一種面向混合數據的模糊等價關系構造約簡*
2015-06-22 15:09:17宋婷
網絡安全與數據管理 2015年9期
關鍵詞:方法
宋婷
(太原科技大學計算機科學與技術學院,山西太原030024)
一種面向混合數據的模糊等價關系構造約簡*
宋婷
(太原科技大學計算機科學與技術學院,山西太原030024)
基于模糊粗糙集模型構建模糊等價關系是混合數據分析的有效方法之一。針對屬性類別多樣性的混合型信息系統,提出一種帶權的對象間相似性度量方法,該方法建立每類屬性對應的相似性度量函數,再通過歸并確立帶權的模糊相似矩陣。在轉化為模糊等價關系的基礎上,采用加入蘊含專家領域知識及用戶需求的約簡算法。通過數據庫中幾個數據集樣本對屬性約簡后的數目、精度進行對比,驗證了方法的有效性和可行性。
模糊粗糙集模型;模糊等價關系;混合數據;模糊相似矩陣;約簡
0 引言
粗糙集理論是一種以精確的數學形式處理不確定信息的數學工具,屬性約簡在保持分類能力不變的前提下獲得最小特征子集,是粗糙集理論的核心應用之一。經典粗糙集理論[1-3]通常是處理只包含符號型屬性的數據模型,而實際的信息系統中屬性和決策的值域是多樣性的,有符號型屬性,也有連續數值型屬性,即混合分類數據。對于混合數據的處理大體可分為兩類:一類是離散化方法[4],將數值型屬性轉化為符號型屬性的數據形式,即在數值屬性值域中選擇合適的分割點,劃分成若干由字符標記的不同區域,從而將不同類別屬性轉化為統一的數據形式再進行約簡。如何選擇分割點引出了離散化方法的系統分析比較[5],討論的關鍵在于分割點數量和位置的設計,缺點在于產生了量化誤差,丟失了同種符號表示的區域內不同屬性值間的序信息。另一類是對不可分辨關系進行拓展的混合型方法。Hall提出了利用信息熵計算符號變量相關性的特征選擇方法[6],Zhou和Qian提出了采用定性信息分解復雜問題的決策樹構造方法[7],以及之后提出的混合數據特征選擇的方法[8],缺點都是將符號型屬性和數值型屬性割裂開分析,丟失了分類能力較強的數值屬性信息。Kwak和Choi、Peng等人陸續采用Parzen窗方法計算數值型樣本概率密度來進行特征選擇[9],取得了一定進展。Zadeh提出了模糊集理論[10],認為模糊信息粒化在知識發現過程中極其重要,模糊粗糙集和粗糙模糊集概念的提出,融合了模糊粒化和粗糙逼近兩種不確定方法[11-15],使得約簡結果能更清晰地體現信息系統的分類能力。Hu采用信息熵的概念度量信息系統的分類能力,在混合數據的處理過程中,得到的對象間相似矩陣數值單一,且整合符號型和數值型屬性的過程中丟失很多分類信息[16]。遺傳算法應用于混合數據約簡的方法,由于本身算法的特點導致計算量大、耗時長[17-18]。
本文重點研究在模糊粗糙集模型框架下如何定義混合數據間帶權的相似性度量方法及模糊等價關系,通過定義不同類別屬性對應的相似性度量函數,以及帶權的模糊相似矩陣,最終確定模糊等價關系;之后通過加入領域專家的經驗知識和系統客戶的需求偏好對數據進行約簡,將約簡后的屬性數目、精度與其他方法的數據進行對比,以驗證方法的有效性和可行性。
1 模糊等價關系及其度量
針對符號型變量的處理,可以利用粗糙集在等價關系的基礎上建立對象間關系。但對于數值型變量,等價關系不足以清晰地刻畫對象間關系,需要借助模糊等價關系的概念。
給定信息系統S=(U,A),論域U={x1,x2,…,xn},屬性集合A=C∪D是條件屬性和決策屬性的集合,且C∩D=?。本文討論的混合信息系統的屬性集合既有條件屬性,也有數值屬性。
定義1:給定一個矩陣A=(aij)n×n,若對?i,j=1,2,…,n,滿足:(1)自反性:aii=1;(2)對稱性:aij=aji;(3)模糊性:aij∈[0,1];(4)傳遞性:aij≥∨k(aik∧akj),則稱矩陣A為模糊等價矩陣。
在以下論述中,用M(R)=(rij)n×n來表示二元關系R的關系矩陣,其中R滿足模糊等價關系。
定義2[16]:R是U上的模糊等價關系,定義R的信息量的模糊等價類。
定義3[16]:給定兩個模糊等價關系B和E,對應的模糊等價類為[xi]B和[xi]E,則B和E的聯合熵定義為:
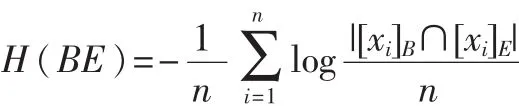
條件熵定義為:
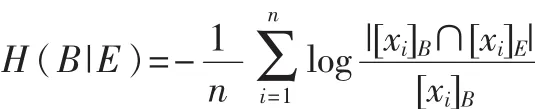
定義4[16]:給定模糊信息系統<U,A,V,f>,A=C∪d,B?C,若H(d|B-a)=H(d|B),則屬性a是冗余的,若H(d|B-a)>H(d|B),則B是獨立的。若滿足:(1)H(d| B)=H(d|A);(2)∨a∈B∶H(d|B-a)<H(d|B),則稱B是A的屬性約簡。
下節將利用上述度量,構造混合數據間的模糊等價關系,依據屬性重要性的度量進行約簡。
2 模糊等價矩陣的構造及算法描述
基于模糊等價關系的數據構造是混合數據分析的重要模型,利用矩陣形式刻畫具有不同屬性類別的樣本間關系。針對符號型屬性,Hu[16]根據屬性取值是否相等計算樣本間的相似度貢獻,屬性間取其交集得結果,由此矩陣中只見兩個單一數值,不能具體地刻畫樣本間的區分信息,且需針對每個屬性做重復計算;刻畫不同類別屬性間的關系依然采用取其交集的簡便算法,在各種屬性類別取值豐富多樣的信息空間,這種關系構造方法丟失大量的非冗余的有效信息。本節將對混合數據中各個類別屬性分別重新進行構造,提出一種帶權的對象間相似性度量方法,并且使其最終轉化為一個模糊等價關系,在加入量化知識的基礎上進行約簡。
2.1 模糊相似關系的構造
給定一個包含n個樣本的決策系統<U,A,D>,其中A=A1∪A2,A1定義為符號型屬性的集合,A2定義為數值型屬性的集合,U={x1,x2,…,xn},A1={},A2=}。本節將描述樣本的屬性分類處理,分別定義與之對應的唯一函數。
符號型屬性的取值是離散的、非有序的,若兩個樣本的條件屬性取值完全相同,則其決策是一致的。因此,不同樣本間的區分能力由取值不同的屬性來體現,在此引入一個關系矩陣來體現符號型屬性集對樣本間的貢獻度。
定義對象xi和xj間的相似性度量當不存在能區分對象xi和xj的屬性時,=1;當對象xi和 xj的分類完全不一致時,=0。
數值型屬性的取值是連續的、有序的,當兩個樣本除屬性a之外的其余條件屬性相同時,針對屬性a,若樣本x比樣本y占優,則x的決策至少不比y差。因此,不同樣本間的區分能力由決策不一致的程度(即樣本x比樣本y占優的程度)來體現。同樣定義數值型屬性集對樣本間的貢獻度:
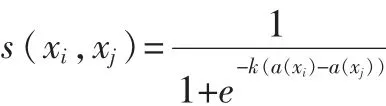
其中k是一個常數,且k>0。
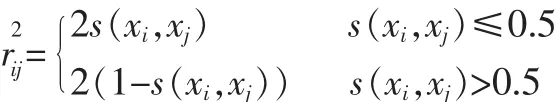
s(xi,xj)表示對象xi比xj在屬性a上偏好、占優的程度,若xi比xj占優,則s(xi,xj)>0.5。若xj比xi占優,則s(xi,xj)<0.5。當s(xi,xj)=1時,說明xi比xj絕對占優。矩陣r2ij是s(xi,xj)轉化后的對象間模糊相似關系,表示對象xi和xj間的相似性度量。
以上是針對一個數值屬性進行的對象間模糊相似處理,對于多個屬性,采用交運算來歸并不同屬性間的模糊關系。假設屬性a和屬性b分別計算其偏好關系為wij和zij,則對象xi與xj對屬性{a}∪{b}量化的偏好關系為min(wij,zij)。
在屬性分類處理之后,引入模糊相似矩陣R=(rij)n×n度量對象間的相似性程度:表示對象xi和 xj在屬性集Ak上的相似性度量,其中α1和α2分別體現符號型屬性和數值型屬性在系統中的權重比例。
以上論述中提出了帶權的對象間相似性度量方法,實現了混合數據間的模糊相似關系構造,但模糊等價關系是計算信息熵的前提,因此,最后還需將模糊相似矩陣轉化為模糊等價矩陣。
2.2 模糊等價關系的構造算法及約簡算法
本節采用Lee Hauan-Shih給出的關于模糊相似矩陣傳遞閉包問題的優化算法來進行轉化[19],使其滿足模糊等價關系的充要條件傳遞性,具體算法如下:
算法:設模糊相似矩陣為R=(rij)n×n,模糊等價矩陣為R*=(r*ij)n×n
輸入:R=(rij)n×n
輸出:R的傳遞閉包R*
(1)令r*ii=1(1≤i≤n);
(2)集合U={rij|j>i}中的元素是從大到小排序的序列;
(3)
①若R*中元素不存在r*ii=?,結束算法;否則轉步驟②。
②對于U中的最大元素ri′j′,若?,令I={j≠?},(i∈I,j∈J),U=U-{ri′′j};否則,轉步驟①。
下面將采用基于屬性重要性的約簡算法進行約簡,算法中設置一個信息表T用來存儲所有屬性值,其中屬性元素按照領域專家的經驗值和用戶的需求偏好多寡來排序。
算法如下:
輸入:決策系統S=<U,A,V,f>,A=C∪d,信息表T;
輸入:S的屬性約簡RED。
(1)令RED=?;
(2)令T中元素從大到小進行排序;
(3)
①選擇T中第一個屬性ai,計算H(d|ai∪RED)以及SIGi(ai,ai∪RED,d)=H(d|RED)-H(d|ai∪RED)
②若SIGi>0,則ai∪RED→RED,T-ai→T,返回步驟①;否則算法結束。
3 實驗分析
本節在MATLAB實驗環境下選擇UCI數據庫中的數據集,驗證混合數據的模糊等價關系構造約簡方法的有效性,表1列出了數據集的基本信息。可以看出其中數據集WPBC包含一類屬性,其他數據集包含兩類屬性。
表2和表3分別列出了本文方法下的數據集約簡結果以及約簡后屬性數目的統計。
分析表3,與其他三種方法(原始數據下的約簡、離散化方法下的約簡、模糊熵方法下的約簡)[16]支撐的數據相比,本文方法在信息量保持不變的前提下剔除了更多的冗余屬性;同時,針對包含一類或兩類屬性的數據集都進行了有效的約簡。表4是采用支持向量機對本文結果與其他幾種方法[16]的約簡數據進行精度對比。實驗結果顯示本文方法下約簡后的屬性精度平均值較高。由此可以看出本文提出的基于模糊等價關系構造的混合數據約簡有效地達到了約簡的目的,并且得到較優的約簡結果。
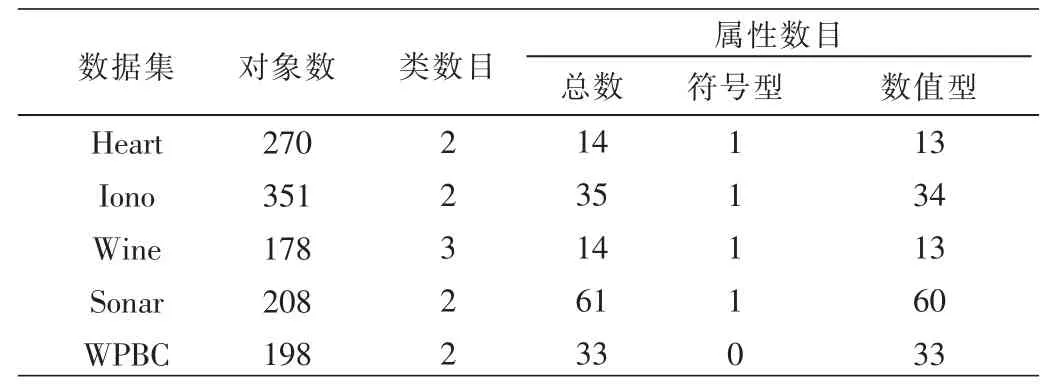
表1 數據集基本信息

表2 五個數據集的約簡結果
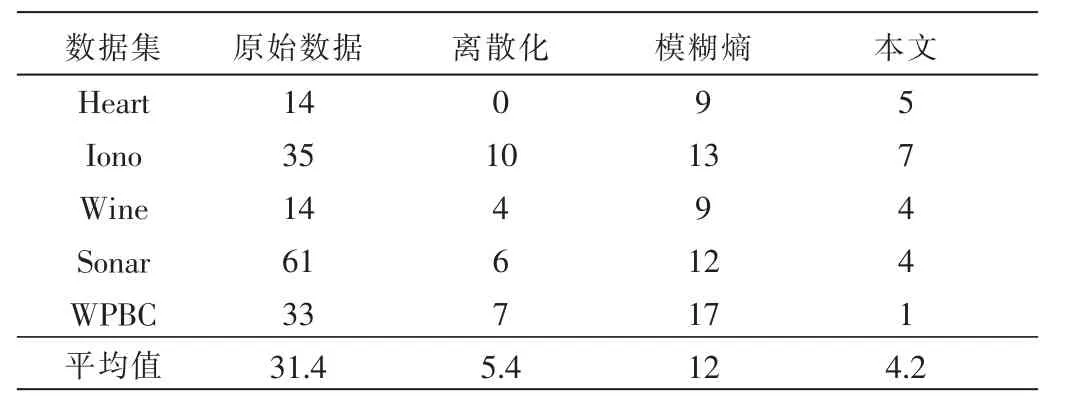
表3 約簡后屬性數目對比

表4 基于SVM的約簡結果屬性精度比較(%)
4 結束語
模糊粗糙集和粗糙模糊集概念的提出,融合了模糊粒化和粗糙逼近兩種不確定性方法,基于模糊粗糙集模型構建模糊等價關系是混合數據分析的有效方法之一。針對混合型信息系統,本文分別提出各類數據的對象間度量以及總體度量方法,建立帶權的對象間相似性度量方法,在轉化為模糊等價關系的基礎上,采用了加入領域專家的經驗知識和系統客戶需求的約簡算法。通過實驗數據分析驗證了方法的有效性和可行性。
[1]PAWLAK Z.Rough sets-theoretical aspects of reasoning about data[M].Dordrecht:Kluwer Academic,1991.
[2]張清華,王國胤,肖雨.粗糙集的近似集[J].軟件學報,2012,23(7):1745-1759.
[3]石夢婷,劉文奇,余高鋒,等.變精度軟粗糙集[J].計算機工程與應用,2014(1):101-104.
[4]CATLETT J.On changing continuous attributes into ordered discrete attributes[C].European working session on learning,1991:164-178.
[5]LIU H,HUSSIANM F,TAN C L,et al.Discretization:an enabling technique[J].Data Mining and Knowledge Discovery,2002,6(4):393-423.
[6]HALL M A.Correlation-based feature selection for discrete and numeric class machine learning[C].In Proc 17th ICML,2000:359-366.
[7]ZHOU Z H,QIAN C Z.Hybrid decision tree[J].Knowledge Based Systems,2002,15(8):515-528.
[8]TANG W.Y,MAO K.Z.Feature selection algorithm for mixed data with both nominal and continuous features[J]. Pattern Recognition Letters,2007,28(5):563-571.
[9]KWAK N,CHOI C H.Input feature selection by mutual information based on parzen window[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2002,24(12):1667-1671.
[10]ZADEH L.Toward a generalized theory of uncertainty-an outline[J].Information Science,2005,172:1-40.
[11]DUBOIS D,PRADE H.Rough fuzzy sets and fuzzy rough sets[J].International Journal of General Systems,1990,17(2-3):191-209.
[12]范成禮,邢清華,鄒志剛,等.基于直覺模糊粗糙集相似度的多屬性決策方法[J].計算機工程與應用,2014(7):121-124.
[13]丁世飛,朱紅,許新征,等.基于熵的模糊信息測度研究[J].計算機學報,2012,35(4):796-801.
[14]Pan Zhenghua,Zhang Lijuan.A new fuzzy set with three kinds of negations and applications to decision making in financial investment[J].Journal of Haman and Ecological Risk Assessment,2011,17(4):795-780.
[15]潘正華.模糊知識的三種否定及其集合基礎[J].計算機學報,2012,35(7):1421-1428.
[16]Hu Qinghua,Yu Daren,Xie Zongxia.Information-preserving hybrid data reduction based on fuzzy-rough techniques[J].Pattern Recognition Letters,2006,27(5):414-423.
[17]HASHMI K,ALHOSBAN A,MALIK Z,et al.WebNeg:a genetic algorithm based approach for service negotiation[C]. In:Foster I,et al.,eds.Proc.of the ICWS 2011,Los Alamitos:IEEE CS,2011:105-112.
[18]梁亞瀾,聶長海.覆蓋表生成的遺傳算法配置參數優化[J].計算機學報,2012,35(7):1522-1538.
[19]LEE H S.An optimal algorithm for computing the maxmin transitive closure of a fuzzy similarity matrix[J].Fuzzy Sets and Systems,2011,123(1),129-136.
Hybrid data reduction based on fuzzy equivalence relations construction
Song Ting
(Computer Science and Technology Institute,Taiyuan University of Science and Technology,Taiyuan 030024,China)
Constructing the fuzzy equivalence relation based on fuzzy-rough set model is one of the effective methods for hybrid data analysis.A weighted similarity measurement between objects for hybrid information system that attributes diversity is proposed. The method creates similarity measurement function corresponding to each class of attribute and then establish fuzzy similar matrix by merging.Reduction algorithm that contains knowledge of filed experts and needs of user is on the basis of transforming into fuzzy equivalence relation.The validity and feasibility of the proposed method are verified by comparing the number and precision of attributes reducted of sample data sets from UCI database.
fuzzy-rough set model;fuzzy equivalence relation;hybrid data;fuzzy similar matrix;reduction
TP3
A
1674-7720(2015)09-0022-04
2015-03-05)
宋婷(1984-),女,碩士研究生,助教,主要研究方向:數據挖掘。
太原科技大學青年基金(20123005)
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
