融合句義分析的跨文本人名消歧
2015-08-10 09:42:26羅森林鄒麗麗石秀民
浙江大學學報(工學版) 2015年4期
張 晗,羅森林,鄒麗麗,石秀民
(北京理工大學 信息與電子學院,北京100081)
面對鋪天蓋地的互聯網信息,搜索引擎的使用逐漸成為大部分網民主要的行為之一.據Guha等[1]的統計可知,5%~10%使用搜索引擎的用戶搜索請求中包含人名作為查詢詞.然而,現實生活中重名現象十分嚴重,對某一個特定人名的查詢結果往往是不同現實個體網頁的混合.人名消歧是判斷相同姓名字符串是否指稱現實中相同實體的過程,針對搜索結果中相同姓名字符串的多文本混合現象,進行文本聚類,即將同名的每一個人的相關文本劃分在一類.人名消歧具有巨大的實際應用價值,是搜索引擎、社交網絡和人名知識庫構建等領域的基礎性研究.
隨著多文本處理的廣泛應用,跨文本人名消歧研究受到越來越多的重視.SemEval-2007評測設立了英文網絡人物搜索任務 Web People Search(WPS)[2].在由ACL SIGHAN 和中文信息學會聯合組織的CLP 2010(CIPS-SIGHAN Joint Conference on Chinese Language Processing)上首次設置了中文跨文本人名消歧任務,并且在CLP 2012上再次設置了這一評測任務,將WPS 以及Text Analysis Conference(TAC)的KBP 實體鏈接任務進行融合.任務不僅要求判定人名實體是否已在知識庫中定義以及是知識庫中的哪一條定義,而且要求對于不屬于知識庫中定義的文本進行聚類,與2010年相比增加了任務難度.本文針對中文跨文本消歧任務,利用句義分析提取句義特征實現人名消歧.
1 相關工作
1998年,Bagga等[3]首次提出跨文本的同指消歧任務.他們對每個文本形成待消歧名字的簡單摘要,并用向量空間模型表示,通過聚類方法將具有人名同指關系的文本聚在一起.他們的方法是較通用的文本消歧技術,沒有考慮到人名消歧的特殊性.2003年,Mann等[4]通過特征模板大大豐富了特征空間中的個人屬性信息,在一定程度上改善了特征提取算法.2005年,Malin[5]提出一種利用社會網絡圖來實現人名消歧的方法,該方法首先構造待消歧人名的社會網絡圖,然后采取隨機游走和網絡切割的方法來精確社會網絡進行人名消歧.2010 年在CLP 2010上,Wang等[6]利用啟發式后處理規則優化命名實體識別效果,然后根據領域信息將文本分類,針對不同領域的人物文本采用不同的處理方式,他們提交的2個系統都表現良好.Xu等[7]依據段落與待消歧名字的距離,將不同位置的特征賦予不同權重進行層次聚類,并對比分析不同鏈接方法應用到人名消歧的效果.2011年,陳峰等[8]運用社會網絡分析法解決中文不同文本同名歧義問題,利用同名的人各自對應不同中心網絡的特點,使用譜聚類將社會網絡圖劃分子圖,通過“集團”劃分來區分不同實體.Wei等[9]用空間向量模型表示文本,以TFIDF計算特征權重,采用支持向量機和凝聚層次聚類相結合的多階段處理策略實現了人名消歧.2012年在CLP 2012上,Peng等[10]在命名實體識別的基礎上,對不同名實體特征、部分詞性以及人物職業名稱賦予不同參數值,結合TF-IDF 構成文本表示模型進行聚類,他們提交的SIR-NERD 系統效果良好.
現有的主要算法大致可以分為以下2類.第一類是對于每一篇文本,用特征向量表示,然后計算向量之間的相似度,采用層次聚類算法將描寫現實中同一人物的文本劃分為一類.第二類是采用圖聚類算法.圖的構造方法是利用文本中命名實體的關系建立一個初始社會關系網絡,然后對該網絡釆用圖聚類算法將節點聚成若干個內部節點緊密連接的“社團”.
層次聚類算法是目前主流的算法,選取合適的特征表示文本是該方面研究的主要工作.目前,大多數特征是文本中的淺層次特征(詞法,句法),沒有考慮特征詞在語句中扮演的語義角色及它們之間的依存關系,造成信息丟失.圖聚類的算法只考慮部分命名實體之間的關系,一方面會造成特征稀疏,另一方面這些命名實體不能充分地描述實體特征,效果并不理想.挖掘文本中更深層次的語義信息,利用不同層次的強弱特征,進而發揮各類特征對人名消歧的作用是有意義的.
2 句義結構模型及句義分析
句義結構模型[11]以現代漢語語義學為基礎,從句義角度研究句子的句義成分以及成分之間關系的句義結構化表示模型,將抽象的句義表示成計算機可處理的結構化數據.模型將句義結構分為句型層、描述層、對象層和細節層4個層次,包含的句義成分有句義類型、話題、述題、謂詞和項等.句義成分中的項分為基本項與一般項,項的具體功能用語義格表示,對應的語義格分為7個基本格和12個一般格.模型的基本形式[12]如圖1所示.
句義分析通過句義結構模型分析句子結構信息和語義信息,抽取能夠表述句子語義的特征,這些特征能夠表達人物實體的重要信息是文本強特征.句義分析的具體方法是根據句義結構模型的基本框架,分別處理不同語義格的對象成分及語義格結構信息,主要的語義格類型說明如表1所示.

表1 語義格類型說明Tab.1 Description of semantic case
在句義結構模型自動構建的基礎上依次查詢上述語義格對應的項作為特征詞,根據語義格的依存關系構造不同組合方式形成具有更精確語義表達能力的特征詞組.對于基本格,要排除查詢詞字串(待消歧人名),若與其他一般格在語義上存在依存關系,則將它們的對應項合并形成新的特征詞組.對于一般格,只提取修飾基本格的作為句義特征,若與其他一般格在語義上存在依存關系,則將它們的對應詞合并形成新的特征詞組.
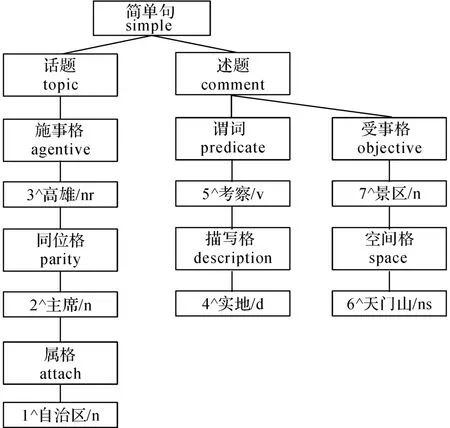
圖2 “自治區主席高雄實地考察天門山景區”的句義結構Fig.2 Sentential semantic structure of“chairman of autonomous region, Gaoxiong survey Tianmen mountain scenic spot”
以下列查詢詞為高雄的句子為例:“自治區主席高雄實地考察天門山景區”.句義結構的生成利用了課題組的自動構建系統ACSM①http:∥www.isclab.org/csa/bfs-csa.php,是基于融合反饋機制的CRF++模型的句義分析器,不依賴于句法分析僅利用詞法分析結果即可實現,保證了分析的性能,對語義格類型的識別準確率達到94%以上.所得的句義結構實例如圖2所示,體現了句義分析的作用:“景區”是“考察”動作的承受對象,“主席”與“高雄”在該句同指一個實體對象,具有同位屬性,所以,該句中受事格、同位格所對應的項“景區”、“主席”兩詞都能夠表達具有區分能力的信息.然而僅僅這兩個詞的表達是不精確的,帶來一定程度的噪音,根據上文方法提取具有依存關系的同位格-屬格、受事格-空間格兩種語義形式,將對應項“自治區主席”、“天門山景區”作為特征詞組,這兩個詞組的表達更細致,有利于區分不同實體對象.此外,去除容易形成噪音的謂詞項以及與實體相關性不大的描述謂詞的語義信息,如該句中的“考察”“實地”,保證了句義特征表達的準確性.
3 算法原理
針對文本分析只停留在表層的問題,本文利用句義結構模型在語義層分析句子,根據語義信息和語義格結構信息處理句子中不同的語義成分和不同語義項之間的依存關系,利用句義特征準確表達語句信息.在抽取實體特征時加入了書名、歌名、電影名等特殊專有名詞以及人物職業,豐富了實體特征類型,結合名詞統計特征進行兩階段層次聚類,利用文本強弱特征實現跨文本人名消歧.
本文提出的融合句義分析的跨文本人名消歧是在文本預處理的基礎上,首先對查詢詞采用啟發式規則的后處理方法進行人名實體識別,將文本集分為人名文本集Nr和非人名文本集Other.然后針對人名文本集Nr根據模板提取與查詢詞相關的局部名實體特征及職業,采用基于規則的分類方法匹配知識庫定義的名字并標記其編號Id.最后針對剩余文本集Out以及非人名文本集Other分別通過自動構建句義結構模型,提取句義特征,利用詞袋模型統計詞頻,依次表示文本進行兩階段層次聚類.
系統主要包括:預處理、人名實體識別、文本表示、分類和兩階段聚類4個模塊.算法原理如圖3所示,各模塊的具體內容在下文詳細介紹.
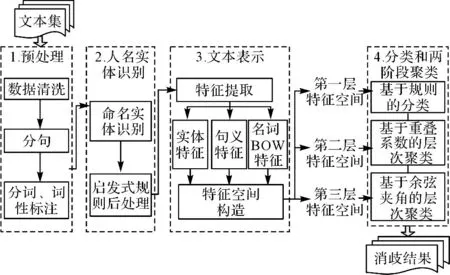
圖3 跨文本人名消歧算法原理圖Fig.3 Cross-document personal name disambiguation algorithm schematic diagram
3.1 預處理
對文本集的預處理模塊主要包括數據清洗、分句、分詞、詞性標注以及命名實體識別.數據清洗階段去除知識庫XML標記以及文本中一些無法正確識別的特殊字符.然后進行分句并依據文本名、段落、段落中位置對每一句編號,目的是方便抽取查詢詞上下文語句以及構建句義結構模型.之后對文本進行分詞、詞性標注,采用中科院計算所的分詞工具ICTCLAS2013.
3.2 人名實體識別
由于人名消歧語料的特殊性,例如查詢詞為“高山”“白雪”等字串時,文本集中存在大量查詢詞以普通詞形式存在的情況,針對這些詞的實體識別效果是非常不理想的.導致錯誤的主要原因是沒有充分利用前后文信息,這種情況直接影響之后的句義結構模型構建的效果.針對上述情況,在利用ICTCLAS2013命名實體識別功能的基礎上,采用基于啟發式規則的后處理方法提升人名的實體識別效果.從文本集中抽取出查詢詞指代人名的文本子集Nr,則剩余文本組成文本集Other,這些文本中的查詢詞以普通詞或者其他命名實體形式出現.整體的識別模塊框架如下所示.

3.2.1 并列詞規則 并列詞是以并列連詞或符號串聯在一起的字串集合,并列連詞和符號有:“和”、“或”、“與”、“、”等.由于并列實體詞在文本中的距離相對較遠,在統計系統中識別效果不好.并列詞規則是若查詢詞的并列詞被識別為人名,則查詢詞也是人名,例如“高山和黃磊都來自云南”中,黃磊作為查詢詞高山的并列詞被識別為人名,而高山被識別為普通名詞,則根據并列詞規則將高山識別為人名.
3.2.2 名稱同指規則 由于現實中經常出現一個人擁有曾用名的情況,甚至擁有筆名、網名等多個名稱,這些名稱在同一個文本中均指代一個人.名稱同指規則即若查詢詞前綴、后綴或通過“,”連接的字串是“原名”“又名”“筆名”“曾用名”“別名”“網名”等,并且這些詞跟隨人名出現就將查詢詞識別為人名,例如“高山,原名高增昌”這兩句中,高山和高增昌指代現實中的同一個人,高增昌被識別為人名,則根據規則查詢詞高山也被識別為人名.
3.2.3 前、后綴稱謂詞規則 前、后綴稱謂詞規則是利用人名稱謂識別人名.前、后綴詞是實體詞前面或后面標示實體類型的部分.若查詢詞本身符合人名的一般原則,而且前、后綴詞是人名稱謂,則查詢詞為人名.例如“(記者高超)”“杜鵑老師”這兩句中,記者及老師都是人名稱謂詞,則查詢詞高超和杜鵑被識別為普通詞,根據該規則將它們識別為人名.
3.3 文本表示
本文根據特征模板提取與查詢詞相關的局部名實體特征及職業,通過自動構建句義結構模型,提取句義特征,利用詞袋模型統計詞頻,利用上述三層特征分別表示文本并進行聚類.
由于名實體及職業信息在人名消歧任務中扮演著重要角色,首先在抽取文本名實體特征及職業時,先從句子劃分完畢的文本中抽取查詢詞的所在句,然后從這些句子中抽取相關的機構名、人名、地名.特別地,通過觀察語料發現,其中出現的人大部分是歌星、演員、作家和學者等知名人士,對于這些特殊人群,一些書名、歌名、電影名等出現在“《”“》”之間的專有名詞可以有效地區分他們,所以將全文本中出現的這些名詞劃分到名實體特征中構成一維獨立特征.最后利用職業稱謂詞典匹配查詢詞前后綴職業,上述特征由相關的特征詞集合組成,構成的第一層特征空間表示文本,標記如表2所示.

表2 第一層特征類型及標記Tab.2 Types and markers of first layer characteristics
根據4章的特征選擇實驗,從8種語義格中選擇施事格、受事格、說明格、范圍格、描寫格、空間格所對應的項.根據2章介紹的句義特征提取方法從查詢詞上下文信息(一般為查詢詞所在句的上下各一句話)中提取特征詞和詞組構成句義特征,利用所選取的特征將文檔形式化表示在n 維空間的向量,構成第二層特征空間表示文本,如下所示:

空間中的每一維wn都是選取的特征詞或詞組.
利用詞袋模型(BOW)統計所有的名詞詞頻,用空間向量模型表示文本構成第三層特征空間,詞袋模型的特點在于該模型忽略掉文本的語法和語序,用一組無序的單詞來表達一段文字或一個文檔.系統采用詞頻矩陣TF 對詞袋特征進行加權,主要表示度量詞t與文檔d 之間的關聯度:通常,如果文檔不包含該詞,則定義為零;否則定義為非零.對于向量中的非零項,定義詞的權重方法有多種.系統采用的方法如下:若詞t出現在文檔d 中,則用規范化詞頻來計算,計算公式為
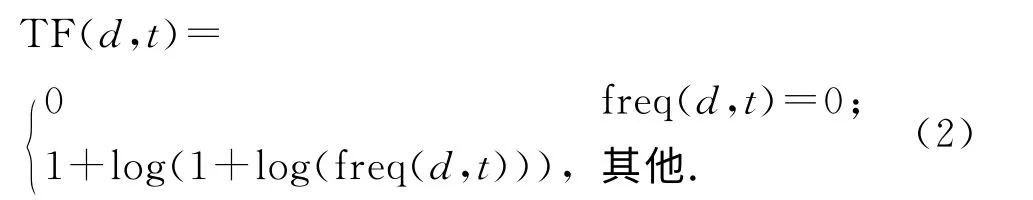
式中:freq(d,t)為詞t在文檔d 中出現的次數.
3.4 分類和兩階段聚類
利用上述三層特征空間,采用一種融合分類和兩階段聚類的處理策略.首先針對人名文本集,利用知識庫定義及表2所示的第一層特征空間進行基于規則的分類方法,將知識庫中提及的每一個人的相關文本劃分為一類.規則為對于每一篇文本和知識庫定義內容,若nr或snz特征集交集非空,或者nt或ns特征集交集元素數不小于2,或者nt或ns特征集交集元素數等于1并且occupation特征集交集非空,則將該文本標記為知識庫定義編號.
后兩個階段是針對未被劃分到知識庫定義的剩余文本集Out以及非人名文本集Other分別進行聚類,其中第一階段利用句義特征構成的第二層特征空間進行基于凝聚的最小距離法層次聚類,兩文本的相似度用重疊系數(overlap coefficient)計算.假設文檔dx的特征向量為fx,文檔dy的特征向量為fy,則
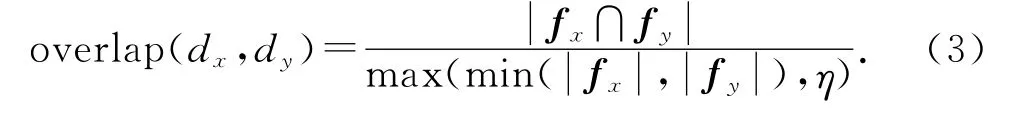
η是為了避免式(3)的分母過小而設定的閾值,一般根據訓練集確定.
第二階段聚類是在第一階段聚類結果映射的基礎上,使用第三層特征空間以及相同的層次聚類算法.兩文本的相似度用空間向量v1、v2之間的余弦夾角表示,如下:
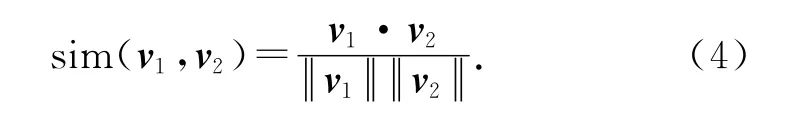
對于結果映射過程,首先觀察第一階段的聚類結果,然后將所有聚類類別中包含文本數≥2的類別篩選出來,將這些類別中的文本在層次聚類初始化數據前聚為一簇,而那些只包含一個文本的離散類別不作任何處理.根據表3所示的部分文本聚類結果,第二階段層次聚類輸入數據的初始化狀態如圖4所示.P1、P2、P3、P4、P5依次表示表3中顯示的文本,樹狀圖中的虛線表示沒有進行第二階段層次聚類之前的初始狀態,嵌套簇圖更直觀地顯示了第一階段聚類的映射結果.
開展4章所述的參數選擇實驗得到重疊系數μ作為第一階段聚類停止時的相似度閾值,夾角余弦值θ作為第二階段聚類停止條件.

表3 第二階段聚類結果示例Tab.3 Typical example of second stage clustering result
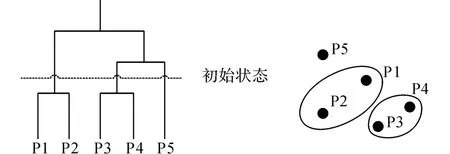
圖4 以樹狀圖和嵌套簇圖顯示的聚類初始狀態Fig.4 Clustering initial state showed by tree diagram and nested cluster diagram
4 實驗及結果分析
4.1 實驗數據資源
實驗數據是CLP 2012中文人名消歧評測任務開放的語料,其中包含16個不同的待消歧人名,每個名字包含50~200篇不等的文本,共包含1 634篇文本,并且對每一個人名均包含一個提供少量實體信息的知識庫.其他數據資源還包括常用人名稱謂1 510個.
4.2 評價方法
采用CLP 2012 使 用 的B_Cubed 指 標 評 價 實驗結果.
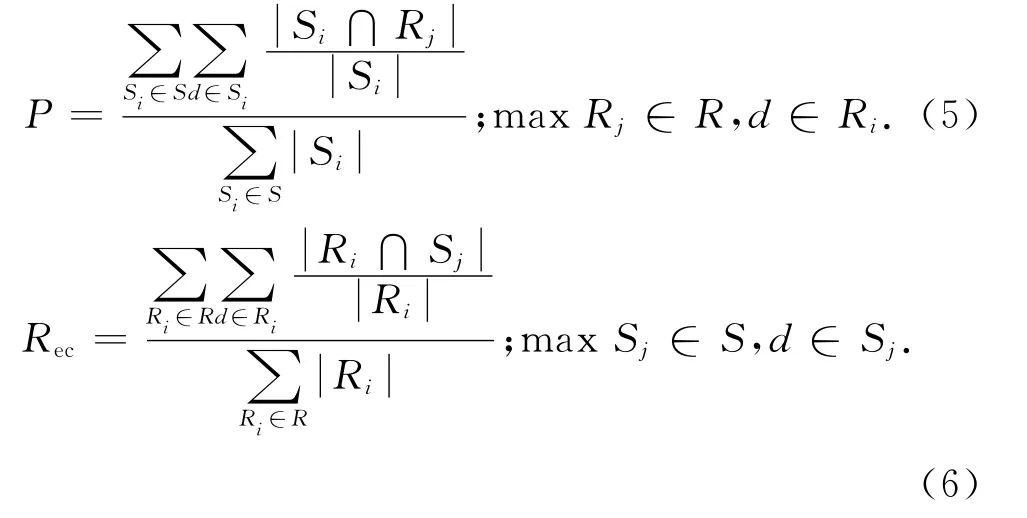
式中:P 為準確率,Rec為召回率;S 為標準聚類結果集合,d 表示文檔,Si∈S 表示標準結果類別集合中的一類;R 為實際聚類結果集合,Rj∈R 表示實際聚類結果集合中的其中一類;|Si|和|Ri|分別為集合Si和Ri的 大 小.
對參與聚類的每個文檔分別求出P 和Rec,再求出平均值作為聚類結果的P 和Rec.F 采用通常的計算公式計算:
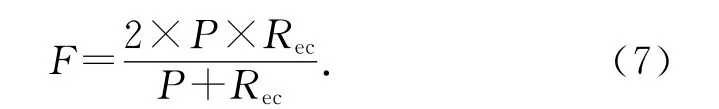
4.3 實驗結果及分析
對融合句義分析的跨文本人名消歧系統進行3組實驗:句義特征選擇實驗、聚類參數選擇實驗和系統總體效果對比實驗.
第1組實驗是句義特征選擇實驗,目的是選擇系統所需的最優化句義特征組合.首先分析消歧中不同語義格的表達能力,挑選出8種語義格進行實驗,語義格的編號如表4所示.
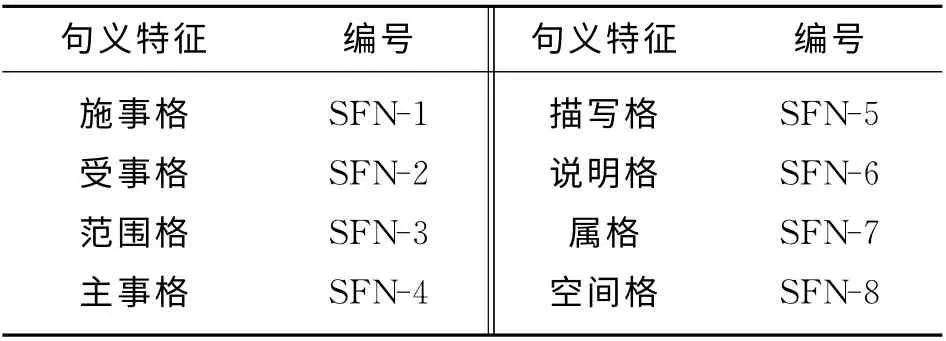
表4 句義特征編號Tab.4 Number of semantic features
對語料進行統計分析發現,大部分文本所提取的句子均含有的基本句義特征是施事格.實驗以施事格作為基線,依次加入其他基本句義特征,觀察它們對層次聚類準確率的影響,均取重疊系數0.49作為聚類停止條件,保留使準確率上升的句義特征,丟棄使準確率下降的句義特征.
由圖5可知,選擇施事格、受事格、范圍格、描寫格、說明格、空間格作為最優句義特征組合,這種句義特征組合具有較強的表達能力,可以更精確地反映句義信息.
第2組實驗是兩階段聚類的參數選擇實驗,選擇最佳的μ 與θ 的組合方式作為兩階段聚類的停止條件.實驗中,μ 以0.02為間隔在0.15~0.35的區間變動,θ以0.02 為間隔在0.08~0.20的區間變動,其中θ1=0.08,實驗結果如圖6所示.由圖6可知,當μ 取0.31,θ取0.12時,聚類效果最好.
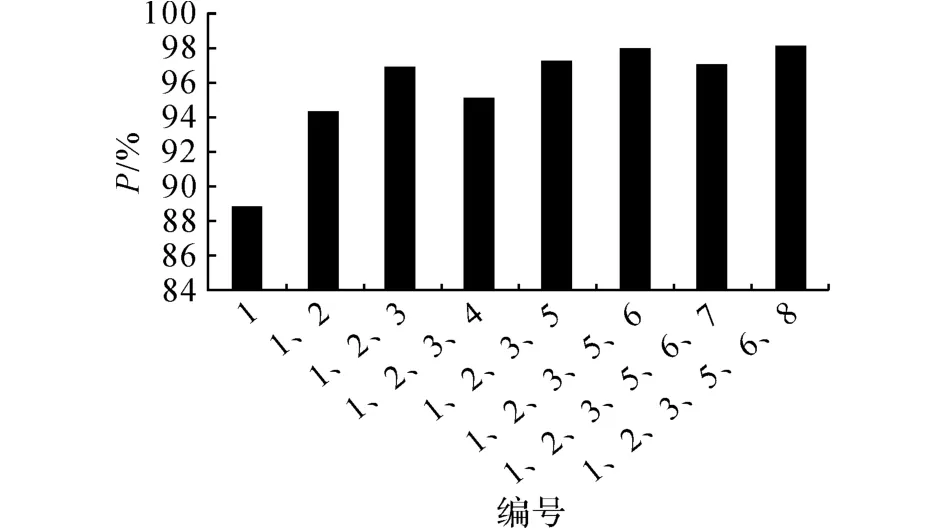
圖5 特征選擇實驗結果Fig.5 Results of experiments of feature selection
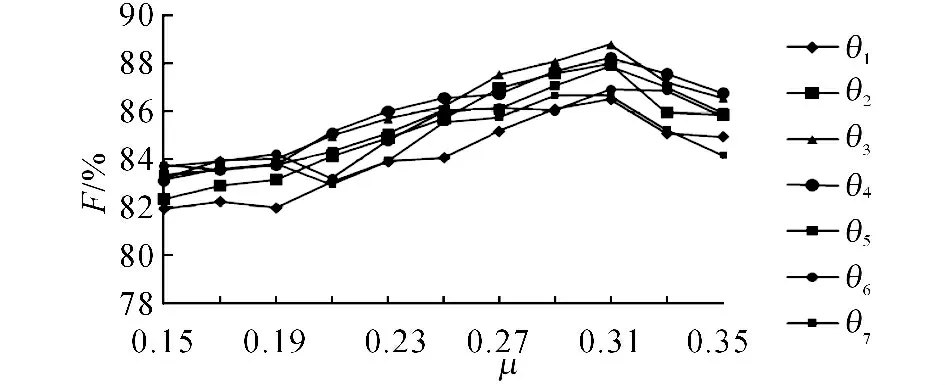
圖6 兩階段聚類參數選擇實驗結果Fig.6 Results of feature selection with two-stage clustering
第3組實驗是系統總體效果對比實驗.對比系統是2 個 參 與CLP 2012 評 測 的 系 統TBHMERD[13]、SIR-NERD和本文系統去除句義分析模塊的結果,如表5所示.
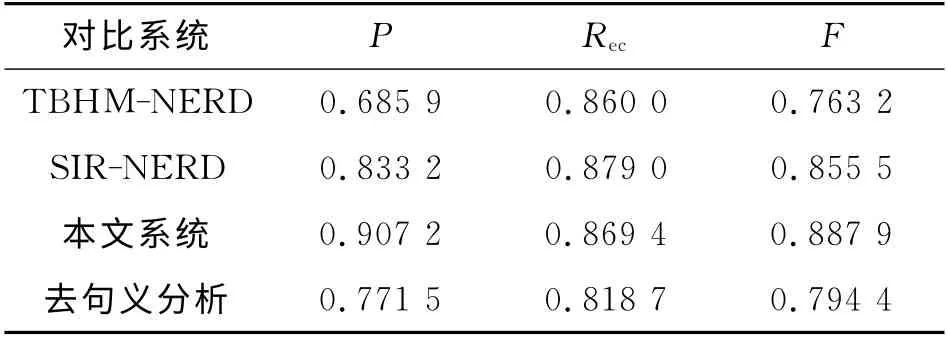
表5 系統總體效果對比實驗結果Tab.5 Comparison with system overall experimental results
由表5可見,去除句義分析模塊后僅利用特定屬性和統計特征的處理方法的準確率較低,而加入句義分析模塊的本文系統效果明顯提升,F 優于其他兩個評測系統,特別是在準確率方面表現良好.原因是句義特征可以精確表達信息,作用于對凝聚層次聚類效果影響較大的底層,優先將部分文本劃分為一類;然后結合統計特征,適應了凝聚層次聚類自底向上的特點,有效地避免了只使用特征融合并賦不同權重的單層次的聚類方法所帶來的噪音.采用該處理方法不僅增加了句子分析的深度,而且合理地利用了文本強弱特征.召回率相對SIR-NERD 系統下降將近1%,可能的原因如下:1)命名實體識別效果不理想,造成特征數據稀疏;2)某些文本中的句子形式不規范,例如缺少謂詞或其他語義成分、出現某些代詞等,只根據該句無法正確地提取有效句義特征;3)分類算法所利用的實體屬性特征不夠豐富,且規則不夠完善,導致知識庫定義人名的相關文本被劃分到Out文本集中.
5 結 語
本文結合文本強弱特征,合理利用分類聚類算法實現了跨文本人名消歧.特別地,利用句義結構模型分析句子的結構信息和語義信息,通過分析特征詞在語句中的依存關系,深化了句子分析層次,提取的句義特征增強了特征向量的表達能力,有效地避免了信息丟失,更準確地描述語句中實體相關信息.實驗證明,結合句義特征的層次聚類方法明顯提高了系統的準確率以及綜合性能.綜上所述,句義分析可以應用到跨文本人名消歧的研究中,并能夠取得良好的效果.
由于利用重疊系數的相似度計算方法沒有考慮到句義特征在句子中扮演角色的重要程度,下一步工作的重點是句義特征權重計算方法的研究.同時,利用上下文信息豐富句義特征以解決由于某些句子形式不規范原因造成的特征稀疏的問題,以期提高算法的召回率.這些研究將提高句義分析能力,進一步提升跨文本人名消歧的效果.
(
):
[1]GUHA R,GARG A.Disambiguating people in search[C]∥The 13th International World Wide Web Conference.New York:Association for Computing Machinery,2004:102-107.
[2]ARTILES J,GONZALO J,SEKINE S.The SemEval-2007 WePS evaluation:establishing a benchmark for the web people search task[C]∥Proceedings of the 4th International Workshop on Semantic Evaluations.Prague:Association for Computational Linguistics,2007:64-69.
[3]BAGGA A,BALDWIN B.Entity-based cross-document conferencing using the vector space model[C]∥Proceedings of the 17th International Conference on Computational Linguistics:Volume 1.Montreal,Ganada:Association for Computational Linguistics,1998:79-85.
[4]MANN G S,YAROWSKY D.Unsupervised personal name disambiguation[C]∥Proceedings of the 17th Conference on Natural Language Learning at HLT-NAACL 2003:Volume 4.Sofia,Bulgaria:Association for Computational Linguistics,2003:33-40.
[5]MALIN B.Unsupervised name disambiguation via social network similarity[C]∥ Workshop on Link Analysis,Counterterrorism,and Security.Minneapolis:[s.n.],2005,1401:93-102.
[6]WANG H,DING H.A multi-stage clustering framework for Chinese personal name disambiguation[C]∥CIPS-SIGHAN Joint Conference on Chinese Language Processing. Tianjin:[s.n.],2010:88-94.
[7]XU R,XU J.Combine person name and person identity recognition and document clustering for Chinese person name disambiguation[C]∥CIPS-SIGHAN Joint Conference on Chinese Language Processing.Tianjin:[s.n.],2010:95-100.
[8]陳峰,王厚峰.基于社會網絡的跨文本同名消歧[J].中文信息學報,2011,25(05):76-82.CHEN Feng,WANG Hou-feng.Social network based cross-document personal name disambiguation [J].Journal of Chinese Information Processing.Tijanjin:[s.n.],2011,25(05):76-82.
[9]WEI H,XU B,ZHAO T.Study on Chinese person name disambiguation based on multi-stage strategy[C]∥2011 8th International Conference on Fuzzy Systems and Knowledge Discovery (FSKD).Chongqing:IEEE,2011:1177-1181.
[10]PENG Z,SUN L.SIR-NERD:a Chinese named entity recognition and disambiguation system using a twostage method[C]∥CIPS-SIGHAN Joint Conference on Chinese Language Processing.Wuhan:[s.n.],2012:115-120.
[11]羅森林,韓磊,潘麗敏,等.漢語句義結構模型及其驗證[J].北京理工大學學報:自然科學版,2013,33(2):166-171.LUO Sen-lin,HAN Lei,PAN Li-min,et al.Chinese sentential semantic mode and verification[J].Beijing Institute of Technology:Natural Science,2013,33(2):166-171.
[12]馮揚.漢語句義模型構建及若干關鍵技術研究[D].北京:北京理工大學,2010.FENG Yang.Research on Chinese sentential semantic mode and some key problems[D].Beijing:Beijing Institute of Technology,2010.
[13]HAO Z,DEREK F.A template based hybrid model for Chinese personal name disambiguation[C]∥CIPSSIGHAN Joint Conference on Chinese Language Processing.Wuhan:[s.n.],2012:121-126.
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
語文知識(2014年1期)2014-02-28 21:59:13
