一種基于元數據本體計算的網絡信息檢索方法*
2015-07-12 17:16:34李彥
新技術新工藝 2015年3期
李 彥
(西安翻譯學院,陜西 西安 710105)
一種基于元數據本體計算的網絡信息檢索方法*
李 彥
(西安翻譯學院,陜西 西安 710105)
為了提高Web信息檢索和過濾的準確性,提出了一種基于元數據本體的網絡信息檢索方法,引入形式概念分析理論本體計算算法來描述本體特征檢索領域的概念和關系,并通過構建以元數據為基礎的信息管理系統,實現對語義元數據的檢索。應用結果證明,采用該方法可有效提高信息檢索的準確性。
元數據;概念相似度;本體;web網頁;檢索
隨著當前網絡信息量以幾何級數的速度增長,傳統的關鍵字檢索方式不能滿足用戶對信息檢索的有效需求,其在進行語義檢索時準確性比較低;因此,如何提高對網頁信息檢索的質量成為當前思考的重要問題。當前,提高Web信息檢索的技術方面思考主要為如何從大量的Web資源中附加計算機可以理解的內容(如元數據),以此使計算機更好地對其進行自動化處理,換句話說就是給出一種計算機能準確理解的資源手段,實現對異構分布信息的有效檢索。解決該問題的關鍵在于:1)通過引入本體特征進行描述,從而提高檢索的準確性;2)構建元數據信息管理系統,實現基于本體的元數據檢索;3)針對其中的非元數據,如何實現轉換。本文針對上述3個問題進行了探討[1]。
1 本體概念相似度算法
目前,針對概念相似度的研究方法主要包括2種。
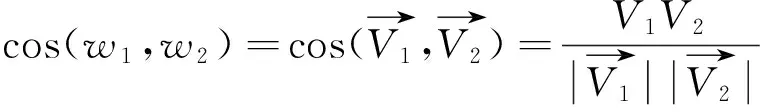
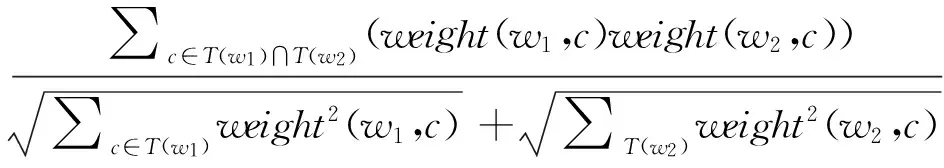
(1)
2)基于語義詞典方法。該方法主要利用語義詞典中的HowNet和WorNet等同義詞所組成的樹狀層次體系結構,通過計算語義之間的距離或者是信息熵的方式對概念相似度進行計算[2]。
2 基于T-L BACH的改進CS0算法
傳統的T-L BACH算法作為一種對本體間概念相似度的計算,與語義相似度算法等相比有著非常重要的特點,通過該算法可實現對 OWL DL等描述語言內涵的充分挖掘,從而得出本體概念以外的潛在的相關信息;但該算法也存在著很大不足,主要體現在計算本體概念相似度的時候,T-L BACH沒有充分考慮到本體的概念特征間的相關結構關系,導致對相似度計算精確度不高。因此,為提高概念本體的計算的準確度,本文提出從 FCA 概念相似度和 RDF 圖結構相似度兩方面對其進行計算,其具體的計算公式為:
simcso=simfcawfca+simrdf+wrdf
(2)
式中,wfca為fca的權重,wrdf為rdf的權重,并有wfca+wrdf=1。
2.1 基于 FCA 的概念相似度計算
在FCA中,形式概念和形式為該算法的基礎,還要通過形式反映其背景,因此,需要做以下幾方面的定義。
定義1:形式背景K=(O,A,R)是由屬性集合A、對象集合O以及由O和A關系R所共同組成。
定義2:假設E表示其對象集合O當中的一個自己,則定義E′={n∈A|?m∈E,mRn}為E中所有對象的共同屬性的集合;同理,定義I作為A當中的自己,定義I′={n∈A|?m∈I,mRn}為I當中所有對象的共同屬性。
定義3:采用二元組(E,I)表示形式背景K:=(O,A,R)的一個形式概念,有E?O,I?A,且滿足E′=I,I′=E。其中,E表示(E,I)的外延,I表示(E,I)的內涵。用δ表示K:=(O,A,R)在背景為K上面所有概念的集合,δ表示背景上的概念格。
定義4:在概念格中,如果某元素不能被寫成其他元素的下確界,則該元素和概念格中上方的元素僅能通過一條邊進行連接,可將該元素稱為是不可約下確界元素;同理,如果某元素不能寫為其他元素的上確界,則將該元素稱為不可約上確界元素[3]。
因此,通過上述定義,可得到基于FCA的相似度計算公式為:
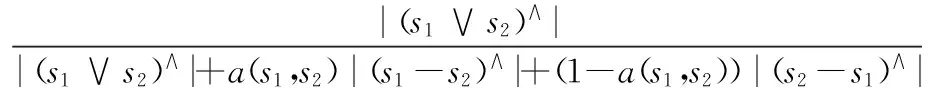
(3)式3中,a(s1,s2)的值為0.5;s1∨s2為概念的上確界;(s1∨s2)∧為概念的上確界的內涵中其不可約下確界的元素集;(s1-s2)∧,(s2-s1)∧為在s1中卻不在s2中的不可約下確界元素集,和在s2中而不在s1中的不可約下確界元素集。
2.2 RDF 圖結構相似度計算
傳統的針對RDF圖結果相似度的計算公式為:
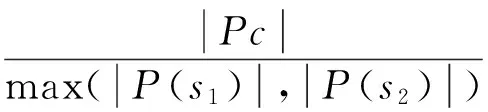
(4)
但是通過上述的數據可以看出,其充分地描述了RDF結構中的謂詞關系,對其中的OWL語言的語義信息卻不能充分表達;因此,在式4中增加了OWL屬性的計算,將OWL的屬性納入到對相似度的計算中得到:

(5)
2.3 算法設計
通過上述分析,將對概念相似度的計算設計為如圖1所示的算法。

圖1 CSO 算法框架圖
3 基于元數據和本體的管理系統構建
結合系統的需求,將該信息管理系統分為3層,并根據B/S訪問模式對信息系統進行建構,其具體的建構如圖2所示。

圖2 元數據信息管理系統平臺
構建元數據管理平臺其主要的目的是對不同的業務信息進行分類,從而為基于本體的概念相似度計算提供相關的基礎的素材。通過該平臺將其分為3個不同的服務層:用戶交互層主要為用戶提供元數據管理交互的平臺,包括對元數據的添加、修改、模板建模、查詢、數據導入等操作;在登陸之后,通過基于本體和基于概念對網絡信息進行搜索,一方面系統通過算法將用戶提交的信息轉換為基于本體領域的語義搜索,另一方面則生成基于本體概念的SPARQL;最后,將上述的信息傳遞給數據服務層,借助數據服務層對數據的處理和修改等完成對數據的搜索。在數據庫中,通過采用一定的領域規則,并借助SWRL解析器對OWL文件進行解析,同時通過JESS推理引擎實現將數據傳遞給本體知識庫。
4 基于元數據的信息搜集
在語義Web當中,最為核心的為 XML、RDF,這些作為解決對網絡信息的搜集提供最為基礎的技術框架;但是,在對信息的搜集過程中還存在著很大的問題就是當前大多數的網絡資源其沒有使用標準的元數據對站點信息進行描述,同時一些相關的網頁或者圖像資源也缺乏統一的元數據描述。因此,為了更好地解決該問題,本文采用了搜集過濾技術,在這個過程中,主動完成對語義元數據的搜集,過程為:1)如果該網絡資源其本身則為元數據,則直接對其進行抽取;2)如果沒有包含元數據,則首先根據文本摘要、關鍵詞抽取和數據挖掘等方式將網絡資源轉換為元數據;3)對標注過的元數據進行抽取,抽取的元數據和對本體的描述統一采用RDF模式進行描述;4)基于過濾本體描述的條件表達式對網絡資源所對應的元數據進行檢索、分析和判別,以此來更新元數據庫。
5 檢索實現
5.1 實現工具
對于系統的實現,采用美國斯坦福大學開發的本體編輯工具Protege工具對該信息管理系統的領域本體進行開發,演示用的相關數據全部存放到SQL Server 2008數據庫當中。采用Jena API接口對操作本體進行開發,最后通過JSP頁面展現。
5.2 結果比較
為比較該算法的有效性,本文設計了2種方案,一種為現有的算法設計,另外一種為傳統的關鍵詞匹配,通過上述實現,得到的結果見表1。

表1 試驗結果比較
6 結語
通過采用改進的CSO算法,加入OWL屬性和引入形成概念,同時構建基于元數據的信息管理系統,得到了其檢索的結果要遠遠好于傳統關鍵字的匹配結果,從而證明了該算法的有效性。通過對該算法的改進,可實現對各種網絡信息資源的搜索,提高搜索的準確性和實現語義延伸的搜索。
[1]王家琴,李仁發. 一種基于本體的概念語義相似度方法的研究[J].計算機工程. 2007,33(11):120-126.
[2]時維元,林正英.復雜設備制造企業遠程服務文檔管理與檢索系統研究[J].新技術新工藝, 2013(2):41-45.
[3]李艷芳.多層網絡中基于資源優化的配置方式[J].新技術新工藝, 2014(9):91-93.
*陜西高等教育教學改革研究(重點)資助項目(13BZ69)
責任編輯李思文
ANetworkInformationRetrievalMethodbasedontheMetadataOntologyCalculation
LI Yan
(Xi′an FanYi University, Xi′an 710105, China)
A network information retrieval method based on the metadata ontology was proposed to improve the accuracy of Web information retrieval and filtering. It introduced the formal concept analysis theory, calculation algorithm of ontology and describes the concept and relation to the ontology feature retrieval field. Meanwhile, through the establishment of information management system based on metadata, the method can realize the retrieval of semantic metadata. The results showed that the method can improve the accuracy of information retrieval effectively.
metadata, concept similarity, ontology, Web page, retrieval
TP 392
:A
李彥(1980-),女,講師,碩士,主要從事計算機教學等方面的研究。
2015-01-05
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
新聞傳播(2016年18期)2016-07-19 10:12:06
現代語文(2016年21期)2016-05-25 13:13:44
現代計算機(2016年11期)2016-02-28 18:35:15
山東青年(2016年1期)2016-02-28 14:25:25
大連民族大學學報(2015年2期)2015-02-27 08:28:11
河南科技(2014年11期)2014-02-27 14:10:19
當代修辭學(2014年3期)2014-01-21 02:30:44
圖書館界(2013年5期)2013-03-11 18:50:29
公務員文萃(2013年5期)2013-03-11 16:08:37
