN-2gN-1代表語塊劃分。本文為每個切分點gi設置粘合度與松弛度兩個屬性(取值均為正整數(shù)): 粘合度代表wiwi+1之間的連接緊密程度,記作ai,值越大代表連接越緊密;相反地,松弛度代表相鄰詞對wiwi+1之間的連接的松弛程度,記作ri,值越大代表連接越不緊密。假設已知wiwi+1之間粘合度ai和松弛度ri,語塊劃分時在切分點gi處應該切開的概率近似為式(1)。
若切分點gi處不應該切開,即wiwi+1被劃分到同一個語塊中的概率近似為式(2)。
請注意一點,黏合度和松弛度是獨立計算的。不同的計算模型有不同訴求,可能對兩者的計算都有貢獻,也可能只對其中之一有幫助。對句子經(jīng)過語塊劃分后,形成若干語塊。對于一個包含M個單詞的語塊C=wi+1wi+2…wi+m…wi+M-1wi+M,其左側(cè)和右側(cè)的切分點gi和gi+M取值為1,而內(nèi)部所有切分點取值為0,本文使用式(3)來給C在語塊劃分結果中的好壞程度評分:

2.2 黏合度與松弛度計算方法
本文使用了多種模型分別計算黏合度和松弛度,包括多種自然語言問題的研究成果,例如,依存句法分析,特定成分識別(如時間表達、命名實體)等,其中雙語劃分鏡面約束是利用GIZA++詞語對齊結果矩陣讓互譯句子對的語塊劃分互相約束、互相促進,這是其他人的工作中沒有討論過的創(chuàng)新做法。
由于每一種特征模型都可以給出每一個詞間切分點gi黏合度和松馳度,由此構成了一個巨大的狀態(tài)空間,我們的任務就變成了對每種特征權重進行尋優(yōu),然后進行融合。在本文工作中,判定經(jīng)驗公式定義的合理與否及取值方法,還有不同影響因素之間的權重關系,均主要靠參數(shù)尋優(yōu)過程來解決。
以命名實體識別特征模型為例,假如句子S內(nèi)部有包含M個單詞的連續(xù)單詞串wiwi+1…wi+M-2wi+M-1構成一個命名實體,如人名、地名、機構名等,使用公式(4)計算受影響的各個切分點的黏合度,ai,λ,θ為比例因子。
其中WNE為命名實體權重,使用公式(5)計算各個切分點的松弛度ri。
r′k=rk+WNE·θ,
2.3 語塊劃分評分方法
假設包含N個單詞的句子S經(jīng)過語塊劃分(用G表示)得到了K(1≤K≤N)個語塊S=C1C2…Ck…CK-1CK,使用公式(6)評估語塊劃分G的好壞程度。

2.4 語塊互譯對相似度計算方法
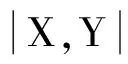


2.5 語塊對齊表示方法
給定源語言句子S和目標語言句子T,假設對S和T完成了語塊劃分和對齊后,S由K個語塊組成,用X1X2…Xk…XK-1XK表示,其中Xk代表S的第k個語塊,T由L個語塊組成,用Y1Y2…Yl…YL-1YL表示,其中Yl代表T的第l個語塊。語塊對齊結果可以用一個目標語塊偏移向量A=A1A2…Ak…AK-1AK來表示,向量的長度與源語言語塊個數(shù)相同,并滿足:
1. 如果第k個源語言語塊有對應的目標語言語塊,則Ak代表第k個源語言語塊與第Ak個目標語言語塊對齊。
2. 如果第k個源語言語塊沒有對應的目標語言語塊,則約定Ak=0。
3. 如果第l個目標語言語塊沒有對應的源語言語塊,則l的值不應該出現(xiàn)在對齊向量所有元素的取值集合中,即l?{Ak|1≤k≤K}。
圖1為一個使用目標語塊偏移向量A來表示語塊對齊結果的例子。

圖1 一個用語塊偏移向量表示語塊對齊的例子
上圖中,橫坐標從左到右為源語言詞序列,縱坐標自上而下為目標語言詞序列,粗線條形成的單元格劃分語塊序列X1,X2,…,X8以及Y1,Y2,…,Y7。最下面的一行單元格代表目標語塊偏移向量A1,A2,…,A8,取值代表對齊,A6=0代表該列上的語塊沒有譯文語塊。我們研發(fā)了專門的Excel程序,以圖1為模版輔助語料的人工標注及修改以及對齊數(shù)據(jù)的自動回收和展示,其標注效率和用戶親和程度超過其他方案。
2.6 語塊對齊評分方法
在源語言句子S和目標語言句子T的語塊劃分分別是GS、GT的情況下,將語塊對齊用目標語塊偏移向量 A 表示,本文使用公式(10)計算語塊對齊A的分數(shù)。

由于本文將語塊劃分與對齊當整體考慮,故將劃分與對齊的綜合評分函數(shù)定義為源語言劃分分數(shù)、目標語言劃分分數(shù)、二者對齊分數(shù)的乘積,如式(11)所示。
3 搜索尋優(yōu)算法
本文提出語塊對齊搜索算法關鍵數(shù)據(jù)結構是一個限長N-Best列表,列表的每一項用以存儲當前劃分GS、GT,當前對齊A,以及劃分與對齊總分數(shù)FAll。 向N-Best列表插入新的元素時,新插入的元素自動按照總分數(shù)FAll排序,列表飽和時,排名最靠后的元素則被自動剔除。算法流程如下:
1. 構造初始對齊對(3.1節(jié)),計算其總分數(shù),插入N-Best列表;
2. 隨機選取出候選對齊,修改候選對齊(3.2節(jié)),計算新對齊與候選對齊之間的總分數(shù)增益;
3. 若增益大于0,則將新的對齊也插入N-Best列表;
4. 若不滿足終止條件,轉(zhuǎn)到第2步。
算法設置的默認N-Best列表長度為10 000,默認的終止條件為了N-Best列表前三名總分數(shù)的平均值連續(xù)1 000次不變。新對齊與候選對齊之間的總分數(shù)增益定義為式(12)。
其中A′,G′S,G′T,K′,L′分別為修改對齊后形成
的新的對齊、新的源語言語塊劃分、新的目標語言語塊劃分、新的源語言語塊個數(shù),新的目標語言語塊個數(shù)。
3.1 構造初始對齊
GIZA++詞語對齊工具*http://www.statmt.org/moses/giza/GIZA++.html能產(chǎn)生兩個方向詞語對齊結果,對稱化處理可以得到合并的詞語對齊結果。但在本文工作的語境下, 我們期望的是在正確的前提下得到更長的對齊對。圖2帶有“@”符號的單元格矩陣為GIZA++詞語對齊結果。

圖2 使用Excel 作為語塊對齊的人工標注和結果檢查交互界面
詞語對齊矩陣中所有的實詞(主要包括名詞、動詞、形容詞)暫可看作互譯語塊,所有剩余單詞看作翻譯為空的語塊。初始對齊從GIZA++詞語對齊開始,放棄了句子對中意譯對齊語塊帶來的計算量和搜索空間,提高了搜索速度,但代價則是包含意譯現(xiàn)象過多的實例中受GIZA++詞語對齊錯誤影響較大。
本文利用以下規(guī)則對不滿足語塊對齊要求的部分進行沖突消解處理,提高初始語塊對齊質(zhì)量:
1. 詞語對齊矩陣中的詞在水平或者垂直方向上連續(xù)多個對齊時,例如,“assault on”、“exchange rate”,則將其綁定為語塊,否則,每個單獨的詞語獨立看待,沒有對應的則對空。
2. 對齊沖突時,分別嘗試當前源語塊與每個目標語塊對應,保留相似度最高者,刪除的語塊看做空譯語塊。本例中“的”與“the”的詞語對齊關系被刪除,最終“the”構成空譯語塊,“的”與 “of an”構成互譯對。
3. 對齊矩陣中詞對齊單元格形成“+”形、“T”形、“L”形或更復雜的連通區(qū)域時綁定對齊,例如,“越來越 充分”與“are increasingly convincing”的詞語對齊信息構成“L”形,可構成對齊。
4. 反復重復上述過程,直到不存在沖突。
3.2 修改與擴展候選對齊
在以上計算結果的基礎上,首先利用相鄰詞擴展互譯語塊,其次合并相鄰互譯語塊。相鄰詞擴展時,從互譯語塊的邊界出發(fā),向相鄰的八個方向擴展,如圖3所示。
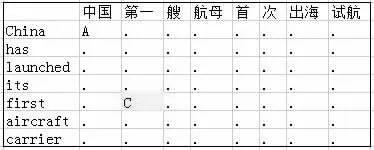
圖3 選取互譯語塊示例
其中“第一”和“first”是一對可以通過查詢詞典得到的互譯實詞,初始候選已對齊,其擴展方式有8種如圖4。如某方向上有屬于其他互譯語塊的詞,則放棄擴展。合并相鄰互譯語塊的方法為隨機選擇兩個相鄰的互譯語塊,將二者以及夾在二者之間空譯語塊合并,如圖5所示。

圖4 互譯語塊向周圍八個方向擴展示例
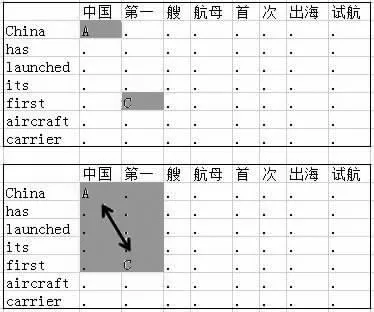
圖5 隨機合并兩個相鄰互譯語塊示例
3.3 減小搜索空間的剪枝策略
為了減小搜索開銷,本文進行狀態(tài)空間剪枝:
1. 設置合適的N-Best列表長度,利用N-Best列表自動刪除最差元素的機制過濾;
2. 針對每個候選對齊計算hash,避免重復處理同一個候選對齊;
3. 根據(jù)源語言和目標語言句子長度估算出各自的可能語塊個數(shù),約束狀態(tài)擴展的進程;
4. 包含標點符號的語塊一般不再與任何語塊合并;
5. 優(yōu)先選擇所有候選中增益最大的互譯語塊以及相應的方向進行擴展;
6. 如果每個方向的增益都小于0,則做標記及下次不再選擇。
4 基于人工標注語料庫的權重參數(shù)優(yōu)化方法
多種特征模型分別給出了對切分點gi的黏合度和松弛度的獨立貢獻,融合這些模型需要確定對應的權重參數(shù)。我們在人工標注語料庫上均勻抽取102個句子對,作為訓練集,試圖找出一組局部最優(yōu)的權重參數(shù)來優(yōu)化語塊劃分的評分值:
(1) 根據(jù)經(jīng)驗構造一個初始參數(shù)集合,用參數(shù)序列W=W1W2…WN表示,并用另一個N-Best自動排序列表存放最多10 000個最佳參數(shù)集合。
(2) 利用本文提出的方法計算小規(guī)模人工標注的訓練集的劃分分數(shù)的平均值,將初始參數(shù)序列W以及對應的平均分數(shù)插入N-Best列表。
(3) 從N-Best列表隨機選擇一組參數(shù),并記錄這一組參數(shù)在列表中的排名Rank,隨機選擇其中的一個參數(shù)進行一定幅度的變化,變化的幅度與Rank呈正相關。即如果這組參數(shù)距離N-Best列表的第一名越近,則變化的幅度越小(在局部最優(yōu)解附近尋優(yōu)),否則,變化的幅度越大(放棄當前解,跳躍到一個新的解)。
(4) 在變化后的參數(shù)集合W′的基礎上計算小規(guī)模人工標注的訓練集的平均劃分分數(shù)和對齊總分數(shù),并插入到N-Best列表。
(5) 反復重復步驟(3)、(4),直到N-Best列表的前3名的平均分數(shù)連續(xù)若干次不變。
5 實驗結果與分析

高質(zhì)量語塊互譯對抽取實驗以及與其他工作的對比實驗則是在包含150萬句對的訓練語料及 1 000句對的開放測試集上完成的。正確率評測時,從抽取結果中去重后隨機采樣5%由封閉語料的標注員依照同樣標準審核,其判定標準是: 短語必須人工可辨識(有意義);在翻譯其他句子上下文中可復用。表1顯示互譯語塊相似度閾值對結果的影響。

表1 1 000句對開放測試集正確率抽樣評測結果
從表1可以看出,隨著閾值的提高,抽取結果的正確率逐漸提高,抽取規(guī)模逐漸降低。當閾值設置為-10時,正確率達到了我們認為在計算機輔助翻譯應用領域內(nèi)可以接受的水平。
本文的工作成果與詞到短語對齊工具MTTK*http://mi.eng.cam.ac.uk/~wjb31/distrib/mttkv1/[15],以及著名開源機器翻譯系統(tǒng)MOSES*http://www.statmt.org/moses/生成的短語表進行了對比。
MTTK訓練后得到的中文到英文、英文到中文的詞到短語對齊結果。GIZA++訓練得到雙向詞到詞對齊結果,利用MOSES提供的腳本工具進行對稱化及短語抽取,對稱化算法使用默認設置grow-diag-final-and,最大短語長度設置為3。MTTK、MOSES以及本文輸出結果列在表2中。

表2 使用MTTK、MOSES以及本文算法在1 000句對開放集上的互譯對抽取結果統(tǒng)計
結果中MTTK互譯對最多,本文最少。本文獨有0∶N和N∶0模式的空對齊對;1∶1模式基本上是詞語對齊,本文比GIZA++少是因為語塊合并等因素; 723個語塊長度大于4的對齊對是語塊擴展策略做出的獨有貢獻。
將本文算法與其他方法對比,主要比較了2∶2模式語塊對,去重后以10%的采樣率進行隨機采樣后再加人工判定,結果如表3所示。

表3 本文與其他研究工作2∶2模式對齊的短語對比
反向估計代表的是根據(jù)正確率和過濾后的互譯對數(shù),估算出過濾后的互譯對中正確互譯對的數(shù)目,3種方法大致相同,由此也可證明本文工作的正確性。
雖然MTTK和MOSES總抽取的互譯對數(shù)目遠超過本文工作,但正確率較低。實驗結果表明本文算法抽取結果少而精,以犧牲召回率為代價提高了準確率。
我們相信,考慮到譯員的認知負擔的問題,對于實際翻譯任務來說,本文的工作對譯員的幫助更大,因為過多的雜亂結果會干擾他們的思考。
6 總結
本文的工作存在一些缺點和不足: 首先是沒有考慮跨越多個詞的搭配,也不允許嵌套,認為語塊只是連續(xù)的單詞片段,這是有缺陷的。語塊相似度計算函數(shù)目前還比較簡單,嘗試利用詞性、GIZA++產(chǎn)生的詞類信息等或可得到更好結果。
本文從GIZA++詞語對齊作為工作起點,但是語塊劃分與詞語對齊似乎依然可以做到相互促進,引文語塊對齊可以幫助縮小詞語對齊的邊界,而高質(zhì)量的詞語對齊也是產(chǎn)生高質(zhì)量語塊對齊的先決條件。這一點還需要進一步的實證研究。
附注: 本文的語塊對齊部分成果,10萬條語塊對齊庫已經(jīng)在數(shù)據(jù)堂網(wǎng)站免費公開,有需要者可以自行下載使用。(http://www.datatang.com/data/46112)公布的數(shù)據(jù)是對齊程序的直接輸出結果,沒有再進行其他加工處理。
[1] Abney Steven. "Statistical methods and linguistics."[J]. The balancing act: Combiningsymbolic and statistical approaches to language.1996: 1-26.
[2] 周強,孫茂松,黃昌寧. 漢語句子的組塊分析體系[J]. 計算機學報,1999,22(11):1158-1165.
[3] 程葳,趙軍,徐波,等. 一種面向漢英口語翻譯的雙語語塊處理方法[J]. 中文信息學報,2003,17(2):21-27.
[4] 李業(yè)剛,黃河燕. 漢語組塊分析研究綜述[J]. 中文信息學報,2013,27(3):1-8.
[5] Ortiz-Martínez D, Leiva L A, Alabau V, et al. Inter-active machine translation using a web-based architecture[C]//Proceedings of the 15th international conference on intelligent user interfaces. ACM, 2010: 423-424.
[6] 呂學強,李清隱,任飛亮,等. 基于統(tǒng)計的漢英法律文獻亞句子級對齊[J]. 東北大學學報,2003,24(1):23-26.
[7] 呂學強,陳文亮,姚天順. 基于連接文法的雙語E-Chunk獲取方法[J]. 東北大學學報,2002,23(9):829-832.
[8] 劉冬明,楊爾弘. 一種新的雙語語塊對應算法[J]. 電腦開發(fā)與應用,2004,17(3):2-3.
[9] 屈剛. 英漢雙語短語對齊[D].上海交通大學,2007.
[10] Macken Lieve. Sub-sentential alignment of translational correspondences[D]. Ghent University, 2010.
[11] 姜柄圭,張秦龍,諶貽榮,等. 面向機器輔助翻譯的漢語語塊自動抽取研究[J].中文信息學報, 2007,21(1):9-16.
[12] 劉海霞,黃德根. 語義信息與CRF結合的漢語功能塊自動識別[J]. 中文信息學報,2011,25(5):53-59.
[13] 諾明花,張立強,劉匯丹,等. 漢藏短語抽取[J]. 中文信息學報,2011,25(1):105-110.
[14] 諾明花,吳健,劉匯丹,等. 漢藏短語對抽取中短語譯文獲取方法研究[J]. 中文信息學報,2011,25(3):112-117.
[15] Deng Yonggang. Bitext alignment for statistical machine translation[D]. Johns Hopkins University, 2006.
[16] Liu Feifan, et al. Bilingual chunk alignment based on interactional matching and probabilistic latent semantic indexing[J]. Natural Language Processing IJCNLP 2004. Springer Berlin Heidelberg, 2005: 416-425.
[17] Zhao Bing. Statistical alignment models for translational equivalence[D]. Carnegie Mellon University, 2007.
[18] Ma Yanjun, Nicolas Stroppa, Andy Way. Bootstrapping word alignment via word packing[J]. Annual Meeting-Association for Computational Linguistics. 2007,45(1):304-311.
[19] Kim Jae Dong. Chunk alignment for Corpus-Based Machine Translation[D]. Carnegie Mellon University, 2012.
A Bilingual Chunk Alignment Algorithm for Computer Aided Translation
YU Jingsong1,3, WANG Huilin2, WU Shenglan3
(1. Department of Information Management, Peking University, Beijing 100871;2. Institute of Scientific and Technical Information of China, Peking University, Beijing 100038;3. School of Software and Microelectronics, Peking University, Beijing 100871)
Automatic Bilingual Chunk Alignment has important application value for Machine Translation, Computer Aided Translation and other fields. In this paper, a Chunk Partition Scoring method is proposed based on the Degree of Adhesion and the Degree of Relaxation to make the chunk partition of source language and target language benefit each other. A novel bilingual chunk alignment algorithm is proposed. Compared with previouswork, this algorithm does not require bilingual chunk partitions, however, the chunk partition score is dynamically calculated during alignment searching. The importance of precision is far beyond recall of this approach.
chunk alignment; machine translation; parallel corpus; bitext alignment

俞敬松(1971-),博士研究生,碩士,副教授,主要研究領域為自然語言處理、計算機輔助翻譯、教育技術等。E?mail:yjs@ss.pku.edu.cn王惠臨(1948—),博士生導師,博士,主要研究領域為信息管理、機器翻譯、自然語言處理等。E?mail:wanghl@istic.a(chǎn)c.cn吳勝蘭(1987—),碩士,主要研究領域為自然語言處理、購物商品推薦等。E?mail:wslgb2010@qq.com
1003-0077(2015)01-0067-08
2014-04-28 定稿日期: 2014-06-16
TP391
A
