基于SOM神經網絡的半監督分類算法
2015-07-18 11:21:23趙建華
西華大學學報(自然科學版) 2015年1期
趙 建 華
(1. 西北工業大學計算機學院,陜西 西安 710072; 2. 商洛學院數學與計算機應用學院,陜西 商洛 726000)
·計算機軟件理論、技術與應用·
基于SOM神經網絡的半監督分類算法
趙 建 華1,2
(1. 西北工業大學計算機學院,陜西 西安 710072; 2. 商洛學院數學與計算機應用學院,陜西 商洛 726000)
為提高半監督分類的性能,提出一種基于SOM神經網絡的半監督分類算法SSC-SOM。結合SOM的聚類特性,基于先聚類后標記的思想,充分利用有標記樣本和未標記樣本訓練SOM分類器;將聚類的形成和有標記樣本分配到各個聚類中同時進行,并根據有標記樣本計算各個聚類的聚類中心;在整個未標記樣本的范圍內,根據聚類中心,使用K近鄰算法對未標記樣本進行標記,挖掘未標記樣本的隱含信息。在UCI數據集中進行分類實驗,其結果表明,SSC-SOM的分類率比SSOM提高2.22 %,且收斂性較好。
半監督學習;自組織特征映射神經網絡;分類;聚類
0 引言
半監督學習是一種結合有監督學習和無監督學習的學習方法,綜合利用少量有標記樣本和大量的未標記樣本來提高學習性能,是一個非常熱門的研究方向[1]。半監督分類[2-3]利用大量未標記數據擴大分類算法的訓練集,主要研究從有監督學習的角度出發, 當已標記訓練樣本不足時, 如何自動地利用大量未標記樣本信息輔助分類器的訓練。
將自組織神經網絡(self-organizing feature maps,SOM)引入到半監督學習領域,設計基于SOM的半監督學習算法,是目前學者涉入較少的一個課題。孫雁飛等[4]提出一種基于半監督學習的GA-SOM聚類方法,該方法用半監督學習進行樣本的初始化,利用SOM作為訓練器對無標簽樣本進行聚類,并申請了專利。在該專利中,SOM僅僅用于處理半監督學習初始化后的數據。Shen Furao 等[5]提出一種基于自組織增量型神經網絡(SOINN)的半監督自主學習算法,將SOINN作為學習器,通過輸入數據的不同拓撲結構將其分類成不同的族群,并主動標簽一些教師節點,用這些教師節點實現對所有未標簽樣本進行標記;然而,該算法僅僅使用最初的有標記樣本訓練分類器,使得算法對初始的已標簽樣本的依賴性太強;同時該算法嚴格地講,并不是一種真正意義上的SOM半監督分類算法。Astudillo等[6]利用基于樹拓撲結構SOM算法 (tree-based topology oriented SOM ,TTOSOM)進行半監督分類,首先使用TTOSOM建立隨機的、有結構的網絡拓撲結構,將網絡分為幾個聚類,將有標記的樣本分配到不同的SOM的神經元中,最后在每個聚類中,實現對標記樣本的分類。然而,在該算法中,如何將標記樣本有效地分布到每個聚類中,本身就是一個較復雜的過程;同時在每個聚類中,用有監督分類算法實現對未標記樣本進行標記,也只能在局部找到最優值。陽時來等[7]在已有的無監督生長型分層自組織映射GHSOM神經網絡算法的基礎上,提出一種半監督GHSOM算法,該算法借鑒cop-kmeans算法的半監督思想,使用Must-Link和Cannot-Link 2種約束關系作為先驗知識,利用少量有標記的數據指導大規模未標記數據的聚類過程。該算法是一種半監督聚類算法,同樣存在分類精度不高,分類結果不易統計等缺點。
針對以上問題,本文將SOM神經網絡引入到半監督分類領域,提出一種基于SOM的半監督分類算法SSC-SOM (semi supervised classification algorithm based on SOM neural network)。SSC-SOM基于先聚類后標記的思想,擴充有標記樣本的數目,提高算法的分類精度。它充分利用有標記樣本和未標記樣本訓練分類器SOM,訓練輸入層和競爭層之間的權值W(1),同時,充分利用有標記樣本的標記信息,調整競爭層和輸出層之間的權值W(2),實現對樣本的分類和類別預測;在訓練SOM過程中,聚類的形成和有標記樣本分配到各個聚類中同時進行,并計算各個聚類的聚類中心,在整個未標記樣本的范圍內,根據聚類中心,使用K近鄰算法實現對未標記樣本的標記,擴充有標記樣本,反復迭代。最后,在UCI數據集進行分類實驗,驗證該算法的有效性。
1 SOM神經網絡
自組織特征映射(SOM)神經網絡是由芬蘭學者Teuvo Kohonen 于1981 年提出的,是一種無監督聚類方法,它能將輸入模式在輸出層映射成一維或二維離散圖形,識別環境特征并自動聚類[8]。
SOM結構如圖1所示,包括輸入層和競爭層2層結構,輸入層的維數與輸入樣本向量維數一致,競爭層節點一般呈二維陣列分布,一個競爭層節點代表一個神經元。SOM 網絡的基本工作原理為:網絡學習過程中,當樣本輸入網絡時,競爭層的各神經元通過競爭來獲取對輸入模式的響應,與輸入樣本距離最小的神經元成為競爭神經元;調整獲勝神經元和相鄰神經元權值,使其權值靠近輸入樣本;通過反復訓練,各神經元被劃分為不同區域,各區域對輸入模型具有不同的響應特征,實現對輸入模型的聚類[8]。
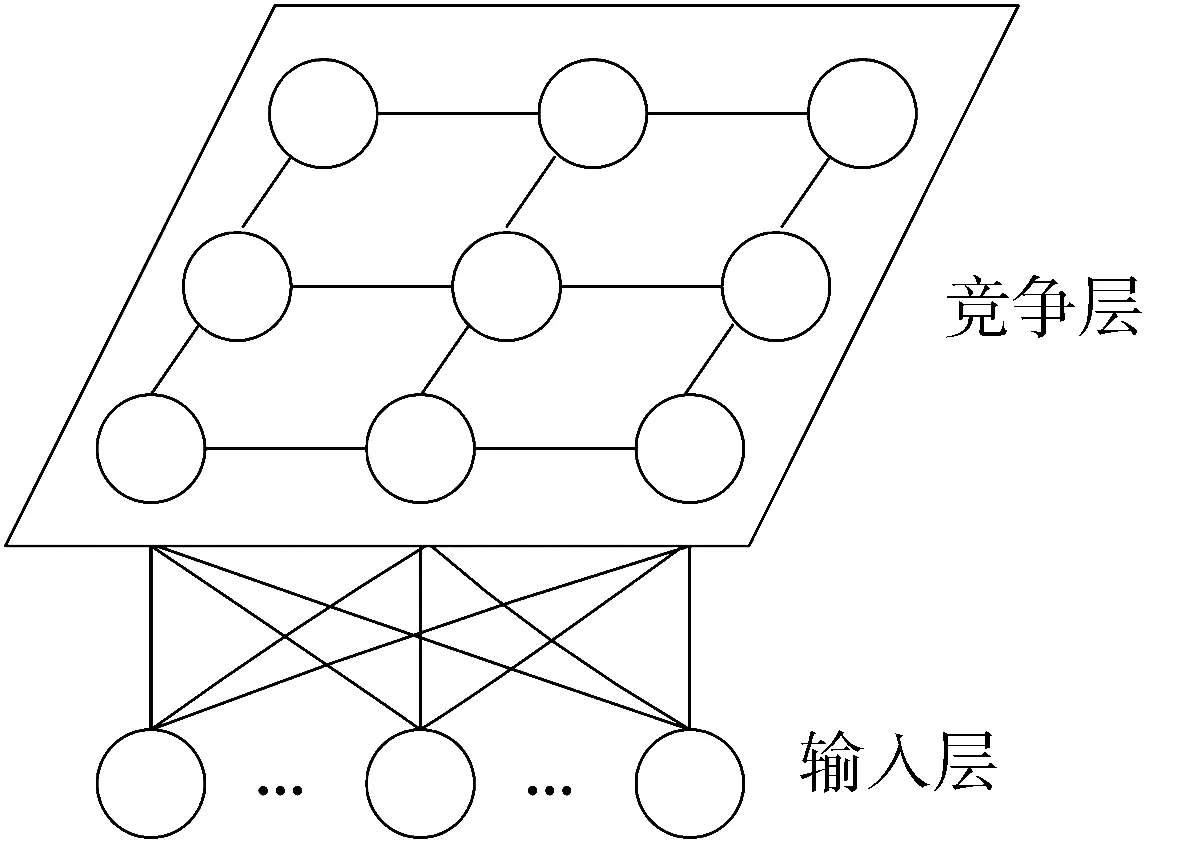
圖1 SOM結構圖
SOM可以對未標記樣本進行無監督聚類,但是分類結果中同一類別數據對應不同的競爭層節點,競爭層節點的數目比實際類別的數目多。文獻[9]將SOM改進為一種有監督的SSOM (supervised SOM),在SOM 2層結構的基礎上,增加了第3層——輸出層,輸出層的個數同數據分類類別數一致,每個輸出節點代表一種數據類別。在進行網絡學習訓練時,根據每個輸入樣本的預測類別和實際類別是否相等,選取不同的權值調整公式對權值進行調整。它不僅調整輸入層節點和競爭層優勝節點領域內的權值W(1),而且調整輸出節點和競爭層優勝節點領域內的權值W(2)。根據輸入樣本Xi的輸出類別Yi和獲勝神經元g對應的輸出類別Og是否相等,進行權值調整。若Og=Yi,則根據公式(1) (2)調整神經元權值;否則,根據式(3) (4)調整神經元權值。通過2個權值的組合,便可以很容易實現對輸入樣本的類別進行分類和統計。
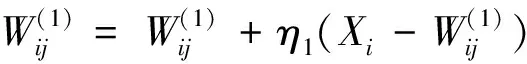
(1)
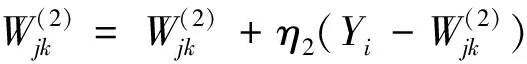
(2)
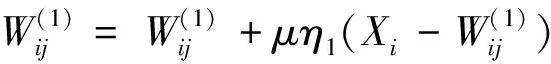
(3)
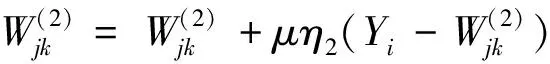
(4)
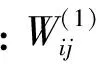
2 基于SOM的半監督分類算法
2.1 基本思想
本文基于“先聚類后標記”的思想,實現對未標記樣本的標記和分類。大體的方法如下:利用聚類算法SOM對未標記樣本集進行聚類,形成幾個聚類中心;然后利用SSOM對有標記樣本進行訓練,使得有標記樣本分布在每個聚類中心的區域內,形成聚類中心;最后,在包含標記樣本和未標記樣本的聚類中心的區域內,使用K近鄰算法實現對未標記樣本的標記,擴充有標記樣本的數目[6,10-12]。
2.2 算法實現
首先,充分利用有標記樣本集和未標記樣本集的屬性特征信息訓練SOM,形成多個聚類,確定輸入層和競爭層之間的權值W(1);接著,利用有標記樣本訓練SSOM,確定競爭層和輸出層之間的權值W(2),根據有標記樣本類別數確定聚類數和聚類的標記信息;然后,根據每個聚類中有標記樣本計算出虛擬的聚類中心;最后,在每個聚類中,以虛擬的聚類中心為中心,使用K近鄰算法實現對其他未標記樣本進行標記,將新標記的樣本擴充到有標記樣本集中。算法的框架如圖2所示,其具體步驟如下。
第1步:聚類過程。SOM是一種包括輸入層和競爭層2層結構、基于聚類思想的無監督分類算法。在對SOM進行訓練時,競爭層是根據輸入層樣本特征之間的距離進行動態調整、自動聚類,因此輸入層和競爭層之間不需要樣本的標記。SSOM是一種3層結構、基于聚類思想的有監督分類算法,是在SOM結構的基礎上增加了1個輸出層,輸出層會根據樣本的標記實現對樣本的分類,競爭層和輸出層之間需要有標記的樣本進行訓練。
基于以上事實,使用有標記樣本集和未標記樣本集共同訓練SOM,形成SOM神經網絡的競爭層節點布局,確定輸入層和競爭層之間的權值W(1)。接著,使用有標記樣本訓練SSOM,確定競爭層和輸出層之間的權值W(2)。使用權值W(1)和權值W(2)的組合形成m分類(即m聚類),每一類都有一個類標記。
通過這樣的處理方式,一方面能充分利用大量未標記樣本和少量有標記樣本的豐富信息,訓練出競爭層分布合理、精確度高的SOM分類器,使有標記樣本的分類布局更合理、更符合實際性,另一方面,結合標記樣本的標記信息,實現每個聚類中都有標記樣本,方便計算聚類中心,實現對未標記樣本的標記。
第2步:尋找聚類中心。對于具有某一類標記的所有樣本,按照式(5)計算該聚類中的虛擬聚類中心。該聚類中心之所以是虛擬的,是因為它是該聚類中所有有標記樣本的平均值,并不一定是一個實實在在的、存在于標記集之中的真實樣本。
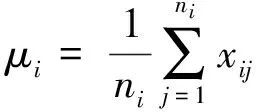
(5)
式中:μi表示第i類樣本的聚類中心;ni表示第i類樣本的樣本數目;xij表示第i類樣本中第j個樣本。
第3步:標記。使用K近鄰方法給距離該聚類中心最近的k個樣本使用類標記進行標記。對于每一個輸入,計算其與聚類中心之間的距離。若其與某一個聚類中心的距離小于某一個閾值,則用該標記給這個未標記樣本進行標記,將標記后的樣本增加到訓練集中。將標記后的樣本添加到標記樣本集,重新訓練SOM,反復迭代。描述算法如表1所示。

表1 SSC-SOM算法過程描述
第4步:分類。使用最終的半監督分類器SSC-SOM實現對樣本的分類。
為防止算法陷入局部最優點,在對每個輸入樣本進行標記時,不是從每個聚類的范圍內尋找距離該聚類中心的最小值,而是從所有的未標記樣本中尋找距離該聚類中心的最小值。
2.3 算法分析
SSC-SOM算法與SOM相比較,都根據輸入層所有樣本特征屬性信息之間的距離進行動態調整,實現對樣本的聚類,都充分利用了所有樣本,包括有標記樣本和未標記樣本的特征信息;但是,SOM沒有用到有標記樣本的標記信息,這是一個巨大的浪費。SOM只能根據競爭層節點的數目進行聚類,聚類的類別比樣本的實際類別要多,分類精度不高; SSC-SOM充分利用了有標記樣本的標記信息,利用有標記樣本調整競爭層和輸出層之間的權值,實現對樣本的分類和類別預測,分類精度更高。
SSC-SOM算法與SSOM算法相比較,都利用了有標記樣本調整競爭層和輸出層之間的權值,實現對樣本的分類和類別預測。但是,SSOM僅僅用到有標記樣本的信息,大量未標記樣本中的隱含信息被浪費了; SSC-SOM充分利用了所有樣本的信息訓練輸入層和競爭層之間的權值W(1),同時,在聚類中通過K近鄰算法擴充有標記樣本的數目。很容易推測出,SSOM訓練出的分類器精度不如SSC-SOM,這在實驗部分得到了證明。
3 實驗和結果分析
實驗平臺選用Intel Core2 Duo CPU 2.0GHz、內存2.0GB的PC,安裝Windows XP 操作系統和MATLAB 7.8.0 (R2009.0a) 編程環境。
MATLAB程序中,實驗參數選取如下:η1=0.8(學習率1),η2=0.8(學習率2),μ=0.2(權值系數),M=12(競爭層神經元個數),r=1.5(學習半徑),K=1。其中,終止條件F表示未標記樣本集為空。學習率和權值系數為SSOM中的參數,不同的參數對SSOM的分類精度影響比較大,這里使用交叉驗證方法[9]選取最優參數作為實驗參數。
實驗采用UCI數據(http://archive.ics.uci.edu/ml/)中常用的6個數據集,如表2所示。
對于表2所選取的樣本,將訓練集和測試集的樣本數目比例設為1∶1。將訓練集分為有標記樣本和未標記樣本2種,按照有標記樣本占訓練集樣本總數目的百分比不同,構造3類半監督分類實驗數據集,百分比λ的計算公式如式(6)所示。λ的取值分別為5%、10%和20%。

(6)
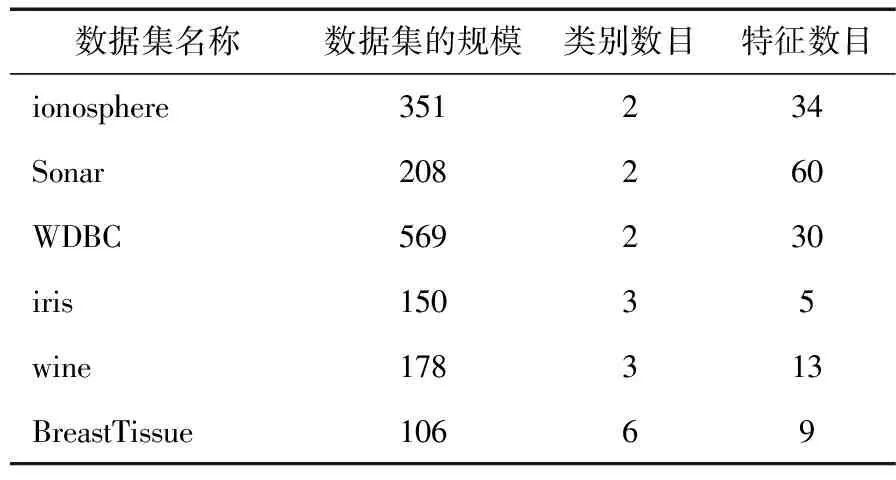
表2 實驗數據集
對于構造的3類半監督分類實驗數據集,分別使用普通的SSOM分類算法(即訓練集僅使用最初的有標記樣本集訓練SSOM分類器)、經典的半監督分類算法tri-training[13](其中分類器采用SSOM作為有監督分類算法)和本文提出的SSC-SOM算法(即SOM的訓練集使用所有的有標記樣本集和未標記樣本集,使用SOM和SSOM擴充有標記樣本數目,使用擴充后的有標記樣本訓練分類器)進行分類實驗。按照式(7)統計實驗結果, rate表示對測試集樣本進行分類測試的正確分類率。實驗結果如表3—10所示。

(7)
表3—6是SSC-SOM和SSOM的實驗結果對比。表7—10是SSC-SOM和tri-training的實驗結果對比。
從表3—5可以看出,相對于僅僅使用有標記樣本訓練分類器的SSOM而言,SSC-SOM分類率rate得到了提高,平均提高2.22 %(如表6所示)。這是因為:1)SSC-SOM充分利用有標記樣本和未標記樣本數據的信息訓練分類器SOM,確定輸入層和競爭層之間的權值W(1),此時的W(1)更能準確反映出輸入層到競爭層的映射關系,比SSOM算法得到的權值精確度要高;2)SSC-SOM在全局范圍內使用K近鄰算法對未標記樣本進行標記,能有效地挖掘未標記樣本的隱含信息,增加有標記樣本的數目。所以,SSC-SOM訓練出來的分類器比僅僅使用最初的標記樣本訓練出來的SSOM分類器精度要高,這也表明SSC-SOM能有效地增加有標記樣本,具有較好的分類性能。
同時還可以看到,隨著標記樣本集數目不斷增加,到達一定程度時,SSC-SOM和SSOM的分類率差距越來越小。這是由于此時有標記樣本數目已經非常充足,半監督學習已經演化成有監督學習。這也反映出SSC-SOM算法具有較好的收斂性,分類率收斂于有監督學習SSOM (所有的訓練樣本都是有標記的)的求解,但是,該算法和SSOM一樣,對初始化的有標記樣本集的依賴性較強,合理選取初始的有標記集L能減小算法的誤差;所以SSC-SOM算法是條件穩定的。
另外,需要注意的是,SSOM僅僅使用已有的有標記樣本訓練網絡,而SSC-SOM需要實現對未標記樣本進行標記。在擴充新標記樣本的過程中,SSC-SOM勢必增加一些時間的開銷。在對未標記進行標記之前,可以采用主動學習算法縮減未標記樣本的規模,只選取信息量豐富的未標記樣本進行標記。這樣需要標記的未標記樣本的數目就大大減小,可以有效地減小時間開銷。
將SSC-SOM與tri-training進行對比,其結果如表7—10所示。可以看出,SSC-SOM能較好地提高分類率,具有較好的穩定性。
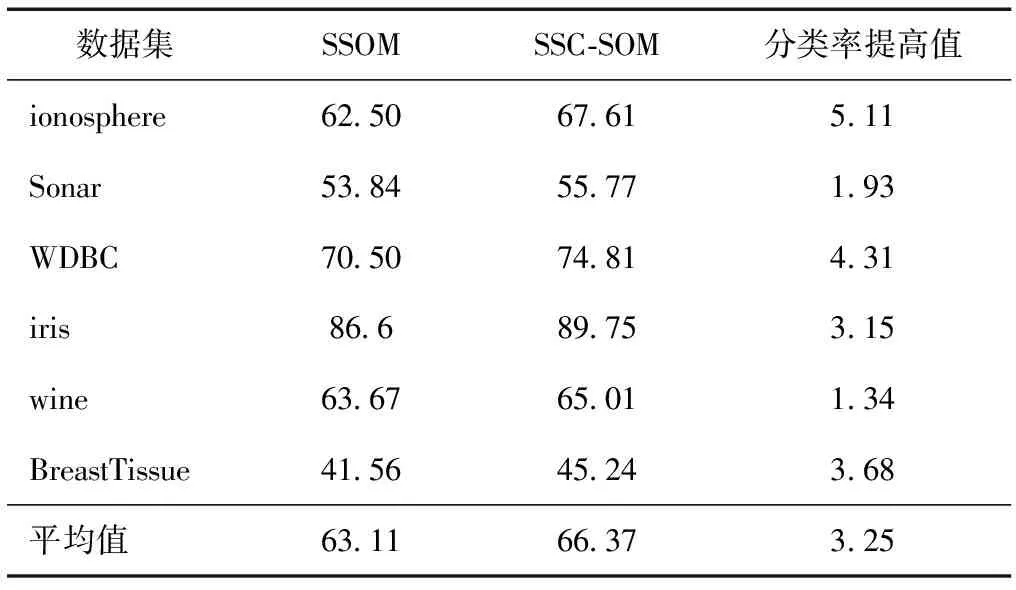
表3 分類率rate(λ=5%) %
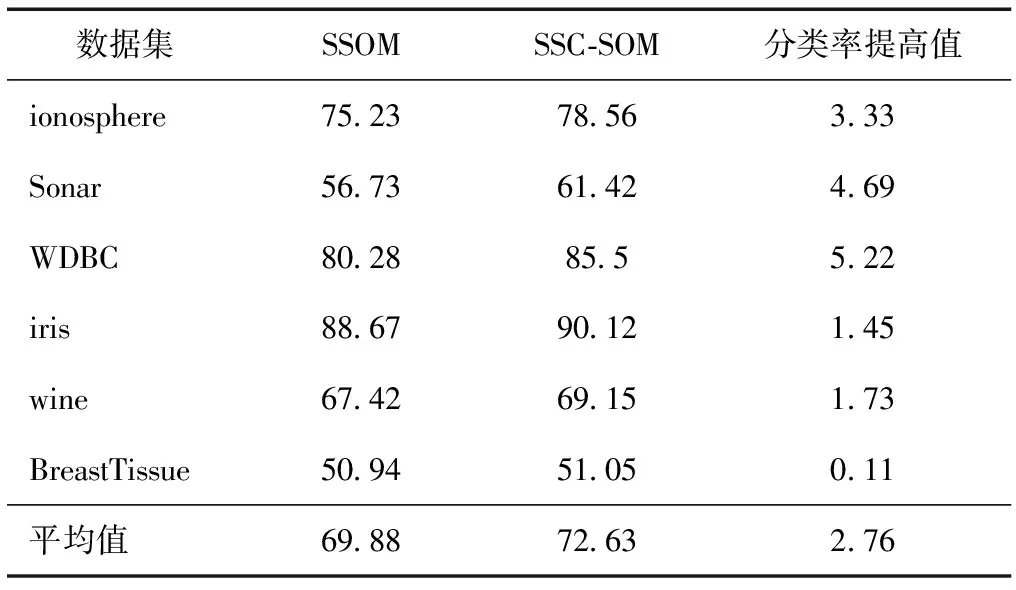
表4 分類率rate(λ=10%) %
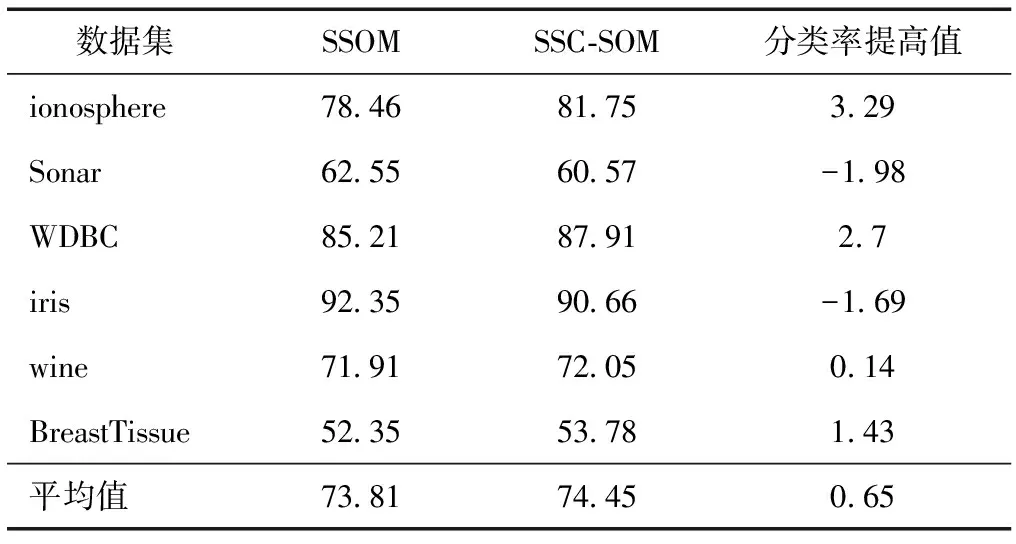
表5 分類率rate(λ=20%) %

表6 分類率提高值統計表 %
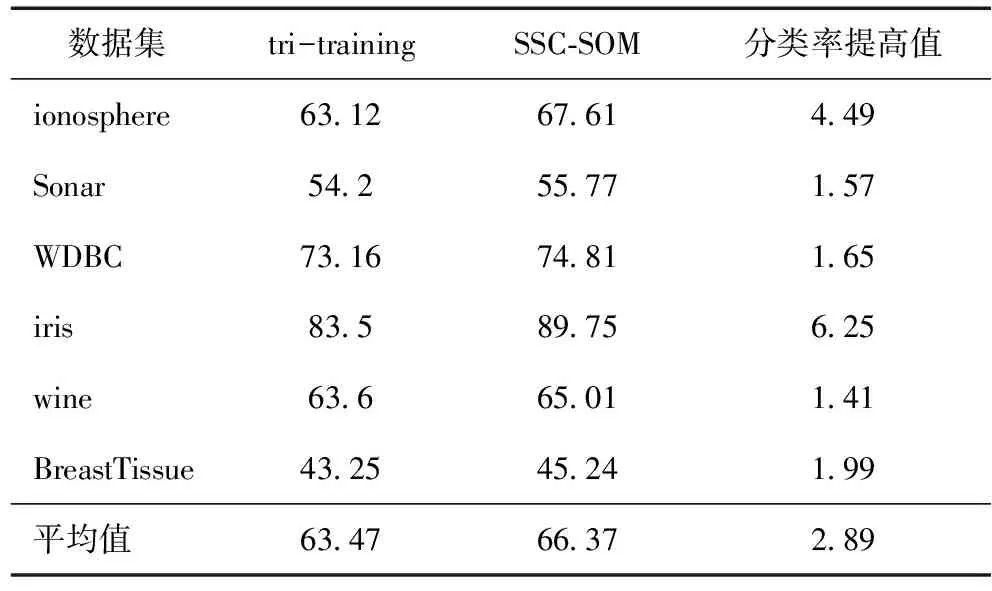
表7 分類率rate(λ=5%) %
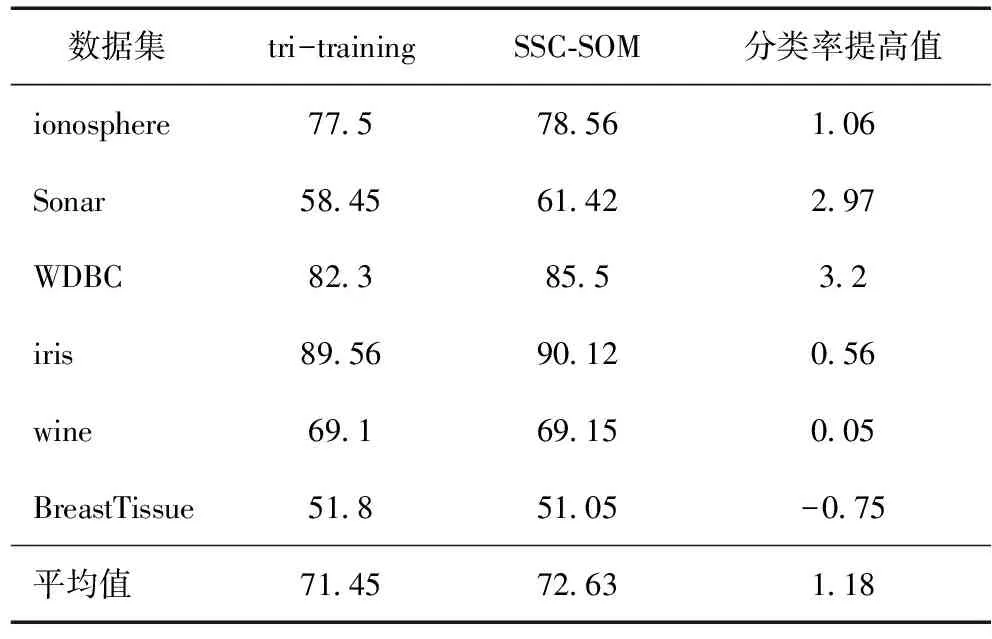
表8 分類率rate(λ=10%) %
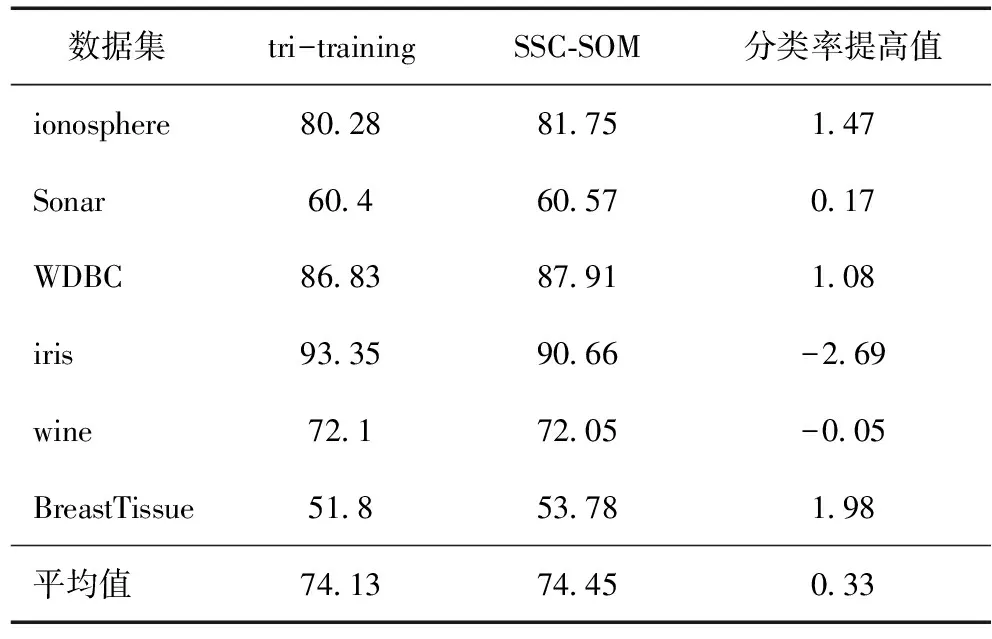
表9 分類率rate(λ=20%) %

表10 分類率提高值統計表 %
4 結束語
本文將SOM神經網絡引入半監督分類領域,基于“先聚類后標記”的思想,結合無監督SOM神經網絡的聚類特征和有監督SSOM神經網絡的分類性能,提出一種基于SOM神經網絡的半監督分類算法(SSC-SOM),充分利用未標記樣本和有標記樣本的信息訓練分類器,實現對未標記樣本的標記和分類。實驗結果表明,該算法操作簡單,能較容易實現對未標記樣本的分類,性能良好。
[1]周志華. 基于分歧的半監督學習[J]. 自動化學報, 2013, 39(11):1871-1878.
[2]ZHU X J. Semi-supervised Learning Literature Survey[R]. Madison: University of Wisconsin, 2008.
[3]李昆侖,曹錚,曹麗蘋,等.半監督聚類的若干新進展[J].模式識別與人工智能,2009,22(5):735-742.
[4]孫雁飛,張順頤,亓晉,等.一種基于半監督學習的GA-SOM聚類方法:中國,201010576193[P]. 2011-04-20.
[5]Shen Furao, Yu Hui, Sakurai Keisuke, et al. An Incremental Online Semi-supervised Active Learning Algorithm Based on Self-organizing Incremental Neural Network[J]. Neural Computing & Applications,2011, 20(7):1061-1074.
[6]Astudillo Cesar A, John Oommen B. On Achieving Semi-supervised Pattern Recognition by Utilizing Tree-based SOMs[J].Pattern Recognition, 2013,46:293-304.
[7]陽時來, 楊雅輝, 沈晴霓, 等. 一種基于半監督 GHSOM 的入侵檢測方法[J]. 計算機研究與發展, 2013, 50(11):2375-2382.
[8]HAGAN M T, DEMUTH H B, BEALE M H. Neural Network Design[M]. Beijing: China Machine Press,2002:64-85.
[9]趙建華,李偉華.有監督SOM神經網絡在入侵檢測中的應用[J]. 計算機工程,2012, 38(12) :110-111.
[10]唐明珠,陽春華,桂衛華. 基于改進的QBC和CS-SVM的故障檢測[J].控制與決策.2012, 27 (10):1489-1493.
[11]文志強,胡永祥,朱文球.流行上的K最近鄰分類方法[J].計算機應用,2012,32(12):3311-3314.
[12]趙建華.一種安全的基于分歧的半監督分類算法[J].西華大學學報:自然科學版,2014,33(5):1-6.
[13]ZHOU Z H, LI M. Tri-Training: Exploiting Unlabeled Data using Three Classifiers[J].IEEE Transactions on Knowledge and Data Engineering,2005,17(11):1529-1542.
(編校:饒莉)
Semi-supervisedClassificationAlgorithmBasedonSOMNeuralNetwork
ZHAO Jian-hua1,2
(1.CollegeofComputer,NorthwesternPolytechnicalUniversity,Xi’an710072China;2.SchoolofMathematicsandComputerApplication,ShangluoUniversity,Shangluo726000China)
In order to improve the performance of semi-supervised classifier, a kind of semi-supervised classification algorithm SSC-SOM is proposed. Based on the clustering characteristics of SOM and the Cluster-then-Label idea, labeled data and unlabeled data are all used to train SOM. The labeled samples are assigned to each cluster and the clusters form simultaneously. The clustering centers are work out.K-NN algorithm is adopted to label the unlabeled samples according to the clustering centers and the information from the unlabeled samples is mined. With UCI dataset, experiments were carried out and the results show that the classification rate of SSC-SOM increases by 2.22 % than SSOM and the SSC-SOM method had good convergence.
semi-supervised learning; SOM; classification; clustering
2014-03-15
陜西省教育廳科研計劃項目資助(12JK0748);商洛學院科研項目資助(14SY006,14SKY007)。
趙建華(1982—),男,講師,博士研究生,主要研究方向為機器學習。
TP181
:A
:1673-159X(2015)01-0036-05
10.3969/j.issn.1673-159X.2015.01.006
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
人大建設(2020年4期)2020-09-21 03:39:12
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
人大建設(2017年2期)2017-07-21 10:59:25
人大建設(2017年9期)2017-02-03 02:53:31
少兒科學周刊·少年版(2015年3期)2015-07-07 21:00:00
浙江人大(2014年5期)2014-03-20 16:20:28
