基于合圖法(co-plot)的我國省際知識產權效率分析
2015-12-02 04:19:50柳春巖
生產力研究 2015年11期
柳春巖,羅 旭
(蘭州理工大學 經濟管理學院,甘肅 蘭州 730050)
知識產權又稱智慧財產權(Intellectual Property Rights,IPR)是指權利人對其所擁有的知識資本在有限時期內享有的專有權利。知識產權不僅是一種重要的法律權利和無形資產,也日益成為企業競爭的重要資源。
一、文獻綜述
知識產權的評價方法很多,通常采用知識產權指數的方法來分析、評估知識產權的競爭能力。根據范圍和內容的不同,知識產權評估方法分為企業知識產權評估和區域知識產權評估兩種。
2000年3月,歐盟出臺包括人力資源、新知識的產生、新知識的轉移和應用及創新的投入、產出和市場等4類,共計17項指標的新評價指標體系。[1]瑞士洛桑國際管理開發研究院連續多年發表的《世界競爭力年鑒》包括R&D支出、R&D人員、技術管理、科學環境、知識產權等五個子體系[2],共計25個指標。2004年日本《知識產權戰略評價指標》[3],以專利的收益率、成果轉化利用率、人均研究開發經費和知識產權的經濟產出作為戰略實施的評價指標。2007年國際知識產權聯盟(IPRA)發布世界知識產權指數(International Property Rights Index)。目前共連續發布六版IPRI,2012年涉及國家達到129個。[4]IPRI由三部分,共計10指標構成。
國內學者對知識產權評價體系也進行了廣泛研究。
黃慶等(2004)[5]從專利數量、質量和價值三方面綜合考慮,構建了一套以數量類指標表征專利關注程度,以質量類指標表征科技創新程度,以價值類指標描述專利在市場經濟活動中作用的指標體系,對我國區域的知識產權狀況進行了評價。劉鳳朝(2009)[6]選取專利申請量、發明專利申請量、專利授權量和發明專利授權量作為分析評價指標,運用主成分分析方法對我國31個省市區和15個副省級城市的專利發展狀況進行綜合排序、等級劃分和評價。王正志(2010)[7]建立了一套包含多層次、多指標的中國知識產權指數體系,對我國知識產權發展過程進行研究分析,多年相繼發布《中國知識產權指數報告》。王鳴濤、葉春明(2010)[8]采用AHP和專家咨詢相結合的方法,提出以知識產權申請、知識產權授權、知識產權實施、知識產權效益、知識產權保護、知識產權管理和知識產權環境為一級指標,涵蓋27個二級指標的區域知識產權工作業績評價指標體系。雒園園等(2011)[9]通過知識產權質量、知識產權數量、知識產權開發能力、知識產權運營能力、知識產權保護能力5指標構建了區域知識產權競爭力評價指標體系。羅旭(2013,2014)[10-11]通過對中國知識產權指數的區域差異及與區域經濟績效分析發現:知識產權指數的區域差異突出,東部地區的知識產權實力指數是西部地區的2倍多。知識產權指數與人均GDP具有明顯的相關性,知識產權指數增長0.1,將產生人均近一萬元GDP增長。并通過Malmquist指數對我國省際知識產權全要素生產率增長進行了分析。
對相關文獻進行梳理,可見國內外對知識產權指數的研究更多是從國家宏觀層面上展開,側重點也不盡相同。雖然數理模型多種多樣,但直觀的圖形化的方法并不多見。本文采用合圖法(co-plot)對《中國知識產權指數報告2013》的相關數據進行圖形分析。圖形直觀地表明了2012年我國31省市區知識產權效率值分布狀況。
二、生產率效率的非參數估計
數據包絡分析(DEA)是由 Charnes,Cooper和 Rhodes(1978)提出,逐步發展為多種模型的一種非參數分析方法,采用DEA方法的主要優勢是它不需要確定的生產函數形式。
可變規模收益時的標準非參數DEA模型:
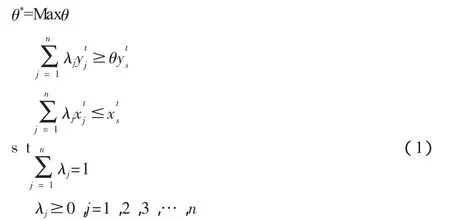
超效率非參數DEA模型:
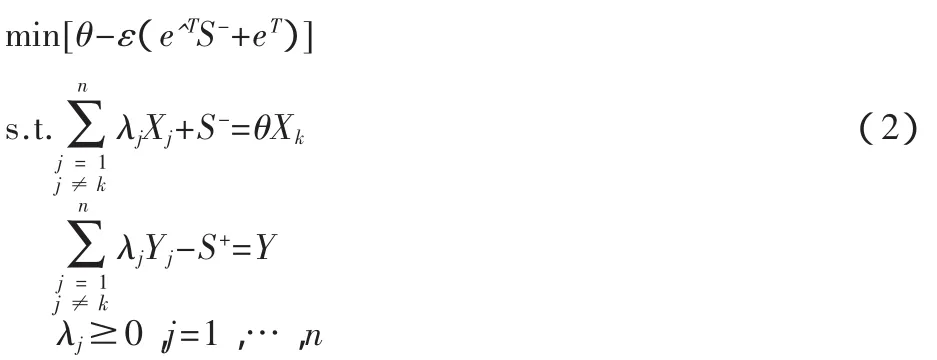
ε是非阿基米德小量,S-,S+是投入與產出的松弛變量。
本文采用《中國知識產權指數報告2013》中的綜合實力指數作為產出指標。并使用相同年份的《中國科技統計年鑒》的三項統計指標:科研經費投入、科研人員投入及科研時間投入作為投入指標、來分析2012年我國31省市區知識產權效率分布狀況。
即采用3投入1產出計算可變規模DEA和超效率DEA模型效率值(見表1)。
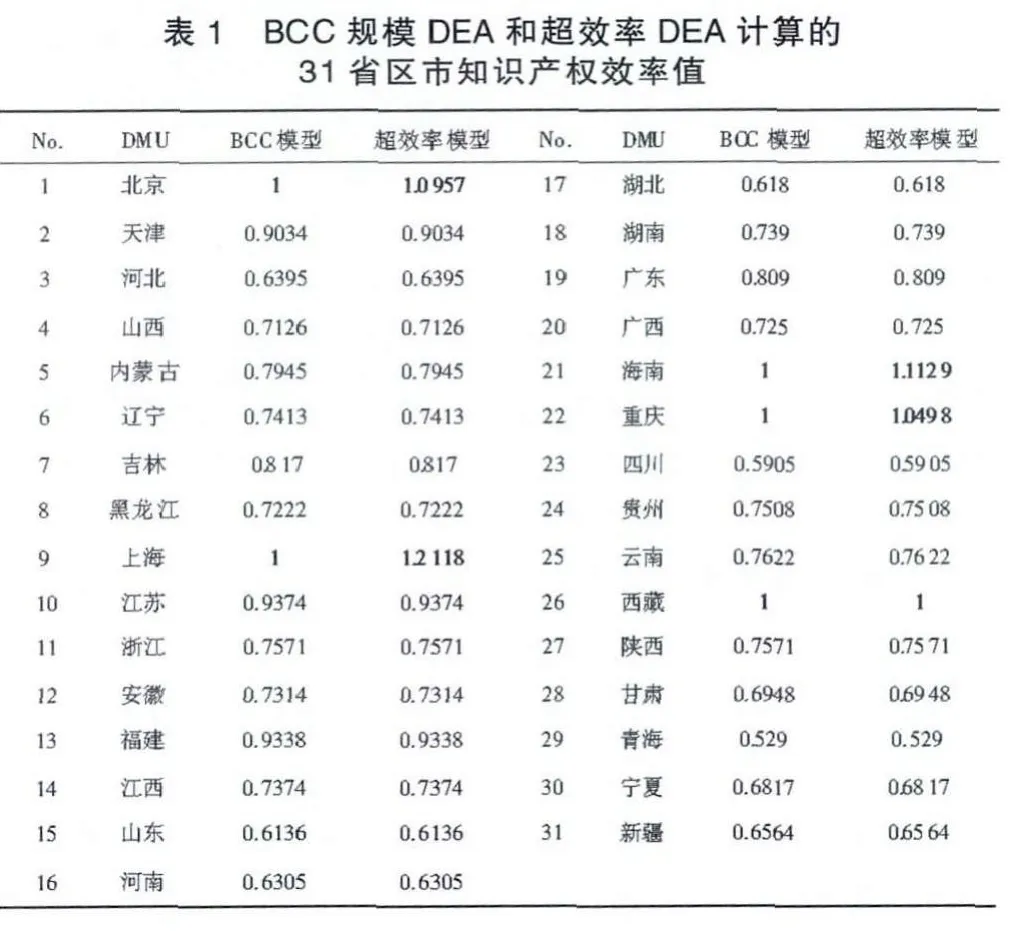
分析可知,通過可變規模DEA模型計算的31省市區知識產權效率值有5個省區市(北京、上海、重慶、海南、西藏)處于效率前沿面上,效率值為1,其余省市區都是無效的。而這5個DMU經濟、社會發展差距突出,通過超效率DEA模型可以較好地區分這5省區市效率值的差異。
三、合圖法
Co-plot方法[12]是由Ad.i Raveh1996年提出的,并很快應用于多個領域研究之中。[13-15]與傳統的統計軟件excel和層次聚類法相比較,co-plot法在研究對象多元聚類分析中具有自己獨特的優勢。合圖法是對數據矩陣Yn×m進行圖形展示,n個研究對象(即DMU)被定為n個點,m個變量基于同一軸線和同一原點以m個箭頭顯示。通過合圖法,具有相似特征的研究對象(即DMU)較為緊密地展示在圖上,而每個變量則以不同的箭頭單獨體現,通過兩箭頭間的夾角關系來分析其相關性。即處于相同方向的箭頭表明正相關,如果兩箭頭形成180°表明兩變量為負相關,若兩箭頭成90°垂直表明其不相關。合圖法以兩圖依次重疊而成。第一幅圖顯示n個研究對象的n個不同區位,第二幅圖基于第一幅圖的基礎上以各個箭頭展示m個屬性有關信息。合圖法使用的主要目的是得到一個包括n個研究對象及其m個變量的對應數據矩陣Yn×m的圖形。
合圖法分為四個步驟:
①標準化數據矩陣:

②研究指標差異性測度:

③圖形展示:采用最小空間分析法(SSA)對n個研究指標進行圖形展示,借助關系疏離指數θ,SSA可以判斷圖形模擬的精確性。通過生成2n個(X1i,X2i),i=1,2,…,n,使每一行Y=(Yi1,…,Yim)能夠在二維空間(X1i,X2i)中以點的形式展現出來。
④形成由研究變量組成的m個箭頭:每個研究變量的實際值和在箭頭軸上的投影的相關程度最大化,由于高度相關的變量在圖形上呈現方向一致。兩兩箭頭的夾角余弦值比例與箭頭之間的相關程度成比例。
借助兩個系數可以檢驗合圖法形成圖形的擬合程度。一個是步驟③中的θ,另一個是步驟④中的m個變量最大相關系,在展示圖形中,那些擁有較低rj的變量將會被剔除。根據經驗當θ≥0.15或,擬合程度較低時,得出的圖形難以正確反映數據所包含的信息。一般而言,合圖法的運用對n和m的數目并沒有嚴格限制,但當n>200和m>50時,很多細節信息在圖形中尚無法展示。
四、數據及圖形分析
(一)數據矩陣
通常DEA與Co-plot是通過比例關系聯系在一起的。我們定義3個產出/投入比率rkj如下:
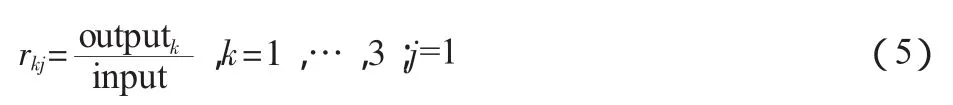
Input分別是科技經費投入額(億元)、科技人員數(萬人)和研發人員全時當量(萬人年);output為知識產權指數。分別得到三個變量(比率值):科技投入(億元)創造的知識產權指數值,科技人員(萬人)創造的知識產權指數值,研發人員全時當量(萬人年)創造的知識產權指數值。將31×3矩陣代入,繪制co-plot圖(見圖1)。
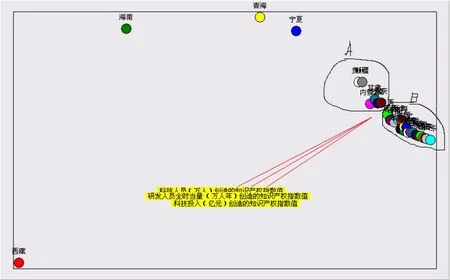
圖1 31省市區在三變量上的合圖法
(二)co-plot圖形分析
1.31省市區在三變量上的合圖法。在圖1中31個省區市分布在兩個維度空間中,反映圖形擬合程度的兩個檢驗系數:離散度 θ=0.01,最大相關系說明擬合程度很高。通過觀察我們可以發現:
(1)三個變量間聯系緊密,尤其是科技人員數(萬人)創造的知識產權指數值和研發人員全時當量(萬人年)創造的知識產權指數值。
(2)31省市區中巨大部分都分布在三變量的重心周圍。西藏和海南兩省區是離群極值,是有效率的,其他有效率的省市(北京、上海和重慶)分布在大量的無效率省市區中。青海和寧夏兩省區也是離群值,是無效率的,且效率值較低。寧夏略高于青海,但青海在科技人員(萬人)創造的知識產權指數值指標上高于寧夏。與可變規模收益DEA,超效率DEA模型結果一致。
(3)剩余的27省市區分為兩個組群:A組包括貴州、新疆、甘肅、內蒙古、重慶和江西,其余21省市區為B組。為了更清晰準確直觀地分析,我們把A、B抽出,單獨進行分析。
用A組6省市區相關數據構成一個6×3的矩陣,代入繪制co-plot圖(見圖2)。
2.6省市區在三變量上的合圖法。在圖2中6個省區市分布在兩個維度空間中,反映圖形擬合程度的兩個檢驗系數:離散度 θ=0.01,最大相關系說明擬合程度很高。通過觀察我們可以發現:
(1)研發人員全時當量(萬人年)創造的知識產權指數值與科技人員數(萬人)創造的知識產權指數值和科技投入(億元)創造的知識產權指數值均保持密切聯系。
(2)江西是離群值,遠離三指標變量的重心,也是無效率值。在三個指標變量上,得分較低。
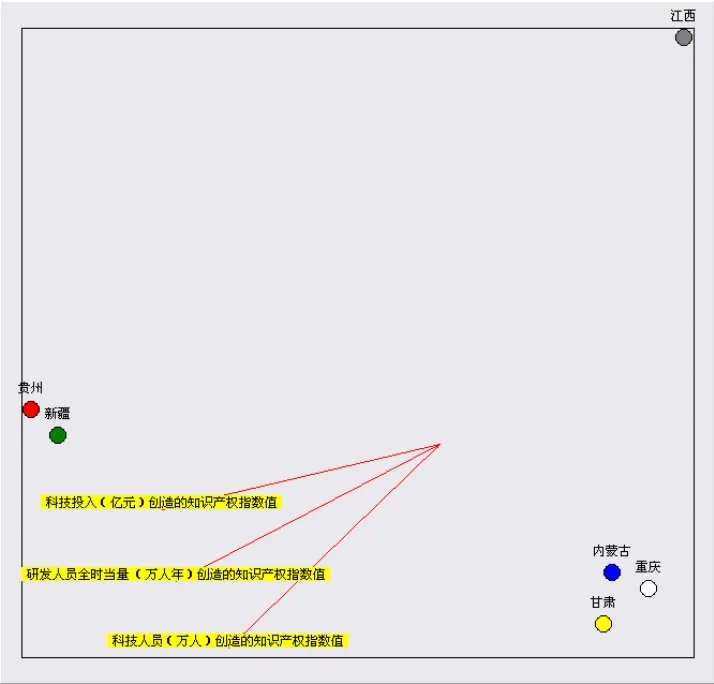
圖2 6省市區在三變量上的合圖法
(3)新疆、貴州在科技投入(億元)創造的知識產權指數值上得分相對較高。
(4)內蒙古、甘肅和重慶三地在科技人員(萬人)創造的知識產權指數值指標變量上得分相對較高,重慶也是有效率值的。
B組21省市區相關數據構成一個21×3的矩陣,代入繪制co-plot圖(見圖 3)。
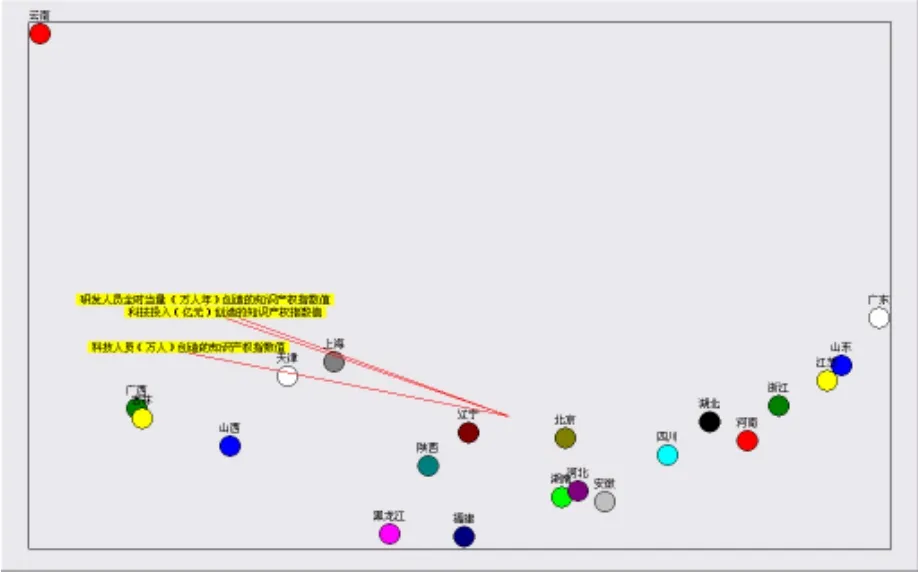
圖3 21省市區在三變量上的合圖法
3.21省市區在三變量上的合圖法。B組主要是東、中部地區省份。反映圖形擬合程度的兩個檢驗系數:離散度θ=0.05,最大相關系說明擬合程度很高。通過觀察我們可以發現:
(1)研發人員全時當量(萬人年)創造的知識產權指數值指標變量與科技投入(億元)創造的知識產權指數值指標變量聯系更為密切。
(2)云南是離群值,遠離三指標變量的重心,也是無效率值。在科技投入(億元)創造的知識產權指數值指標變量上,得分較高。
(3)天津在科技人員(萬人)創造的知識產權指數值指標變量上得分較高。上海在研發人員全時當量(萬人年)創造的知識產權指數值指標變量與科技投入(億元)創造的知識產權指數值指標變量上,有上佳表現。
(4)廣西、吉林和山西在科技投入(億元)創造的知識產權指數值指標變量和科技人員(萬人)創造的知識產權指數值指標變量上得分相對較高。
(5)廣東、山東和江蘇在科技人員(萬人)創造的知識產權指數值和科技投入(億元)創造的知識產權指數值兩指標上表現不佳,得分較低。
(6)福建、黑龍江兩省在三個指標變量上得分比較低。北京和遼寧在三指標變量的重心附件,表明它們的得分比較平均。剩余的其它各省區得分則比較低。
五、研究結論
本文采用合圖法(Co-plot)直觀分析了基于DEA模型計算的2012年我國省際知識產權相對效率值及其相關指標變動特點。合圖法是對Yn×m的數據矩陣進行圖形展示,每一個DMU表現為二維空間的一個點,每一個指標變量體現為源于(m個指標變量)重心的一條射線。通過比例關系設定,與其它的圖示方法相比,合圖法(Co-plot)的明顯優勢就是可以同時分析DMU和指標變量。把DEA和合圖法(Co-plot)聯系起來,通過解讀3張合圖,不僅可以直觀、清晰地分析31個省市區在知識產權相對效率值方面的分布及變化,更能進一步分析其在三項指標變量上的優劣和特點。
[1]楊平.歐盟建立創新評價指標體系及其與美日的比較[J].科技經濟透視,2002(8):24-25
[2]陳昌柏.借鑒國際經驗設置我國知識產權戰略評價指標[EB/OL].http://www.chinado.cn/ReadNews.asp?NewsID=935.
[3]王紹媛.日本知識產權戰略特點與借鑒[J].現代日本經濟,2009(6):40-44.
[4]Gaurav Tiwari.2011 report international property rights index property rights alliance,2011.
[5]黃慶,曹津燕.專利評價指標體系——專利評價指標體系的設計和構建[J].知識產權,2004(5):25-28.
[6]劉鳳朝,徐冠華.國家創新能力測度方法及其應用[M].北京:科學出版社,2009.
[7]王正志.中國知識產權指數報告2009/2011/2012[M].北京:知識產權出版社,2009/2011/2012/2013.
[8]王鳴濤,葉春明.區域知識產權工作業績評價指標體系研究[J].科技管理研究,2010(21):47-53.
[9]雒園園,田樹軍,于小丹.區域知識產權競爭力及評價指標體系研究[J].科技管理研究,2011(14):68-75.
[10]羅旭.中國知識產權指數的區域差異及與區域經濟績效分析[J].科研管理研究,2013(23):120-122.
[11]羅旭,柳春巖.基于DEA-Malquist指數的我國省際知識產權全要素生產率增長分析[J].科研管理研究,2014(22):38-42.
[12]LipshitzG,Raveh.A Applications of the Co-plot Method in the Study of Socioeconomic Differences Among Cities[J].Urban Studies,1996,31(1):123-135.
[13]Adi Raveh.Co plot:A Graphic Display Method for Geo metrical Representations of MCDM[J].European Journal of Operational Research,2000,125(3):670-678.
[14]馬秋芳,楊新軍,孫根年.合圖法(co plot)在入境游客期望感知分析的應用[J].系統工程理論與實踐,2008(4):167-171.
[15]馬秋芳,楊新軍,王軍偉.基于游客的旅游資源分類及旅游空間模型構建[J].地域研究與開發,2009,28(4):81-84.
猜你喜歡
石油瀝青(2021年4期)2021-10-14 08:50:44
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
甘肅教育(2020年14期)2020-09-11 07:57:42
電子制作(2018年18期)2018-11-14 01:48:24
山東工業技術(2016年15期)2016-12-01 05:31:22
時代英語·高二(2015年1期)2015-03-16 00:08:11
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
中國衛生(2014年11期)2014-11-12 13:11:32
俄羅斯問題研究(2012年1期)2012-03-25 09:54:51
體育師友(2012年4期)2012-03-20 15:30:10
