上市公司財務預警實證研究
2015-09-17 16:51:51張彥寧
商場現代化 2015年19期
摘 要:利用數學模型對企業進行財務預警,并以此來反應財務風險及采取相對應的化解措施就成為企業利益相關者日漸關注的問題。上市公司的財務預警判別問題是國內外財務研究的熱點,建立過多種財務預警模型。本文以2012年33家上市公司公開披露的財務數據作為檢驗數據來源,采用多元統計中的逐步判別法確立出3個判別分析變量,運用逐步判別法來確定具體的篩選指標,從而得出相應的財務預警檢驗模型。
關鍵詞:上市公司;財務預警
一、文獻綜述
回顧國內外學者對財務預警系統各類研究,發現已經形成一個成熟的體系。早期的財務預警模型的實證研究是一元模型,此模型用19家公司作為樣本,運用單個財務比率將樣本劃分為破產和非破產兩類來研究。結果表明,最具財務危機的判別能力的是凈利率比股東權益和股東權益比負債這兩個比率。但一元判定模型在指標選取上過于單一,不能完全展現出企業的財務狀況。Ohlson(1980)是第一個將邏輯回歸方法引入財務危機預警領域,他選擇了1970年—1976年間破產的105家公司和2058 家非破產公司組成的配對樣本,分析了樣本公司在破產概率區間上的分布以及兩類錯誤和分割點之間的關系,發現公司規模、資本結構、業績和當前的融資能力進行財務危機的預測準確率達到96.12%。在我國,目前慣用的用于財務預警的方法主要有一元判別法、多元判別法以及多元邏輯回歸法。雖然這些方法并不十分穩定,但對上述模型進行修正后,大大降低了不穩定性。本文結合了奧特曼(1968)的研究和我國上市金融公司公開披露的財務數據,運用逐步判別的實證檢驗做出有顯著判斷能力的模型。
二、方法介紹
判別分析法是指根據某一研究對象的各種特征值判別其類型歸屬問題的一種多變量的統計分析方法。判別分析有二級判別、多級判別、逐步判別等多種方法。本文主要講述的逐步判別法運用于上市公司財務預警系統中的實際應用。
逐步判別分析法的主旨思路:根據組內離差和總離差形成的判別能力構造F統計量,判斷指標的取舍,每引入一個新指標的時,也同樣在檢驗己經存在指標的判別能力,若其判別能力由于新指標的引入而變的不明顯,就刪除該指標。然后檢驗剩余指標中的判別能力,其中最大指標能不能納入評價體系,按此種模式,直到所有有顯著影響的指標全部納入評價體系,且其中指標均不能剔除掉。筆者認為對模型的正確判別能力和預警的可靠性產生較大的影響的關鍵是如何選取最具判別能力的指標。為此,本文在判別分析前先用逐步判別法來篩選指標。
三、實證分析
從1968年奧特曼的研究文獻中可知,根據指標的流動性、獲利能力、財務杠桿、償債能力和周轉能力五個方面,結合普遍性與潛在相關性選擇了22個財務比率,顯著判別分析變量即為這5個財務比率。其所得到的判別模型為:
Z=0.012X1+0.014X2+0.033X3+0.006X4+0.999X5
X1=營運資金/總資產;X2=留存收益/總資產;X3=資產報酬率;X4=權益市場值/總債務的賬面值;X5=銷售收入/總資產。
采用逐步判別法生成的判別函數的一般形式是:
Z=aX1+bX2+cX3+dX4+…
Xi(i=1,2,3…s)是反映研究對象的特征變量a,b,c,d…為各變量的判別系數,Z為判別分值。
數據的選取對于一個檢驗模型的成功與否有直接關系,樣本的選取就直接關系到模型的預警能力,應因不同的行業而異。本文所選取的是2012年A股主板上市公司的相關財務數據,以及2012年被ST的公司。在非ST樣本的選取中,應依據ST公司的分類相近原則,選取2012年具有經營代表性的金融上市公司。采取一個ST公司與一個非ST公司對應的方式,且每一對公司的經營狀況與總體規模相近。因此通過仔細選擇,最后得到16家ST公司和16家非ST公司,組成一個32家主板上市公司的樣本數據作為構建財務預警模型的數據。
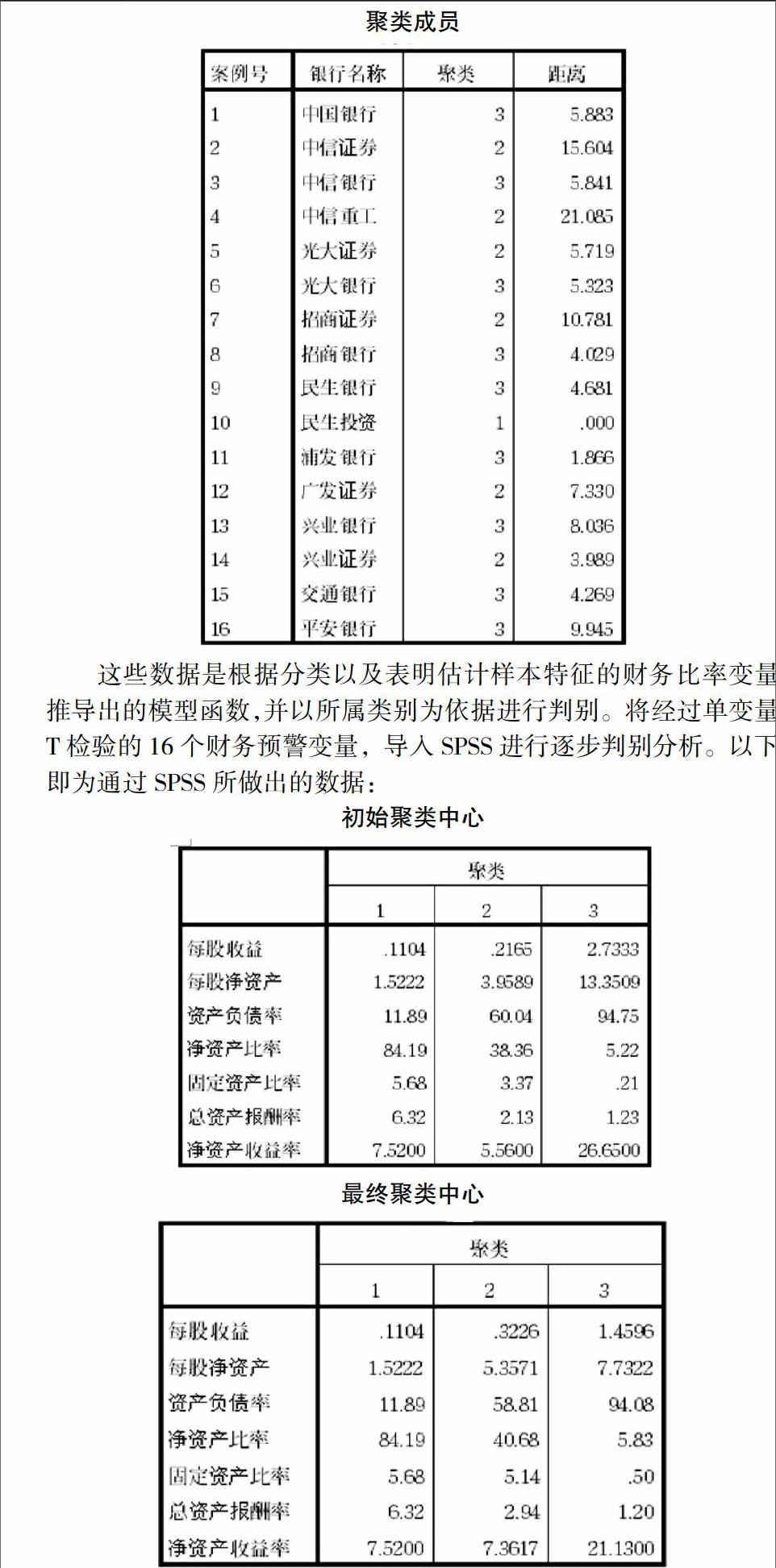
聚類成員
這些數據是根據分類以及表明估計樣本特征的財務比率變量推導出的模型函數,并以所屬類別為依據進行判別。將經過單變量T檢驗的16個財務預警變量,導入SPSS進行逐步判別分析。以下即為通過SPSS所做出的數據:
初始聚類中心
最終聚類中心
a.協方差矩陣的自由度為13。
b.軟件采用Wilkslambda方法進行逐步判別分析,使用F值作為判別統計量,并采用F>=3.84時進入模型,F<=2.71時從模型中移除的篩選標準。
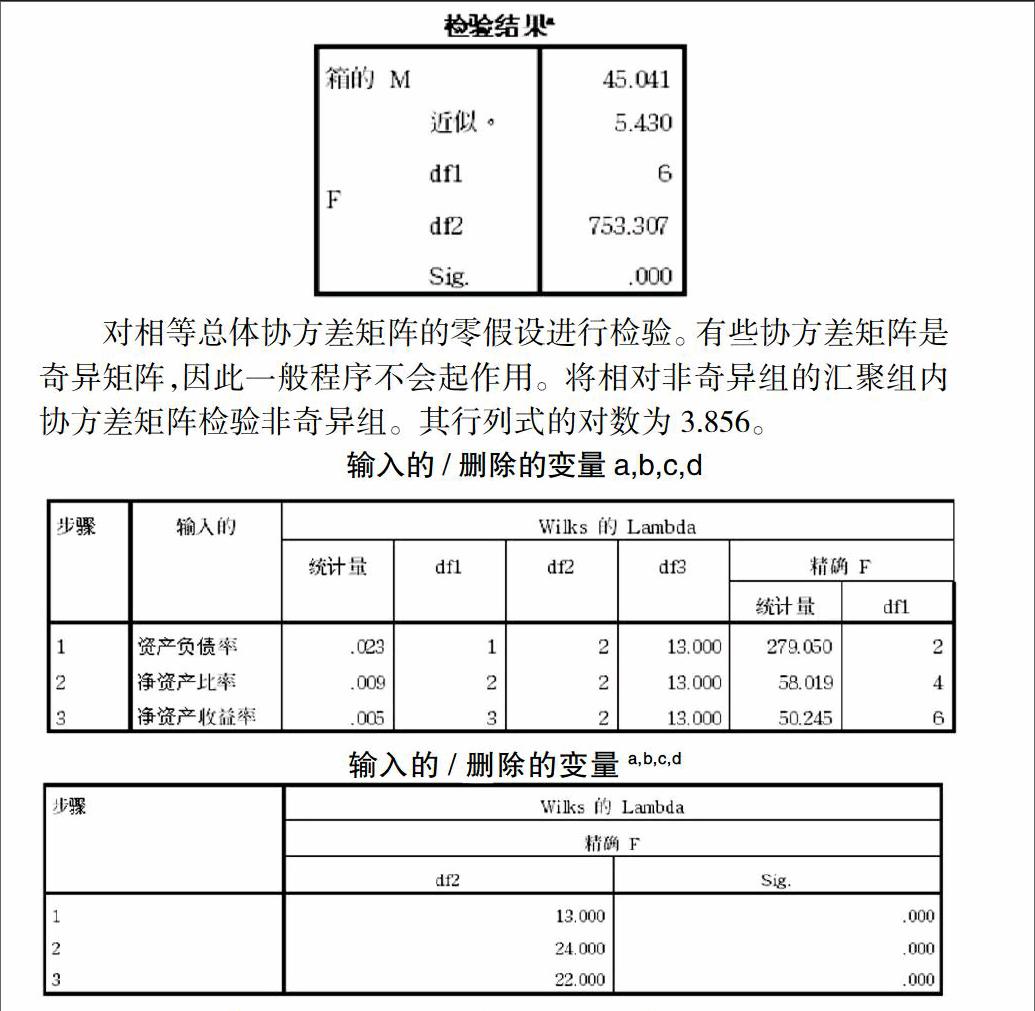
對相等總體協方差矩陣的零假設進行檢驗。有些協方差矩陣是奇異矩陣,因此一般程序不會起作用。將相對非奇異組的匯聚組內協方差矩陣檢驗非奇異組。其行列式的對數為3.856。
輸入的/刪除的變量a,b,c,d
在每個步驟中,輸入了最小化整體Wilk的Lambda的變量。a,b,c,d
a.步驟的最大數目是14。
b.要輸入的最小偏F是3.84。
c.要刪除的最大偏F是2.71。
d.F級容差或VIN不足以進行進一步計算。
所以,根據這三個變量得出標準化的典型判別函數公式:
Z=0.406X1+0.604X2+0.607X3
其中,X1為資產負債率,X2為凈資產比率,X3為凈資產收益率。
根據檢驗結果,Wilkslambda和F統計檢驗表明,現金流量比率、總資產凈利潤率和每股留存收益這三個變量的顯著性水平均小于0.001,檢驗通過。
針對篩選出的32家主板上市公司樣本數據(其中16家ST公司和16家非ST公司),采用逐步判別法剔除顯著性不高的變量,獲取判別出的高顯著性變量:資產負債率、凈資產比率和凈資產收益率,從而構建出財務預警模型。
通過實證檢驗可以清楚地看出,所構建的判別模型具有良好的判別能力和較高的判別精度,同時,也說明了逐步判別分析方法在構建財務預警模型中的可行性和有效性,它的分析結果不僅能夠為投資者的科學決策以及銀行等金融機構的放貸決策提供一定的依據,而且能夠為上市公司的財務風險提供預警和防范思路。
雖然文中的財務預警模型存在一定的局限性,但仍然是一種較為有效的預警方式,不僅可以在上市公司的財務預警方面發揮較好的示警作用,甚至可以不斷擴展在其他風險管理中的應用。
作者簡介:張彥寧(1990- ),女,漢族,河南洛陽,研究生,貴州財經大學,金融
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
發明與創新(2022年30期)2022-10-03 08:40:56
現代企業(2021年2期)2021-07-20 07:57:18
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
現代經濟信息(2020年34期)2020-06-08 06:02:40
數學物理學報(2020年2期)2020-06-02 11:29:24
意林·全彩Color(2019年9期)2019-10-17 02:25:48
人大建設(2018年6期)2018-08-16 07:23:10
文理導航·科普童話(2017年5期)2018-02-10 19:42:14
河南水利年鑒(2017年0期)2017-05-19 02:29:27
