湘西農副產品網絡平臺系統持久層的設計
2015-05-30 13:22:14段強
中國新通信 2015年24期
段強
湘西農副產品網絡平臺這個項目初期是作為一個中小型的垂直行業電子商務平臺而進行設計的,但是在項目的設計需求中明確提出了要考慮到日后要能方便升級為大型的網絡平臺,同時在系統架構的概念性設計中也特別關注了這個問題。因此后續的開發工作中,在對數據層的設計上,我們細化出了一個在數據庫層之上的一個持久層來處理。
一、為何選用持久層
持久層是實現數據持久化的一個邏輯上的層次。數據持久化就是對系統中的數據固化到硬盤等物理存儲器中的一個過程。最大眾化的情況,就是通過某些程序設計語言把從軟件界面取得的數據保存到數據庫中的一個過程。
使用數據庫對數據進行管理,效率最高的方法就是直接使用SQL語句。但是在主流的OOP編程語言平臺中,都不可避免地會把SQL語言和編程語言混雜在一起,即使程序員經過了精心設計,也依舊如此。本項目計劃使用JAVA作為開發平臺,同樣面臨相同的情況。但是這樣的做法,在提高了軟件效率的同時,卻犧牲了軟件的可修改性,尤其是在數據庫層更新為大型數據庫或分布式數據庫時,需要重新編寫的代碼將不亞于重新開發所需要的代碼量。
二、如何設計持久層
在使用JAVA開發的軟項目中,其業務對象大體上可以分成普通的Java對象和持久對象。普通的Java對象用于控制、邏輯處理等業務,而持久對象則用于對數據庫中的數據實體進行映射。從功能上說,如果要在數據庫中插入一條記錄,則大致等同于將一個持久對象進行初始化,而在數據庫中刪除一條記錄,則等同于將這個持久對象賦值為NULL,且清理內存。可以說,數據持久化之后的結果是數據庫中存在真實的數據記錄,而數據持久層中的數據則是存儲在可掉電設備(例如內存)中的對應數據庫中數據的一些映射。
在代碼編寫階段,最原始的使用持久層的技術就是一些簡單的代碼編寫工作,但是在企業級的開發中,就必須將對象-關系的映射(Object-Relation Mapping,ORM)框架與持久層的開發結合起來考慮了。
在本系統的設計中,出于對高可修改性的需求的滿足來考慮,我們對數據的處理采取了以下幾個步驟:1、使用DAO設計模式將底層的數據庫訪問和高層的業務邏輯分離,利用DAO模式提供的接口實現對數據庫的查詢、刪除等操作;2、采用工廠方法(Factory Method)設計模式設計類和接口,并實現系統接口來實現底層對象的訪問;3、充分利用面向對象程序設計中的繼承的概念,設計各種持久對象的子類,以便方便地將數據庫中的各種表中的記錄轉換為各種值對象來訪問。
就目前預期的系統使用而言,以上3個步驟的設計和實現完全依靠手工編寫代碼是綽綽有余了。可是倘若本軟件系統日后的數據庫處理需求升級或功能需求進行了拓展后,我們將無法避免DAO模式中對于1對多(1:N)關系處理的弊端:對于1:N關系的持久對象的查詢隨著數據的拓展變成了1+N次SQL語句的執行,直接導致代碼的出現大量的重復執行,最終將導致系統可修改性完全喪失。這就不得不讓我們選擇一個較為可行的開發框架作為我們數據持久層設計的基礎,其目的在于提高系統的可修改性。最終我們選定Hibernate作為本軟件系統持久層開發工具。
Hibernate的工作機制如圖1所示。使用Hibernate之后,編寫在業務邏輯層中的代碼通過Hibernate提供的API來操作數據這對代碼的編寫工作來說是相當有利的。下面以用戶基本信息表中的部分信息為例,概要闡述如何應用Hibernate設計一個持久化類,然后使用這個類的任意實例完成對應的任務。創建最終用戶信息的持久化類時,該類的屬性必須與數據庫中表的字段存在1:1的映射關系,還需要設置一個類似print()方法作為輸出的接口。在本例中,類的類圖如圖2所示。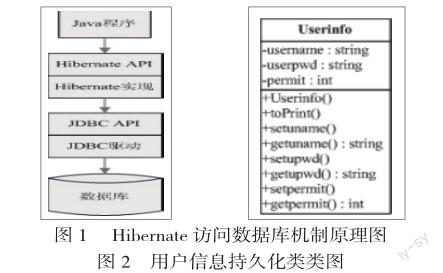
類的設計完成后,需要在的是將數據庫中的表與這個類的對象產生聯系。為了實現這個目標,只需要編寫一個映射文件以實現數據庫中的數據和類的映射。之后繼續完成Hibernate的配置文件hibernate.cfg.xml中相應的內容即可。接下來是編寫Hibernate的配置文件hibernate.cfg.xml。該文件的部分內容如表5.2所示。
三、如何應用持久層的設計
在完成了以數據持久層的配置和設計工作以后,就可以專注于在建邏輯層中設計不同的類來實現各種功能了。例如,如果設計用戶注冊功能的類,其核心代碼如表1所示。
小結:數據持久層的設計及其實現是有關系統效率、安全和可修改性等一系列質量屬性優劣與否的重要工作。在軟件架構的概念設計中需要考慮這個問題,在軟件架構的實際設計中需要在技術選型、開發平臺等技術細節中對此設計予以實現。但是這仍然是粗粒度的設計,但是已經可以為具體完成代碼編寫的工作人員提供開發依據了。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
裝備制造技術(2021年1期)2021-05-21 07:55:08
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
福建基礎教育研究(2019年6期)2019-05-28 17:48:32
家庭影院技術(2017年9期)2017-09-26 03:41:45
人大建設(2017年11期)2017-04-20 08:22:46
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
